Standard Metabolomics
Christina Schmidt
Heidelberg UniversityDimitrios Prymidis
Cologne UniversitySource:
vignettes/Standard Metabolomics.Rmd
Standard Metabolomics.Rmd
A standard metabolomics experiment refers to intracellular extracts
(e.g. cell or bacteria culture), to tissue samples (e.g. from animals or
patients), to plasma samples (e.g. blood) and many other types of
experimental setups.
In this tutorial we showcase how
to use MetaProViz:
- To process raw peak data and identify outliers.
- To perform differential metabolite analysis (DMA) to generate Log2FC
and statistics and perform pathway analysis using Over Representation
Analysis (ORA) on the results.
- To do metabolite clustering analysis (MCA) to find clusters of
metabolites with similar behaviors and perform pathway analysis using
ORA on each cluster.
- To use specific visualizations to aid biological interpretation of
the results.
First if you have not done yet, install the required dependencies and load the libraries:
# 1. Install Rtools if you haven’t done this yet, using the appropriate version (e.g.windows or macOS).
# 2. Install the latest development version from GitHub using devtools
#devtools::install_github("https://github.com/saezlab/MetaProViz")
library(MetaProViz)
#> Error in get(paste0(generic, ".", class), envir = get_method_env()) :
#> object 'type_sum.accel' not found
#dependencies that need to be loaded:
library(magrittr)
library(dplyr)
library(rlang)
library(ggfortify)
library(tibble)
#Please install the Biocmanager Dependencies:
#BiocManager::install("clusterProfiler")
#BiocManager::install("EnhancedVolcano")1. Loading the example data
Here we choose an example datasets, which is publicly available on metabolomics
workbench project PR001418 including metabolic profiles of human
renal epithelial cells HK2 and cell renal cell carcinoma (ccRCC) cell
lines cultured in Plasmax cell culture media (Sciacovelli et al. 2022). Here we use the
integrated raw peak data as example data using the trivial metabolite
name in combination with the KEGG ID as the metabolite
identifiers.
As part of the
MetaProViz package you can load the example data into
your global environment using the function
toy_data():1. Intracellular experiment (Intra)
The raw data are available via metabolomics
workbench study ST002224 were intracellular metabolomics of HK2 and
ccRCC cell lines 786-O, 786-M1A and 786-M2A were performed.
We can load the ToyData, which includes columns with Sample
information and columns with the measured metabolite integrated
peaks.
Intra <- MetaProViz::ToyData(Data="IntraCells_Raw")| Conditions | Analytical_Replicates | Biological_Replicates | valine-d8 | ADP-ribose | citrulline | |
|---|---|---|---|---|---|---|
| MS55_01 | HK2 | 1 | 1 | 1910140239 | 2417484 | 514024322 |
| MS55_02 | HK2 | 2 | 1 | 2030901280 | 2159520 | 507001076 |
| MS55_03 | HK2 | 3 | 1 | 2001950756 | 2427805 | 551503662 |
| MS55_04 | HK2 | 4 | 1 | 1971520079 | 1988317 | 483751307 |
| MS55_05 | 786-O | 1 | 1 | 2150817213 | 1732016 | 272896668 |
2. Additional information mapping the trivial metabolite
names to KEGG IDs and selected pathways
(MappingInfo)
MappingInfo <- MetaProViz::ToyData(Data="Cells_MetaData")| HMDB | KEGG.ID | KEGGCompound | Pathway | |
|---|---|---|---|---|
| N-acetylaspartate | HMDB0000812 | C01042 | N-Acetyl-L-aspartate | Alanine, aspartate and glutamate metabolism |
| argininosuccinate | HMDB0000052 | C03406 | N-(L-Arginino)succinate | Alanine, aspartate and glutamate metabolism |
| N-acetylaspartylglutamate | HMDB0001067 | C12270 | N-Acetylaspartylglutamate | Alanine, aspartate and glutamate metabolism |
| tyrosine | HMDB0000158 | C00082 | L-Tyrosine | Amino acid metabolism |
| asparagine | HMDB0000168 | C00152 | L-Asparagine | Amino acid metabolism |
3. KEGG pathways that are loaded via KEGG API using the
package KEGGREST and can be used to perform pathway
analysis (Kanehisa and Goto 2000).
(KEGG_Pathways)
#This will use KEGGREST to query the KEGG API to load the pathways:
MetaProViz::LoadKEGG()
#> Cached file loaded from: ~/.cache/KEGG_Metabolite.rds| term | Metabolite | MetaboliteID | Description | |
|---|---|---|---|---|
| 1 | Glycolysis / Gluconeogenesis - Homo sapiens (human) | Pyruvate | C00022 | Glycolysis / Gluconeogenesis - Homo sapiens (human) |
| 2 | Glycolysis / Gluconeogenesis - Homo sapiens (human) | Acetyl-CoA | C00024 | Glycolysis / Gluconeogenesis - Homo sapiens (human) |
| 3 | Glycolysis / Gluconeogenesis - Homo sapiens (human) | D-Glucose | C00031 | Glycolysis / Gluconeogenesis - Homo sapiens (human) |
| 52 | Pentose phosphate pathway - Homo sapiens (human) | Pyruvate | C00022 | Pentose phosphate pathway - Homo sapiens (human) |
| 53 | Pentose phosphate pathway - Homo sapiens (human) | D-Glucose | C00031 | Pentose phosphate pathway - Homo sapiens (human) |
| 54 | Pentose phosphate pathway - Homo sapiens (human) | D-Fructose 6-phosphate | C00085 | Pentose phosphate pathway - Homo sapiens (human) |
2. Run MetaProViz Analysis
Currently, MetaProViz contains four different modules, which include different methods and can be used independently from each other or in combination (see introduction for more details). Here we will go trough each of those modules and apply them to the example data.
Pre-processing
MetaProViz includes a pre-processing module with the
function Preprocessing() that has multiple parameters to
perform customize data processing.Feature_Filtering applies the 80%-filtering rule on the
metabolite features either on the whole dataset (=“Standard”) (Bijlsma et al. 2006) or per condition
(=“Modified”) (Wei et al. 2018). This
means that metabolites are removed were more than 20% of the samples
(all or per condition) have no detection. With the parameter
Feature_Filt_Value we enable the adaptation of the
stringency of the filtering based on the experimental context. For
instance, patient tumour samples can contain many unknown subgroups due
to gender, age, stage etc., which leads to a metabolite being detected
in only 50% (or even less) of the tumour samples, hence in this context
it could be considered to change the Feature_Filt_Value
from the default (=0.8). If Feature_Filtering = "None", no
feature filtering is performed. In the context of
Feature_Filtering it is also noteworthy that the function
Pool_Estimation() can be used to estimate the quality of
the metabolite detection and will return a list of metabolites that are
variable across the different pool measurements (pool = mixture of all
experimental samples measured several times during the LC-MS run) .
Variable metabolite in the pool sample should be removed from the
data.
The parameter TIC_Normalization refers to Total Ion Count
(TIC) normalisation, which is often used with LC-MS derived metabolomics
data. If TIC_Normalization = TRUE, each feature
(=metabolite) in a sample is divided by the sum of all intensity value
(= total number of ions) for the sample and finally multiplied by a
constant ( = the mean of all samples total number of ions). Noteworthy,
TIC normalisation should not be used with small number of features (=
metabolites), since TIC assumes that on “average” the ion count of each
sample is equal if there were no instrument batch effects (Wulff and Mitchell 2018).
The parameter MVI refers to Missing Value Imputation (MVI)
and if MVI = TRUE half minimum (HM) missing value
imputation is performed per feature (= per metabolite). Here it is
important to mention that HM has been shown to perform well for missing
vales that are missing not at random (MNAR) (Wei
et al. 2018).
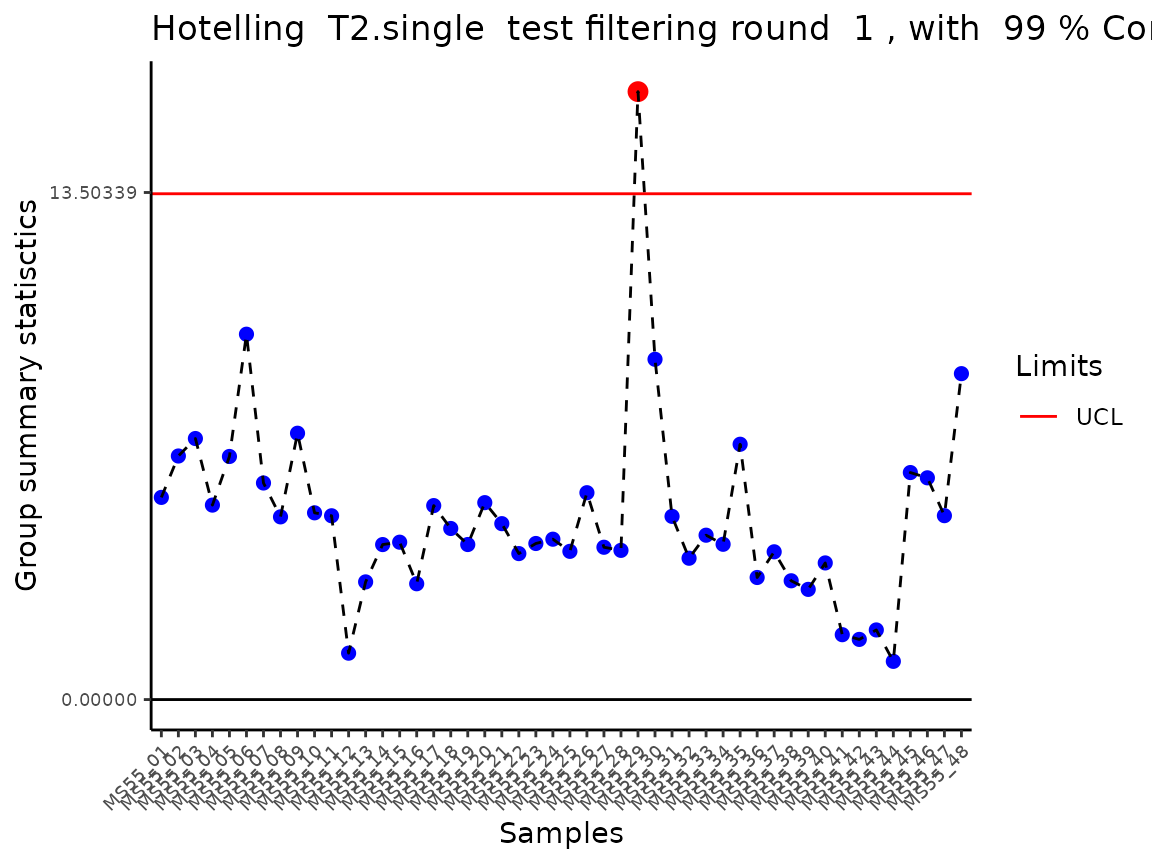
Lastly, the function Preprocessing() performs outlier
detection and adds a column “Outliers” into the DF, which can be used to
remove outliers. The parameter HotellinsConfidence can be
used to choose the confidence interval that should be used for the
Hotellins T2 outlier test (Hotelling
1931).
Since our example data contains pool samples, we will do
Pool_Estimation() before applying the
Preprocessing() function. This is important, since one
should remove the features (=metabolites) that are too variable prior to
performing any data transformations such as TIC as part of the
Preprocessing() function.
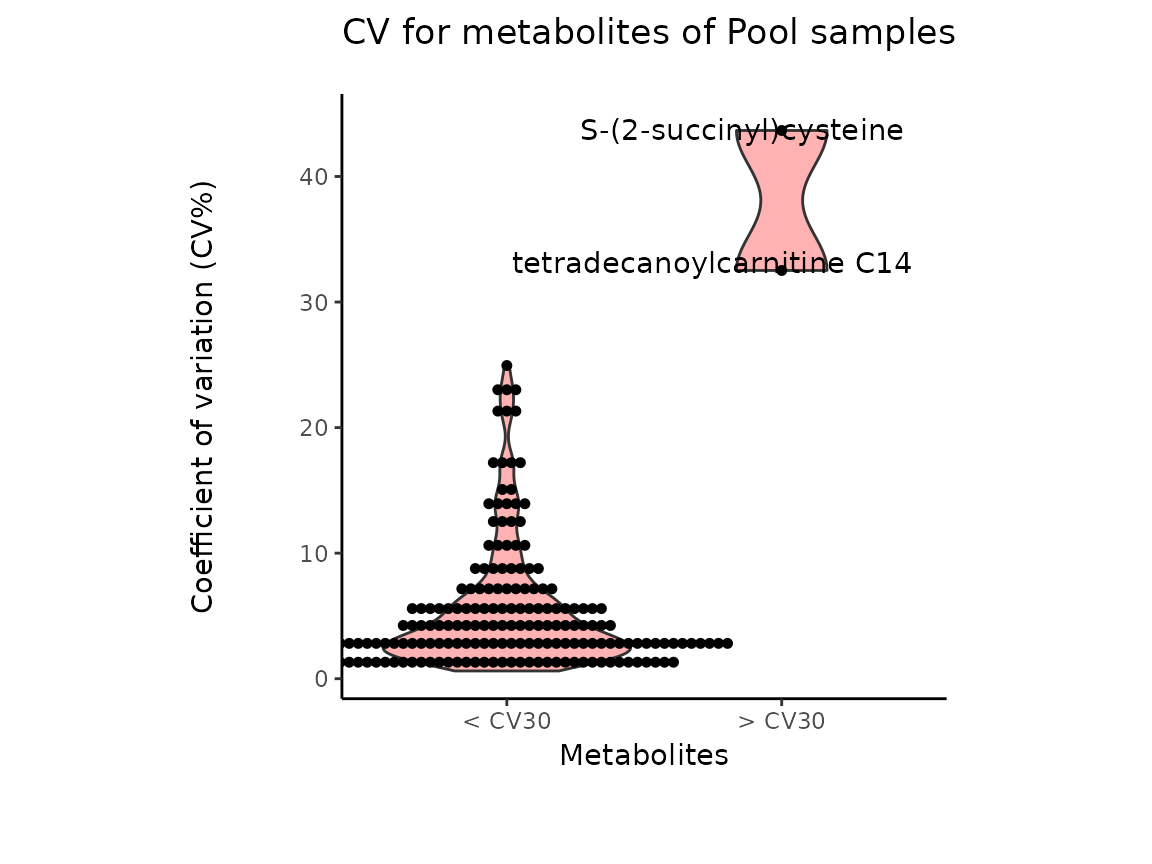
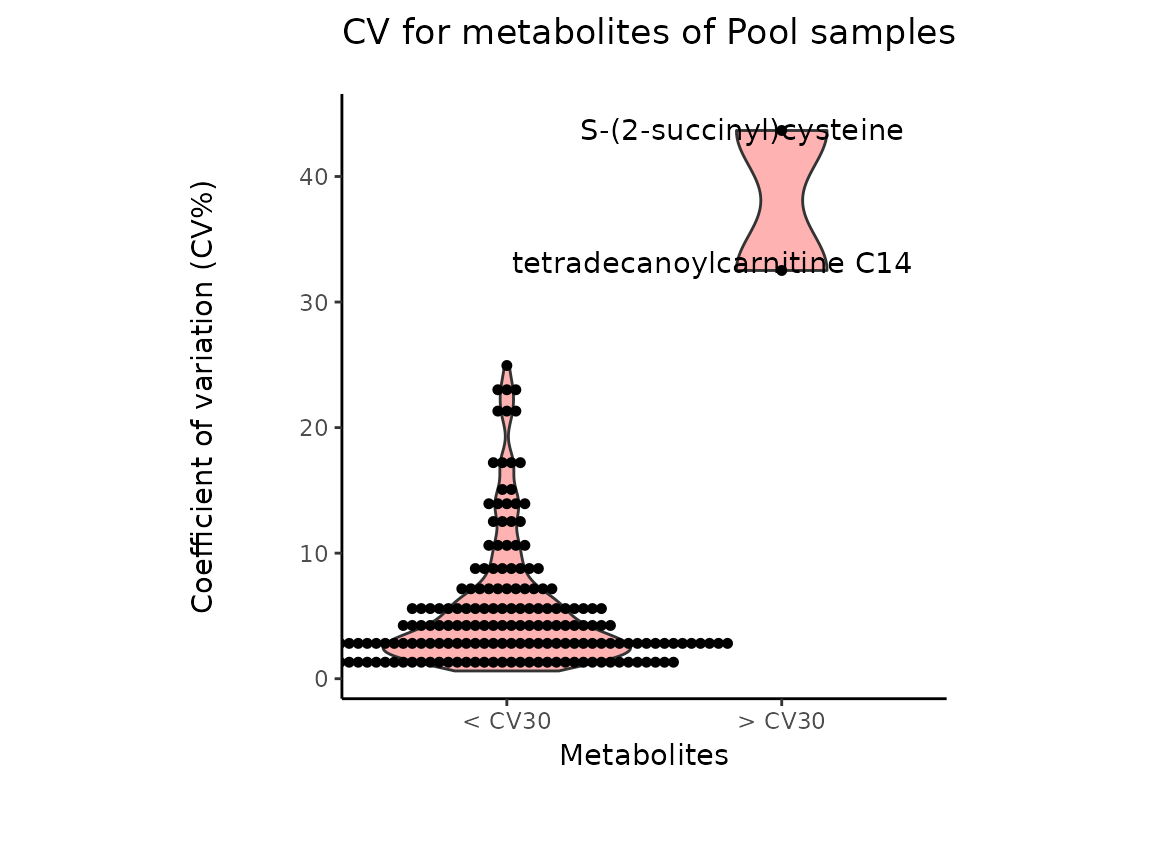
It is worth mentioning that the Coefficient of variation (CV) is
calculated by dividing the standard deviation (SD) by the mean. Hence CV
depends on the SD, which in turn works for normally distributed
data.
#### Select Pool samples:
#Get the Pool data
PoolData <- MetaProViz::ToyData(Data="IntraCells_Raw") %>%
subset(Conditions=="Pool", select = -c(1:3)) # we remove the columns "Conditions", "Analytical_Replicates" and "Biological_Replicates"
# Check the metabolite variability
Pool_Estimation_result<- MetaProViz::PoolEstimation(InputData = PoolData,
SettingsFile_Sample = NULL,
SettingsInfo = NULL,
CutoffCV = 30)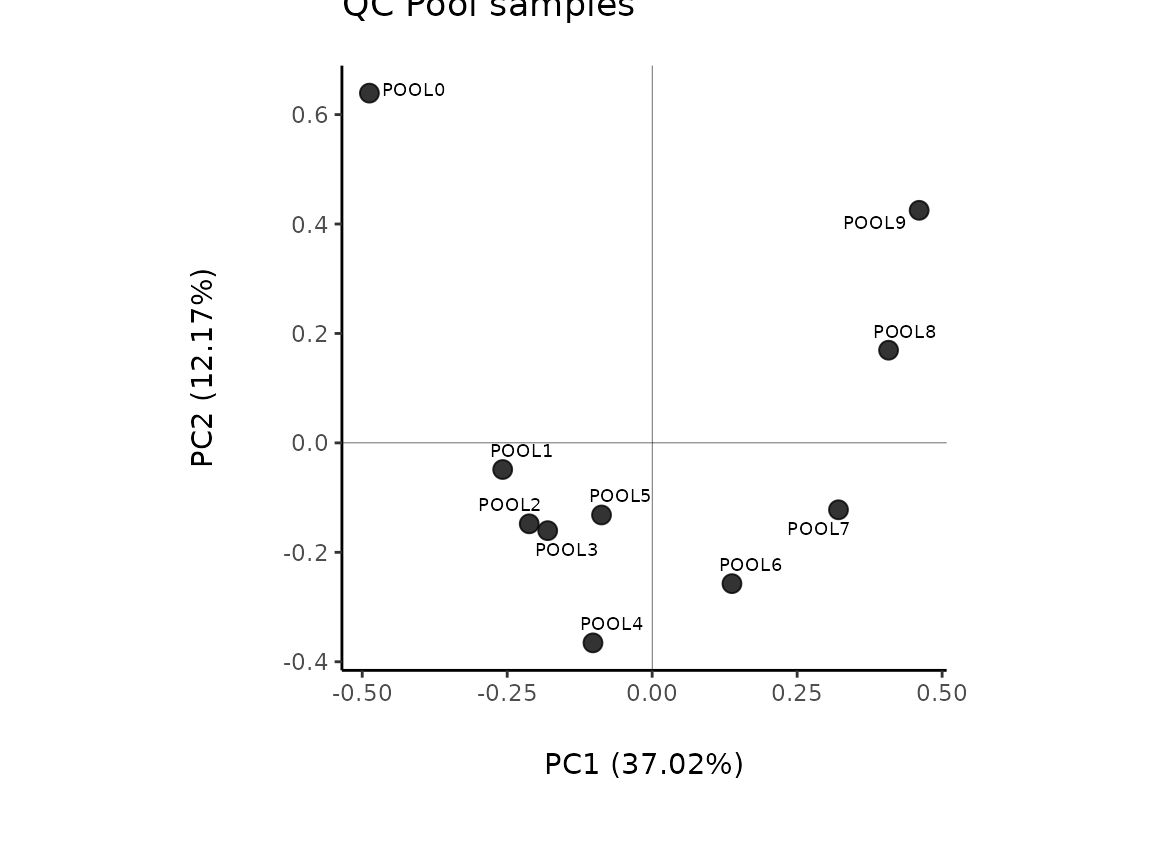

#### Alternatively a full dataset can be added. Here, the Conditions and PoolSamples name have to be specified in the Input_SettingsInfo
Pool_Estimation_result<- MetaProViz::PoolEstimation(InputData = Intra[,-c(1:3)],
SettingsFile_Sample = Intra[,1:3],
SettingsInfo = c(PoolSamples = "Pool", Conditions="Conditions"),
CutoffCV = 30)
Pool_Estimation_result_DF_CV <-Pool_Estimation_result[["DF"]][["CV"]]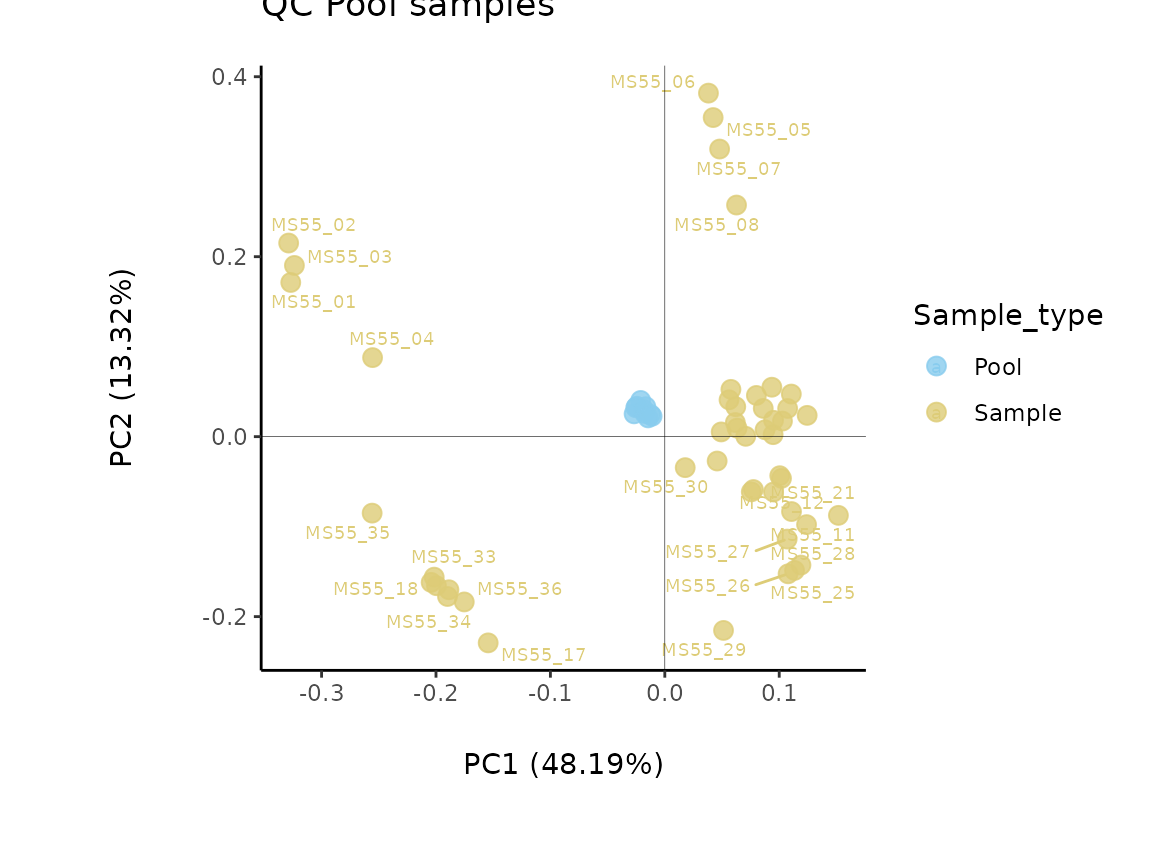
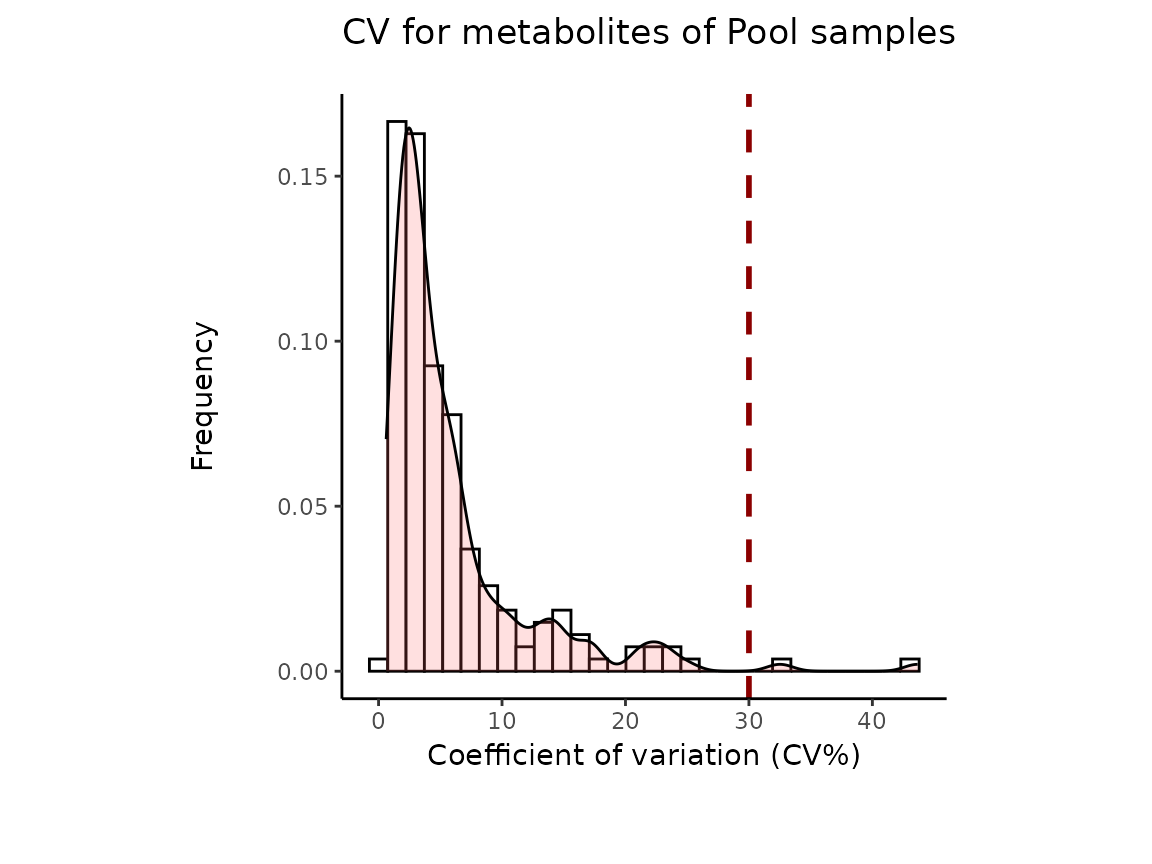
| Metabolite | CV | HighVar | MissingValuePercentage |
|---|---|---|---|
| valine-d8 | 2.425263 | FALSE | 0 |
| hippuric acid-d5 | 1.579717 | FALSE | 0 |
| 2/3-phosphoglycerate | 2.933440 | FALSE | 0 |
| 2-aminoadipic acid | 5.461470 | FALSE | 0 |
| 2-hydroxyglutarate | 1.366187 | FALSE | 0 |
The results from the Pool_Estimation() is a table that has
the CVs. If there is a high variability, one should consider to remove
those features from the data. For the example data nothing needs to be
removed. If you have used internal standard in your experiment you
should specifically check their CV as this would indicate technical
issues (here valine-d8 and hippuric acid-d5).
Now we will apply the Preprocessing() function to example
data and have a look at the output produced. You will notice that all
the chosen parameters and results are documented in messages. All the
results data tables, the Quality Control (QC) plots and outlier
detection plots are returned and can be easily viewed.
PreprocessingResults <- MetaProViz::PreProcessing(InputData=Intra[-c(49:58) ,-c(1:3)], #remove pool samples and columns with sample information
SettingsFile_Sample=Intra[-c(49:58) , c(1:3)], #remove pool samples and columns with metabolite measurements
SettingsInfo = c(Conditions = "Conditions",
Biological_Replicates = "Biological_Replicates"),
FeatureFilt = "Modified",
FeatureFilt_Value = 0.8,
TIC = TRUE,
MVI = TRUE,
HotellinsConfidence = 0.99,# We perform outlier testing using 0.99 confidence intervall
CoRe = FALSE,
SaveAs_Plot = "svg",
SaveAs_Table= "csv",
PrintPlot = TRUE,
FolderPath = NULL)
# This is the results table:
Intra_Preprocessed <- PreprocessingResults[["DF"]][["Preprocessing_output"]]#> FeatureFiltering: Here we apply the modified 80%-filtering rule that takes the class information (Column `Conditions`) into account, which additionally reduces the effect of missing values (REF: Yang et. al., (2015), doi: 10.3389/fmolb.2015.00004). Filtering value selected: 0.8
#> 3 metabolites where removed: AICAR, FAICAR, SAICAR
#> Missing Value Imputation: Missing value imputation is performed, as a complementary approach to address the missing value problem, where the missing values are imputing using the `half minimum value`. REF: Wei et. al., (2018), Reports, 8, 663, doi:https://doi.org/10.1038/s41598-017-19120-0
#> Total Ion Count (TIC) normalization: Total Ion Count (TIC) normalization is used to reduce the variation from non-biological sources, while maintaining the biological variation. REF: Wulff et. al., (2018), Advances in Bioscience and Biotechnology, 9, 339-351, doi:https://doi.org/10.4236/abb.2018.98022
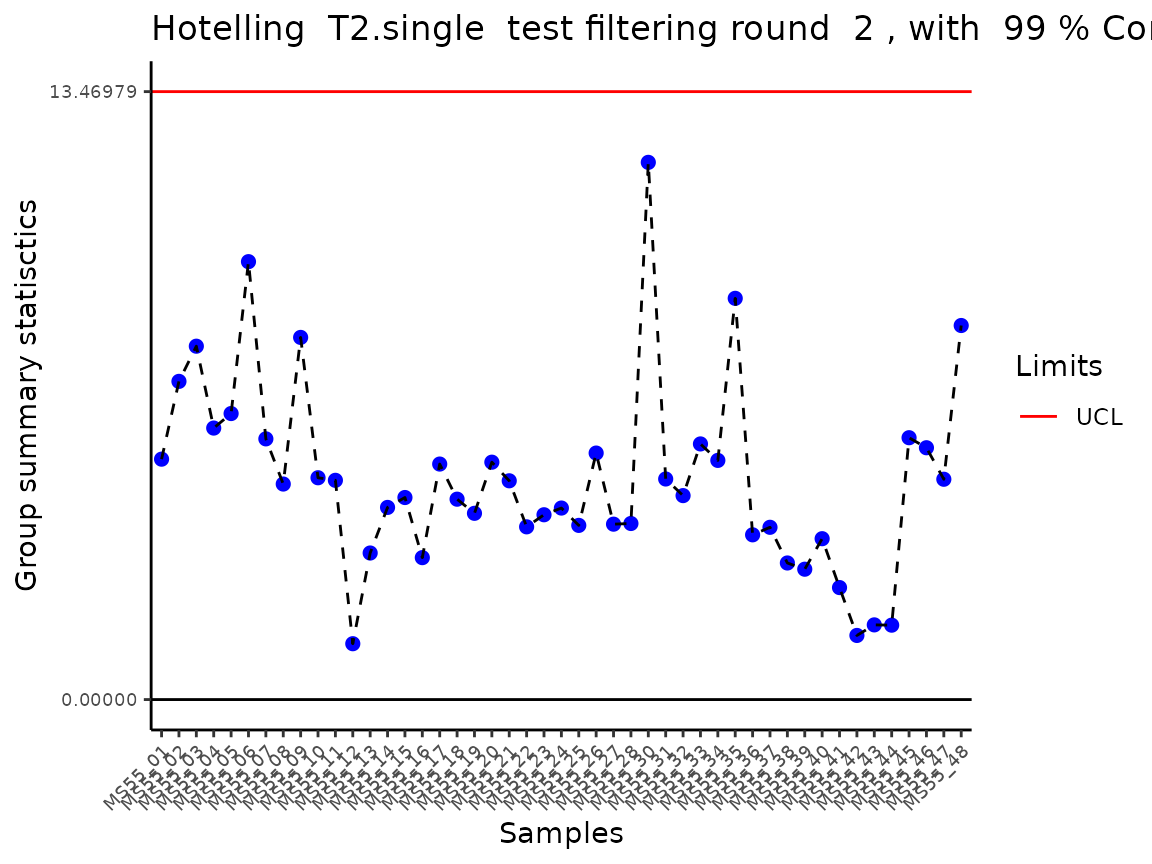
#> Outlier detection: Identification of outlier samples is performed using Hotellin's T2 test to define sample outliers in a mathematical way (Confidence = 0.99 ~ p.val < 0.01) (REF: Hotelling, H. (1931), Annals of Mathematical Statistics. 2 (3), 360–378, doi:https://doi.org/10.1214/aoms/1177732979). HotellinsConfidence value selected: 0.99
#> There are possible outlier samples in the data
#> Filtering round 1 Outlier Samples: MS55_29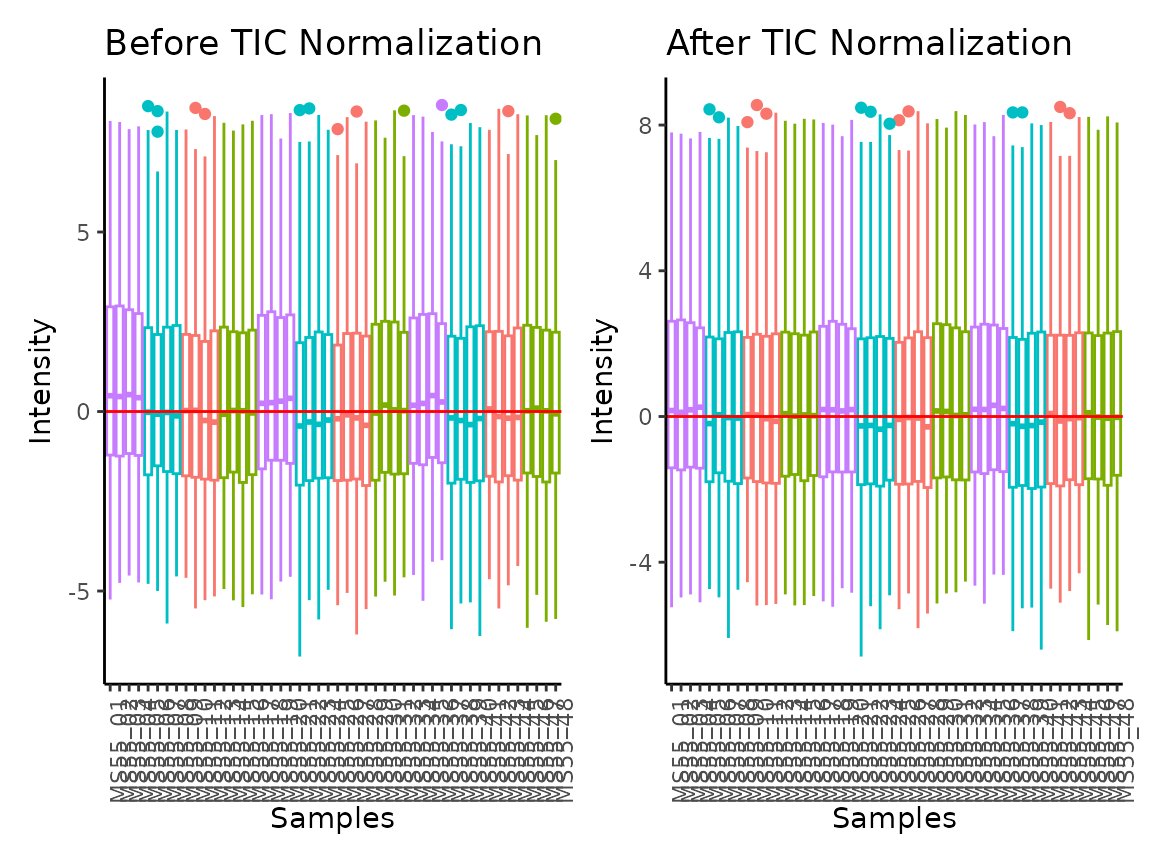






| Conditions | Analytical_Replicates | Biological_Replicates | Outliers | valine-d8 | hippuric acid-d5 | 2/3-phosphoglycerate | 2-aminoadipic acid | 2-hydroxyglutarate | |
|---|---|---|---|---|---|---|---|---|---|
| MS55_29 | 786-M2A | 1 | 2 | Outlier_filtering_round_1 | 2387588900 | 4569088590 | 40184147 | 6064712 | 447702444 |
| MS55_30 | 786-M2A | 2 | 2 | no | 2129509827 | 3909434732 | 40901362 | 5928248 | 438592007 |
| MS55_31 | 786-M2A | 3 | 2 | no | 2008257641 | 3820133317 | 45656317 | 6122422 | 423960574 |
| MS55_32 | 786-M2A | 4 | 2 | no | 2023353119 | 3808913048 | 46166031 | 6633984 | 434158266 |
In the output table you can now see the column “Outliers” and for the
Condition 786-M2A, we can see that based on Hotellin’s T2 test, one
sample was detected as an outlier in the first round of filtering.
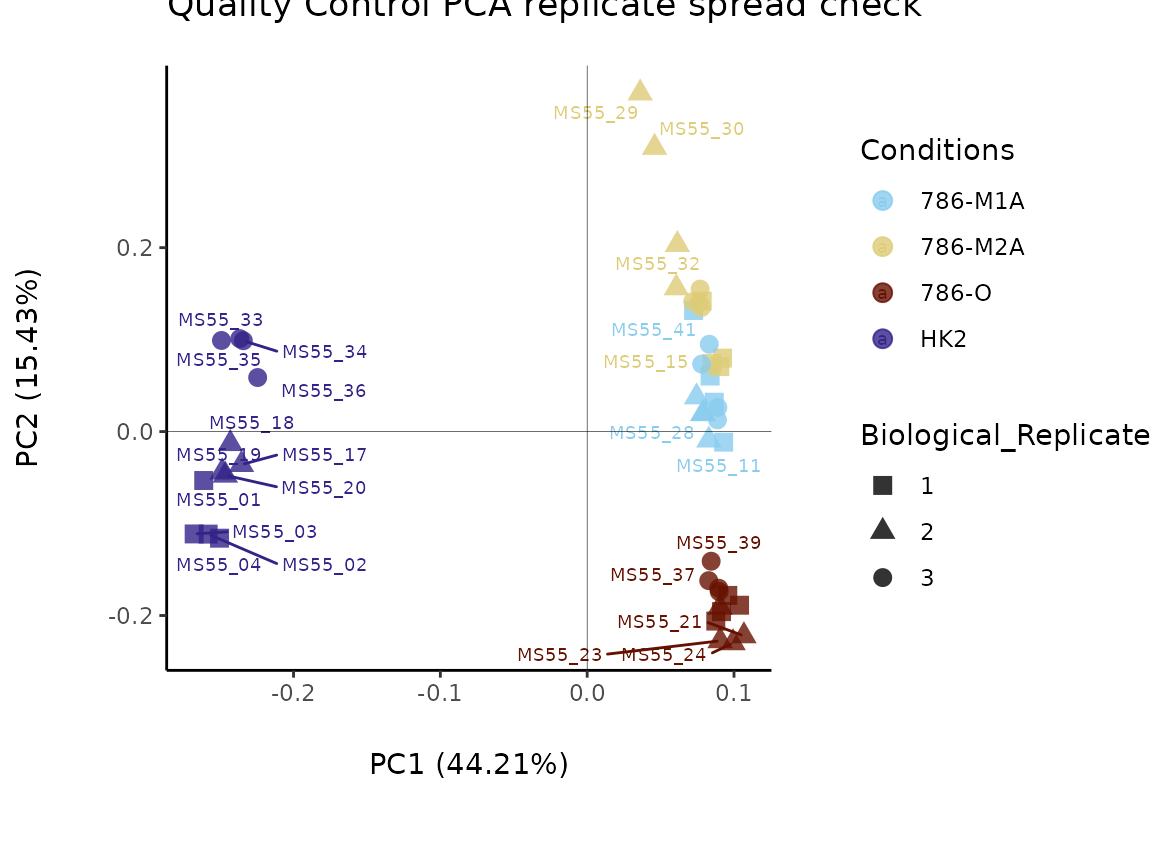
As part of the Preprocessing() function several plots are
generated and saved. Additionally, the ggplots are returned into the
list to enable further modifiaction using the ggplot syntax. These plots
include plots showing the outliers for each filtering round and other QC
plots.
As part of the MetaProViz visualization module one can
easily further customize the PCA plot and adapt color and shape for the
information of interest. You can see more below for the
VizPCA() function.
Before we proceed, we will remove the outlier:
As you may have noticed, in this example dataset we have several
biological replicates that where injected (=measured) several times,
which can be termed as analytical replicates. The
MetaProViz pre-processing module includes the function
ReplicateSum(), which will do this task and save the
results:
Intra_Preprocessed <- MetaProViz::ReplicateSum(InputData=Intra_Preprocessed[,-c(1:4)],
SettingsFile_Sample=Intra_Preprocessed[,c(1:4)],
SettingsInfo = c(Conditions="Conditions", Biological_Replicates="Biological_Replicates", Analytical_Replicates="Analytical_Replicates"))
Using the pre-processed data, we can now use the
MetaProViz visualization module and generate some
overview Heatmaps VizHeatmap() or PCA plots
VizPCA(). You can see some examples below.
DMA
Differential Metabolite Analysis (DMA) is used to
compare two conditions (e.g. Tumour versus Healthy) by calculating the
Log2FC, p-value, adjusted p-value and t-value. With the different
parameters STAT_pval and STAT_padj one can
choose the statistical tests such as t.test, wilcoxon test, limma,
annova, kruskal walles, etc. (see function reference for more
information).
As input one can use the pre-processed data we have generated using the
Preprocessing module, but here one can of course use any DF
including metabolite values, even though we recommend to normalize the
data and remove outliers prior to DMA. Moreover, we require the
Input_SettingsFile_Sample including the sample metadata
with information which condition a sample corresponds to. Additionally,
we enable the user to provide a Plot_SettingsFile_Metab
containing the metadata for the features (metabolites), such as KEGG ID,
pathway, retention time, etc.
By defining the numerator and denominator as part of the
Input_SettingsInfo parameter, it is defined which
comparisons are performed:
1. one_vs_one (single comparison):
numerator=“Condition1”, denominator =“Condition2”
2. all_vs_one (multiple comparison): numerator=NULL,
denominator =“Condition”
3. all_vs_all (multiple comparison): numerator=NULL,
denominator =NULL (=default)
Noteworthy, if you have not performed missing value imputation and hence
your data includes NAs or 0 values for some features, this is how we
deal with this in the DMA() function:
1. If you use the parameter STAT_pval="lmFit", limma is
performed. Limma does a baesian fit of the data and substracts
Mean(Condition1 fit) - Mean(Condition2 fit). As such, unless all values
of a feature are NA, Limma can deal with NAs. 2. Standard Log2FC:
log2(Mean(Condition1)) - log2(Mean(Condition2)) a. If all values of the
replicates of one condition are NA/0 for a feature (=metabolite):
Log2FC= Inf/-Inf and the statistics will be NA
b. If some values of the replicates of one condition are NA/0 for a
feature (=metabolite): Log2FC= positive or negative value, but the
statistics will be NA
It is important to mention that in case of
STAT_pval="lmFit", we perform log2 transformation of the
data as prior to running limma to enable the calculation of the log2FC,
hence do not provide log2 transformed data.
Here, the example data we have four different cell lines, healthy (HK2)
and cancer (ccRCC: 786-M1A, 786-M2A and 786-O), hence we can perform
multiple different comparisons. The results can be automatically saved
and all the results are returned in a list with the different data
frames. If parameter Plot=TRUE, an overview Volcano plot is generated
and saved.
# Perform multiple comparison All_vs_One using annova:
DMA_Annova <- MetaProViz::DMA(InputData=Intra_Preprocessed[,-c(1:3)], #we need to remove columns that do not include metabolite measurements
SettingsFile_Sample=Intra_Preprocessed[,c(1:3)],#only maintain the information about condition and replicates
SettingsInfo = c(Conditions="Conditions", Numerator=NULL , Denominator = "HK2"),# we compare all_vs_HK2
SettingsFile_Metab = MappingInfo,# Adds metadata for the metabolites such as KEGG_ID, Pathway, retention time,...
StatPval ="aov",
StatPadj="fdr")
#Inspect the DMA results tables:
DMA_786M1A_vs_HK2 <- DMA_Annova[["DMA"]][["786-M1A_vs_HK2"]]
Shapiro <- DMA_Annova[["ShapiroTest"]][["DF"]][["Shapiro_result"]]#> There are no NA/0 values
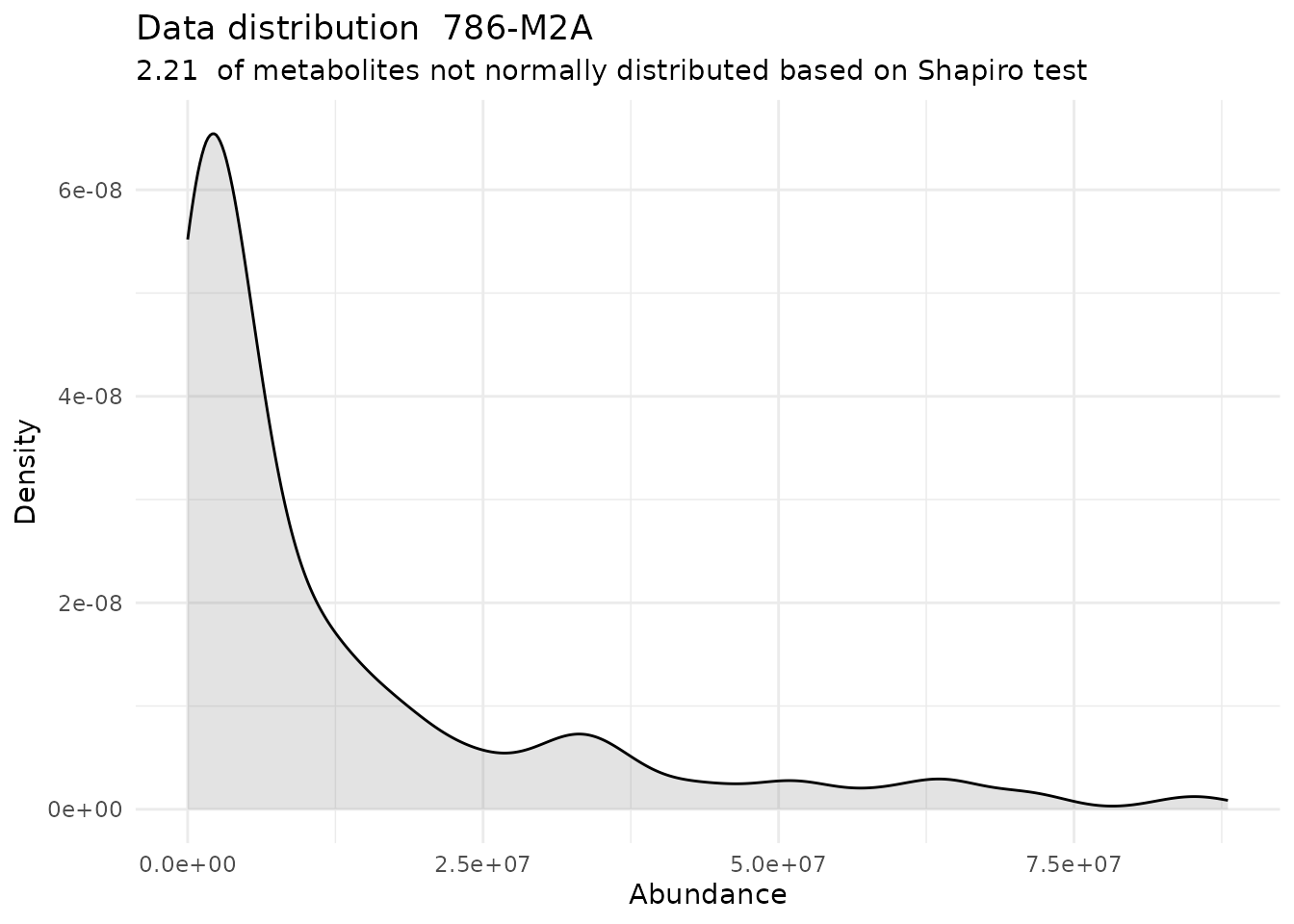
#> For the condition 786-M1A 94.41 % of the metabolites follow a normal distribution and 5.59 % of the metabolites are not-normally distributed according to the shapiro test. You have chosen aov, which is for parametric Hypothesis testing. `shapiro.test` ignores missing values in the calculation.
#> For the condition 786-M2A 97.79 % of the metabolites follow a normal distribution and 2.21 % of the metabolites are not-normally distributed according to the shapiro test. You have chosen aov, which is for parametric Hypothesis testing. `shapiro.test` ignores missing values in the calculation.
#> For the condition 786-O 95.03 % of the metabolites follow a normal distribution and 4.97 % of the metabolites are not-normally distributed according to the shapiro test. You have chosen aov, which is for parametric Hypothesis testing. `shapiro.test` ignores missing values in the calculation.
#> For the condition HK2 96.13 % of the metabolites follow a normal distribution and 3.87 % of the metabolites are not-normally distributed according to the shapiro test. You have chosen aov, which is for parametric Hypothesis testing. `shapiro.test` ignores missing values in the calculation.
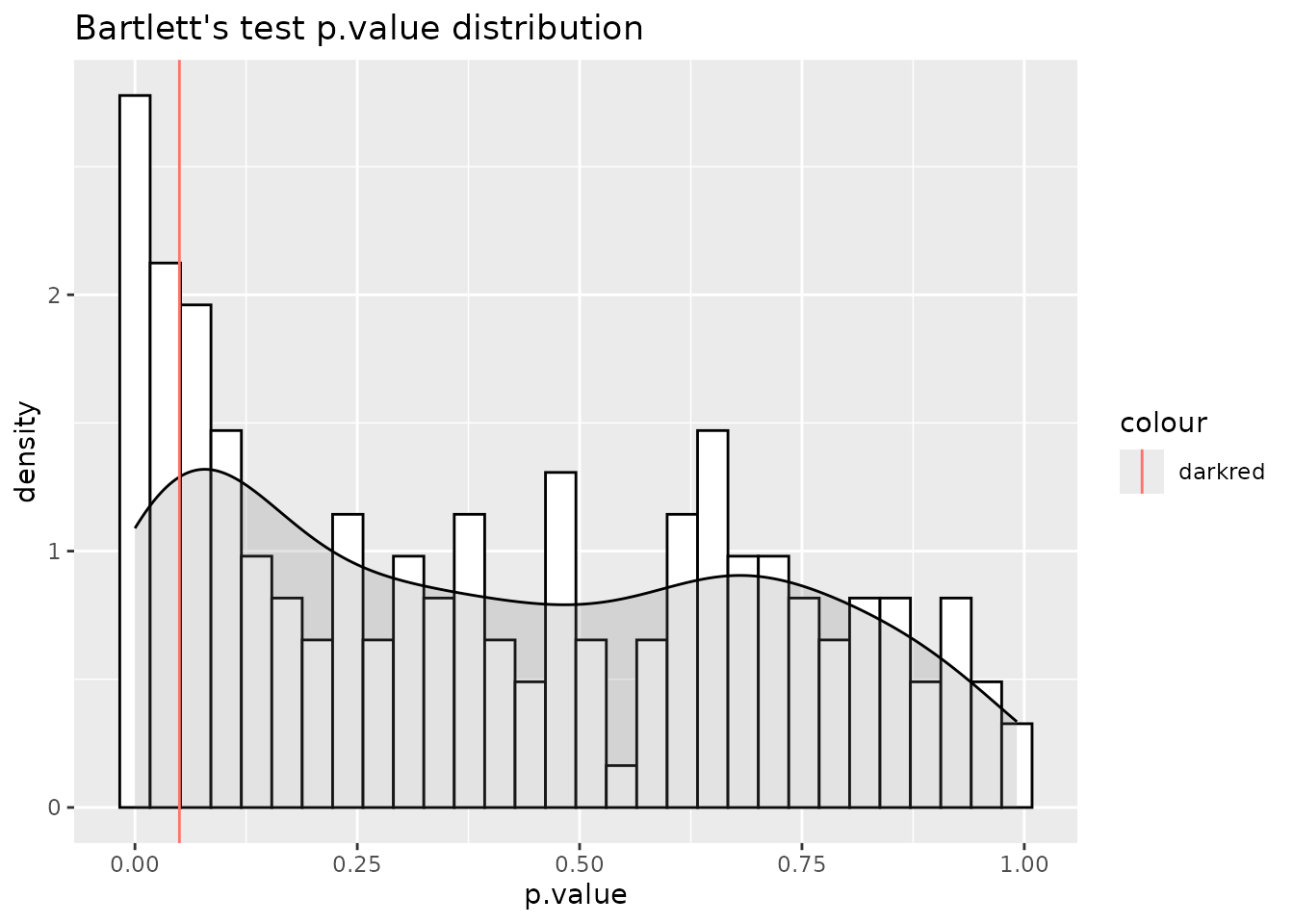
#> For 83.24% of metabolites the group variances are equal.
#> No condition was specified as numerator and HK2 was selected as a denominator. Performing multiple testing `all-vs-one` using aov.


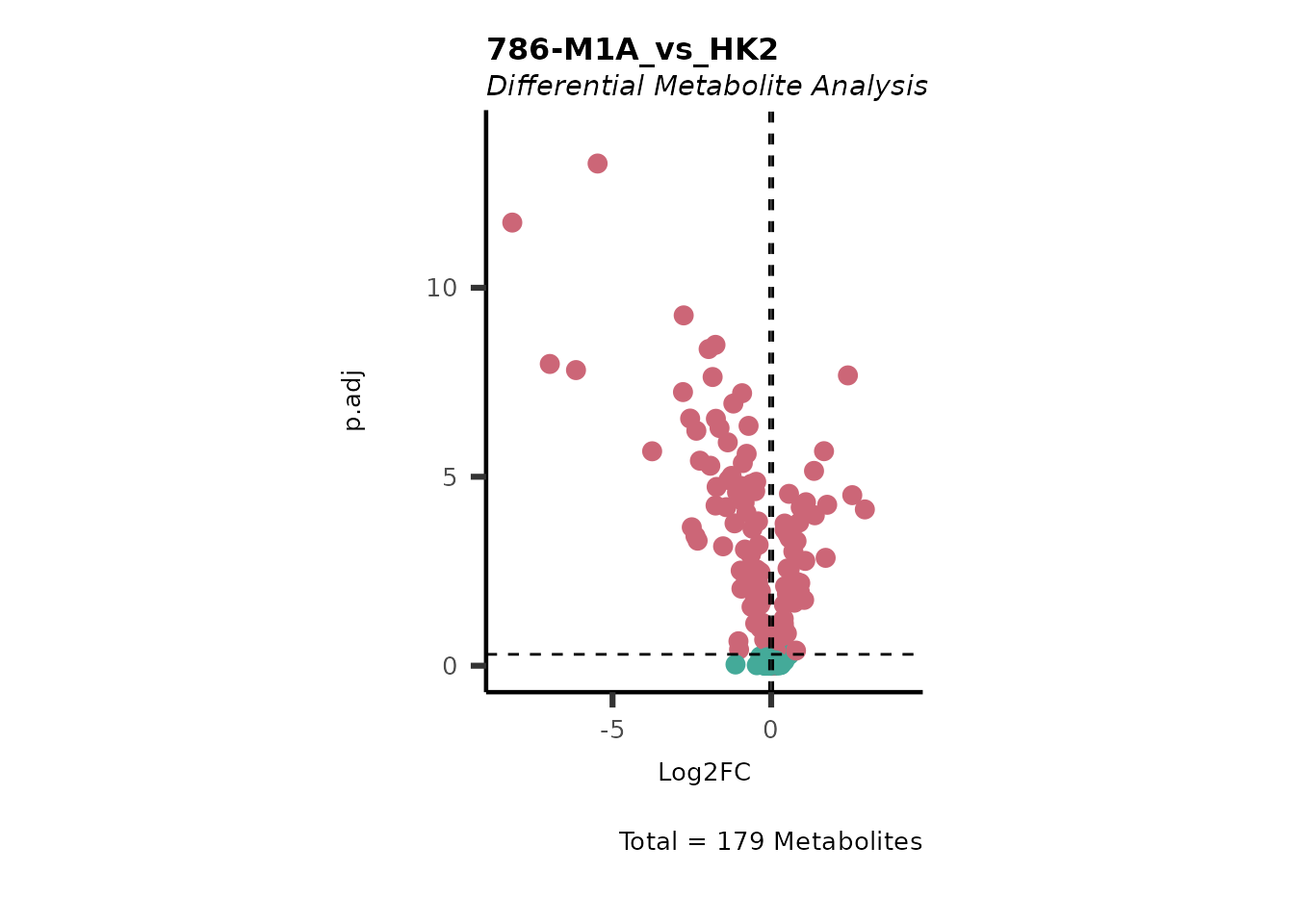
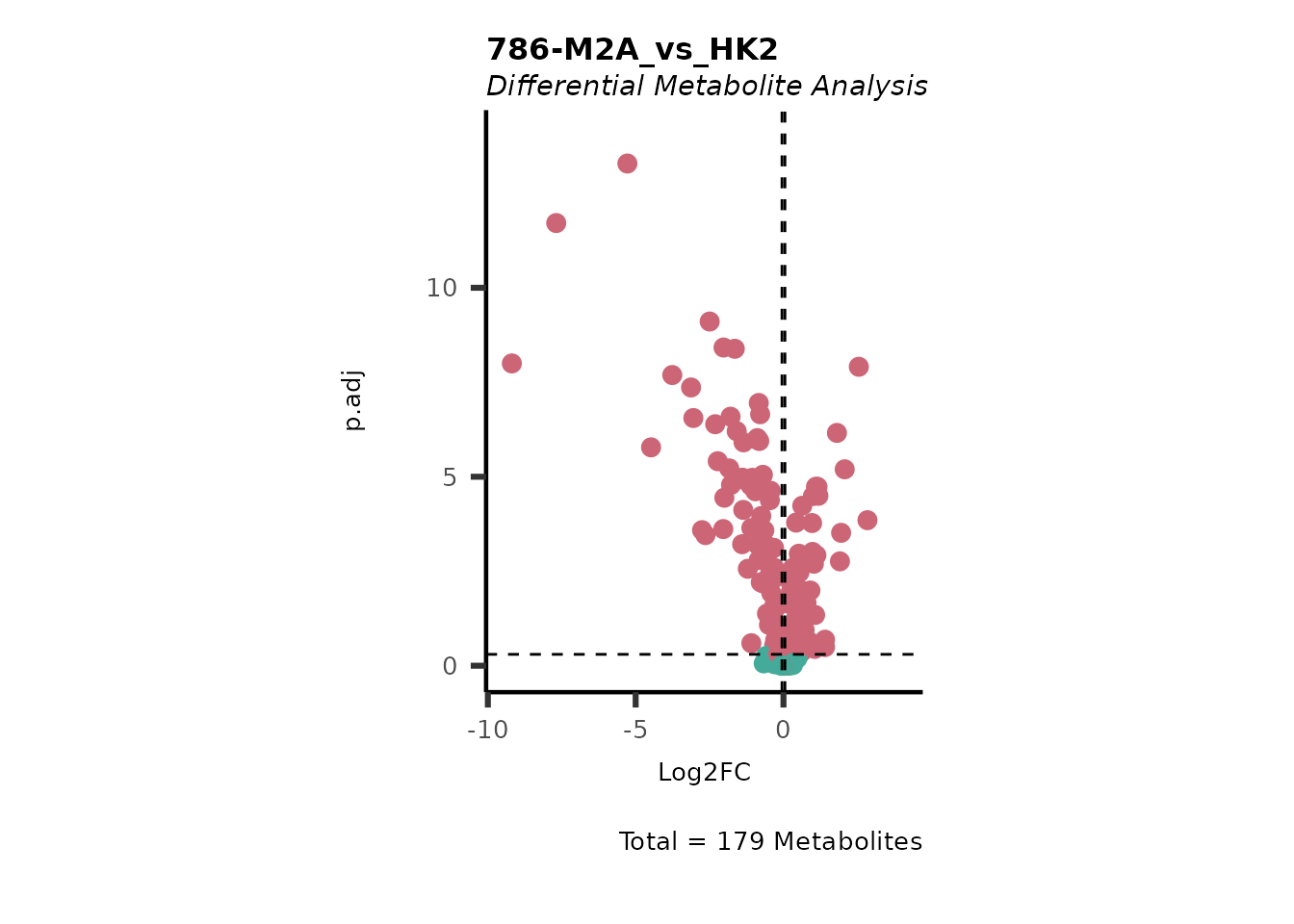
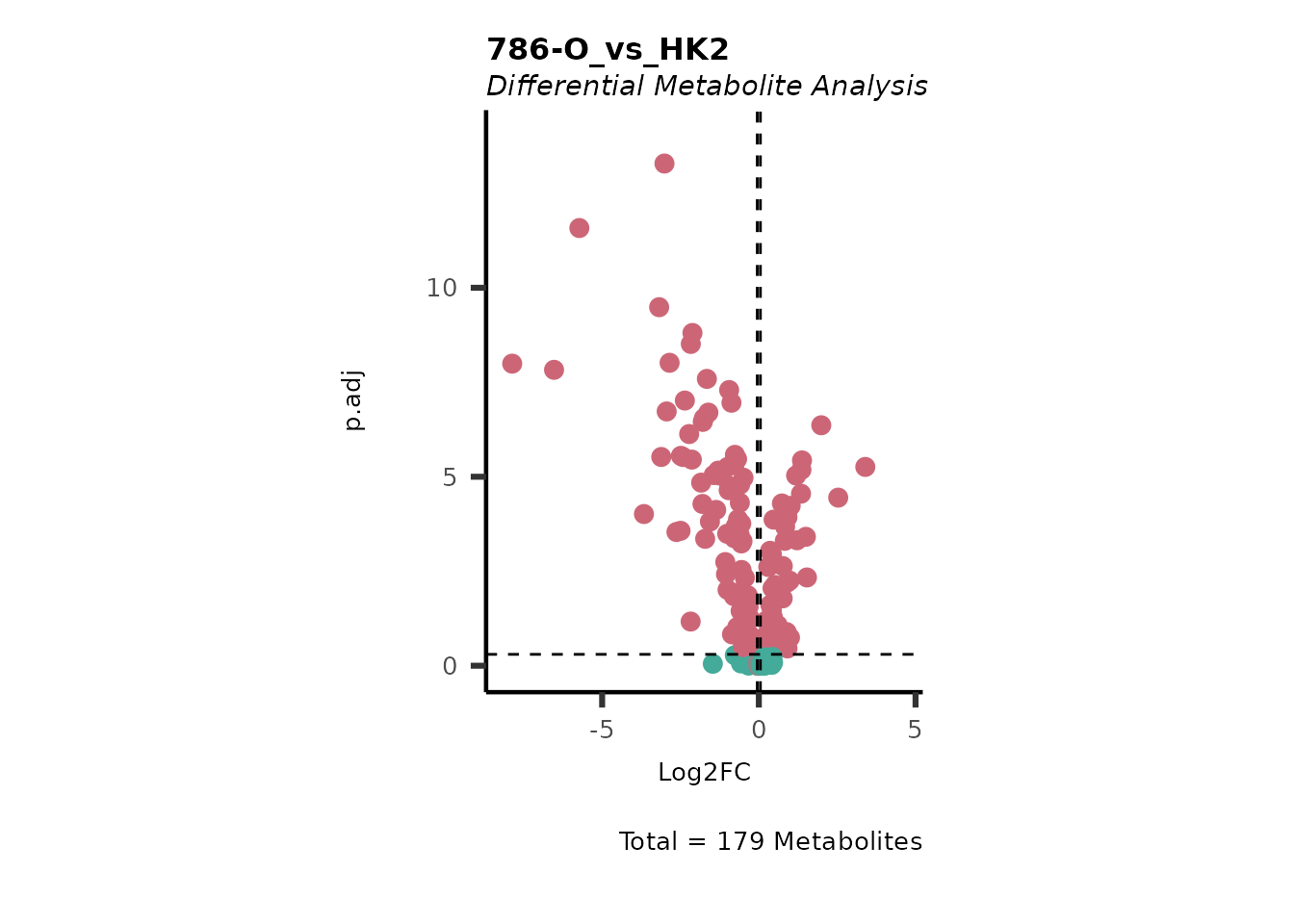
| Code | Metabolites with normal distribution [%] | Metabolites with not-normal distribution [%] | Shapiro p.val(valine-d8) | Shapiro p.val(hippuric acid-d5) | Shapiro p.val(2/3-phosphoglycerate) |
|---|---|---|---|---|---|
| 786-M1A | 94.41 | 5.59 | 0.8523002 | 0.5818282 | 0.4219607 |
| 786-M2A | 97.79 | 2.21 | 0.4748815 | 0.6406826 | 0.8924641 |
| 786-O | 95.03 | 4.97 | 0.7789735 | 0.7821734 | 0.2773603 |
| HK2 | 96.13 | 3.87 | 0.1736777 | 0.0790043 | 0.9247262 |
| Metabolite | Log2FC | p.adj | t.val | 786-M1A_1 | 786-M1A_2 | 786-M1A_3 | HK2_1 | HK2_2 | HK2_3 | HMDB | KEGG.ID | KEGGCompound | Pathway |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5-aminolevulinic acid | -0.1777271 | 0.4915165 | 525130.26 | 3774613 | 3938304 | 4303746 | 4028435 | 4373207 | 5190412 | HMDB0001149 | C00430 | 5-Aminolevulinate | Not assigned |
| 5-methylthioadenosine (MTA) | -0.5027548 | 0.0763874 | 7369026.23 | 13467707 | 19486388 | 20071094 | 24864886 | 22428867 | 27838513 | HMDB0001173 | C00170 | 5’-Methylthioadenosine | Cysteine and methionine metabolism |
| acetyl-CoA | -0.0089685 | 0.9999312 | 16711.52 | 2924310 | 2186801 | 2928606 | 2894329 | 2296944 | 2898579 | HMDB0001206 | C00024 | Acetyl-CoA | Citrate cycle (TCA cycle) |
| acetylcarnitine | 0.0653289 | 0.9951478 | -194906873.29 | 4022430586 | 3567130318 | 5617724322 | 5947039758 | 3143517363 | 3532007486 | HMDB0000201 | C02571 | O-Acetylcarnitine | Fatty acyl carnitines |
| aconitate | 0.9032263 | 0.0109616 | -46075390.99 | 87829577 | 93936706 | 115296044 | 66710215 | 42899324 | 49226614 | HMDB0000072 | C00417 | cis-Aconitate | Citrate cycle (TCA cycle) |
Using the DMA results, we can now use the MetaProViz
visualization module and generate further customized Volcano plots
VizVolcano(). You can see some examples below.
ORA using the DMA results
Over Representation Analysis (ORA) is a pathway enrichment analysis
(PEA) method that determines if a set of features (=metabolic pathways)
are over-represented in the selection of features (=metabolites) from
the data in comparison to all measured features (metabolites) using the
Fishers exact test. The selection of metabolites are usually the most
altered metabolites in the data, which can be selected by the top and
bottom t-values.
Of course, there are many other PEA methods such as the well known GSEA.
Here we do not aim to provide an extensive tool for different methods to
perform pathway enrichment analysis and only focus on ORA since we can
apply this to perform standard pathway enrichment as well as pathway
enrichment on clusters of metabolites (see MCA below). If you are
interested in using different pathway enrichment methods please check
out specialized tools such as decopupleR (Badia-I-Mompel et al. 2022).
Here we will use the KEGG pathways (Kanehisa and
Goto 2000). Before we can perform ORA on the DMA results, we have
to ensure that the metabolite names match with the KEGG IDs or KEGG
trivial names. In general, the PathwayFile requirements are
column “term”, “Metabolite” and “Description”, and the
Input_data requirements are column “t.val” and column
“Metabolite”.
#Since we have performed multiple comparisons (all_vs_HK2), we will run ORA for each of this comparison
DM_ORA_res<- list()
comparisons <- names(DMA_Annova[["DMA"]])
for(comparison in comparisons){
#Ensure that the Metabolite names match with KEGG IDs or KEGG trivial names.
DMA <- DMA_Annova[["DMA"]][[comparison]]
DMA <- DMA[complete.cases(DMA),-1]%>%#we remove metabolites that do not have a KEGG ID/KEGG pathway
dplyr::rename("Metabolite"="KEGGCompound")#We use the KEGG trivial names to match with the KEGG pathways
#Perform ORA
DM_ORA_res[[comparison]] <- MetaProViz::StandardORA(InputData= DMA%>%remove_rownames()%>%tibble::column_to_rownames("Metabolite"), #Input data requirements: column `t.val` and column `Metabolite`
SettingsInfo=c(pvalColumn="p.adj", PercentageColumn="t.val", PathwayTerm= "term", PathwayFeature= "Metabolite"),
PathwayFile=KEGG_Pathways,#Pathway file requirements: column `term`, `Metabolite` and `Description`. Above we loaded the Kegg_Pathways using MetaProViz::Load_KEGG()
PathwayName="KEGG",
minGSSize=3,
maxGSSize=1000,
pCutoff=0.01,
PercentageCutoff=10)
}
#>
#Lets check how the results look like:
DM_ORA_786M1A_vs_HK2 <- DM_ORA_res[["786-M1A_vs_HK2"]][["ClusterGoSummary"]]| GeneRatio | BgRatio | pvalue | p.adjust | qvalue | Metabolites_in_pathway | Count | Metabolites_in_Pathway | Percentage_of_Pathway_detected |
|---|---|---|---|---|---|---|---|---|
| 12/25 | 32/129 | 0.0043514 | 0.2210152 | 0.2035666 | Betaine/Glutathione/Hydroxyproline/L-Alanine/L-Aspartate/L-Glutamate/L-Histidine/L-Leucine/L-Proline/L-Threonine/myo-Inositol/Taurine | 12 | 130 | 9.23 |
| 8/25 | 18/129 | 0.0078934 | 0.2210152 | 0.2035666 | 2-Oxoglutarate/Hydroxyproline/L-Alanine/L-Aspartate/L-Glutamate/L-Histidine/L-Proline/L-Threonine | 8 | 69 | 11.59 |
| 4/25 | 6/129 | 0.0129138 | 0.2410577 | 0.2220268 | 2-Oxoglutarate/L-Aspartate/L-Glutamate/L-Histidine | 4 | 47 | 8.51 |
| 6/25 | 14/129 | 0.0295646 | 0.3613164 | 0.3327915 | 2-Oxoglutarate/Citrate/L-Alanine/L-Aspartate/L-Glutamate/N-Acetyl-L-aspartate | 6 | 27 | 22.22 |
| 7/25 | 19/129 | 0.0441107 | 0.3613164 | 0.3327915 | L-Alanine/L-Aspartate/L-Glutamate/L-Histidine/L-Leucine/L-Proline/L-Threonine | 7 | 52 | 13.46 |
MCA
Metabolite Clustering Analysis (MCA) is a module, which
includes different functions to enable clustering of metabolites into
groups either based on logical regulatory rules. This can be
particularly useful if one has multiple conditions and aims to find
patterns in the data.
MCA-2Cond
This metabolite clustering method is based on the Regulatory
Clustering Method (RCM) that was developed as part of the Signature
Regulatory Clustering (SiRCle) model (Mora et al.
(2022)). As part of the SiRCleR
package, also variation of the initial RCM method are proposed as
clustering based on two comparisons (e.g. KO versus WT in hypoxia and in
normoxia).
Here we set two different thresholds, one for the differential
metabolite abundance (Log2FC) and one for the
significance (e.g. p.adj). This will define if a feature (=
metabolite) is assigned into:
1. “UP”, which means a metabolite is
significantly up-regulated in the underlying comparison.
2. “DOWN”, which means a metabolite is
significantly down-regulated in the underlying comparison.
3. “No Change”, which means a metabolite does
not change significantly in the underlying comparison and/or is not
defined as up-regulated/down-regulated based on the Log2FC threshold
chosen.
Therebye “No Change” is further subdivided into four states:
1. “Not Detected”, which means a metabolite is
not detected in the underlying comparison.
2. “Not Significant”, which means a metabolite
is not significant in the underlying comparison.
3. “Significant positive”, which means a
metabolite is significant in the underlying comparison and the
differential metabolite abundance is positive, yet does not meet the
threshold set for “UP” (e.g. Log2FC >1 = “UP” and we have a
significant Log2FC=0.8).
4. “Significant negative”, which means a
metabolite is significant in the underlying comparison and the
differential metabolite abundance is negative, yet does not meet the
threshold set for “DOWN”.
This definition is done individually for each comparison and will impact
in which metabolite cluster a metabolite is sorted into.
Since we have two comparisons, we can choose between different
Background settings, which defines which features will be considered for
the clusters (e.g. you could include only features (= metabolites) that
are detected in both comparisons, removing the rest of the features).The
background methods backgroundMethod are the following from
1.1. - 1.4. from most restrictive to least
restrictive:
1.1. C1&C2: Most stringend background
setting and will lead to a small number of metabolites.
1.2. C1: Focus is on the metabolite abundance
of Condition 1 (C1).
1.3. C2: Focus is on the metabolite abundance
of Condition 2 (C2).
1.4. C1|C2: Least stringent background method,
since a metabolite will be included in the input if it has been detected
on one of the two conditions.
Lastly, we will get clusters of metabolites that are defined by the
metabolite change in the two conditions. For example, if Alanine is “UP”
based on the thresholds in both comparisons it will be sorted into the
cluster “Core_UP”. As there are two 6-state6 transitions between the
comparisons, the flows are summarised into smaller amount of metabolite
clusters using different Regulation Groupings (RG): 1. RG1_All
2. RG2_Significant taking into account genes that are significant (UP,
DOWN, significant positive, significant negative)
3. RG3_SignificantChange only takes into account genes that have
significant changes (UP, DOWN).
#Example of all possible flows:
MCA_2Cond <- MetaProViz::MCA_rules(Method="2Cond")| Cond1 | Cond2 | RG1_All | RG2_Significant | RG3_SignificantChange |
|---|---|---|---|---|
| DOWN | DOWN | Cond1 DOWN + Cond2 DOWN | Core_DOWN | Core_DOWN |
| DOWN | Not Detected | Cond1 DOWN + Cond2 Not Detected | Cond1_DOWN | Cond1_DOWN |
| DOWN | Not Significant | Cond1 DOWN + Cond2 Not Significant | Cond1_DOWN | Cond1_DOWN |
| DOWN | Significant Negative | Cond1 DOWN + Cond2 Significant Negative | Core_DOWN | Cond1_DOWN |
| DOWN | Significant Positive | Cond1 DOWN + Cond2 Significant Positive | Opposite | Cond1_DOWN |
| DOWN | UP | Cond1 DOWN + Cond2 UP | Opposite | Opposite |
| UP | DOWN | Cond1 UP + Cond2 DOWN | Opposite | Opposite |
| UP | Not Detected | Cond1 UP + Cond2 Not Detected | Cond1_UP | Cond1_UP |
| UP | Not Significant | Cond1 UP + Cond2 Not Significant | Cond1_UP | Cond1_UP |
| UP | Significant Negative | Cond1 UP + Cond2 Significant Negative | Opposite | Cond1_UP |
| UP | Significant Positive | Cond1 UP + Cond2 Significant Positive | Core_UP | Cond1_UP |
| UP | UP | Cond1 UP + Cond2 UP | Core_UP | Core_UP |
| Not Detected | DOWN | Cond1 Not Detected + Cond2 DOWN | Cond2_DOWN | Cond2_DOWN |
| Not Detected | Not Detected | Cond1 Not Detected + Cond2 Not Detected | None | None |
| Not Detected | Not Significant | Cond1 Not Detected + Cond2 Not Significant | None | None |
| Not Detected | Significant Negative | Cond1 Not Detected + Cond2 Significant Negative | None | None |
| Not Detected | Significant Positive | Cond1 Not Detected + Cond2 Significant Positive | None | None |
| Not Detected | UP | Cond1 Not Detected + Cond2 UP | Cond2_UP | Cond2_UP |
| Significant Negative | DOWN | Cond1 Significant Negative + Cond2 DOWN | Core_DOWN | Cond2_DOWN |
| Significant Negative | Not Detected | Cond1 Significant Negative + Cond2 Not Detected | None | None |
| Significant Negative | Not Significant | Cond1 Significant Negative + Cond2 Not Significant | None | None |
| Significant Negative | Significant Negative | Cond1 Significant Negative + Cond2 Significant Negative | None | None |
| Significant Negative | Significant Positive | Cond1 Significant Negative + Cond2 Significant Positive | None | None |
| Significant Negative | UP | Cond1 Significant Negative + Cond2 UP | Opposite | Cond2_UP |
| Significant Positive | DOWN | Cond1 Significant Positive + Cond2 DOWN | Opposite | Cond2_DOWN |
| Significant Positive | Not Detected | Cond1 Significant Positive + Cond2 Not Detected | None | None |
| Significant Positive | Not Significant | Cond1 Significant Positive + Cond2 Not Significant | None | None |
| Significant Positive | Significant Negative | Cond1 Significant Positive + Cond2 Significant Negative | None | None |
| Significant Positive | Significant Positive | Cond1 Significant Positive + Cond2 Significant Positive | None | None |
| Significant Positive | UP | Cond1 Significant Positive + Cond2 UP | Core_UP | Cond2_UP |
| Not Significant | DOWN | Cond1 Not Significant + Cond2 DOWN | Cond2_DOWN | Cond2_DOWN |
| Not Significant | Not Detected | Cond1 Not Significant + Cond2 Not Detected | None | None |
| Not Significant | Not Significant | Cond1 Not Significant + Cond2 Not Significant | None | None |
| Not Significant | Significant Negative | Cond1 Not Significant + Cond2 Significant Negative | None | None |
| Not Significant | Significant Positive | Cond1 Not Significant + Cond2 Significant Positive | None | None |
| Not Significant | UP | Cond1 Not Significant + Cond2 UP | Cond1_UP | Cond1_UP |
Now let’s use the data and do clustering:
MCAres <- MetaProViz::MCA_2Cond(InputData_C1=DMA_Annova[["DMA"]][["786-O_vs_HK2"]],
InputData_C2=DMA_Annova[["DMA"]][["786-M1A_vs_HK2"]],
SettingsInfo_C1=c(ValueCol="Log2FC",StatCol="p.adj", StatCutoff= 0.05, ValueCutoff=1),
SettingsInfo_C2=c(ValueCol="Log2FC",StatCol="p.adj", StatCutoff= 0.05, ValueCutoff=1),
FeatureID = "Metabolite",
SaveAs_Table = "csv",
BackgroundMethod="C1&C2",
FolderPath=NULL)
# Check how our data looks like:
ClusterSummary <- MCAres[["MCA_2Cond_Summary"]]| Regulation Grouping | SiRCle cluster Name | Number of Features |
|---|---|---|
| RG2_Significant | Cond1_DOWN | 3 |
| RG2_Significant | Cond2_UP | 2 |
| RG2_Significant | Core_DOWN | 33 |
| RG2_Significant | Core_UP | 13 |
| RG2_Significant | None | 128 |
| RG3_SignificantChange | Cond1_DOWN | 7 |
| RG3_SignificantChange | Cond1_UP | 2 |
| RG3_SignificantChange | Cond2_DOWN | 3 |
| RG3_SignificantChange | Cond2_UP | 4 |
| RG3_SignificantChange | Core_DOWN | 26 |
| RG3_SignificantChange | Core_UP | 9 |
| RG3_SignificantChange | None | 128 |
ORA on each metabolite cluster
As explained in detail above, Over Representation Analysis (ORA) is a pathway enrichment analysis (PEA) method. As ORA is based on the Fishers exact test it is perfect to test if a set of features (=metabolic pathways) are over-represented in the selection of features (= clusters of metabolites) from the data in comparison to all measured features (all metabolites). In detail,MC_ORA() will perform ORA on
each of the metabolite clusters using all metabolites as the background.
| HMDB | KEGG.ID | KEGGCompound | Pathway | |
|---|---|---|---|---|
| N-acetylaspartate | HMDB0000812 | C01042 | N-Acetyl-L-aspartate | Alanine, aspartate and glutamate metabolism |
| argininosuccinate | HMDB0000052 | C03406 | N-(L-Arginino)succinate | Alanine, aspartate and glutamate metabolism |
| N-acetylaspartylglutamate | HMDB0001067 | C12270 | N-Acetylaspartylglutamate | Alanine, aspartate and glutamate metabolism |
| tyrosine | HMDB0000158 | C00082 | L-Tyrosine | Amino acid metabolism |
| asparagine | HMDB0000168 | C00152 | L-Asparagine | Amino acid metabolism |
| glutamate | HMDB0000148 | C00025 | L-Glutamate | Amino acid metabolism |
3. Run MetaProViz Visualisation
The big advantages of the MetaProViz visualization
module is its flexible and easy usage, which we will showcase below and
that the figures are saved in a publication ready style and format. For
instance, the x- and y-axis size will always be adjusted for the amount
of samples or features (=metabolites) plotted, or in the case of Volcano
plot and PCA plot the axis size is fixed and not affected by figure
legends or title. In this way, there is no need for many adjustments and
the figures can just be dropped into the presentation or paper and are
all in the same style.
All the VizPlotName() functions are constructed in the same
way. Indeed, with the parameter Plot_SettingsInfo the user
can pass a named vector with information about the metadata column that
should be used to customize the plot by colour, shape or creating
individual plots, which will all be showcased for the different plot
types. Via the parameter Plot_SettingsFile the user can
pass the metadata DF, which can be dependent on the plot type for the
samples and/or the features (=metabolites). In case of both the
parameter is named Plot_SettingsFile_Sample and
Plot_SettingsFile_Metab.
In each of those Plot_Settings, the user can label color and/or shape
based on additional information (e.g. Pathway information, Cluster
information or other other demographics like gender). Moreover, we also
enable to plot individual plots where applicable based on those MetaData
(e.g. one plot for each metabolic pathway).
For this we need a metadata table including information about our
samples that could be relevant to e.g. color code:
MetaData_Sample <- Intra_Preprocessed[,c(1:2)]%>%
mutate(Celltype = case_when(Conditions=="HK2" ~ 'Healthy',
Conditions=="786-O" ~ 'Primary Tumour',
TRUE ~ 'Metastatic Tumour'))%>%
mutate(Status = case_when(Conditions=="HK2" ~ 'Healthy',
TRUE ~ 'Cancer'))| Conditions | Biological_Replicates | Celltype | Status | |
|---|---|---|---|---|
| 786-M1A_1 | 786-M1A | 1 | Metastatic Tumour | Cancer |
| 786-M1A_2 | 786-M1A | 2 | Metastatic Tumour | Cancer |
| 786-M1A_3 | 786-M1A | 3 | Metastatic Tumour | Cancer |
| 786-M2A_1 | 786-M2A | 1 | Metastatic Tumour | Cancer |
| 786-M2A_2 | 786-M2A | 2 | Metastatic Tumour | Cancer |
| 786-M2A_3 | 786-M2A | 3 | Metastatic Tumour | Cancer |
| 786-O_1 | 786-O | 1 | Primary Tumour | Cancer |
| 786-O_2 | 786-O | 2 | Primary Tumour | Cancer |
| 786-O_3 | 786-O | 3 | Primary Tumour | Cancer |
| HK2_1 | HK2 | 1 | Healthy | Healthy |
| HK2_2 | HK2 | 2 | Healthy | Healthy |
| HK2_3 | HK2 | 3 | Healthy | Healthy |
Moreover, we can use MetaData for our features (=Metabolites), which we
loaded with the MappingInfo and we can also add the
information on which cluster a metabolite was assigned to in the
MetaProViz::MCA() analysis above:
MetaData_Metab <-merge(MappingInfo%>%tibble::rownames_to_column("Metabolite"), MCAres[["MCA_2Cond_Results"]][,c(1, 14,15)], by="Metabolite", all.y=TRUE)%>%
tibble::column_to_rownames("Metabolite")| HMDB | KEGG.ID | KEGGCompound | Pathway | RG2_Significant | RG3_SignificantChange | |
|---|---|---|---|---|---|---|
| 2-ketoglutarate | HMDB0000208 | C00026 | 2-Oxoglutarate | Citrate cycle (TCA cycle) | Core_UP | Core_UP |
| 2/3-phosphoglycerate | HMDB0060180 | C00197 | 3-Phospho-D-glycerate | Glycolysis / Gluconeogenesis | None | None |
| 4-hydroxyphenyllactate | HMDB0000755 | C03672 | 3-(4-Hydroxyphenyl)lactate | Not assigned | None | None |
| ATP | HMDB0000538 | C00002 | ATP | Purine metabolism | None | None |
| beta-alanine | HMDB0000056 | C00099 | beta-Alanine | Pyrimidine metabolism | Core_DOWN | Core_DOWN |
| beta-citrylglutamic acid | HMDB0013220 | NA | NA | Not assigned | None | None |
Noteworthy, here we can also use the KEGG pathways we used for the
pathway analysis.
PCA plots
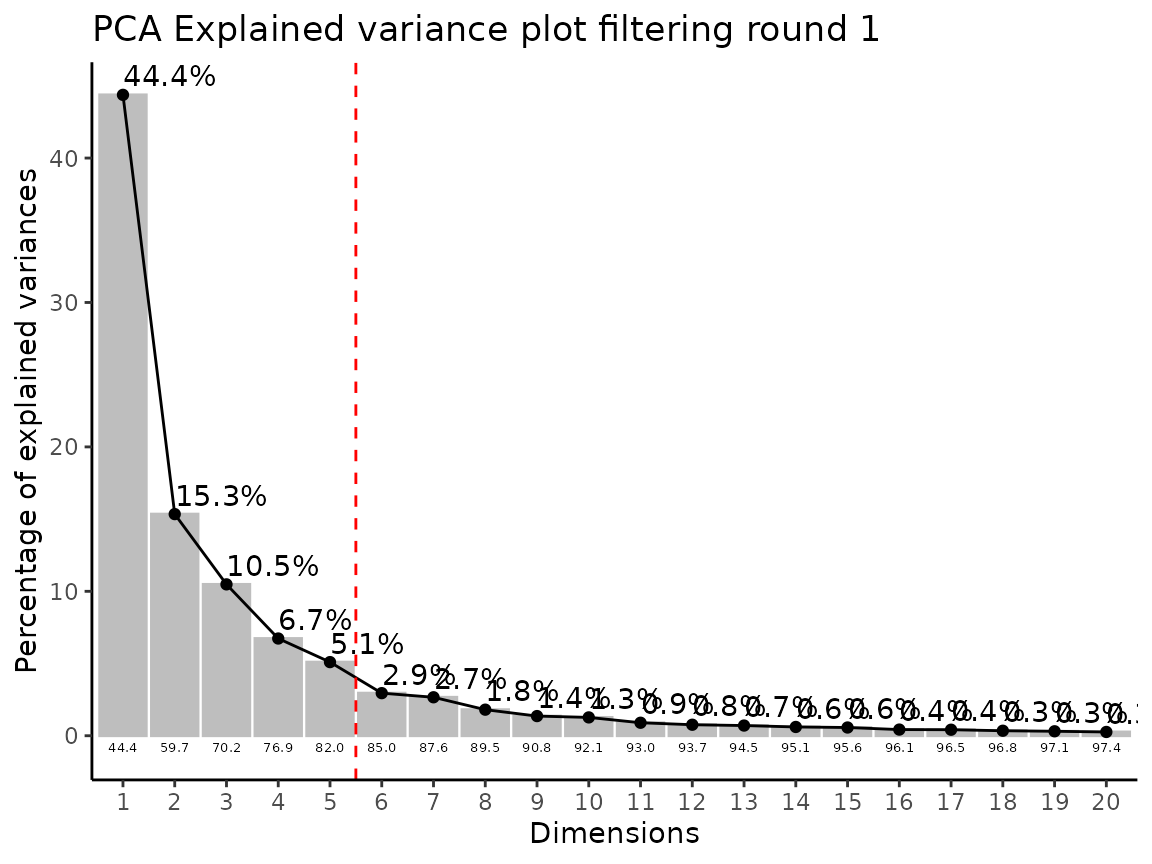
Principal component analysis (PCA) is a dimensionality reduction
method that reduces all the measured features (=metabolites) of one
sample into a few features in the different principal components,
whereby each principal component can explain a certain percentage of the
variance between the different samples. Hence, this enables
interpretation of sample clustering based on the measured features
(=metabolites).
As mentioned above, PCA plots can be quite useful for quality control,
but of course it offers us many more opportunities, which will be
showcased here.
As input, we need a DF that contains the samples as rownames and the
features (=metabolites) as column names:
Input_PCA <- Intra_Preprocessed[,-c(1:5)]#remove columns that include Metadata such as cell type,...| 2/3-phosphoglycerate | 2-aminoadipic acid | 2-hydroxyglutarate | 2-ketoglutarate | 4-guanidinobutanoate | 4-hydroxyphenyllactate | 5-aminolevulinic acid | |
|---|---|---|---|---|---|---|---|
| 786-M1A_1 | 56869710 | 7515755 | 424350094 | 959154968 | 1919685 | 2200691 | 3774613 |
| 786-M1A_2 | 48343621 | 7794629 | 432815728 | 979152171 | 1885079 | 2038710 | 3938304 |
| 786-M1A_3 | 45802902 | 7241957 | 417484370 | 1003428045 | 2000096 | 2205282 | 4303746 |
| 786-M2A_1 | 45783712 | 6136730 | 438371418 | 844281227 | 2623110 | 2253523 | 4109374 |
| 786-M2A_2 | 44241237 | 6228218 | 432236949 | 885890420 | 1980782 | 2334933 | 4097771 |
| 786-M2A_3 | 42973150 | 6389024 | 463135059 | 884908893 | 1478488 | 2226276 | 4767468 |
| 786-O_1 | 36932026 | 8968347 | 389934195 | 887922452 | 2390741 | 2000374 | 3273419 |
| 786-O_2 | 30493039 | 9089987 | 463318717 | 1057350518 | 2329025 | 2113869 | 3645631 |
| 786-O_3 | 29305326 | 9025706 | 407917219 | 1012290078 | 1695489 | 2193180 | 4122241 |
| HK2_1 | 30931592 | 5801816 | 188417805 | 326367919 | 4418820 | 3963104 | 4028435 |
| HK2_2 | 32564867 | 7322390 | 228825446 | 366703618 | 4133883 | 3971958 | 4373207 |
| HK2_3 | 29507162 | 7159140 | 251061831 | 459945537 | 4366242 | 4226693 | 5190412 |
Now lets check out the standard plot:
MetaProViz::VizPCA(InputData=Input_PCA)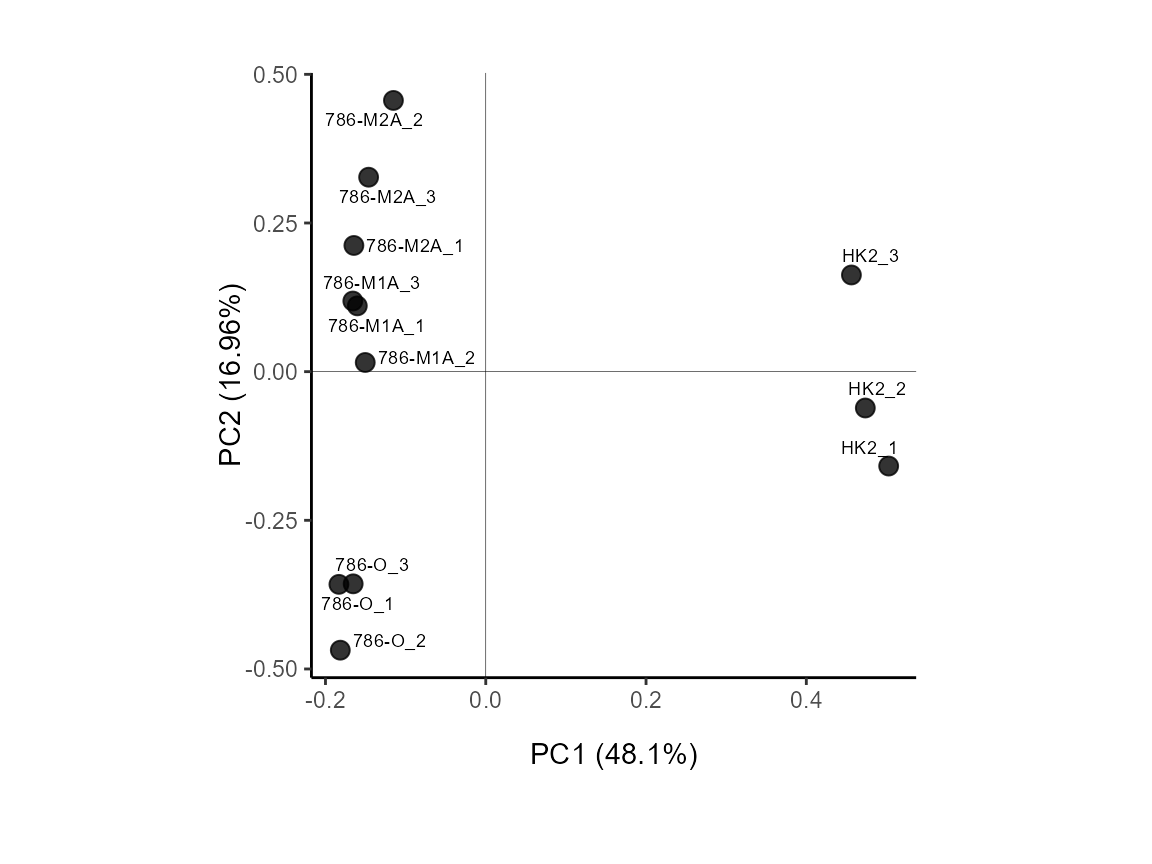
Figure: Standard Settings.
Next, we can interactively choose shape and color using the
additional information of interest from our Metadata. Especially for
complex data, such as patient data, it can be valuable to use different
demographics (e.g. age, gender, medication,…) for this. First lets check
if we have any batch effect by colour coding for the biological
replicates, which would be the case if the replicates cluster
together.
MetaProViz::VizPCA(SettingsInfo= c(color="Biological_Replicates"),
SettingsFile_Sample = MetaData_Sample ,
InputData=Input_PCA,
PlotName = "Batch Effect")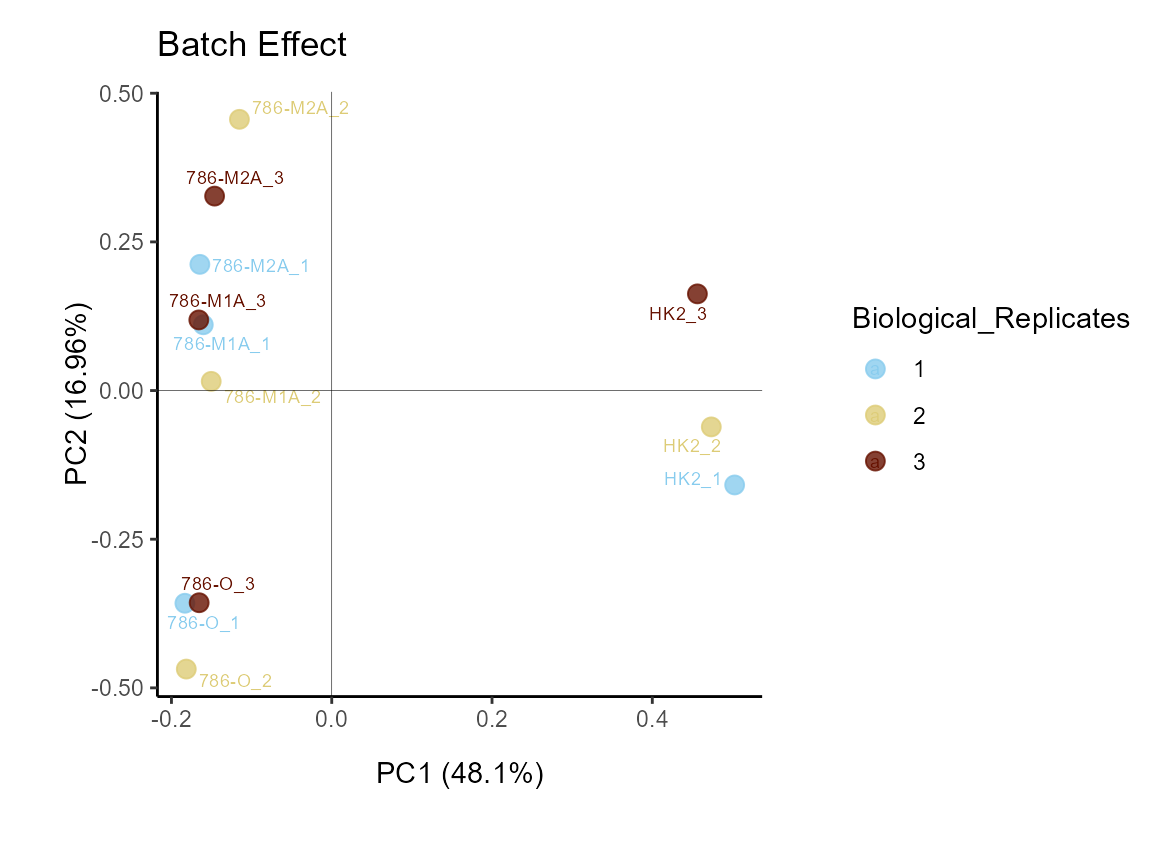
Figure: Do we have a batch effect?
Next, we can colour code for condition and use the biological
replicates in the shape parameter:
MetaProViz::VizPCA(SettingsInfo= c(color="Conditions", shape="Biological_Replicates"),
SettingsFile_Sample= MetaData_Sample,
InputData=Input_PCA,
PlotName = "Sample Conditions")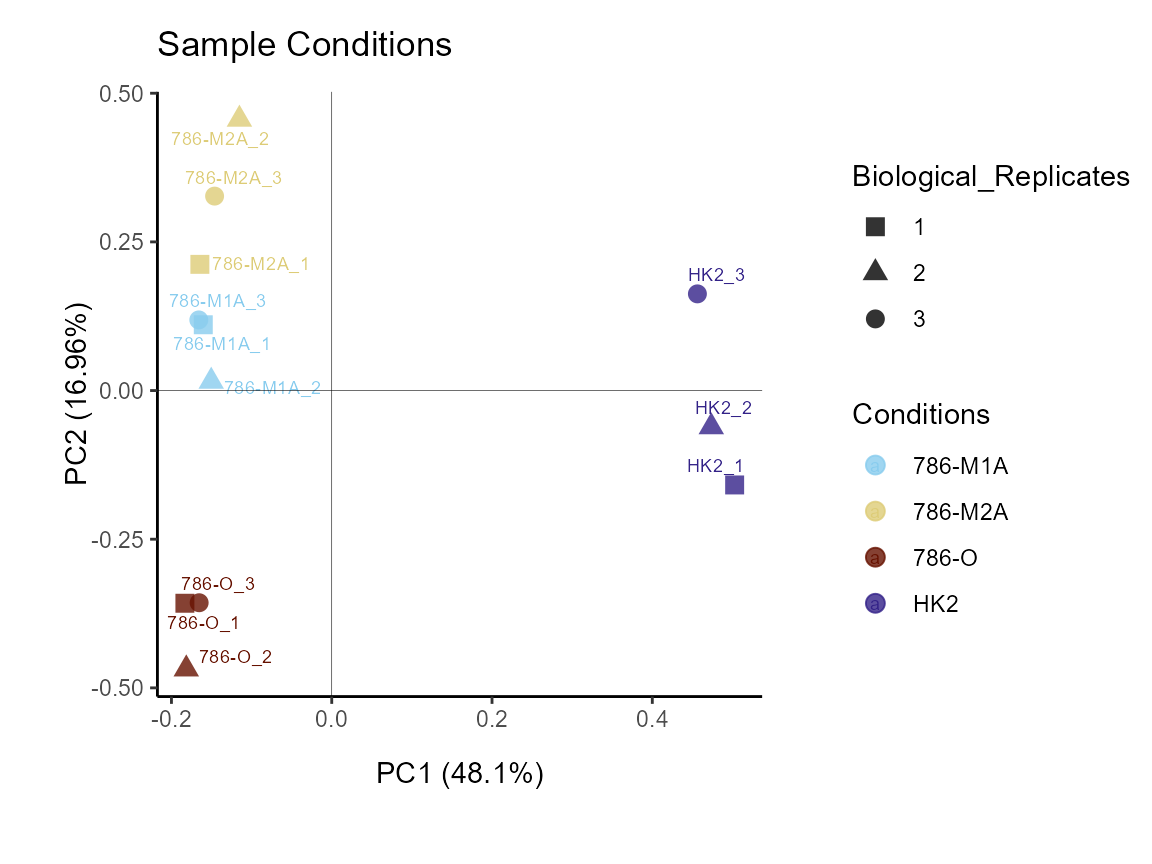
Figure: Do the samples cluster for the conditions?
The different cell lines we have are either control or cancerous, so
we can display this too. Here is becomes apparent that the cell status
is responsible for 64% of the variance (x-axis).
MetaProViz::VizPCA(SettingsInfo= c(color="Status"),
SettingsFile_Sample= MetaData_Sample,
InputData=Input_PCA,
PlotName = "Sample Status")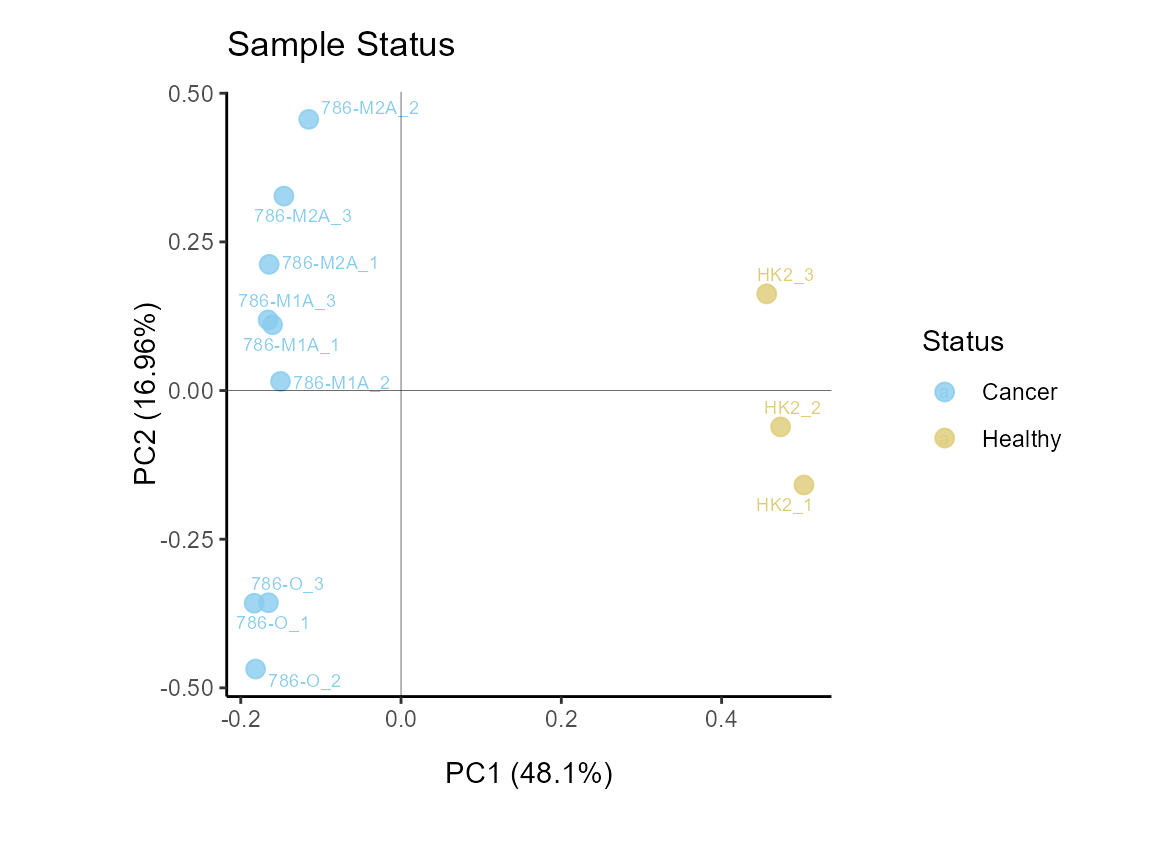
Figure: Do the samples cluster for the Cell status?
We can separate the cancerous cell lines further into metastatic or
primary. This shows us that this is separated on the y-axis and accounts
for 30%of the variance.
MetaProViz::VizPCA(SettingsInfo= c(color="Celltype", shape="Status"),
SettingsFile_Sample= MetaData_Sample,
InputData=Input_PCA,
PlotName = "Cell type")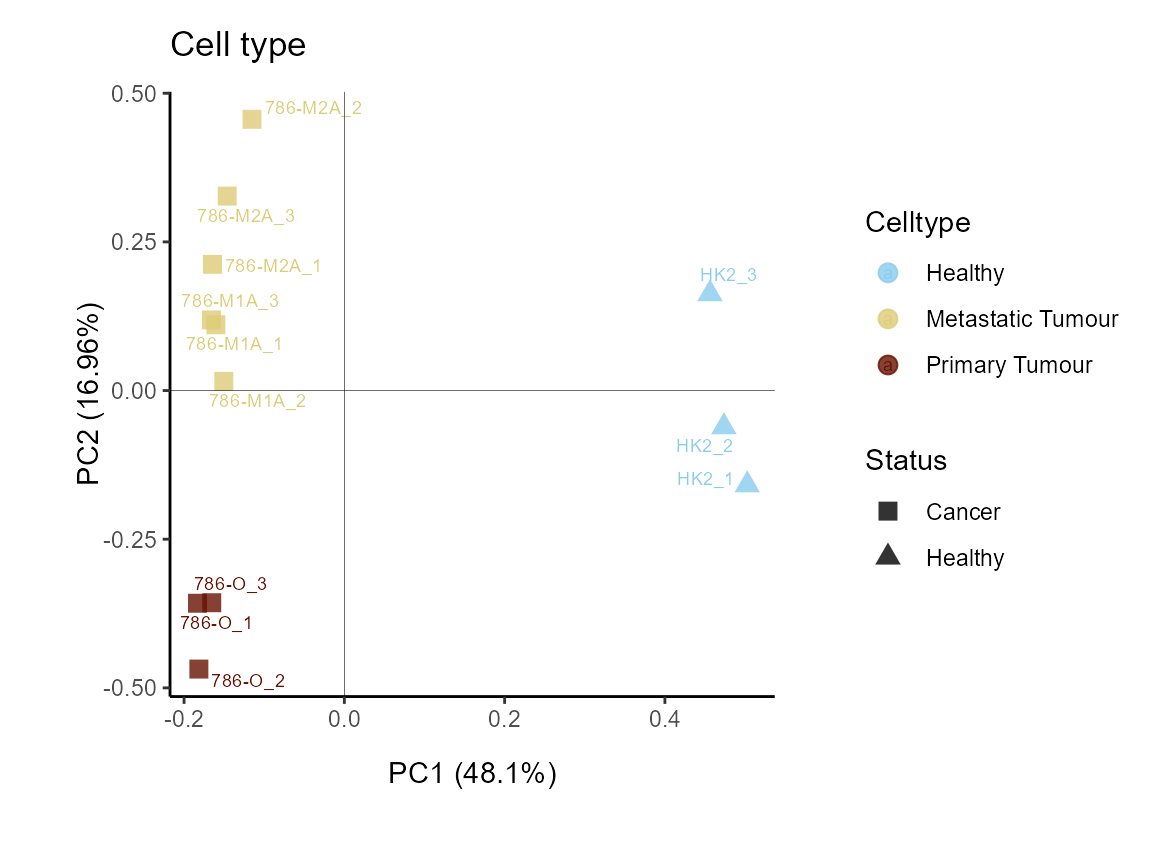
Figure: Do the samples cluster for the Cell type?
Lastly, its worth mentioning that one can also change many style parameters to customize the plot.
Heatmaps
Clustered heatmaps can be useful to understand the patterns in the
data, which will be showcased on different examples.
As input, we need a DF that contains the samples as rownames and the
features (=metabolites) as column names:
Input_Heatmap <- Intra_Preprocessed[,-c(1:4)]#remove columns that include Metadata such as cell type,...| hippuric acid-d5 | 2/3-phosphoglycerate | 2-aminoadipic acid | 2-hydroxyglutarate | 2-ketoglutarate | 4-guanidinobutanoate | 4-hydroxyphenyllactate | |
|---|---|---|---|---|---|---|---|
| 786-M1A_1 | 4624712907 | 56869710 | 7515755 | 424350094 | 959154968 | 1919685 | 2200691 |
| 786-M1A_2 | 4340353963 | 48343621 | 7794629 | 432815728 | 979152171 | 1885079 | 2038710 |
| 786-M1A_3 | 4214210391 | 45802902 | 7241957 | 417484370 | 1003428045 | 2000096 | 2205282 |
| 786-M2A_1 | 4796131050 | 45783712 | 6136730 | 438371418 | 844281227 | 2623110 | 2253523 |
| 786-M2A_2 | 3846160365 | 44241237 | 6228218 | 432236949 | 885890420 | 1980782 | 2334933 |
| 786-M2A_3 | 4164512249 | 42973150 | 6389024 | 463135059 | 884908893 | 1478488 | 2226276 |
| 786-O_1 | 3896527350 | 36932026 | 8968347 | 389934195 | 887922452 | 2390741 | 2000374 |
| 786-O_2 | 4496764782 | 30493039 | 9089987 | 463318717 | 1057350518 | 2329025 | 2113869 |
| 786-O_3 | 4137100133 | 29305326 | 9025706 | 407917219 | 1012290078 | 1695489 | 2193180 |
| HK2_1 | 3171399130 | 30931592 | 5801816 | 188417805 | 326367919 | 4418820 | 3963104 |
| HK2_2 | 3180479423 | 32564867 | 7322390 | 228825446 | 366703618 | 4133883 | 3971958 |
| HK2_3 | 3365930405 | 29507162 | 7159140 | 251061831 | 459945537 | 4366242 | 4226693 |
Now we can generate an overview heatmap. Since we plot all metabolites
the metabolite names are not plotted since this would get too crowded
(You can enforce this by changing the parameter
enforce_FeatureNames = TRUE).
MetaProViz::VizHeatmap(InputData = Input_Heatmap,
PlotName = "Overview")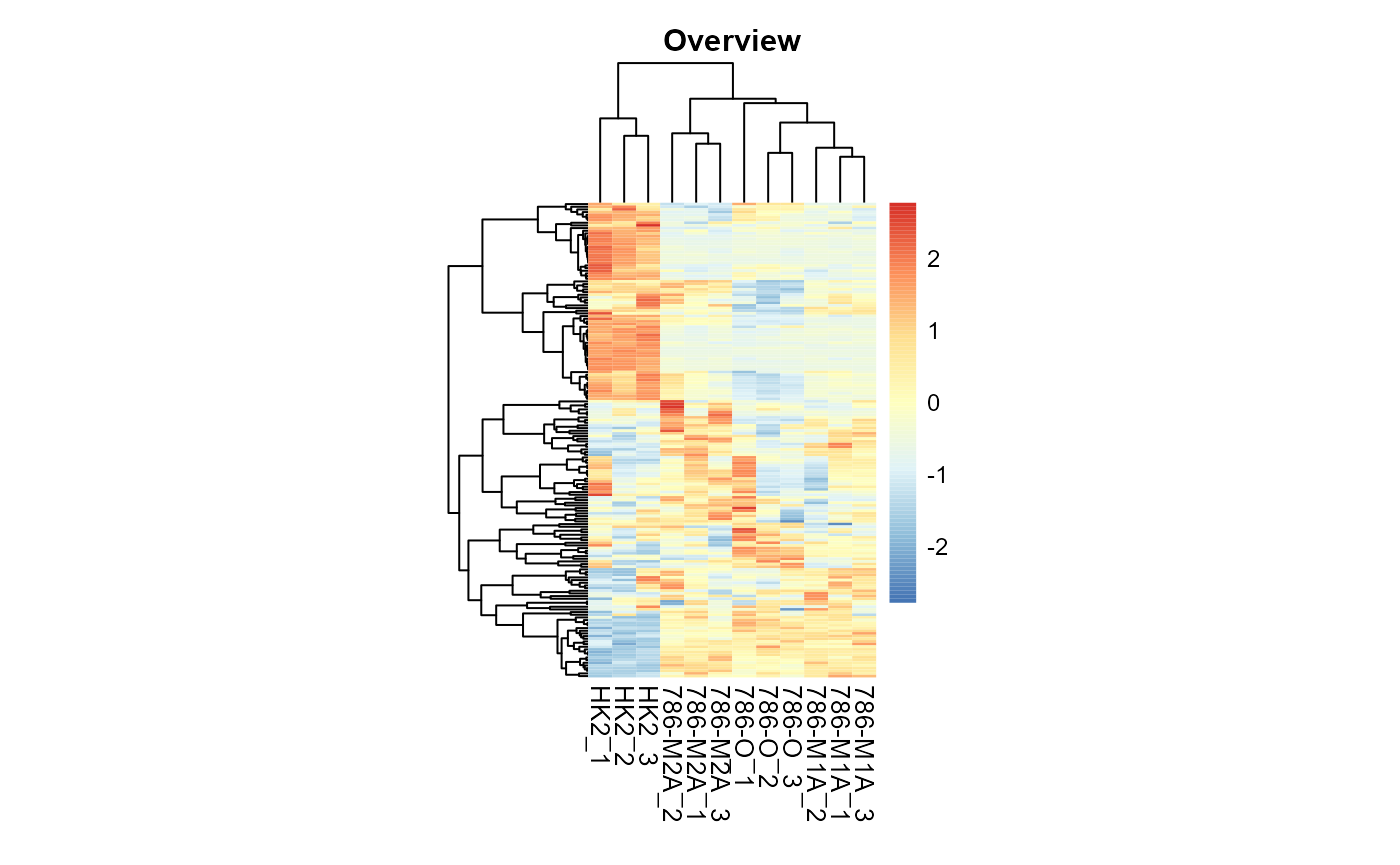
Overview heatmap.
Here we can add as many sample metadata information as needed at the
same time:
MetaProViz::VizHeatmap(InputData = Input_Heatmap,
SettingsFile_Sample = MetaData_Sample,
SettingsInfo = c(color_Sample = list("Conditions","Biological_Replicates", "Celltype", "Status")),
PlotName = "Colour Samples")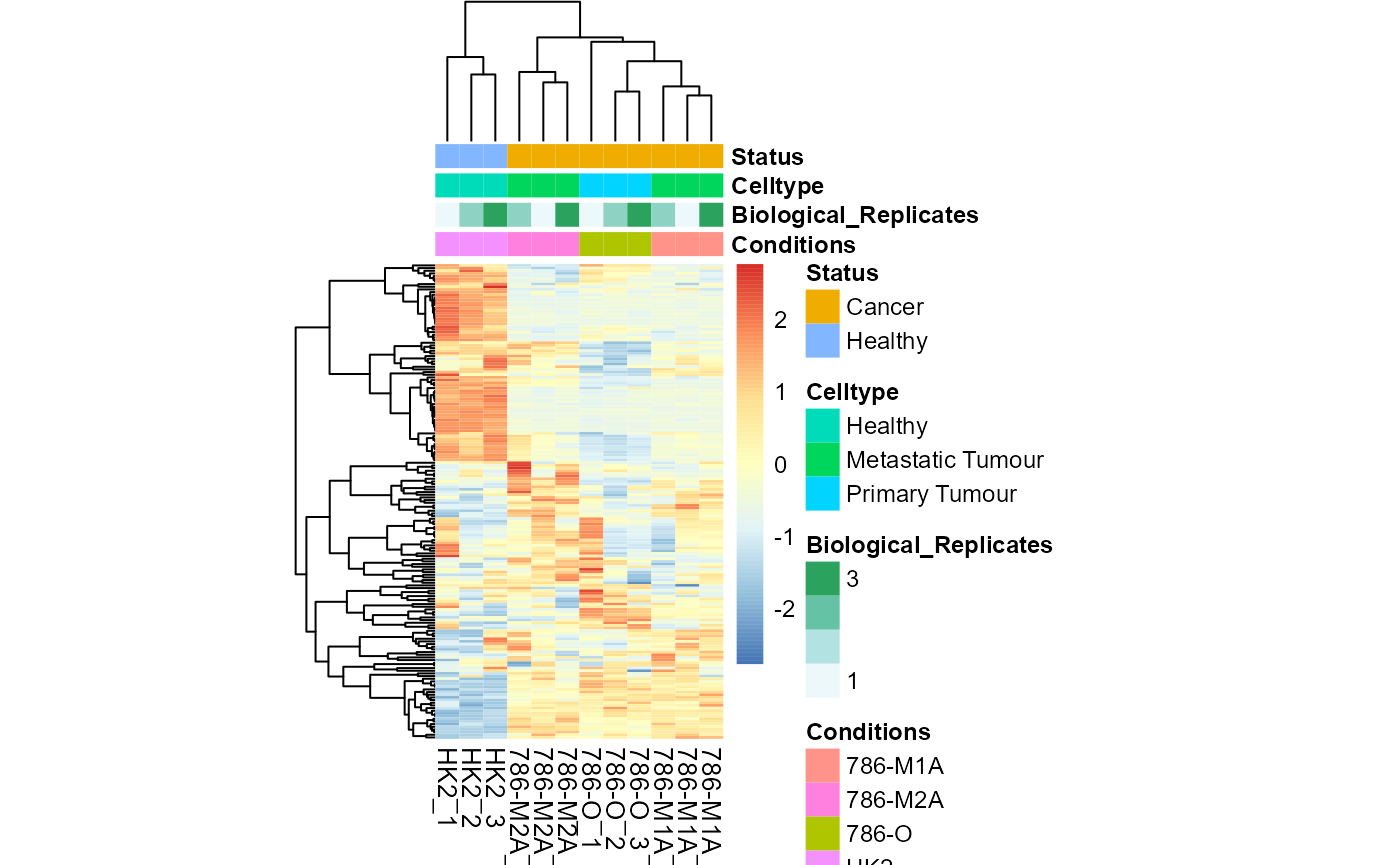
Colour for sample metadata.
Moreover, we can also add metabolite metadata information:
# row annotation: Color for Metabolites
MetaProViz::VizHeatmap(InputData = Input_Heatmap,
SettingsFile_Sample = MetaData_Sample,
SettingsInfo = c(color_Metab = list("Pathway")),
SettingsFile_Metab = MappingInfo,
PlotName = "Colour Metabolites")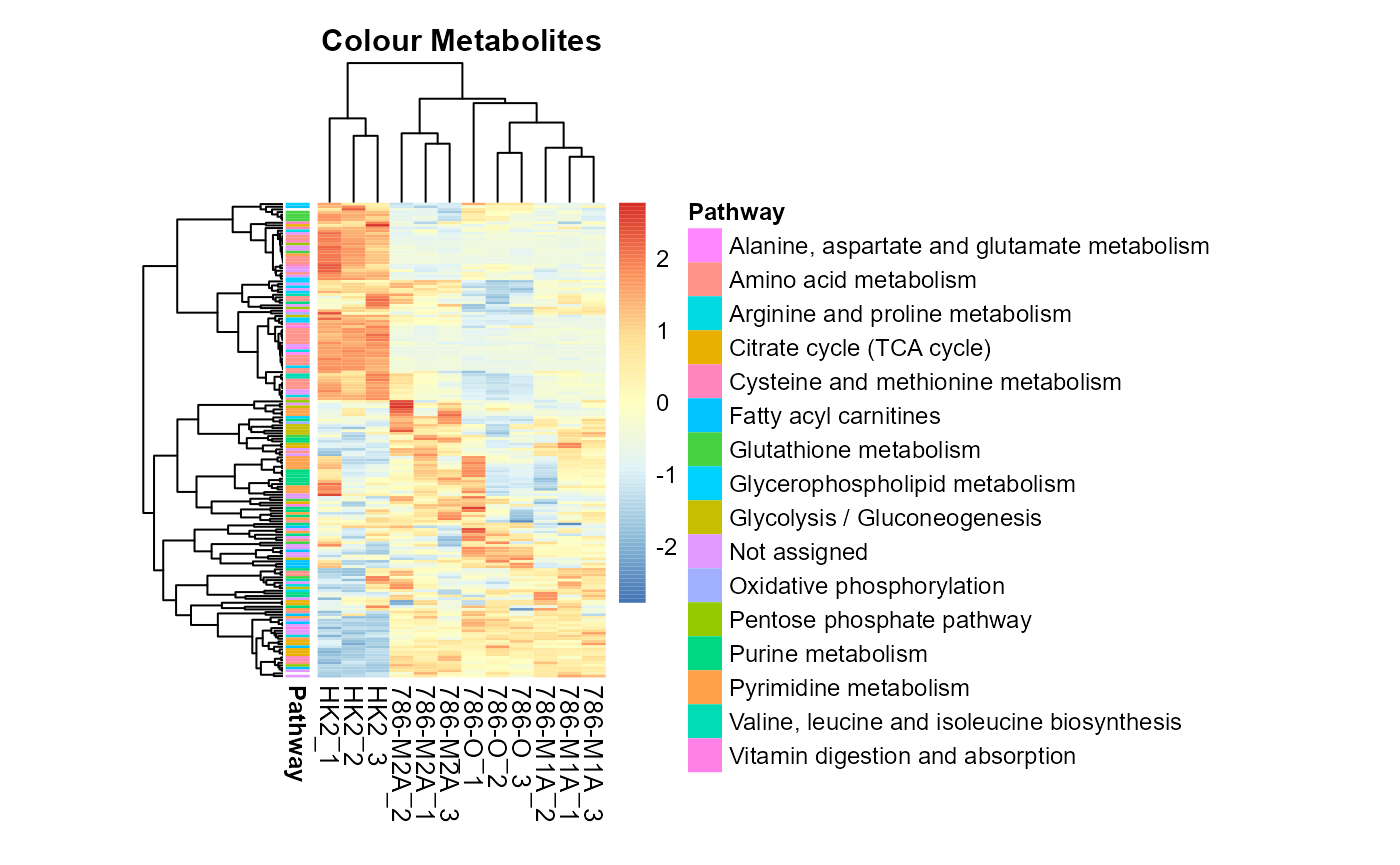
Colour for metabolite metadata.
Lastly, by generate individual plot for e.g. each pathway or the
metabolite clusters by adding individual (individual_Sample
or individual_Metab) to Plot_SettingsInfo. At
the same time we can still maintain the metadata information for both,
the samples and the metabolites. Together this can help us to draw
biological conclusions about the different pathways: Indeed, we can
observe for the D-Amino acid metabolism many metabolites
fall into the MCA-Cluster Core_DOWN, meaning in comparison
to HK2 cells we have a negative Log2FC for 786-O and 786-M1A.
# individual: One individual plot for each pathway, col annotation: Colour for samples
MetaProViz::VizHeatmap(InputData = Input_Heatmap,
SettingsFile_Sample = MetaData_Sample,
SettingsInfo = c(individual_Metab = "Pathway",
color_Sample = list("Conditions","Biological_Replicates"),
color_Metab = list("RG2_Significant")),
SettingsFile_Metab = MetaData_Metab,
PlotName = "Pathway")
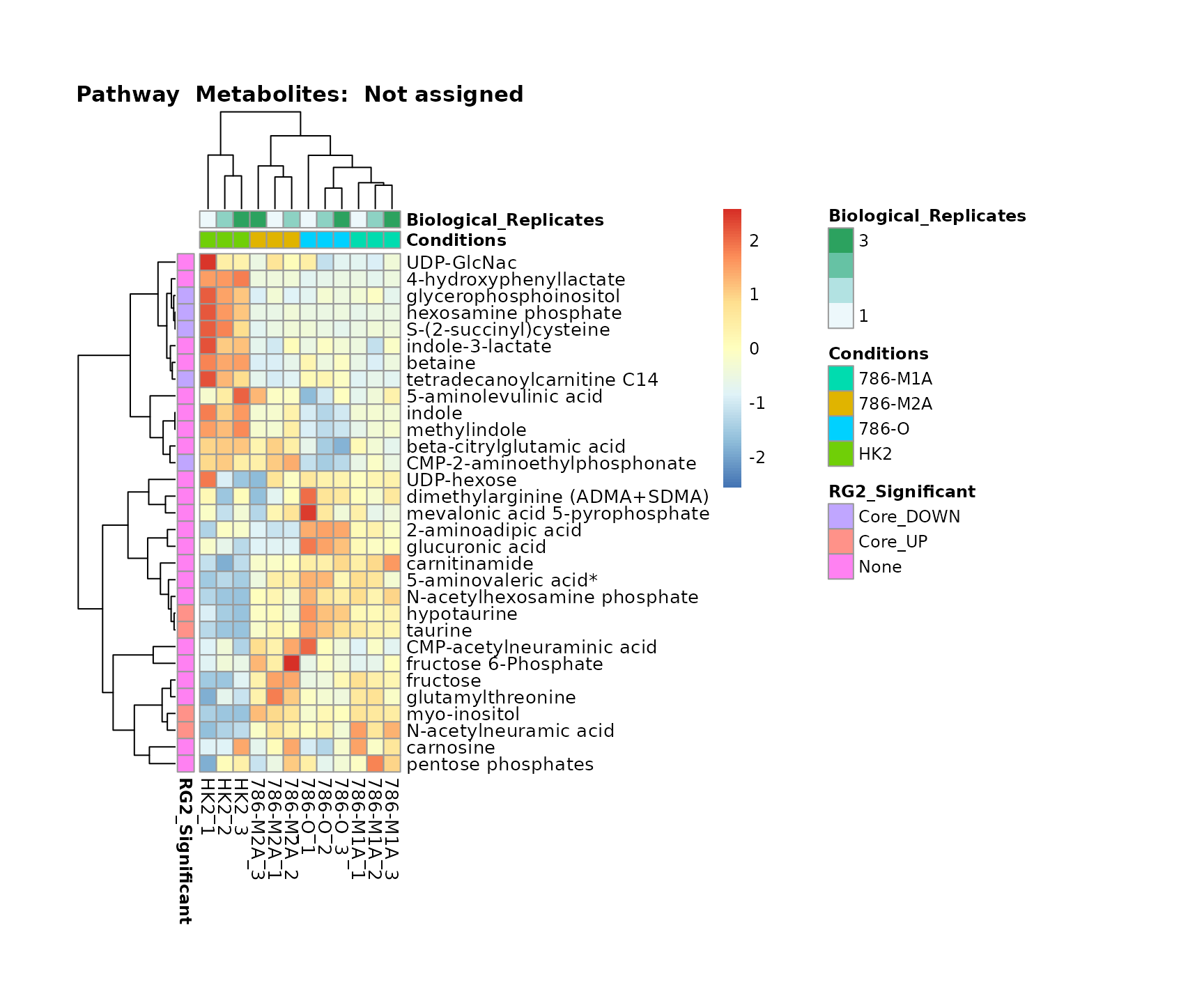
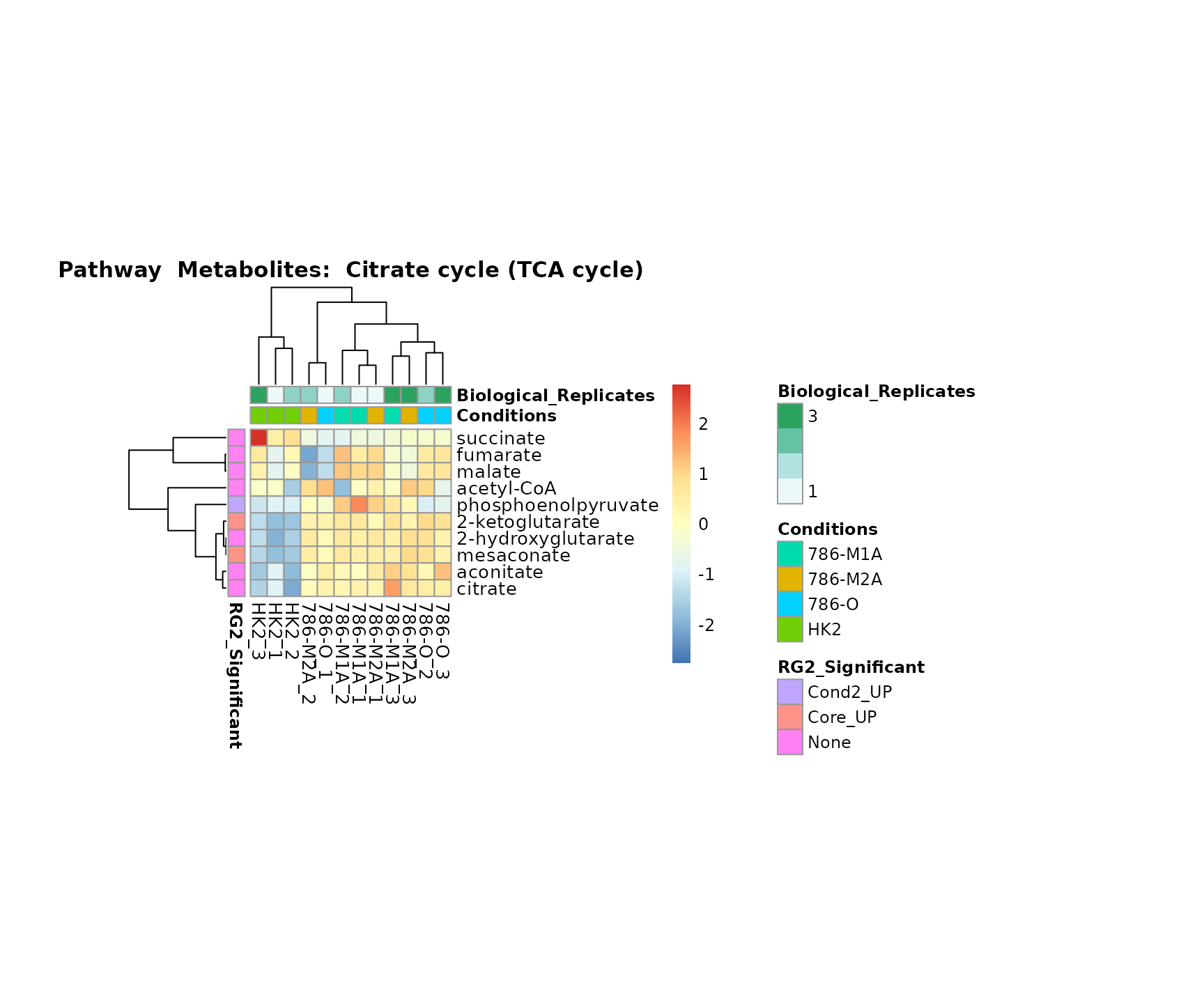

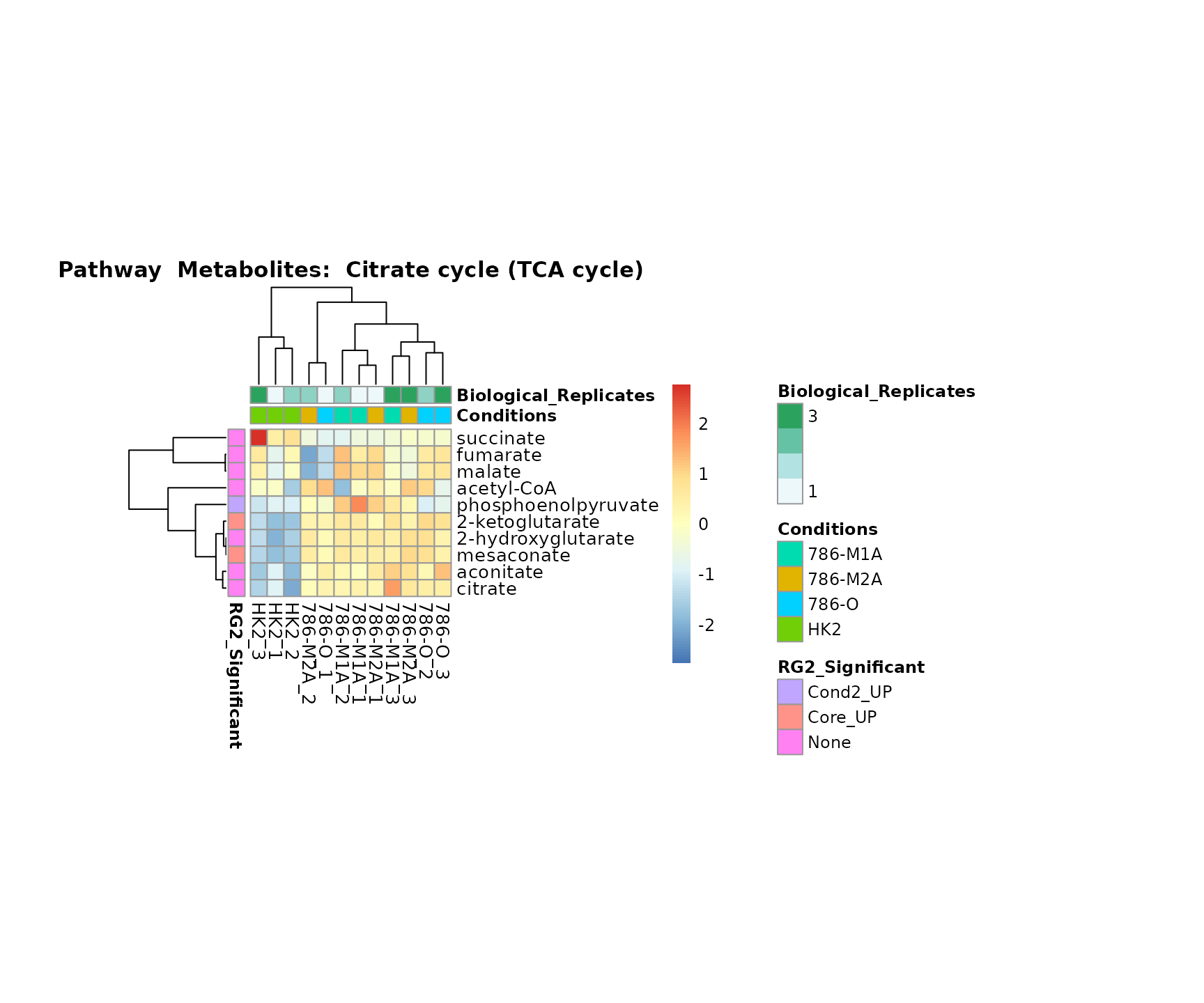


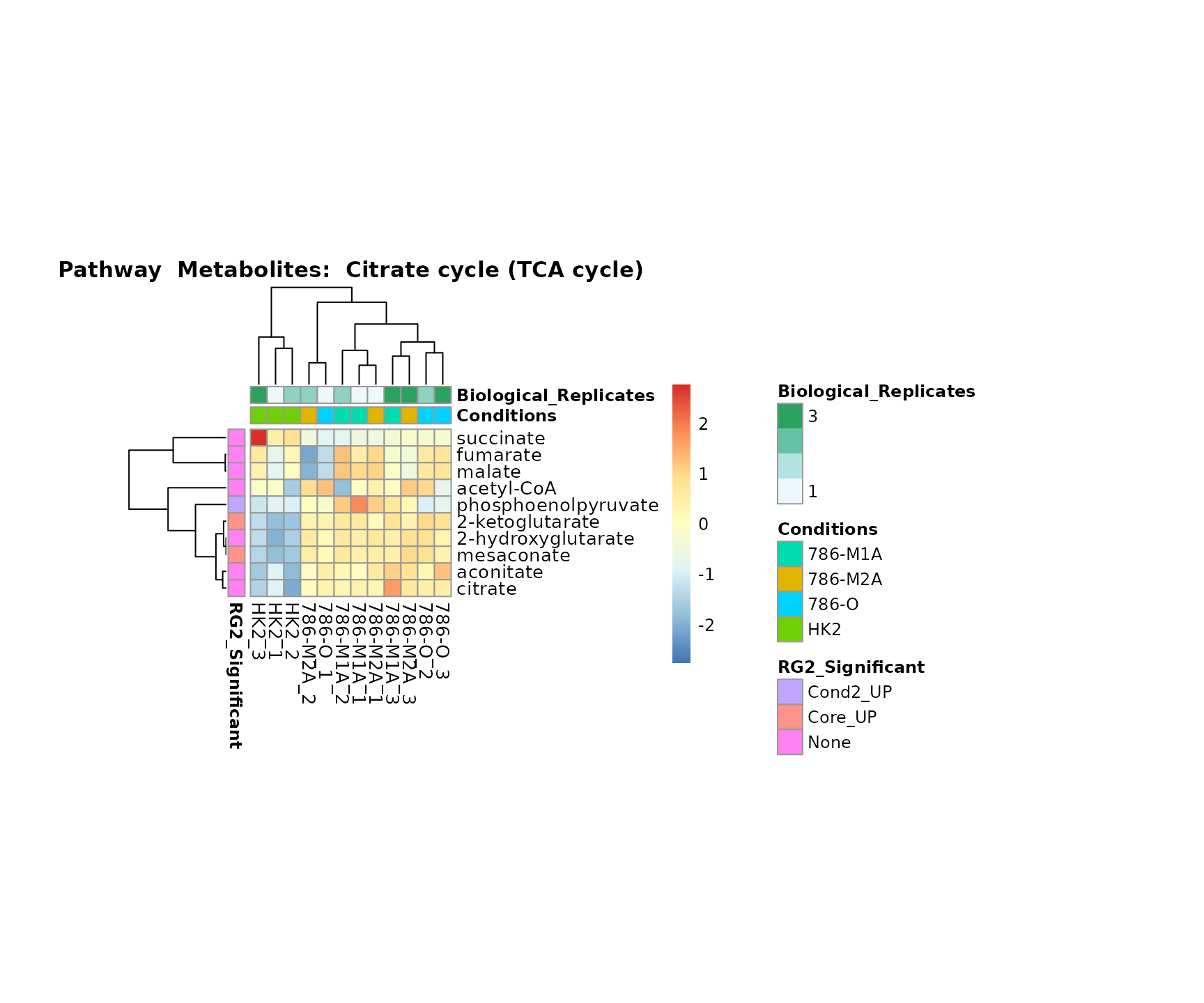

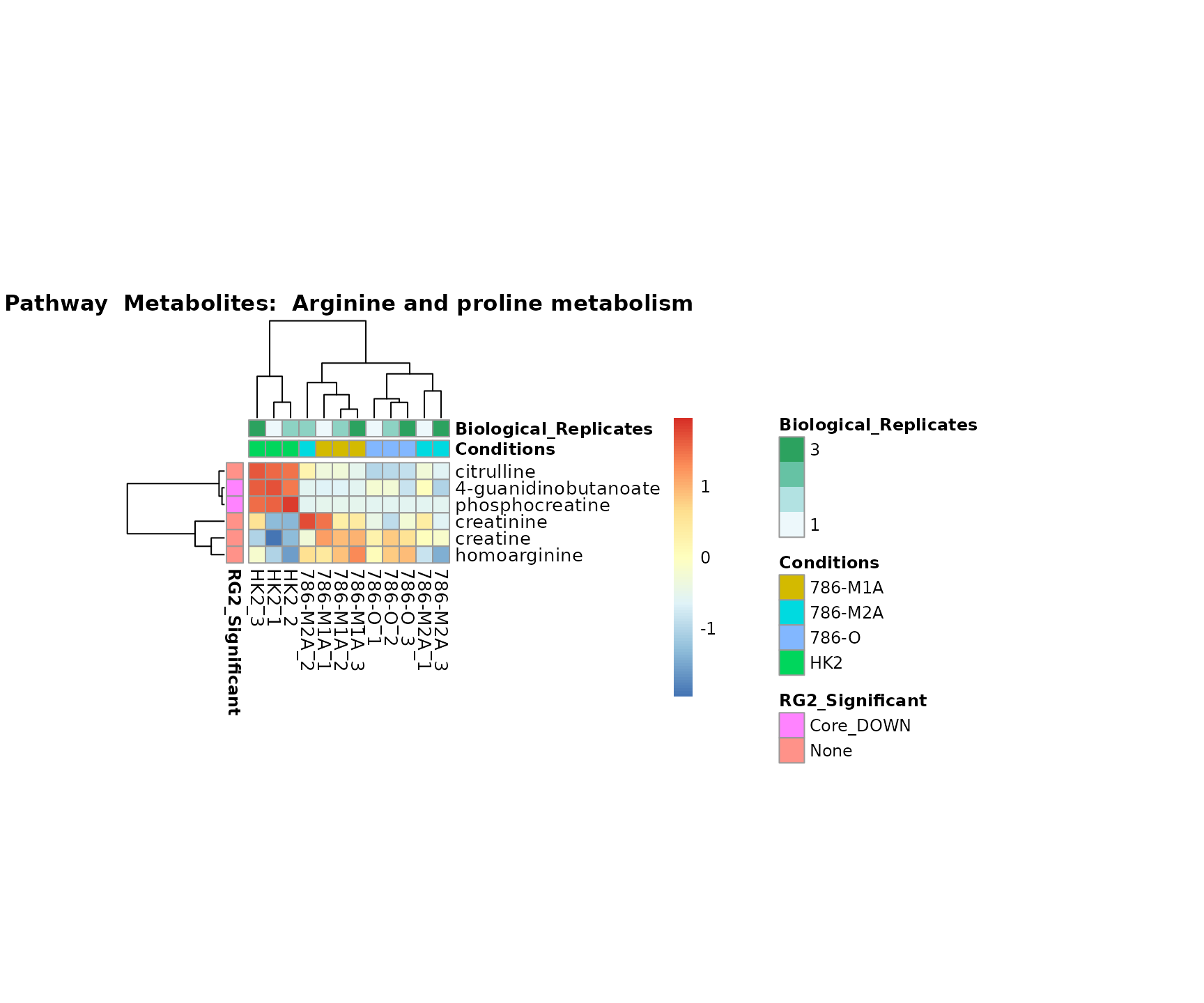

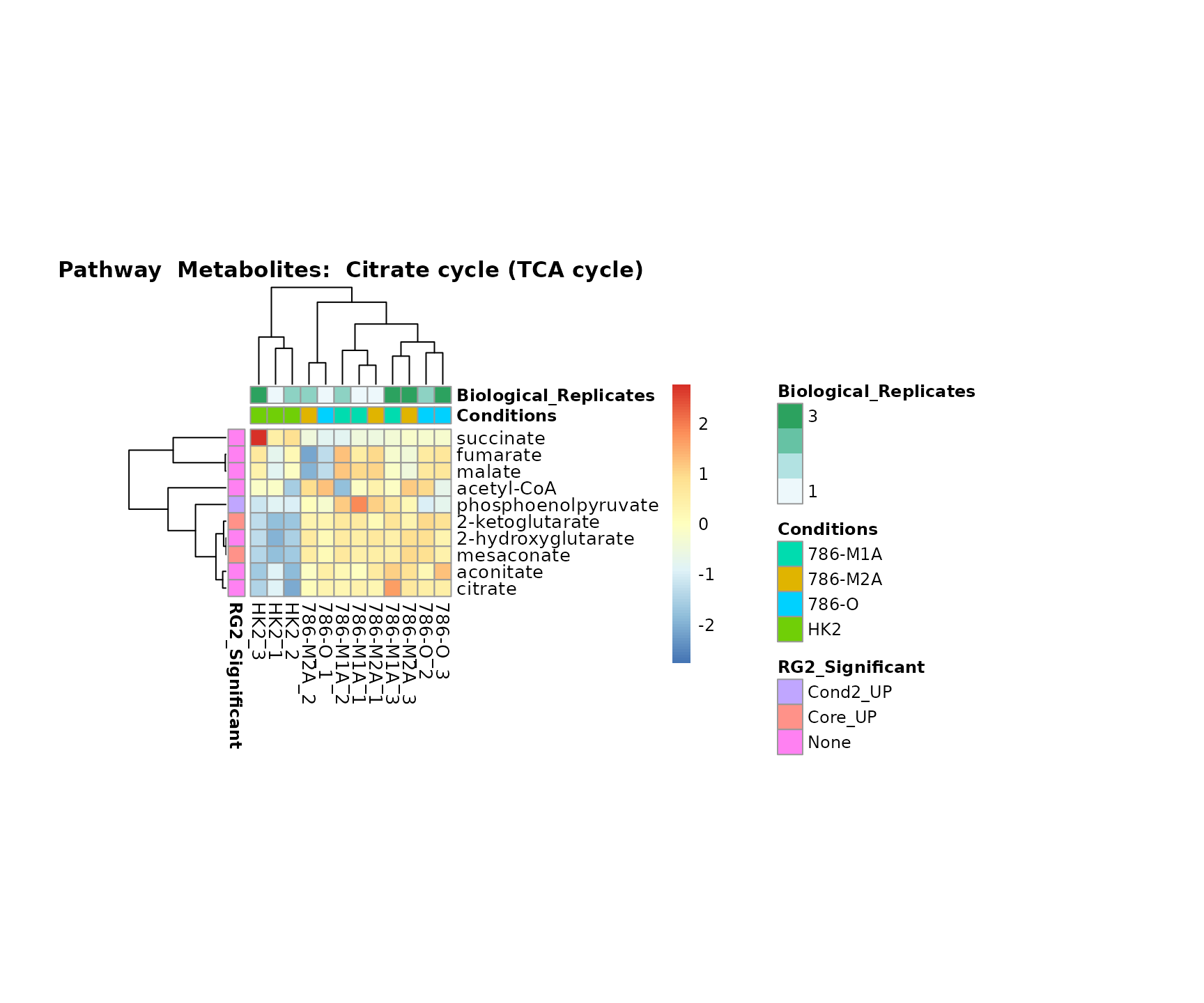

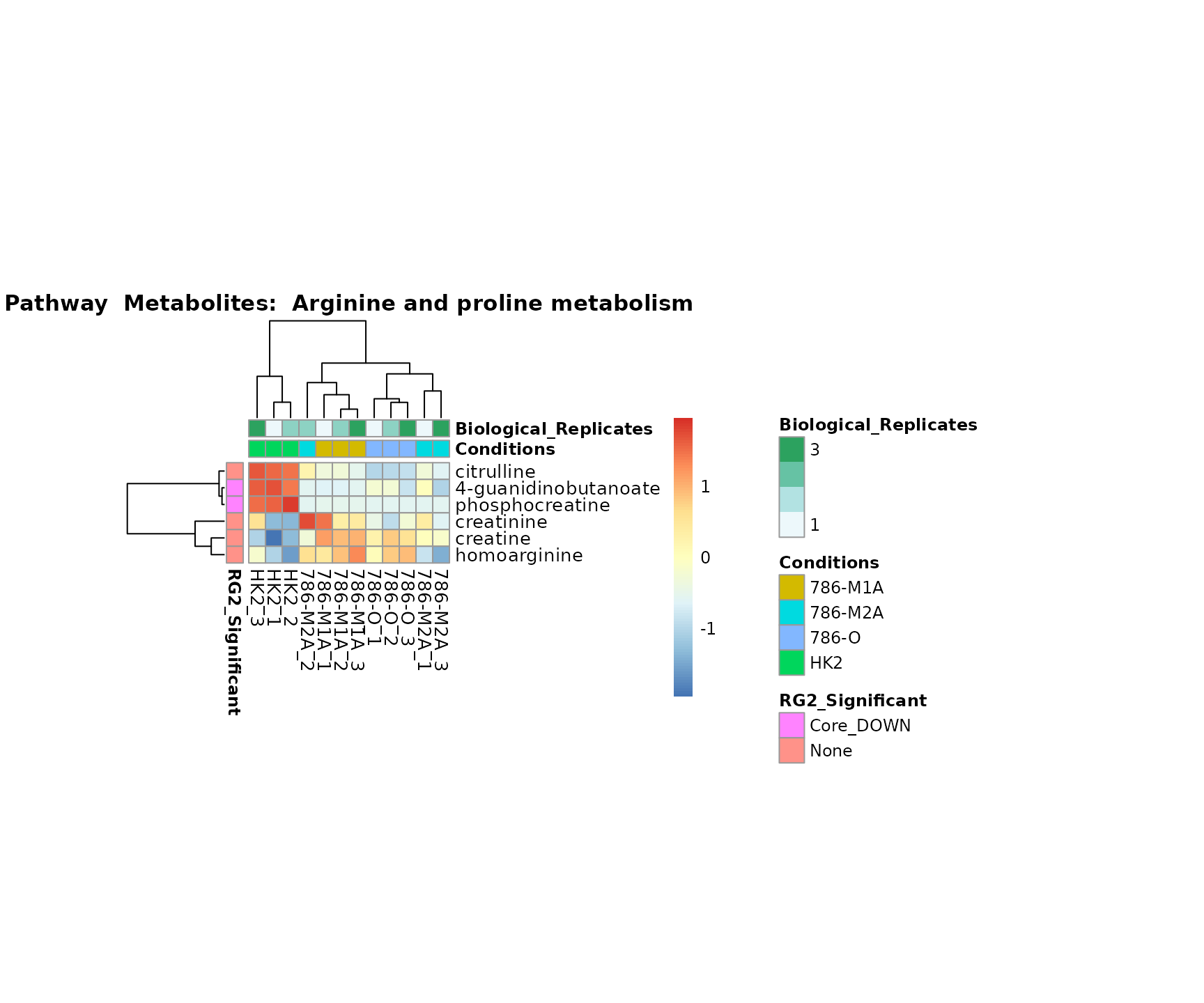


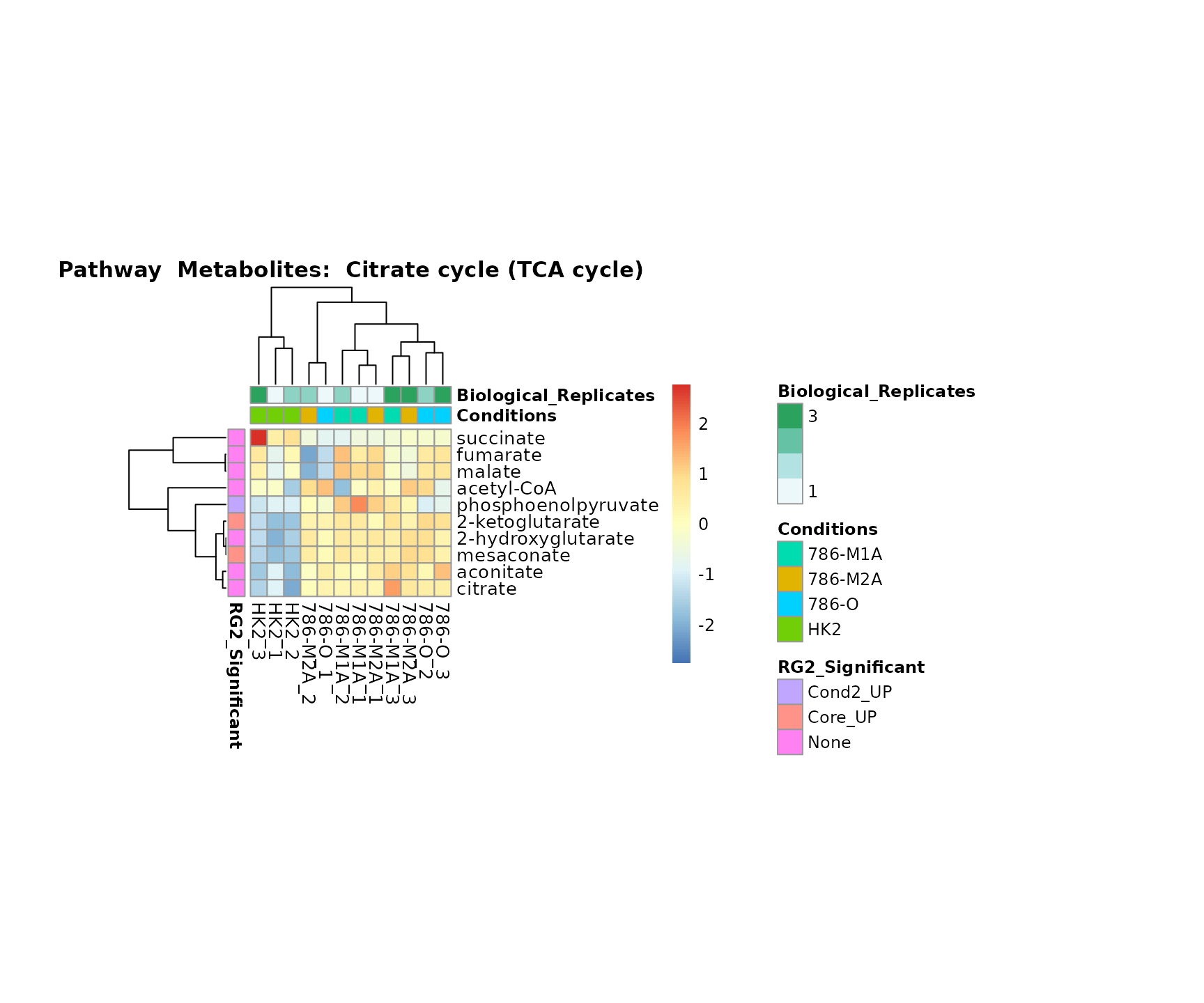

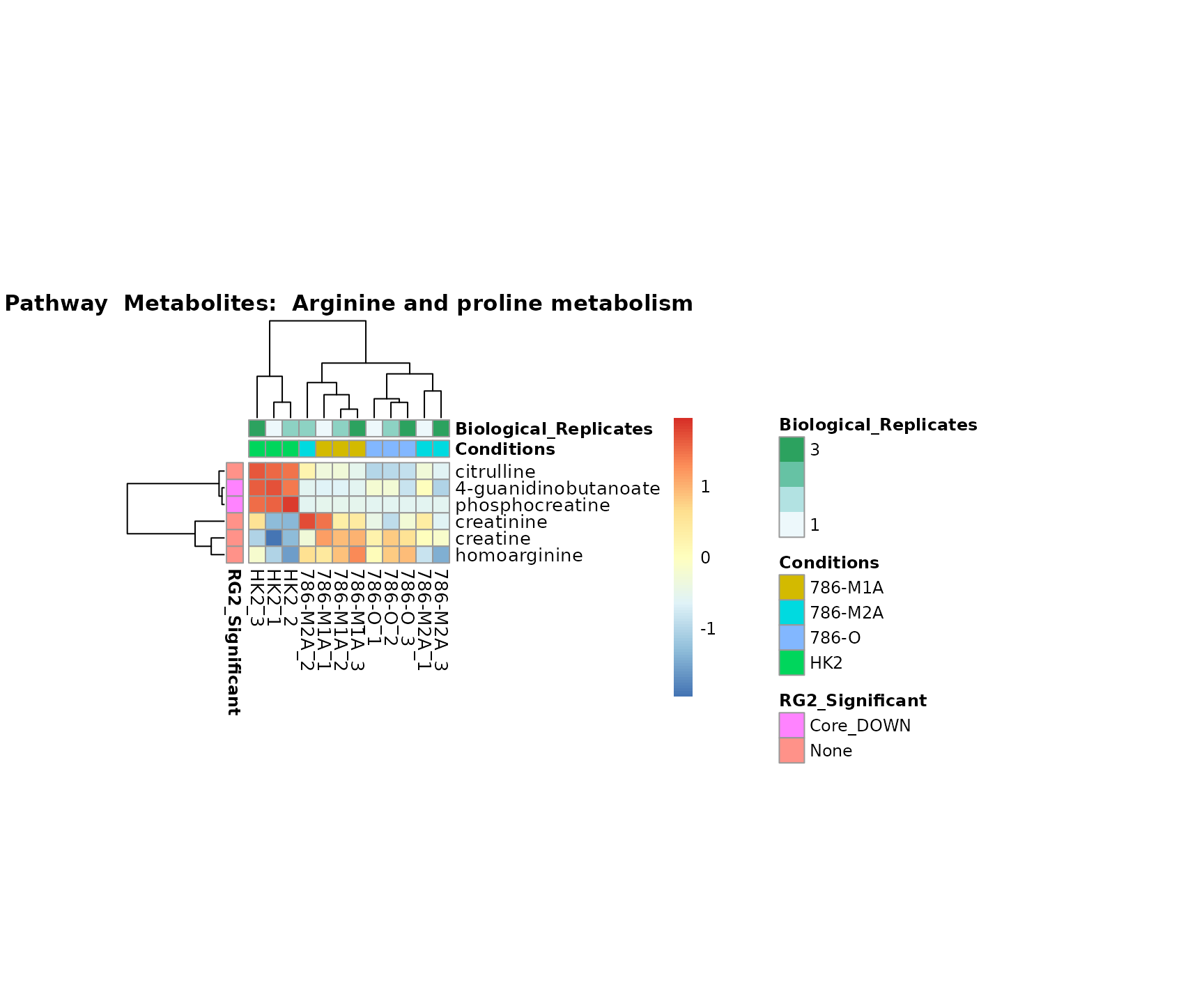

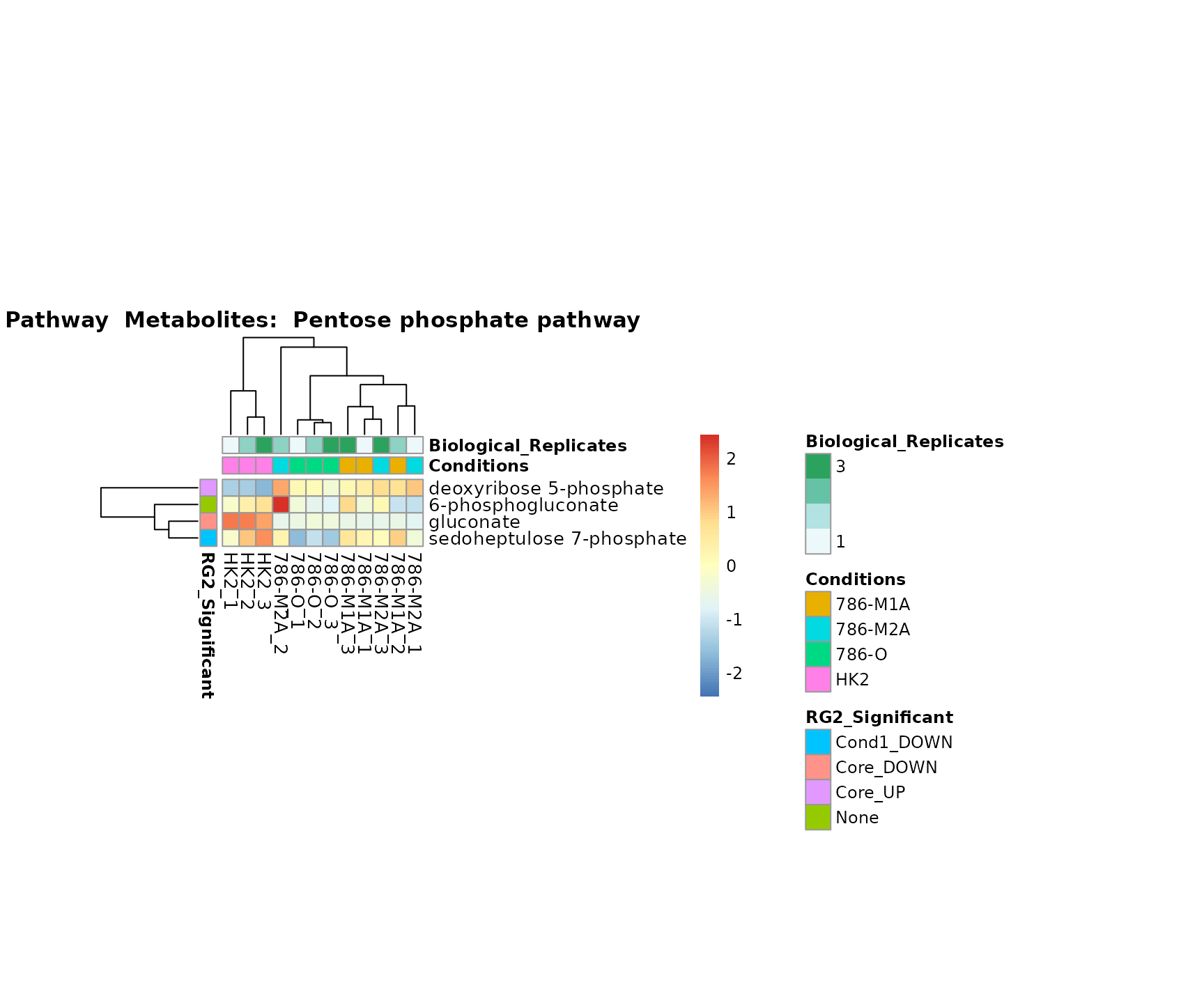


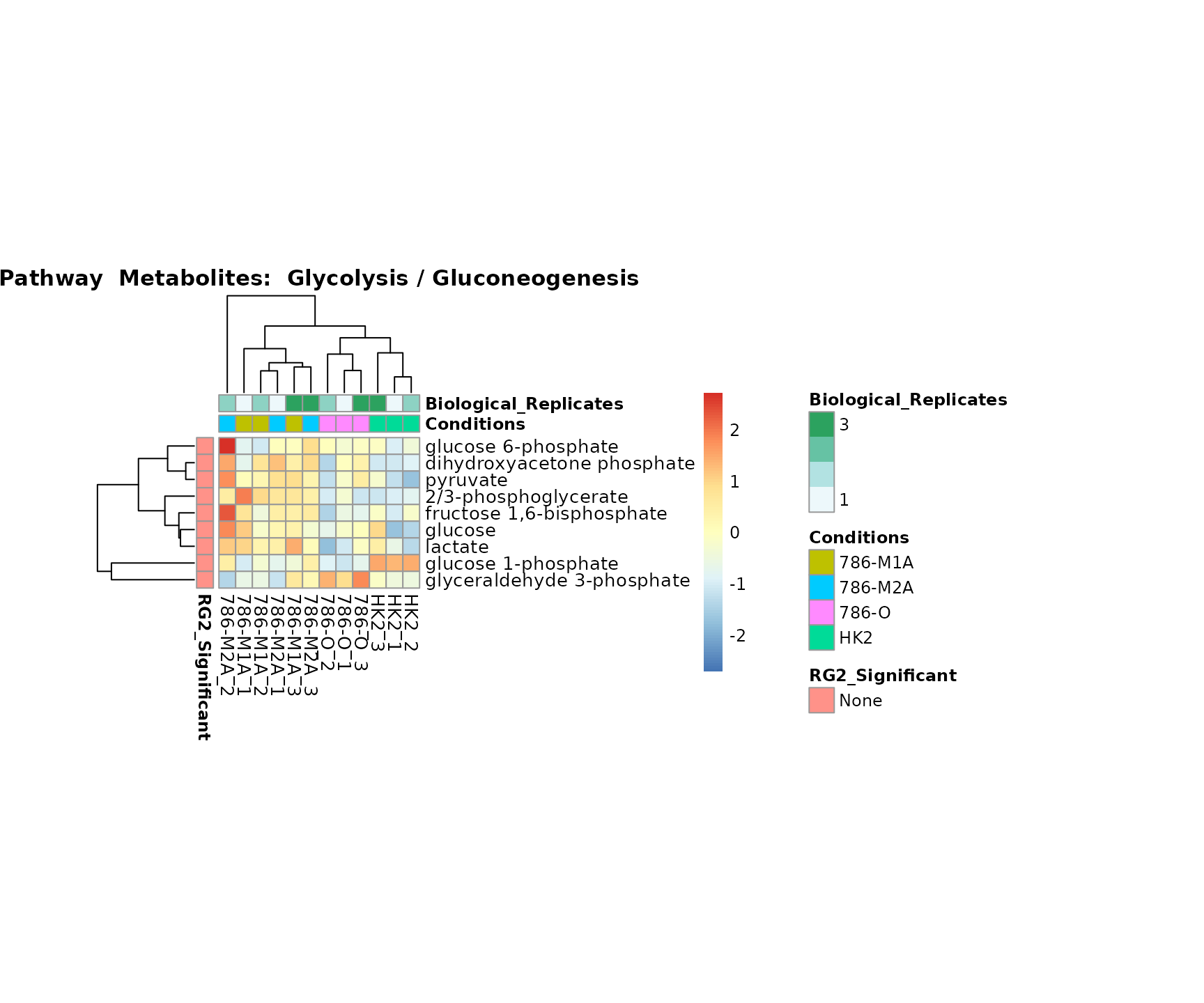

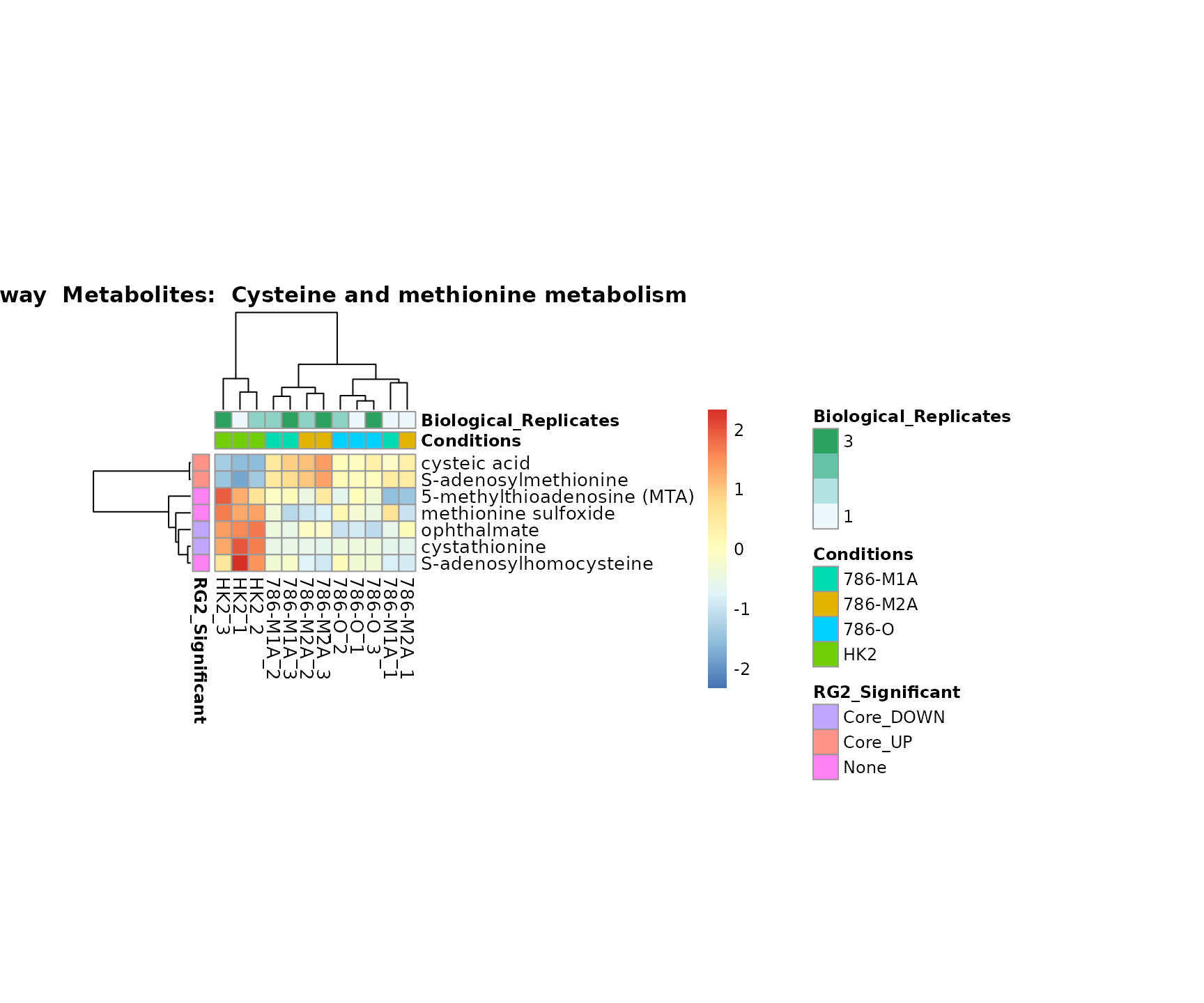
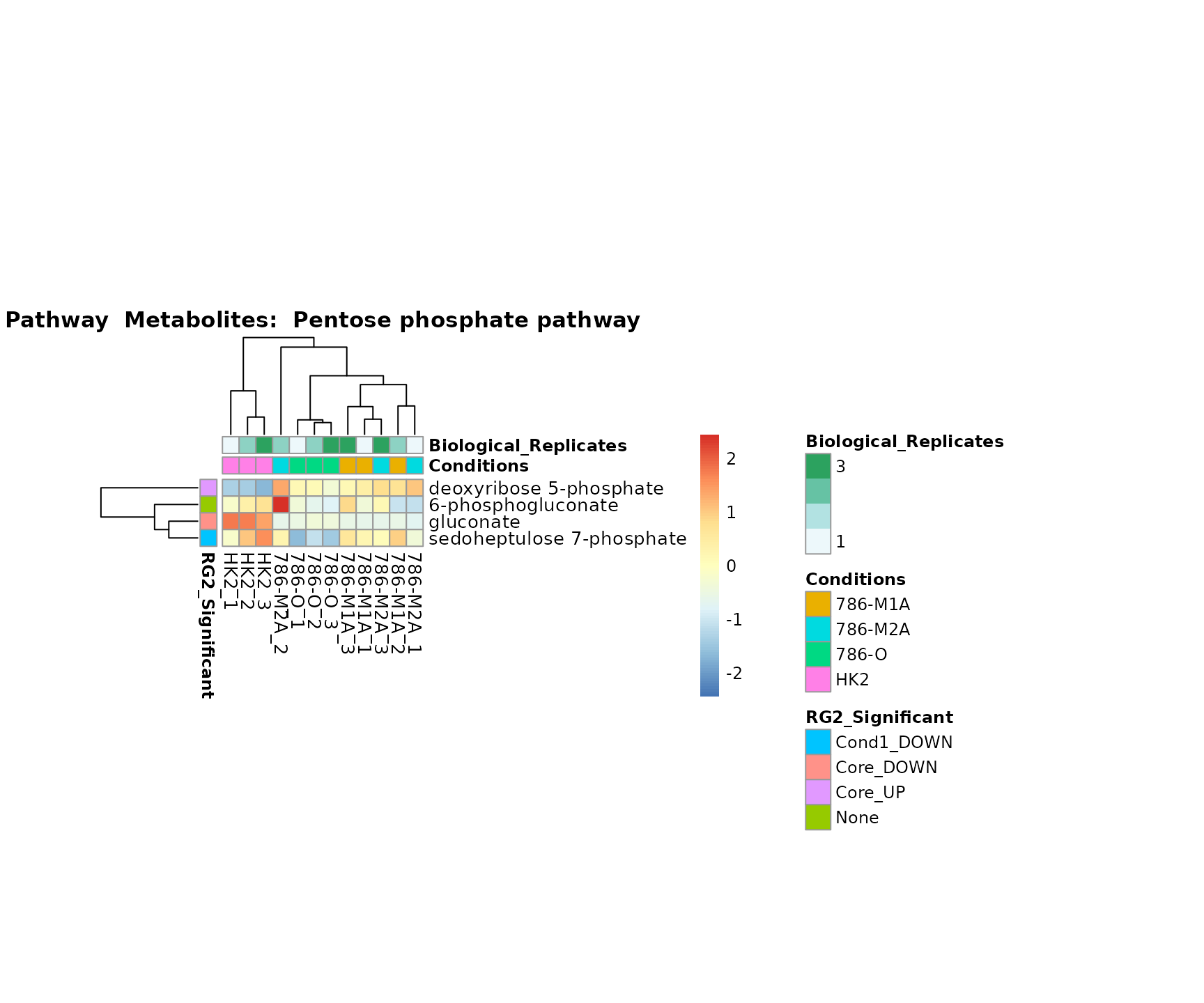
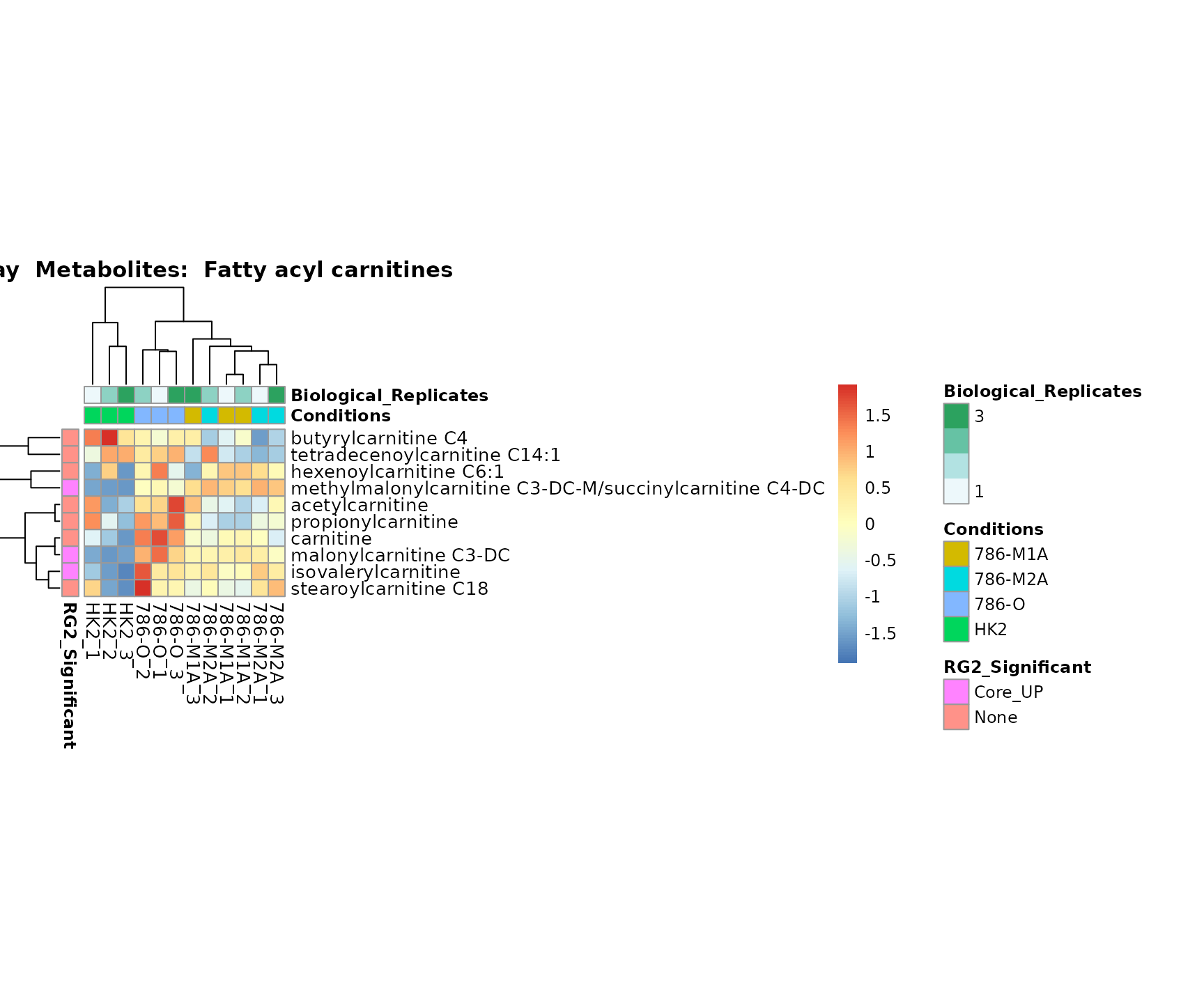



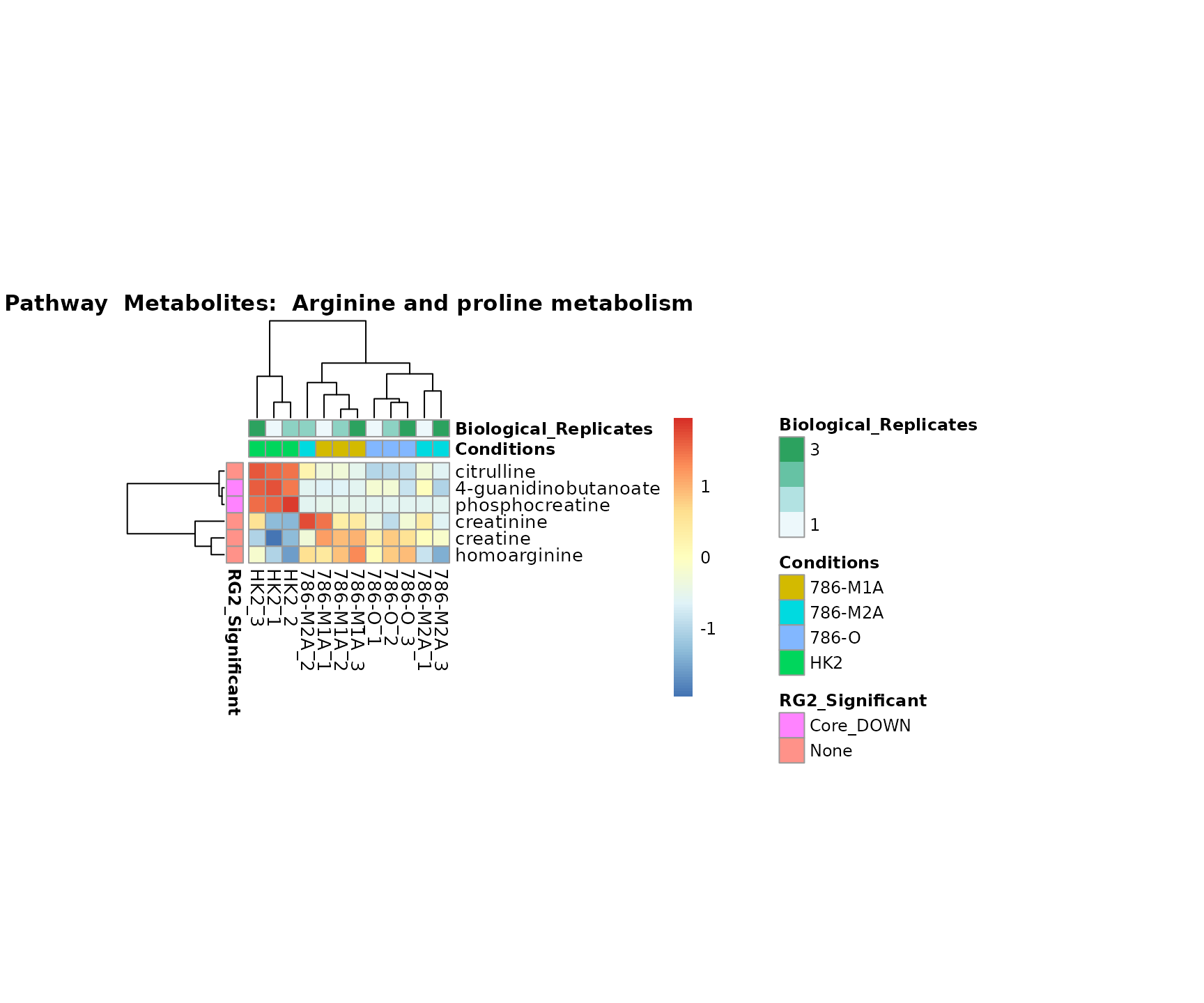
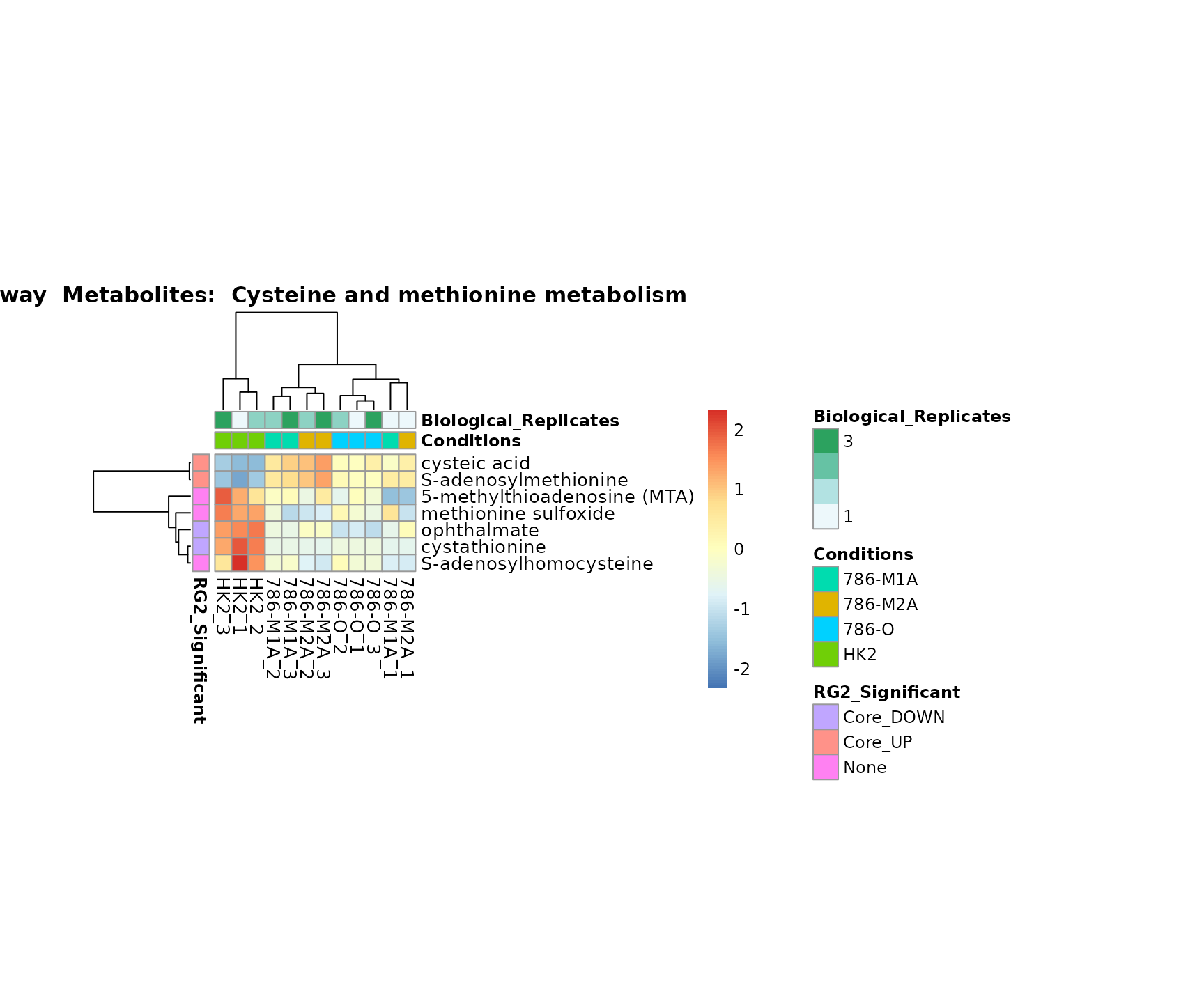
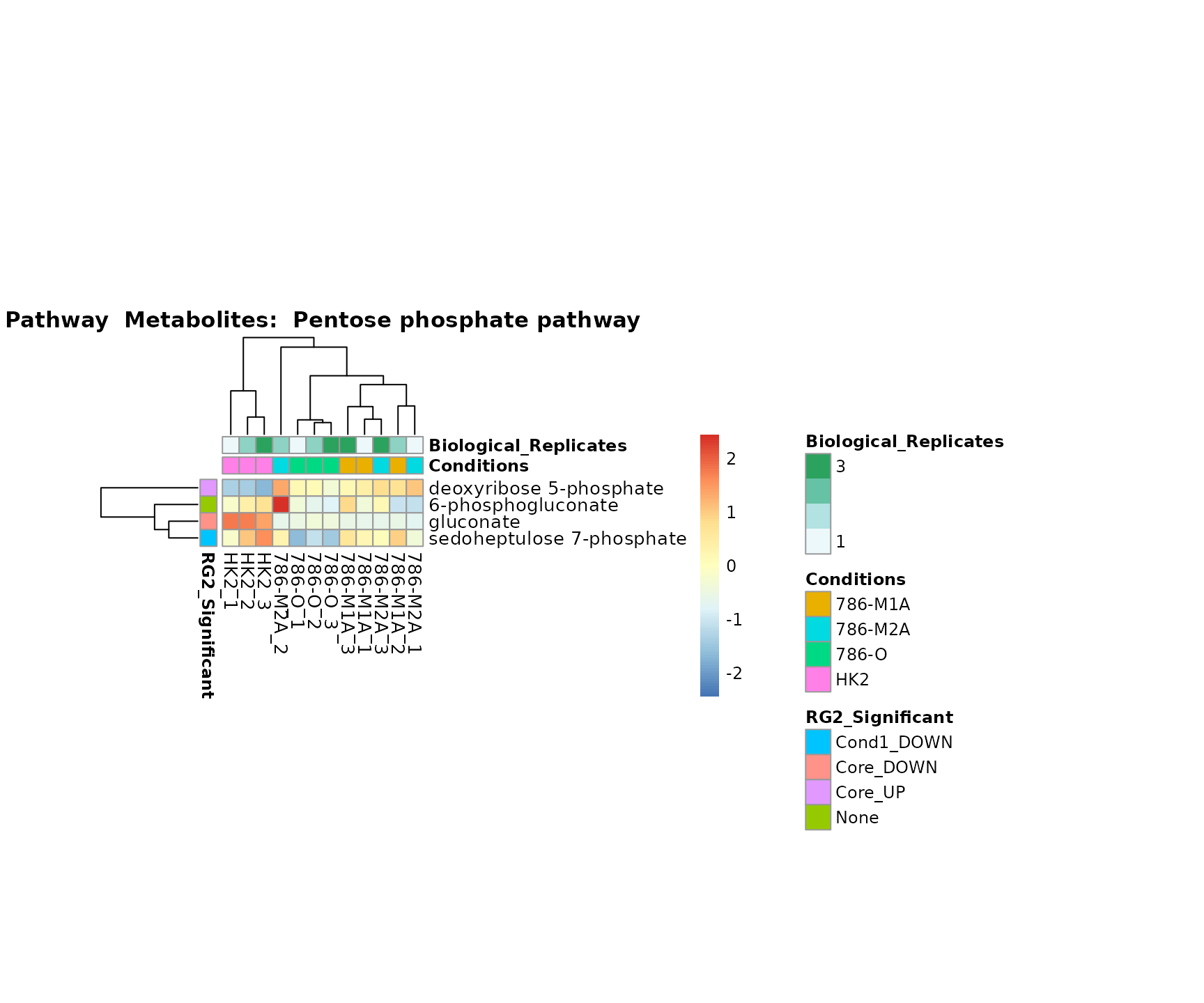
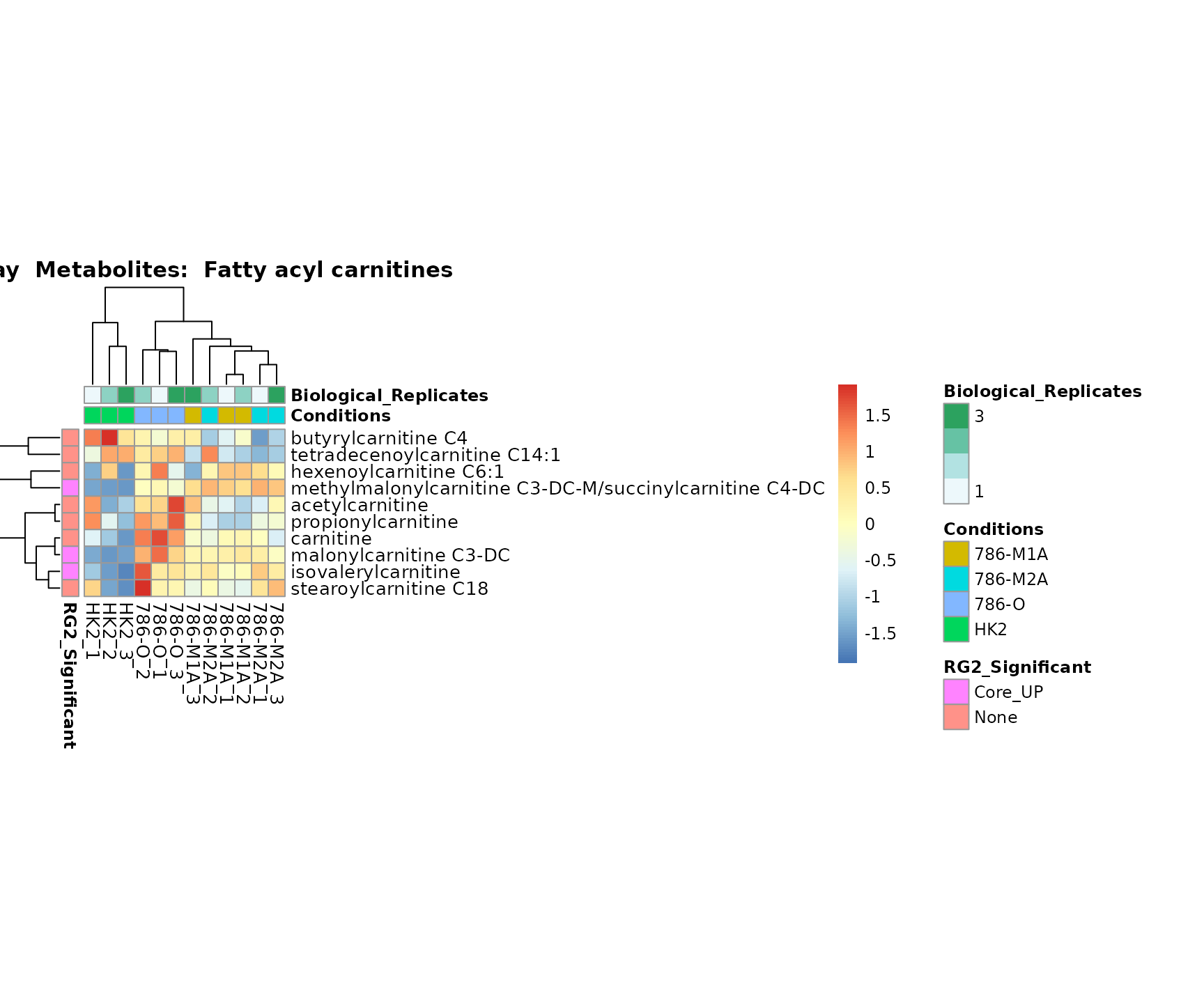
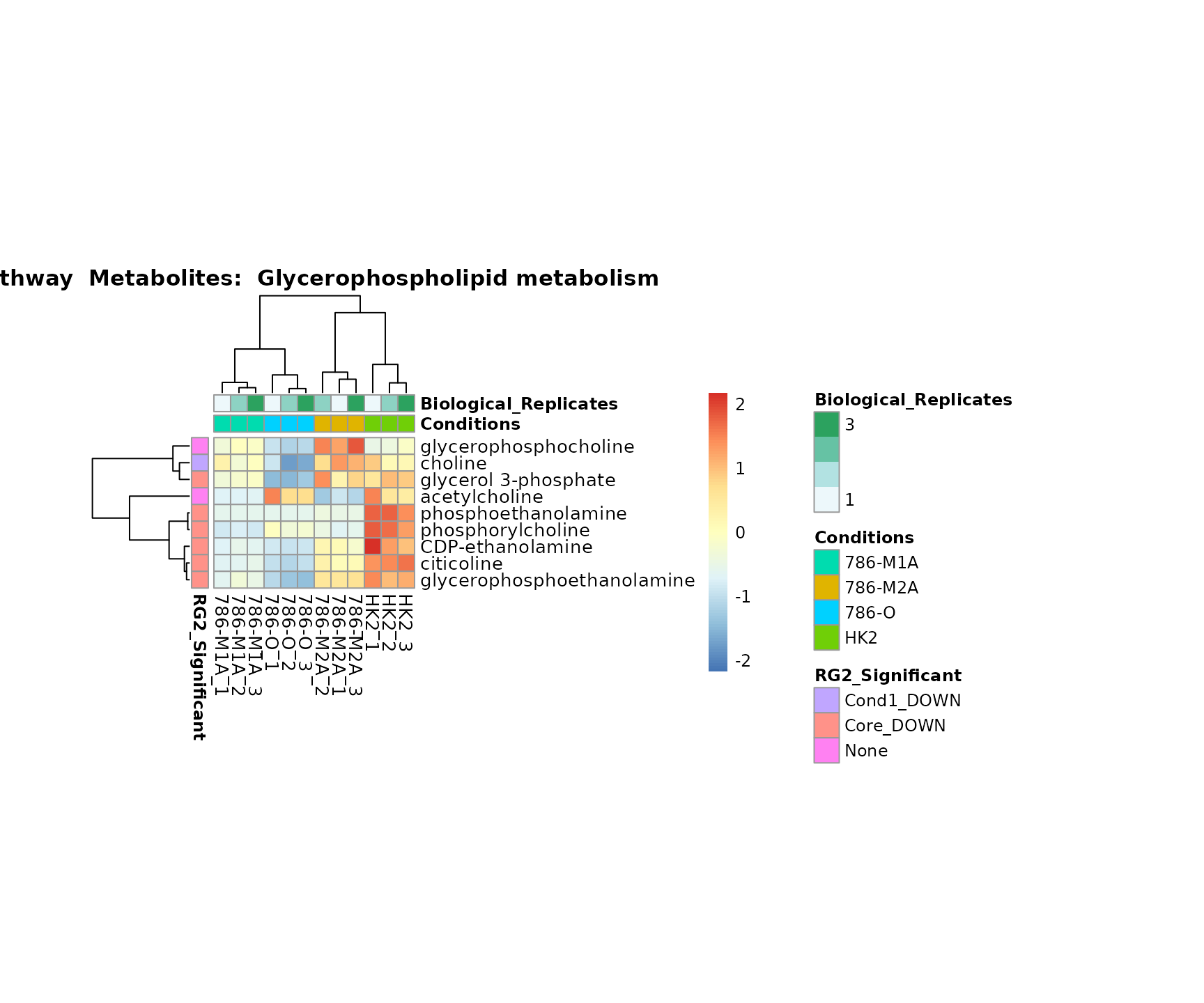
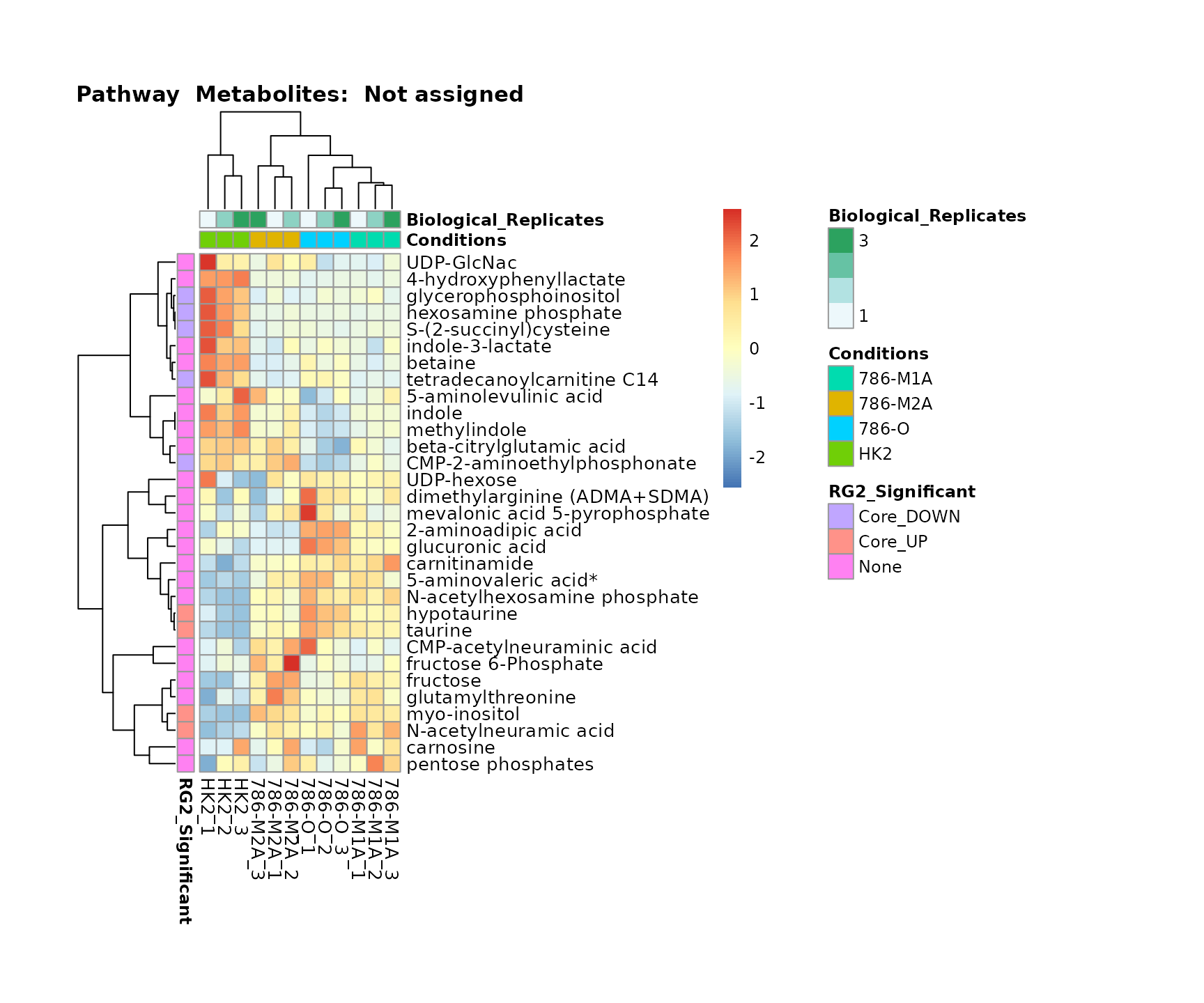
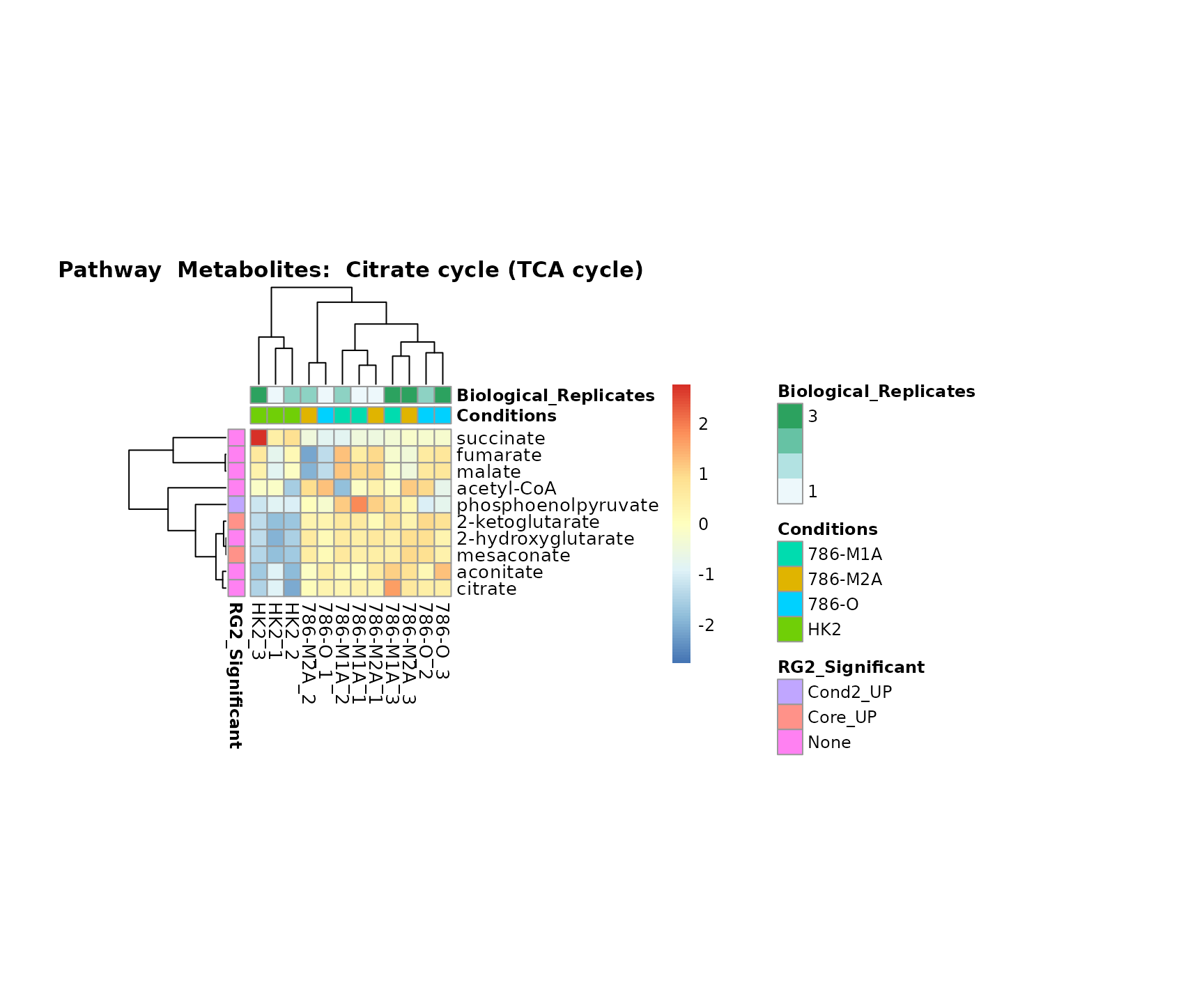
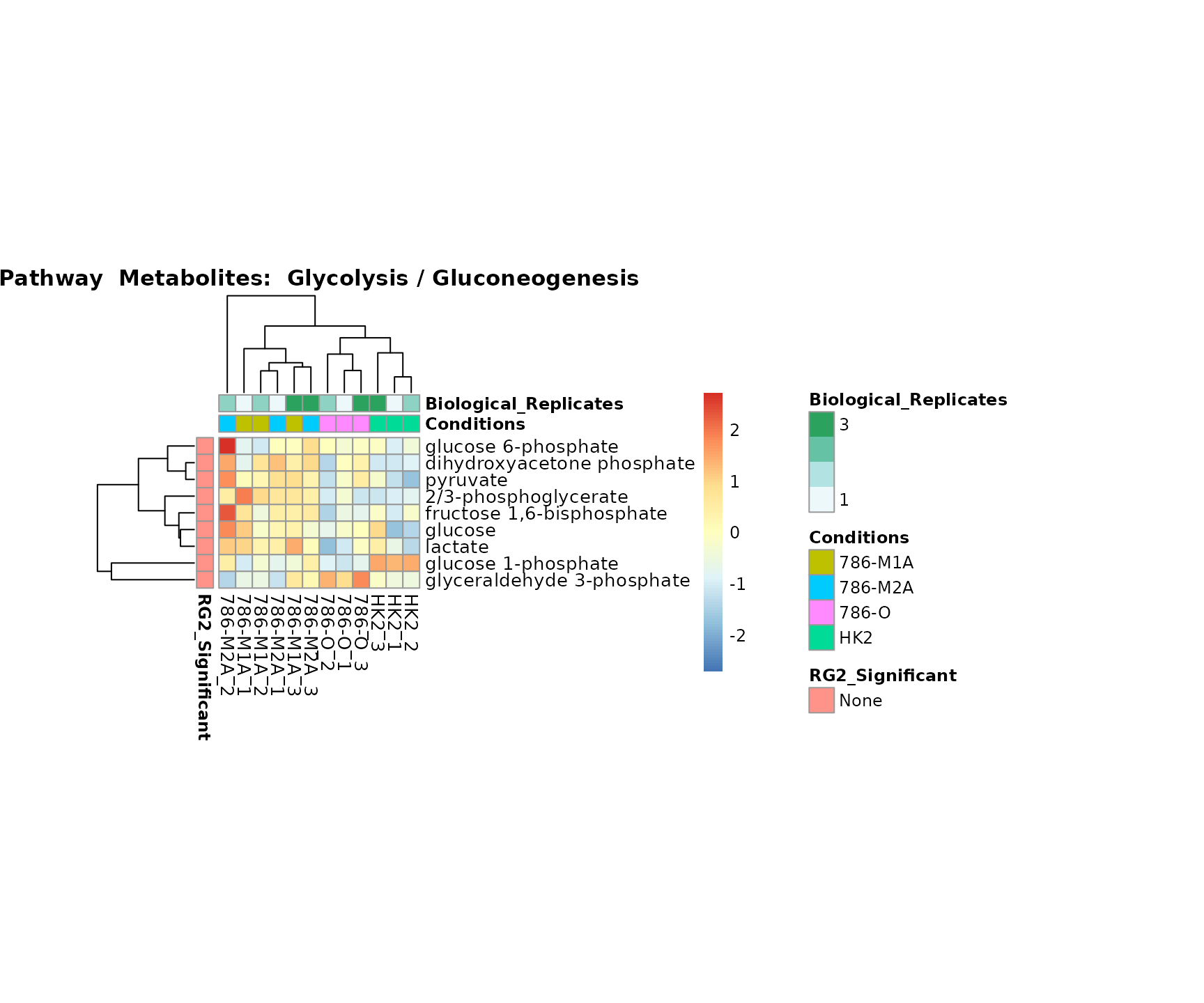

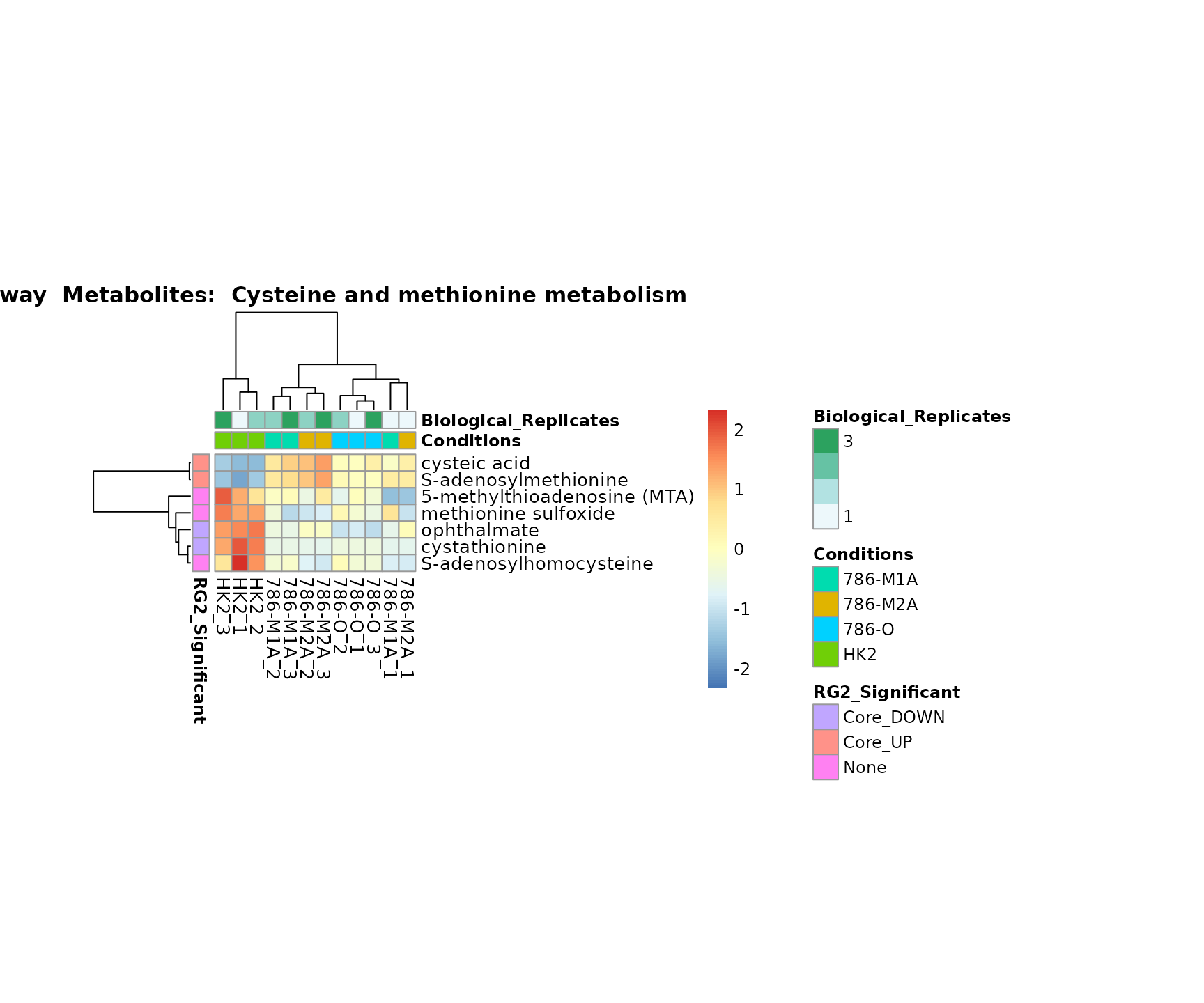


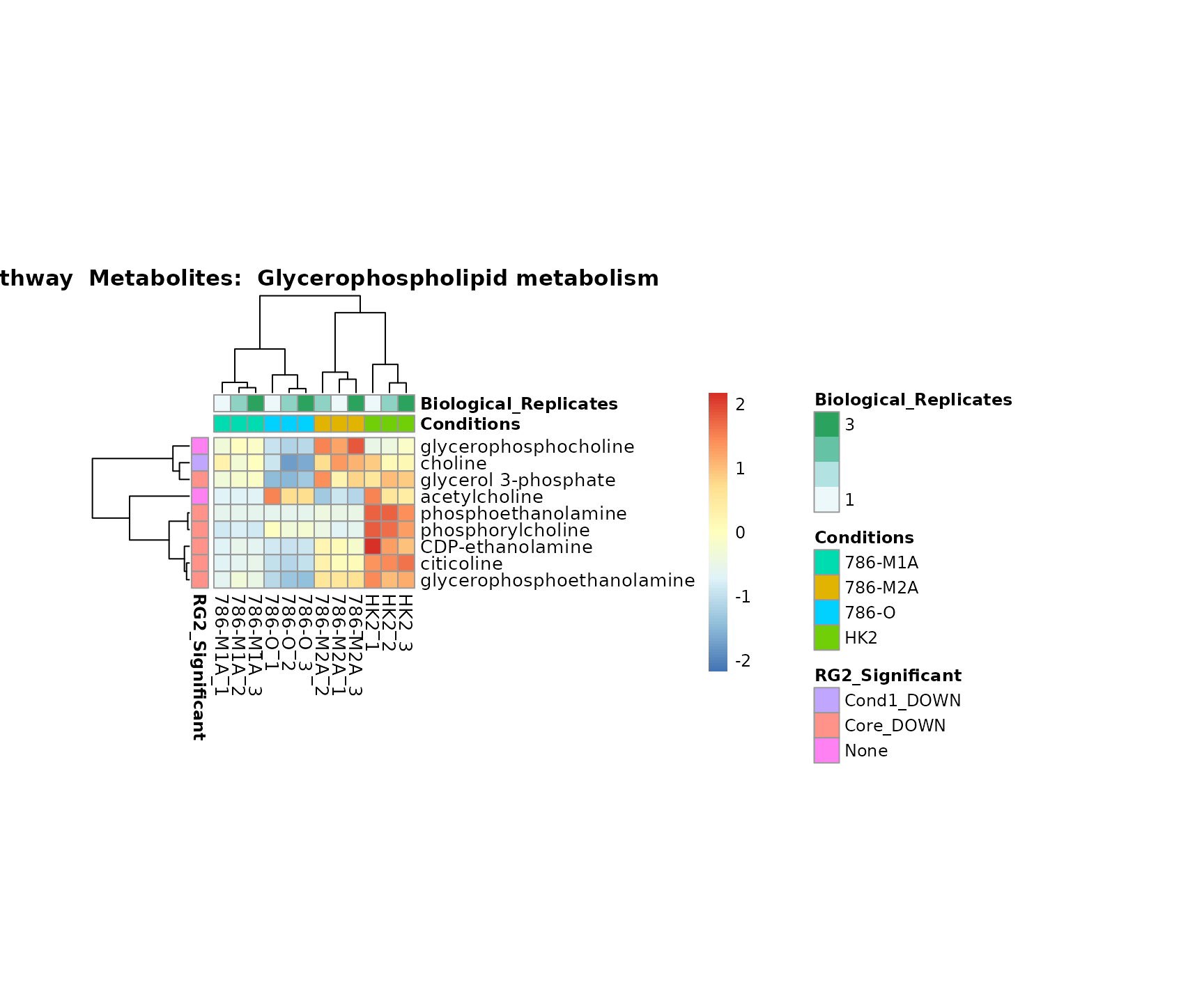
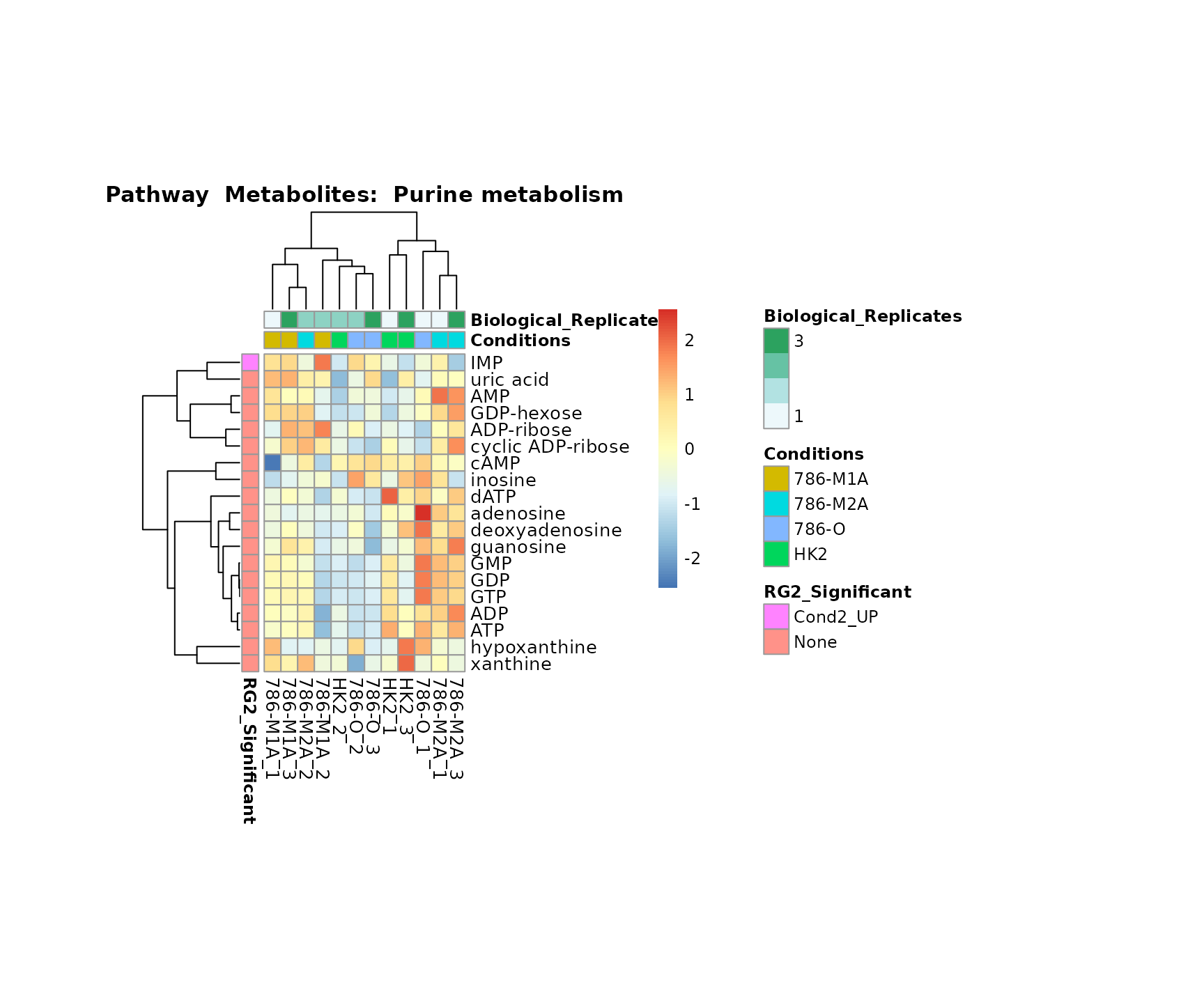
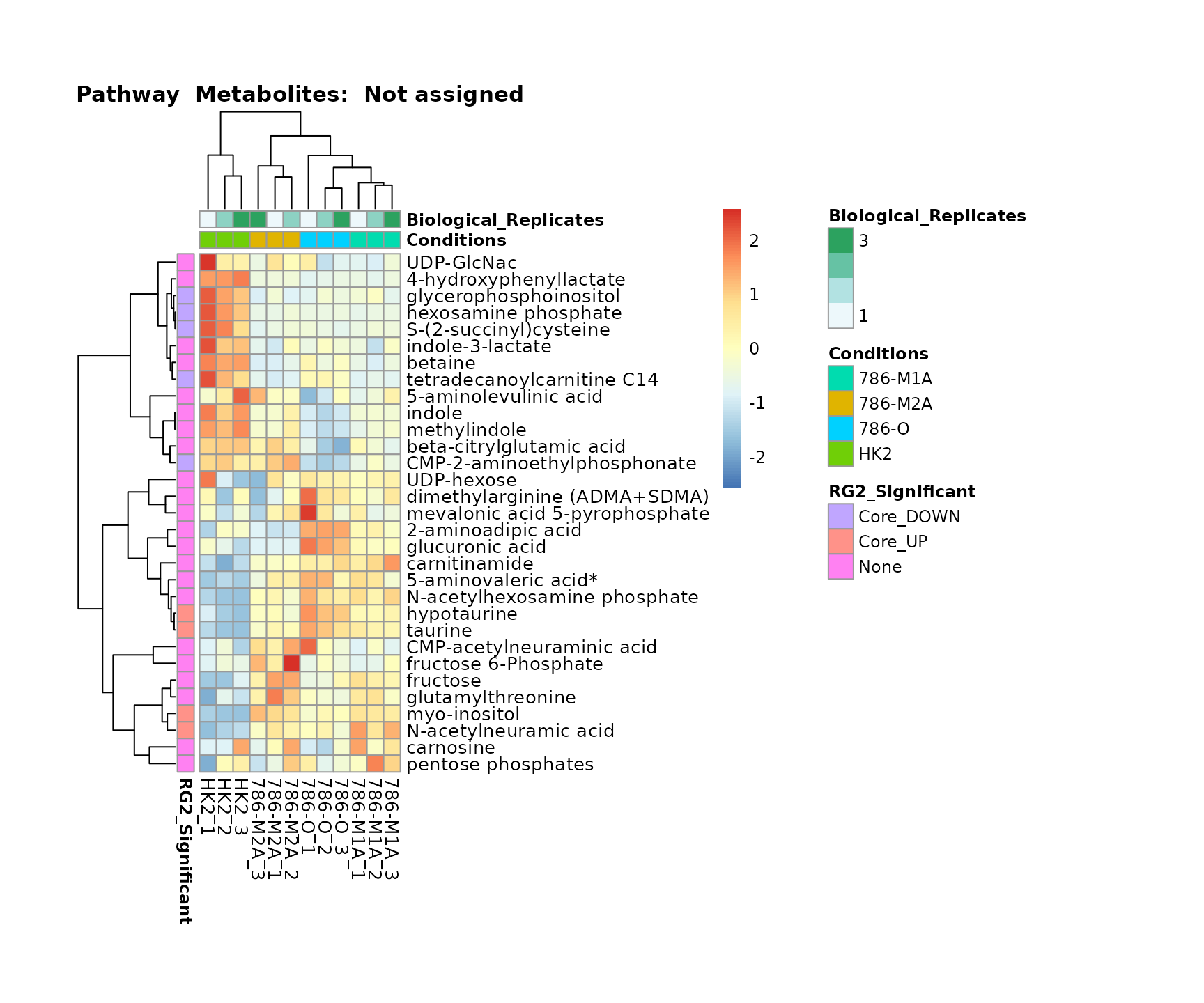
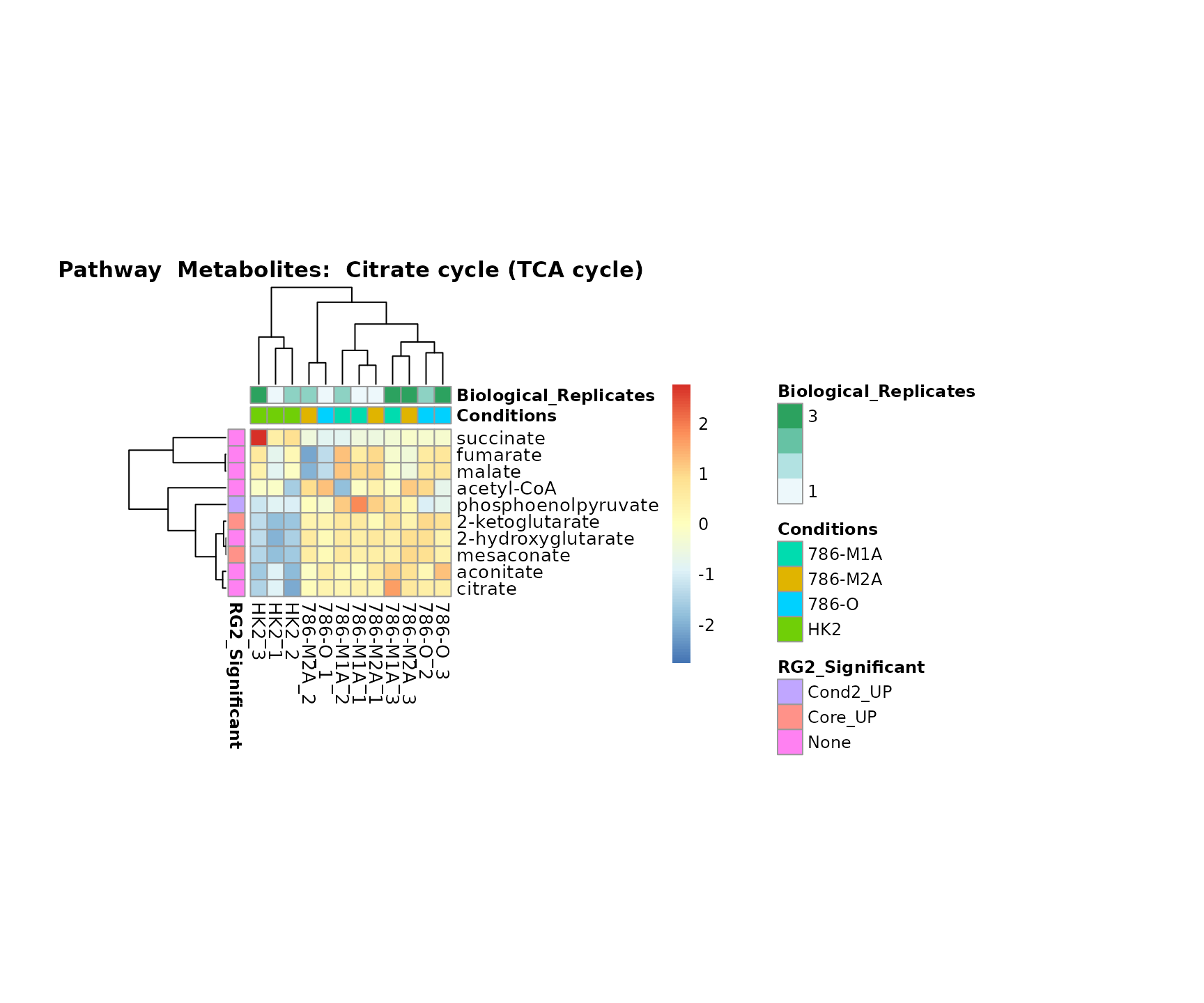
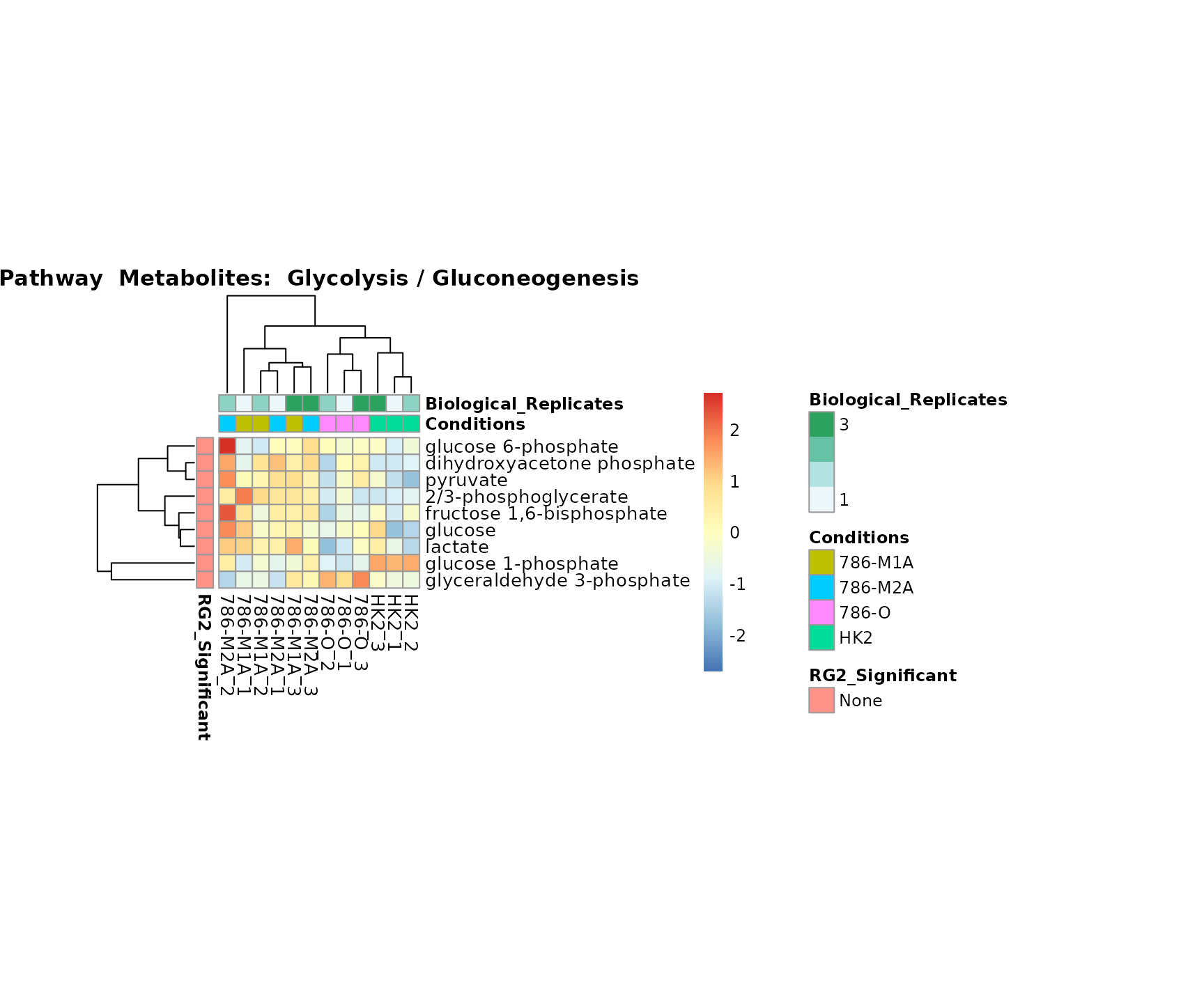
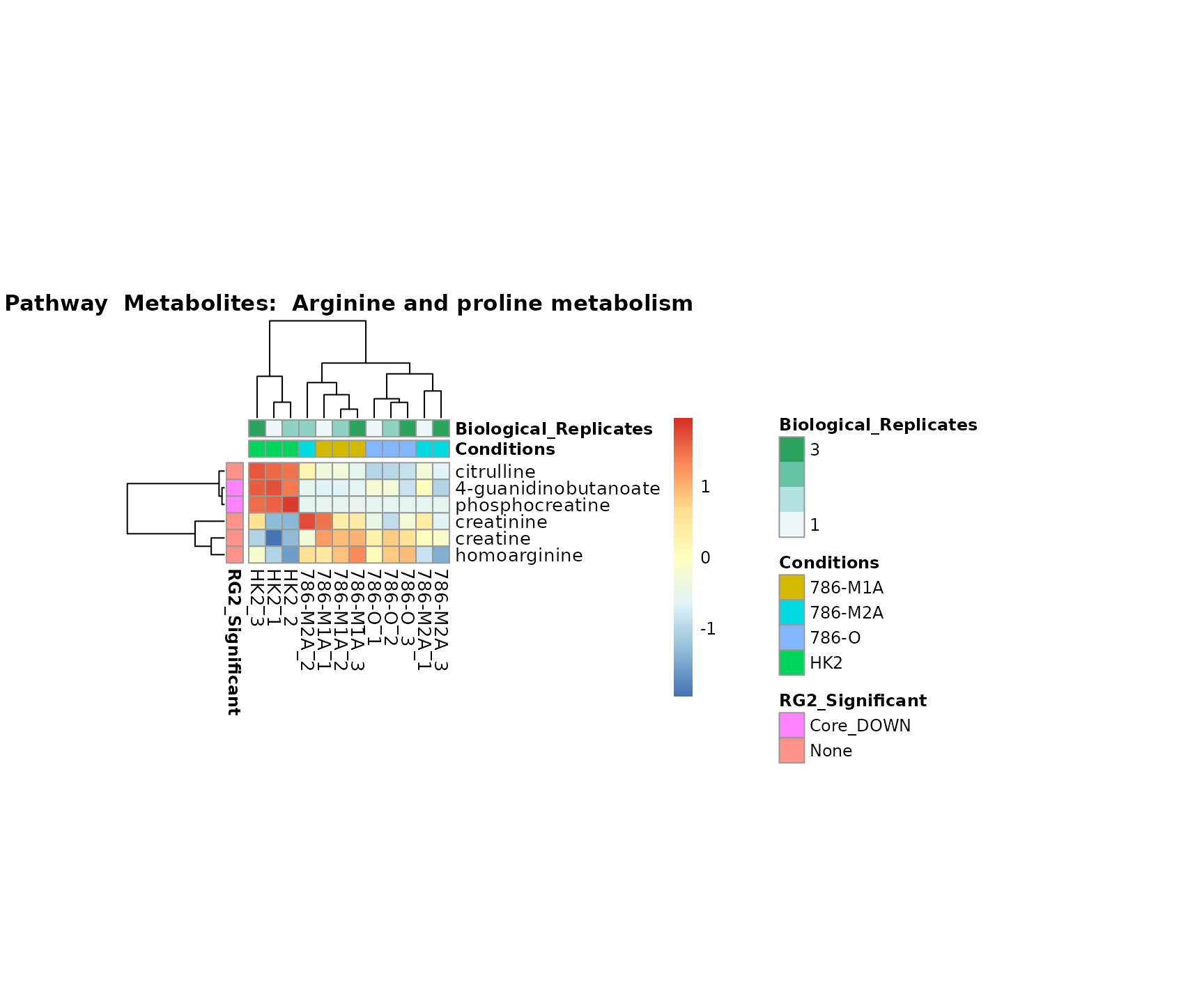


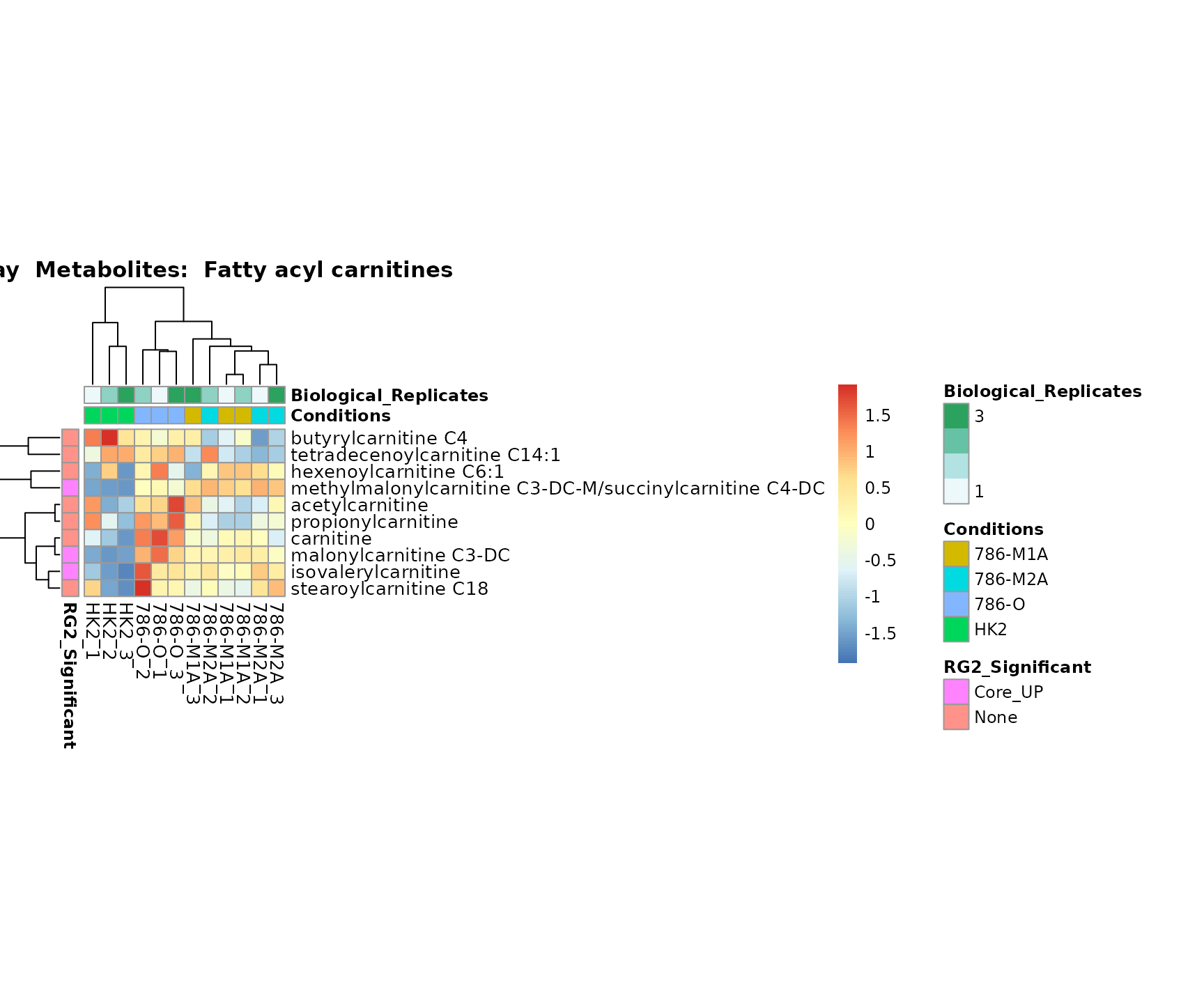
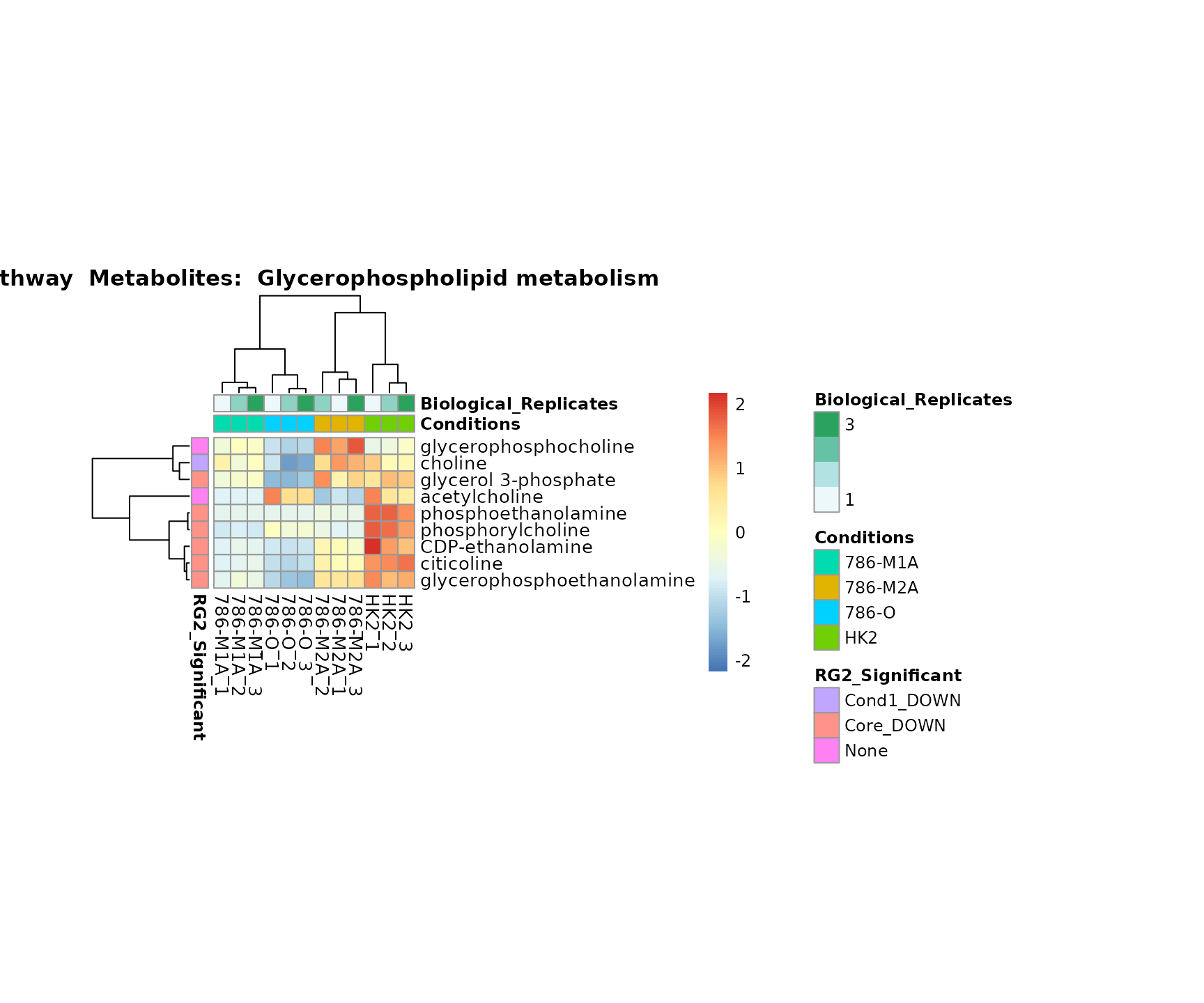
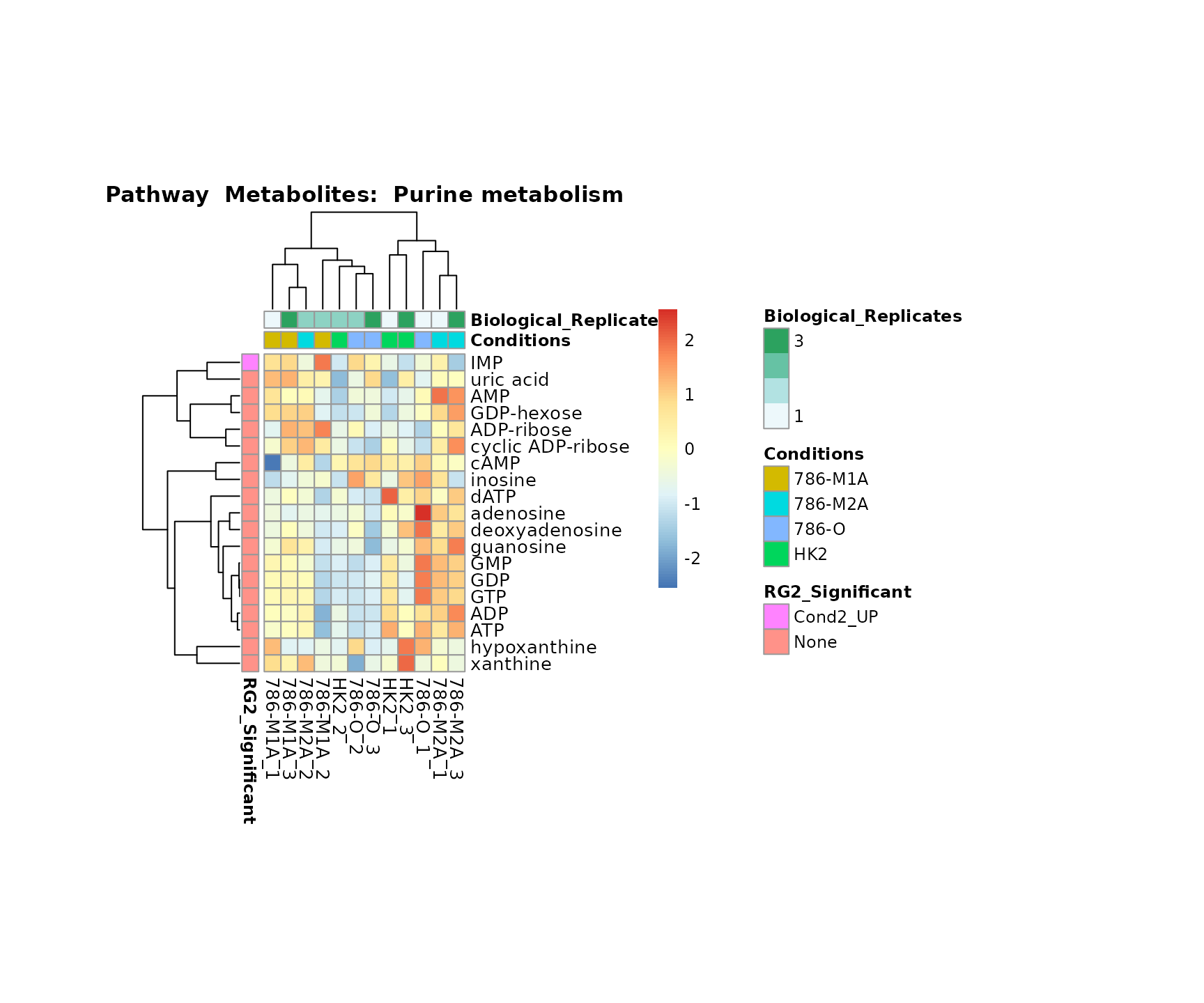
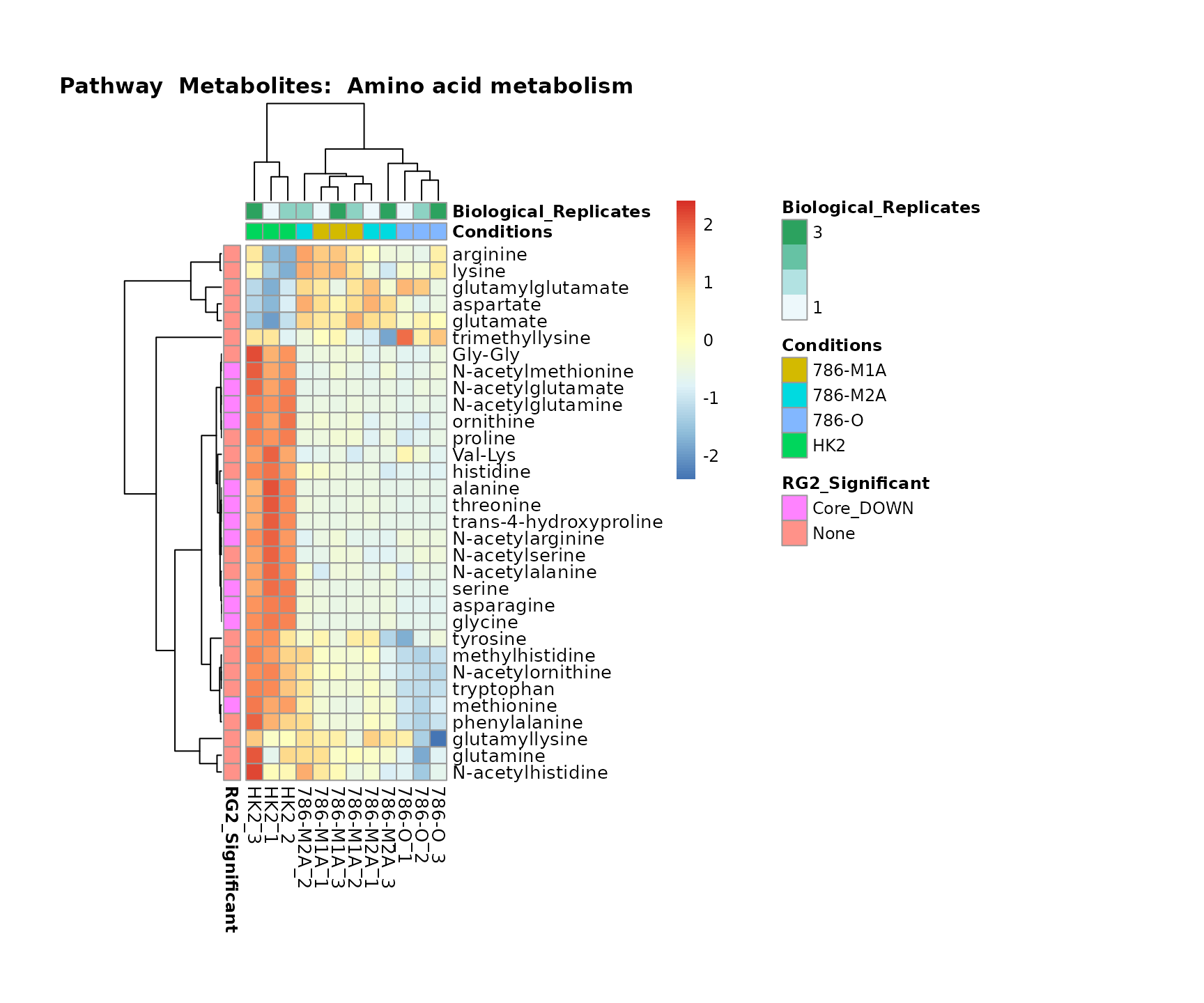
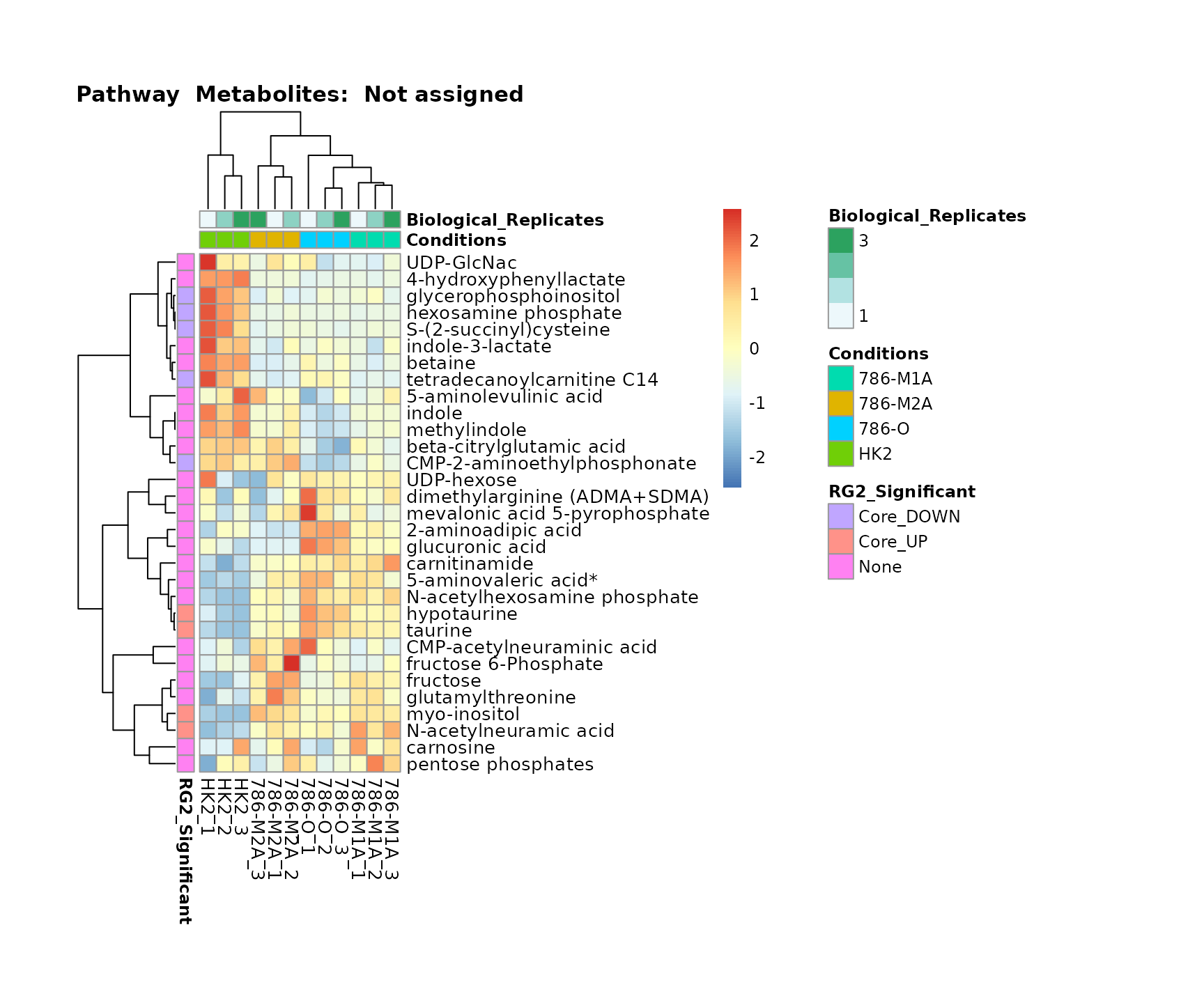
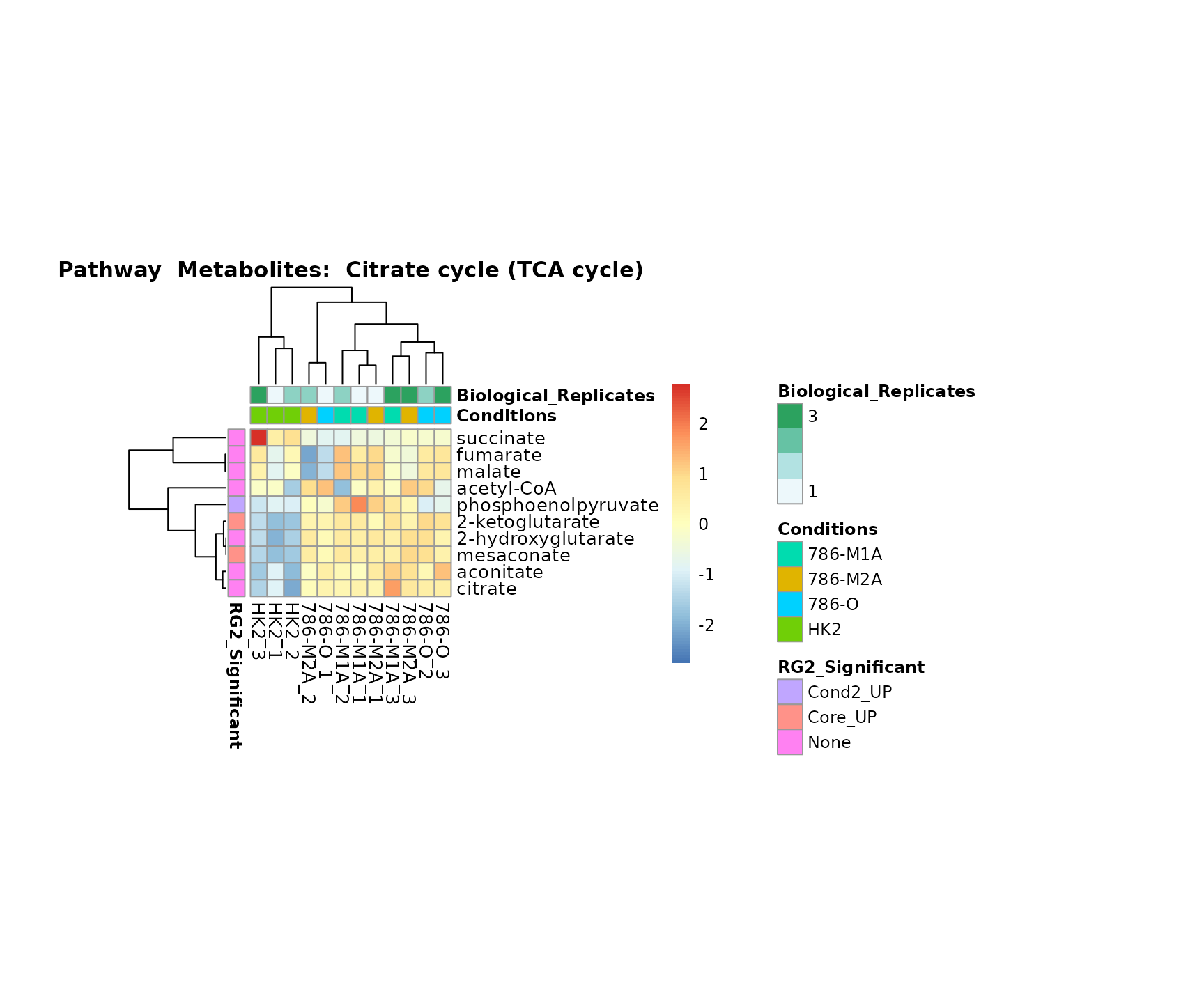





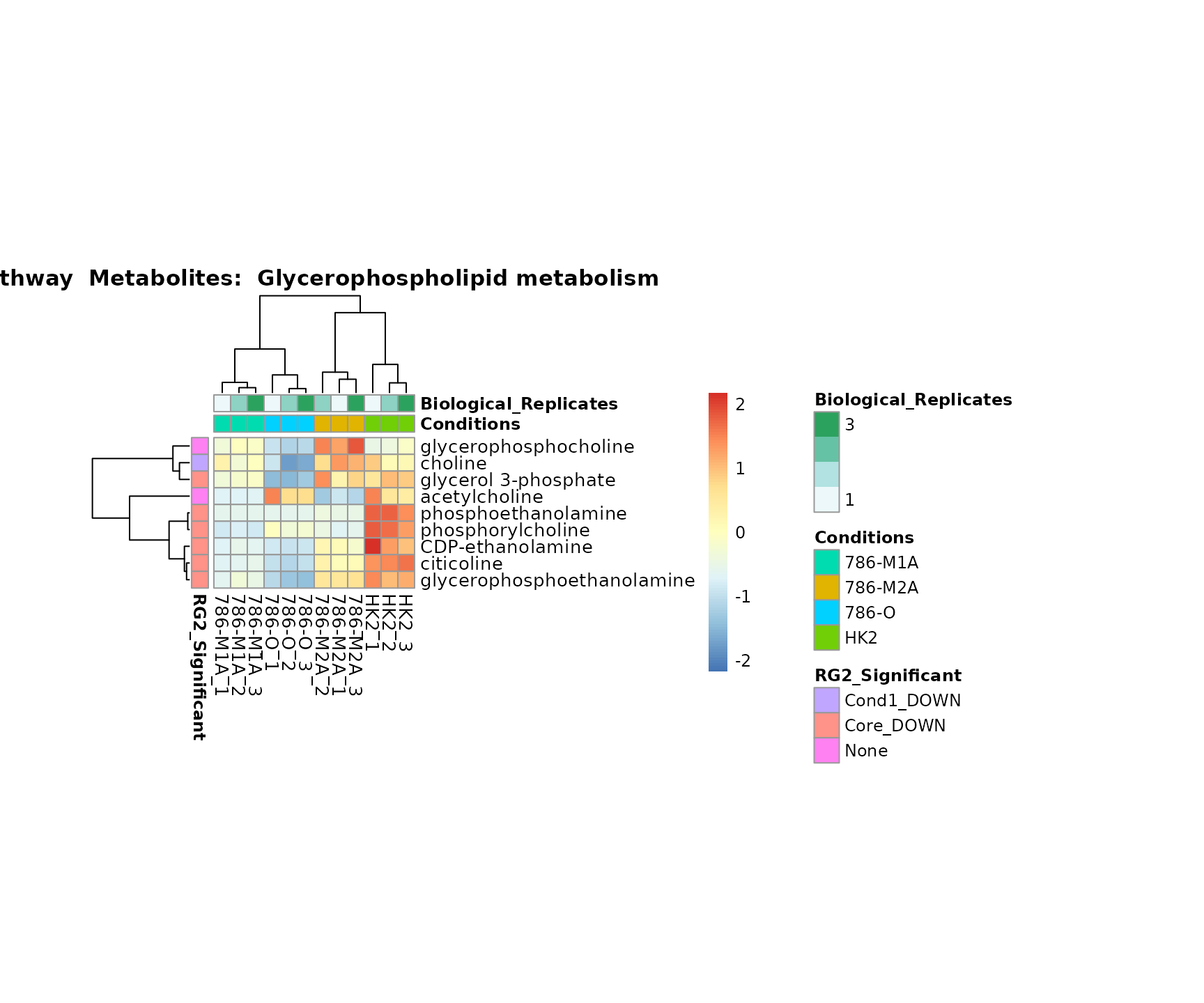
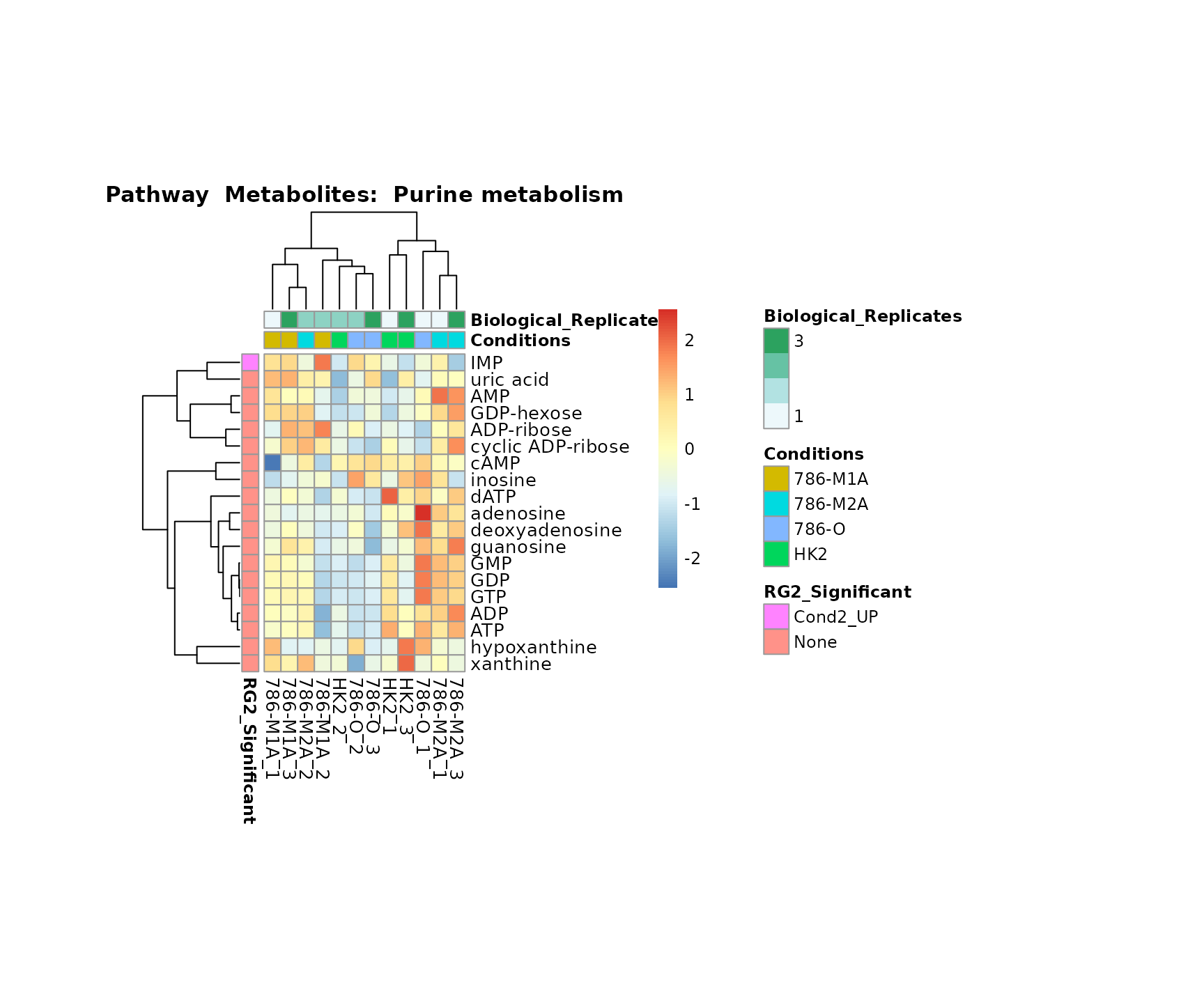
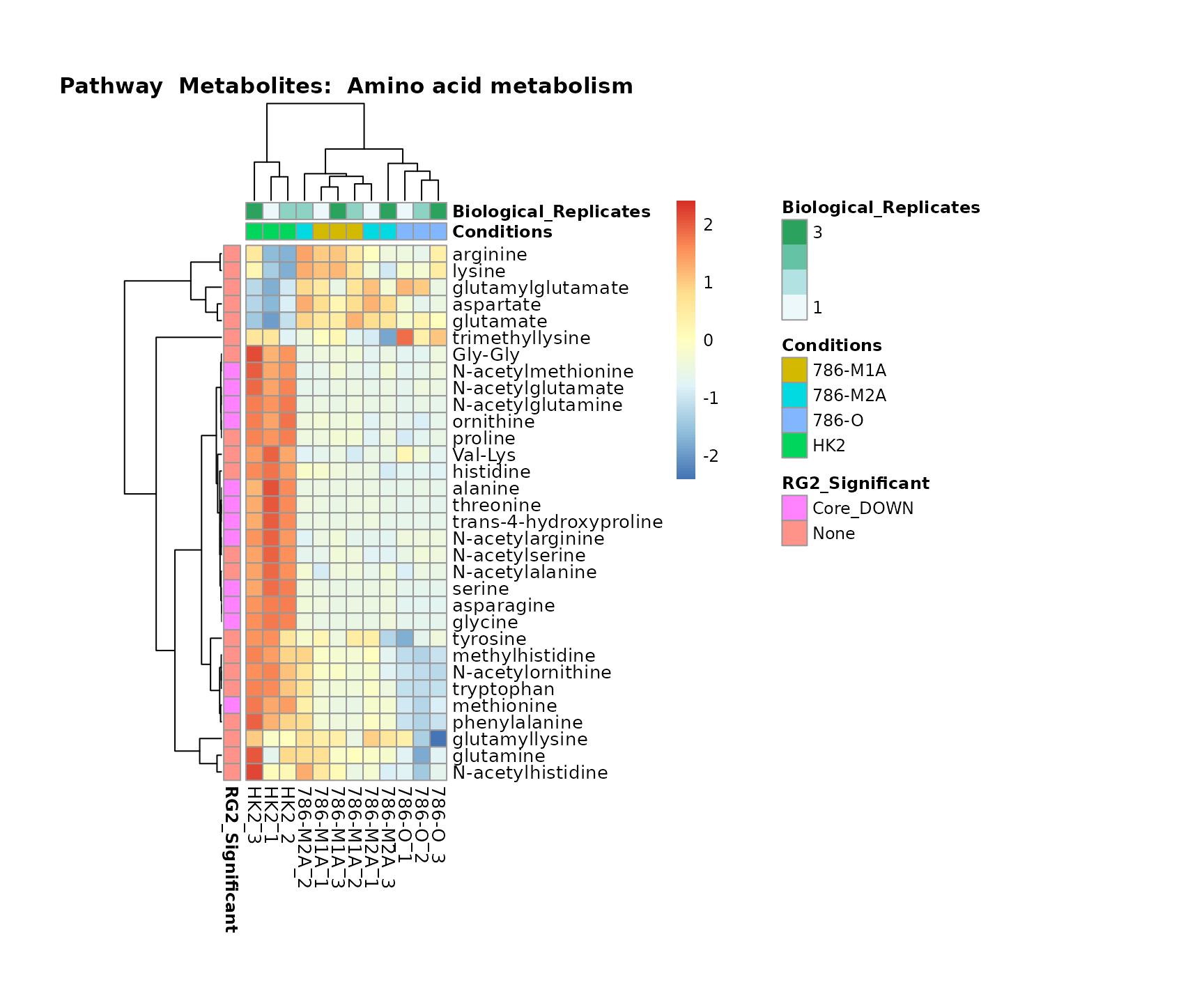

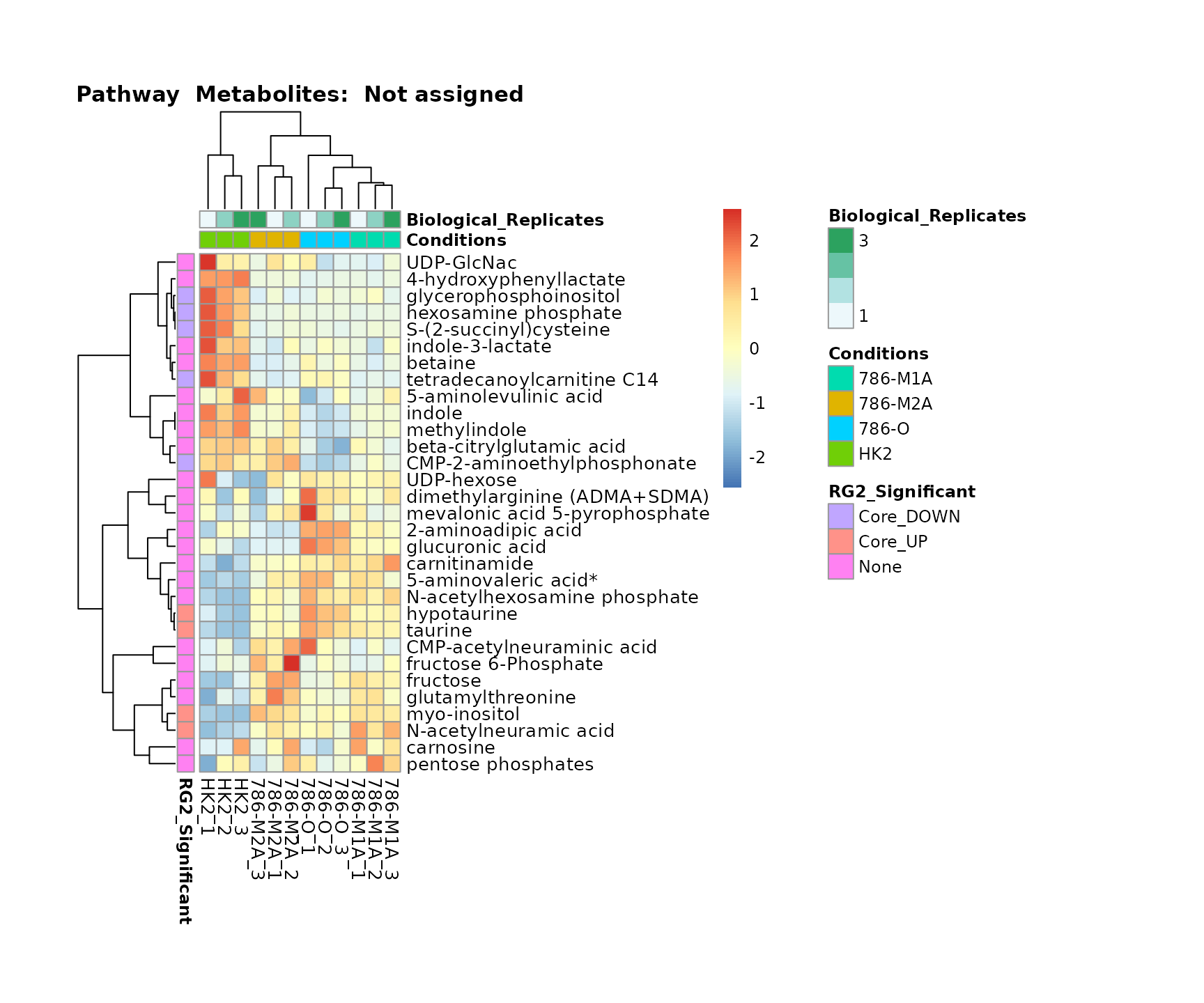
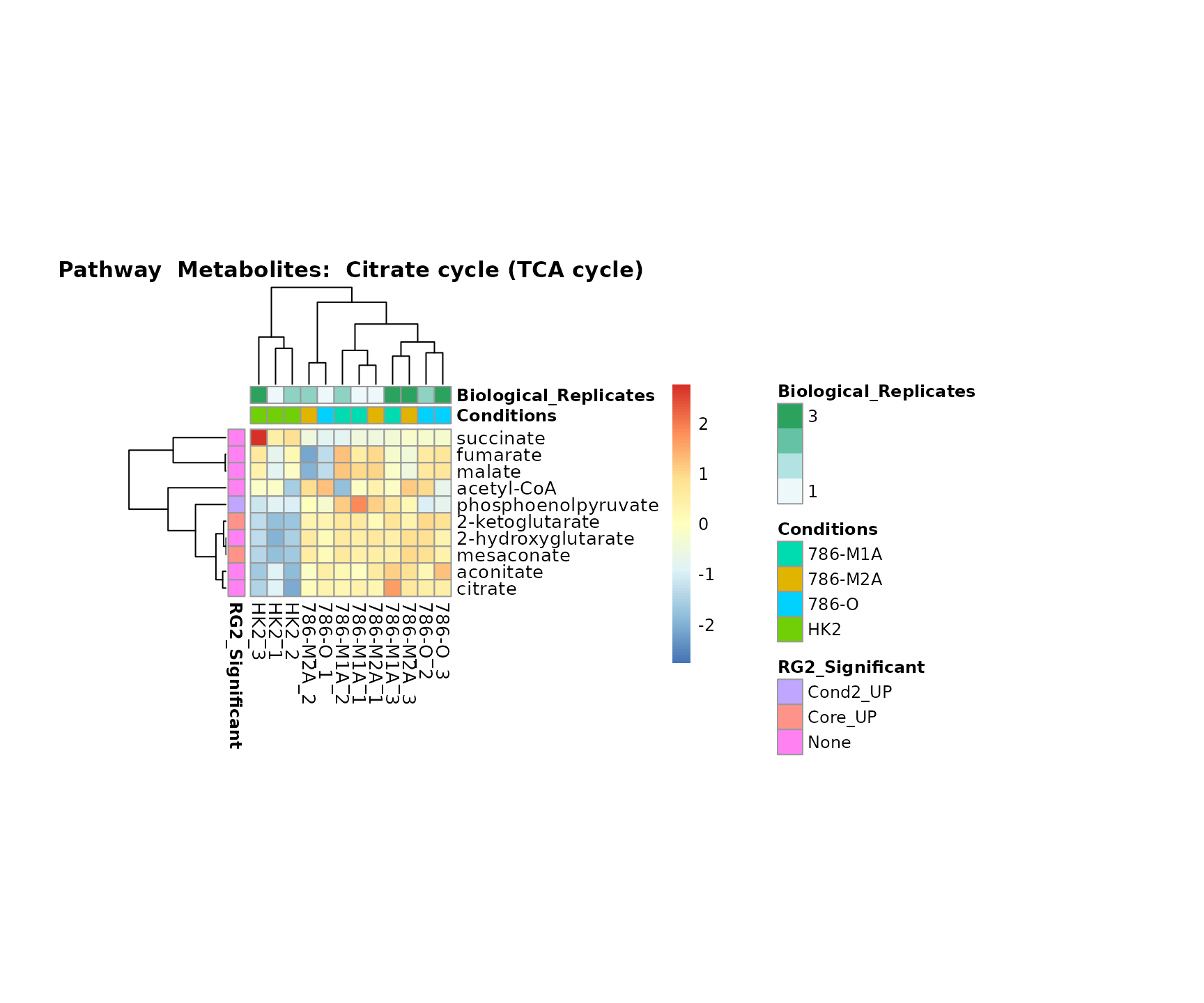
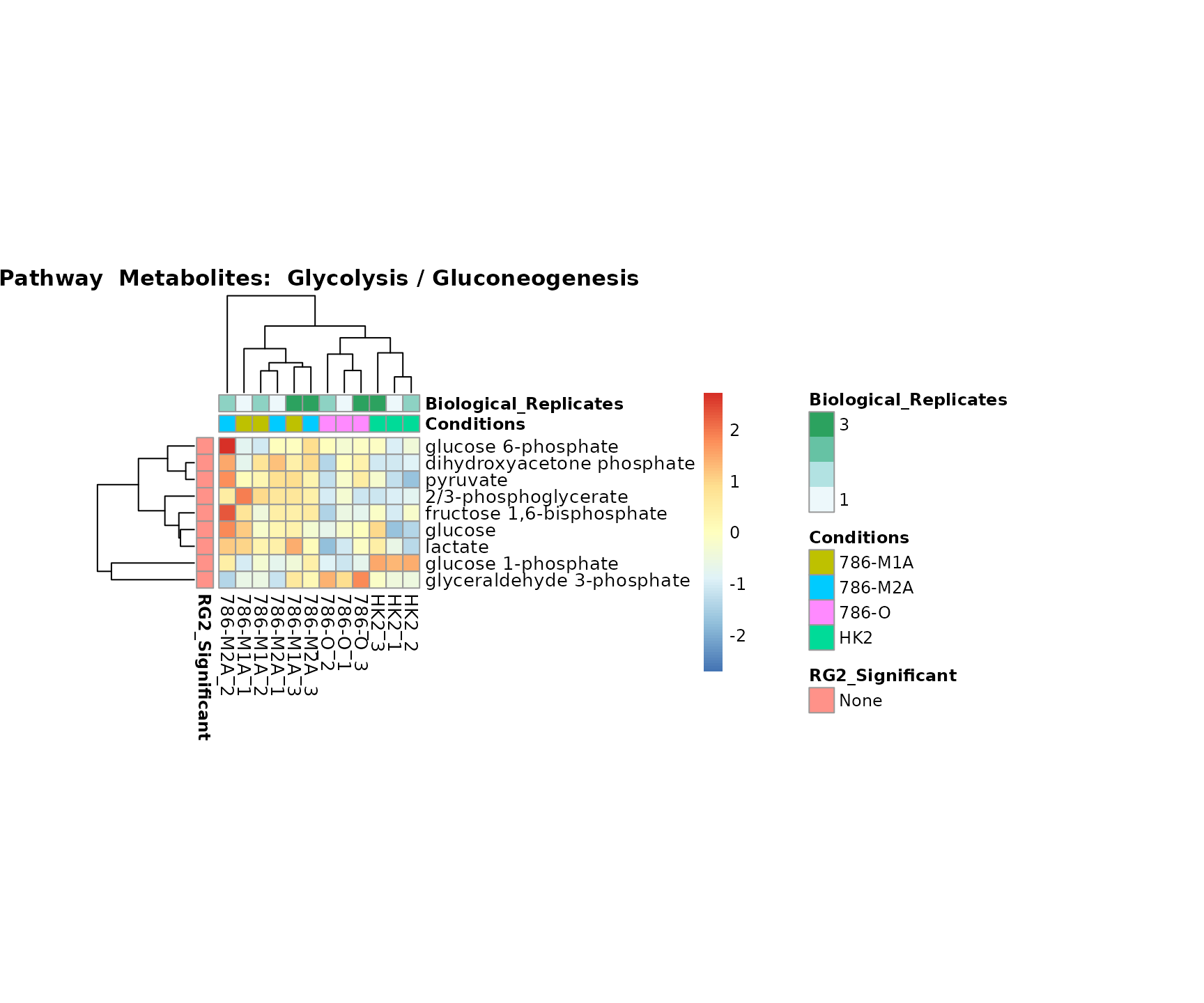
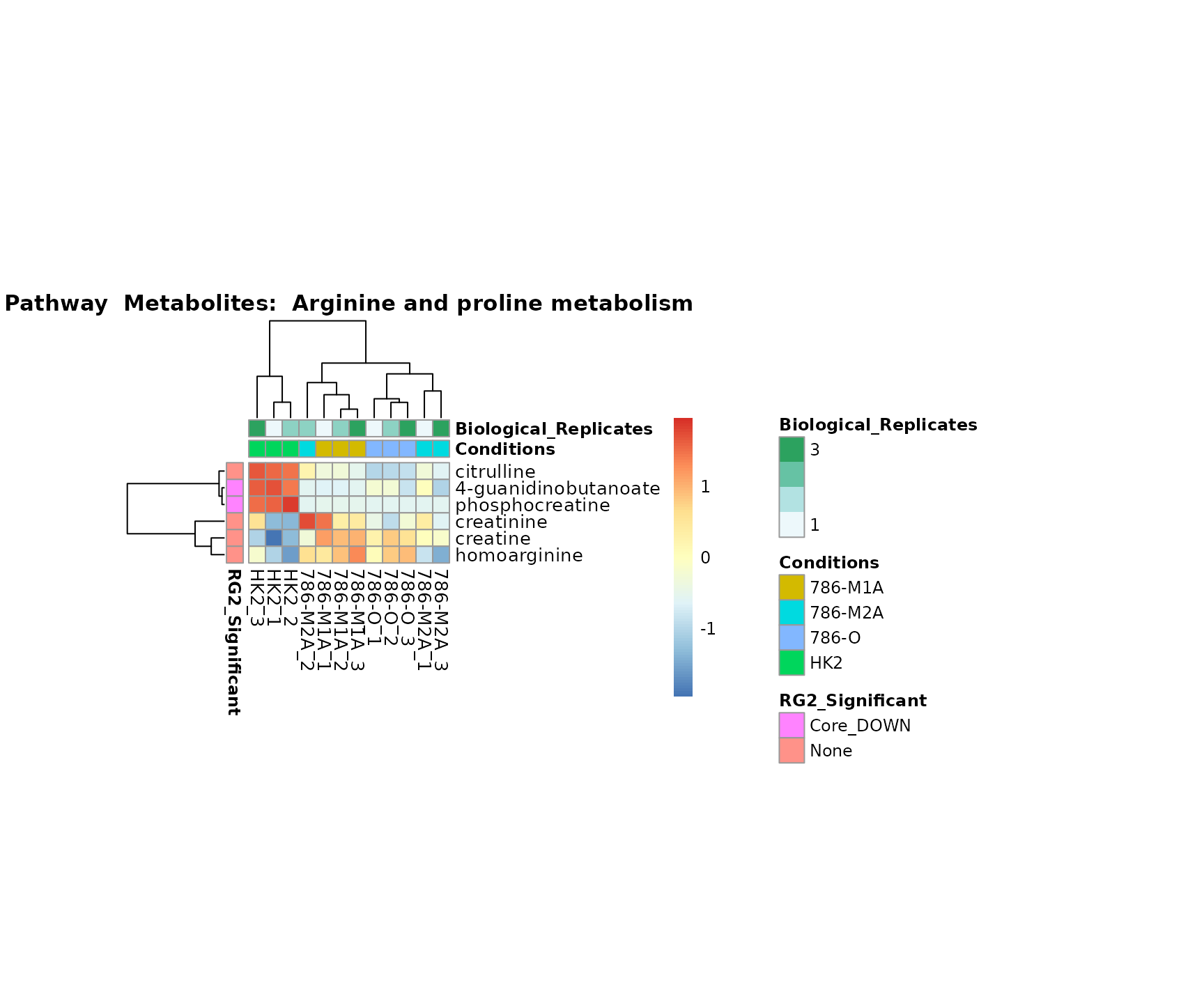
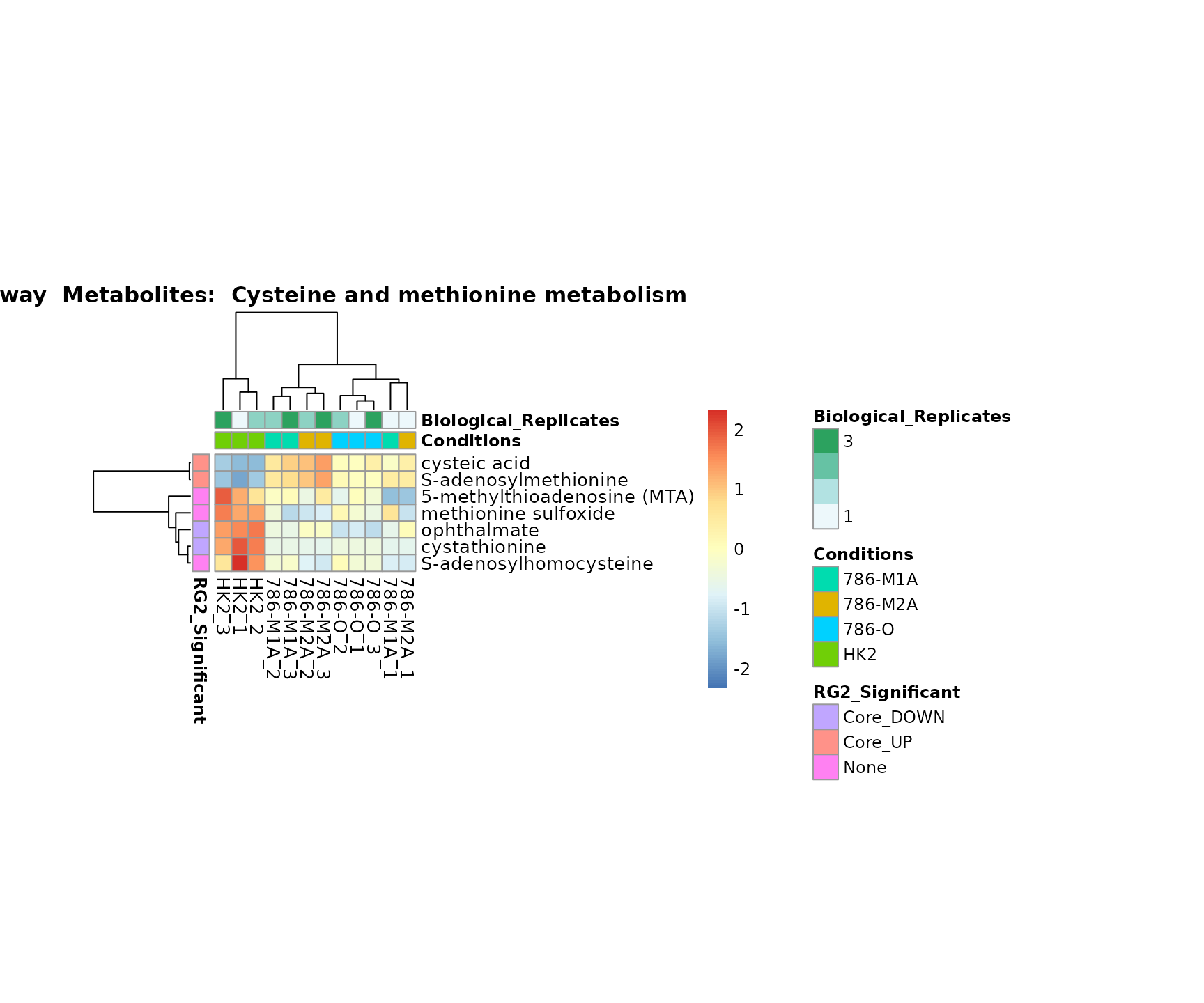


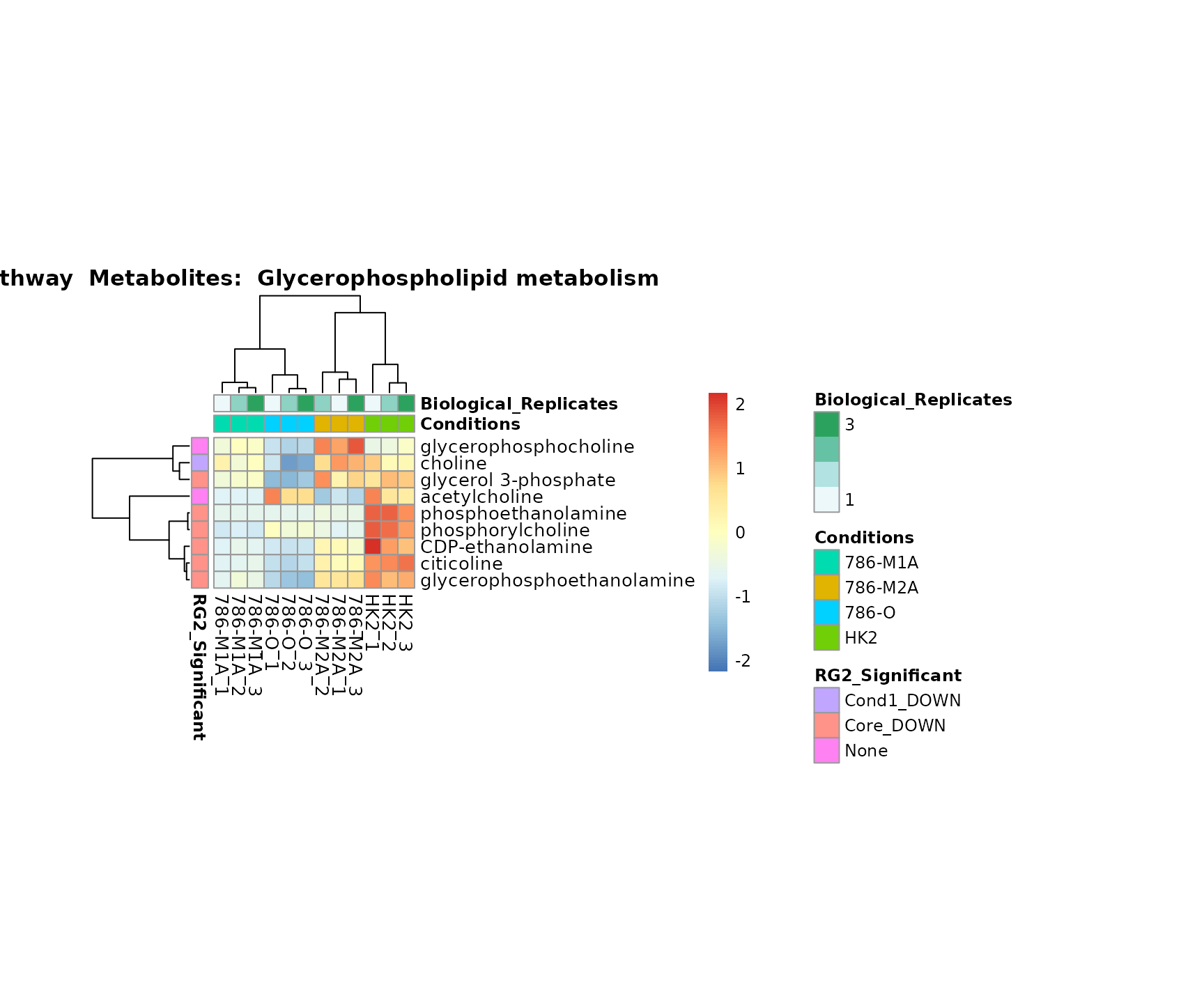
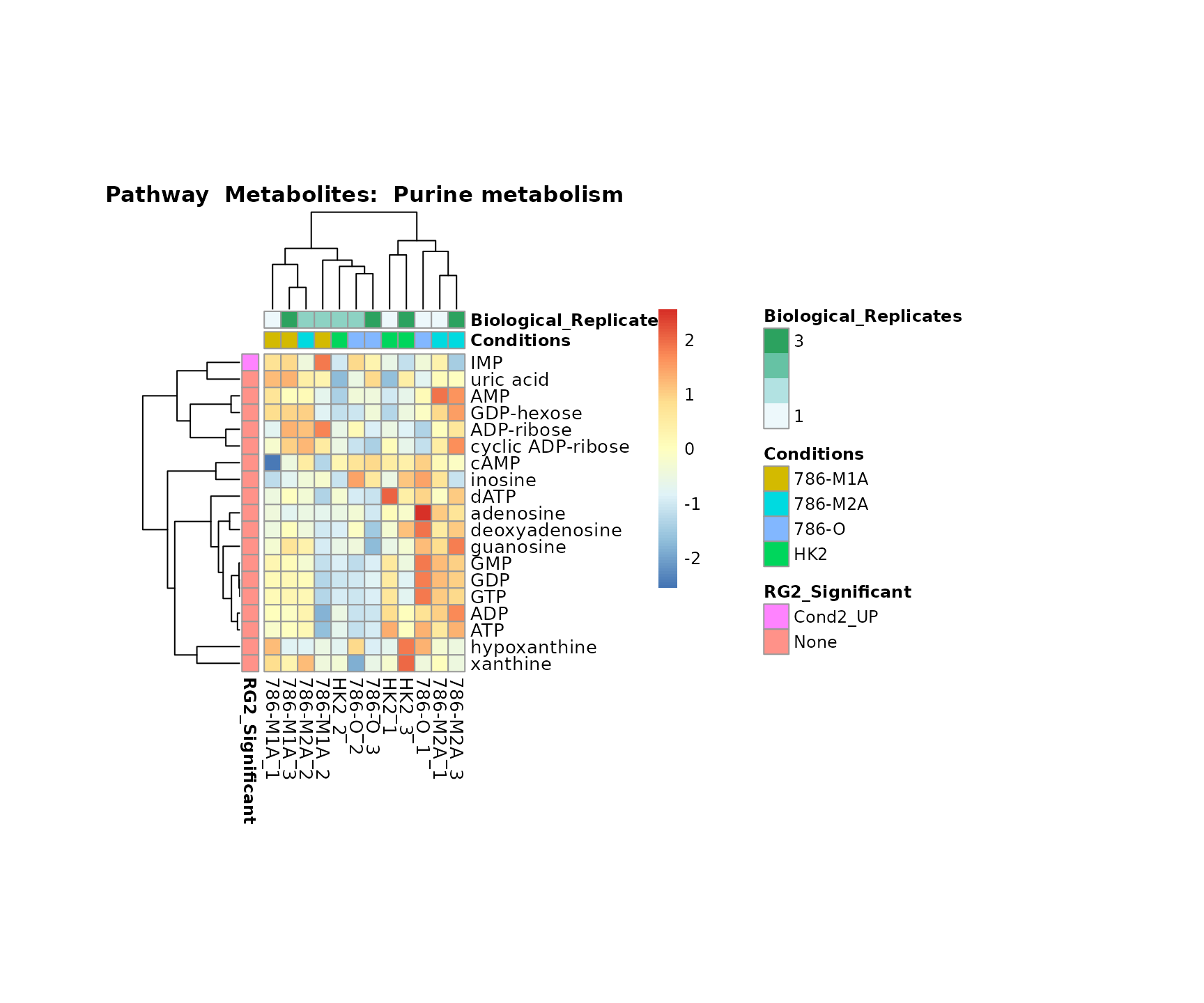
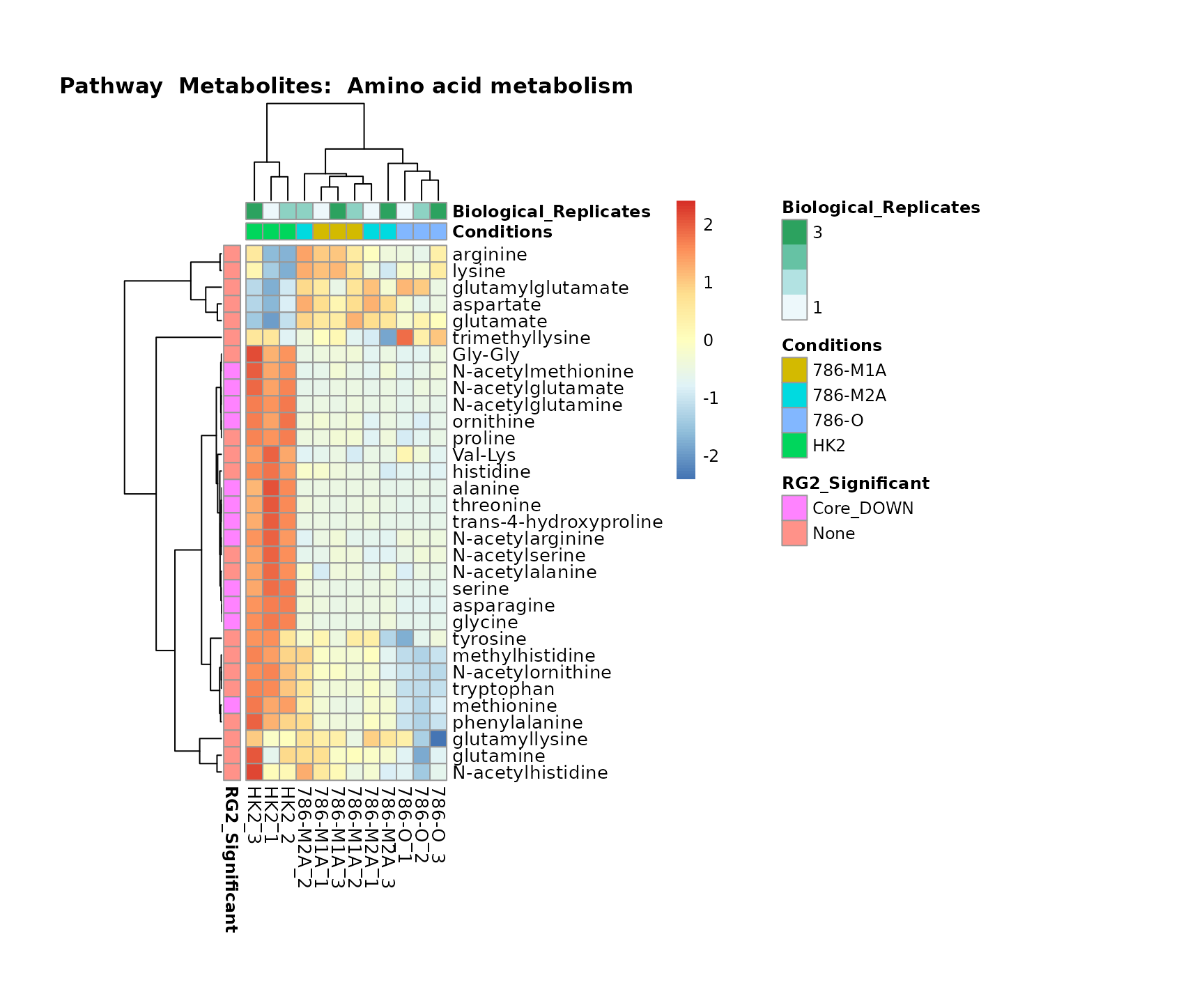
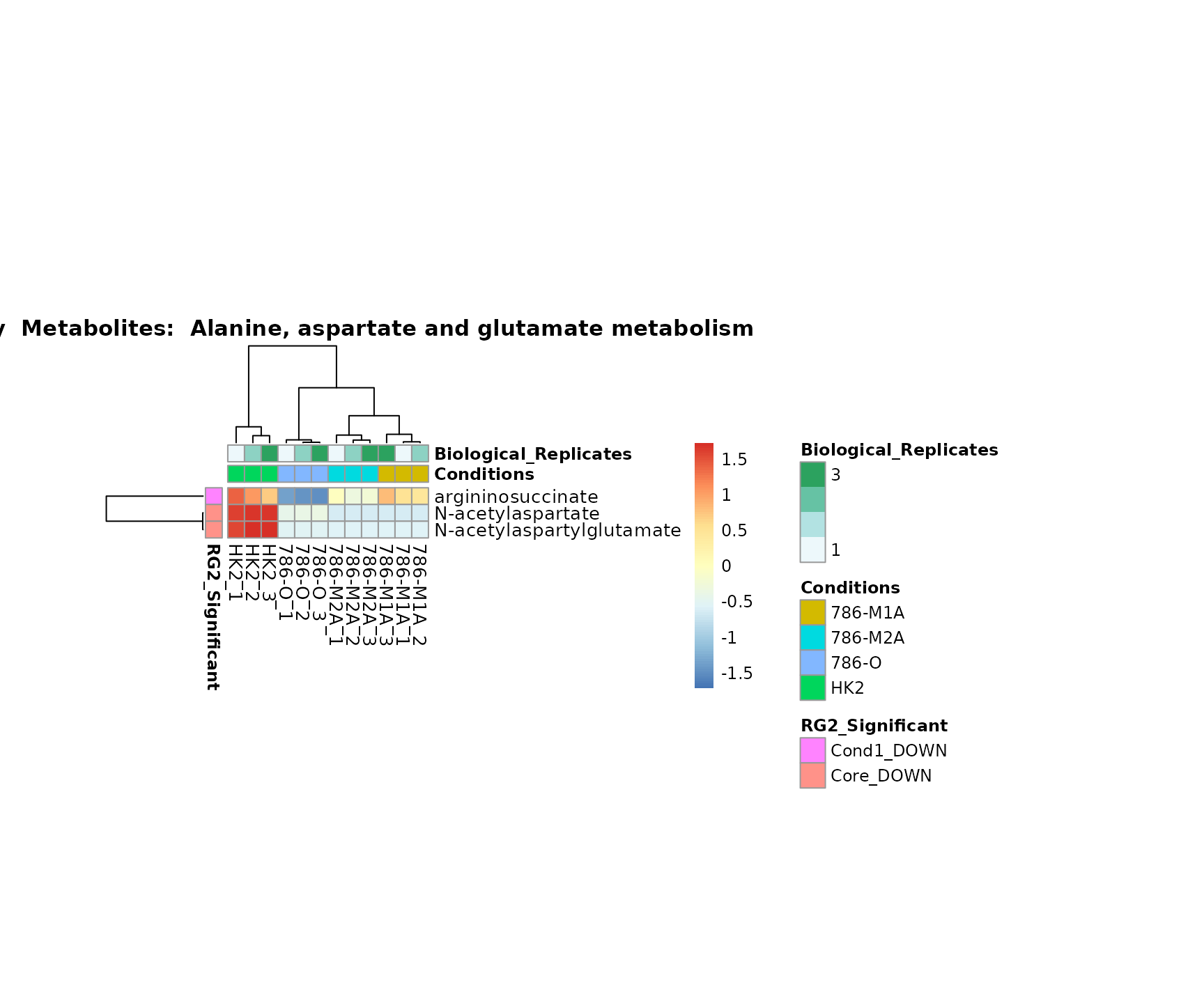
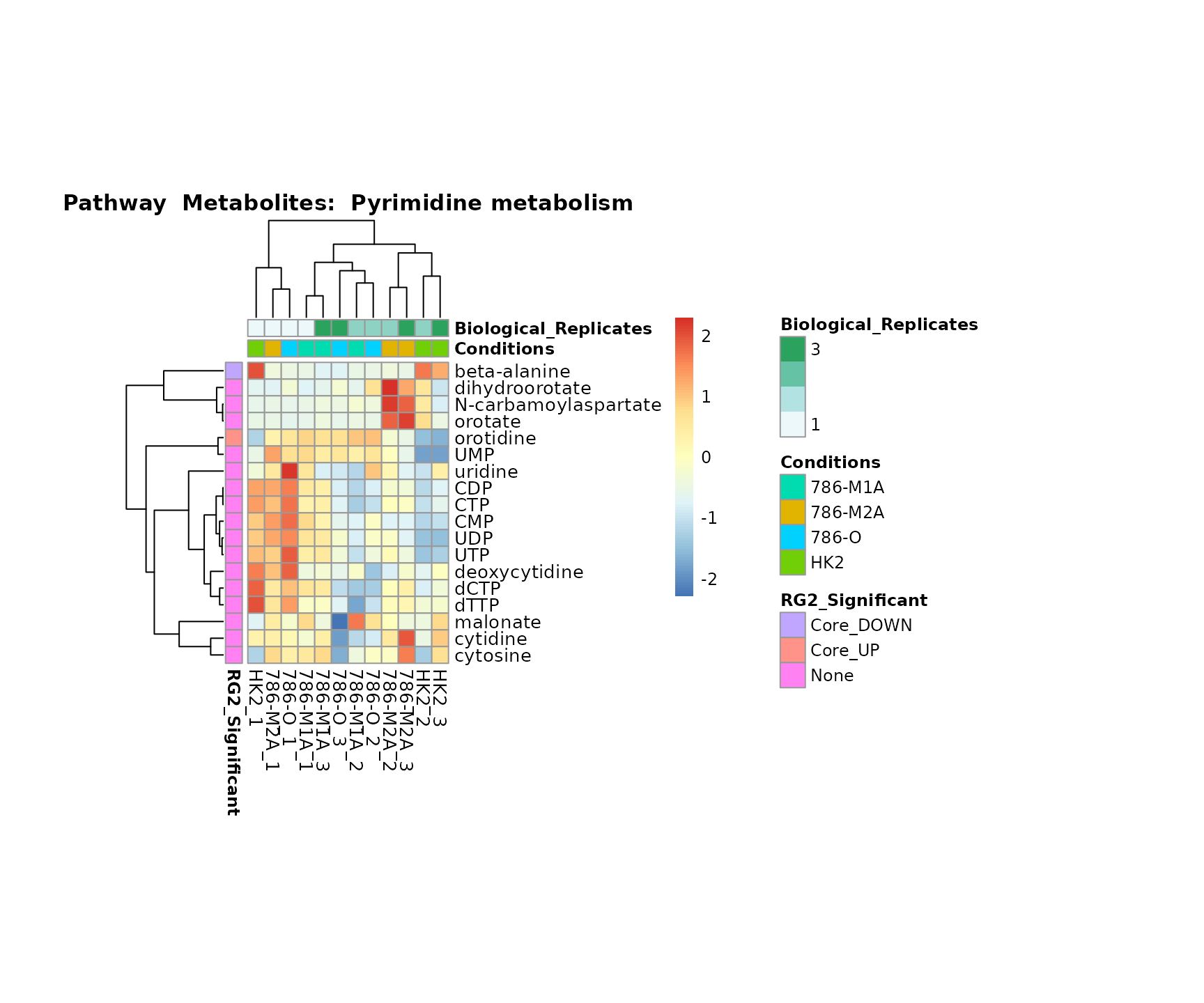

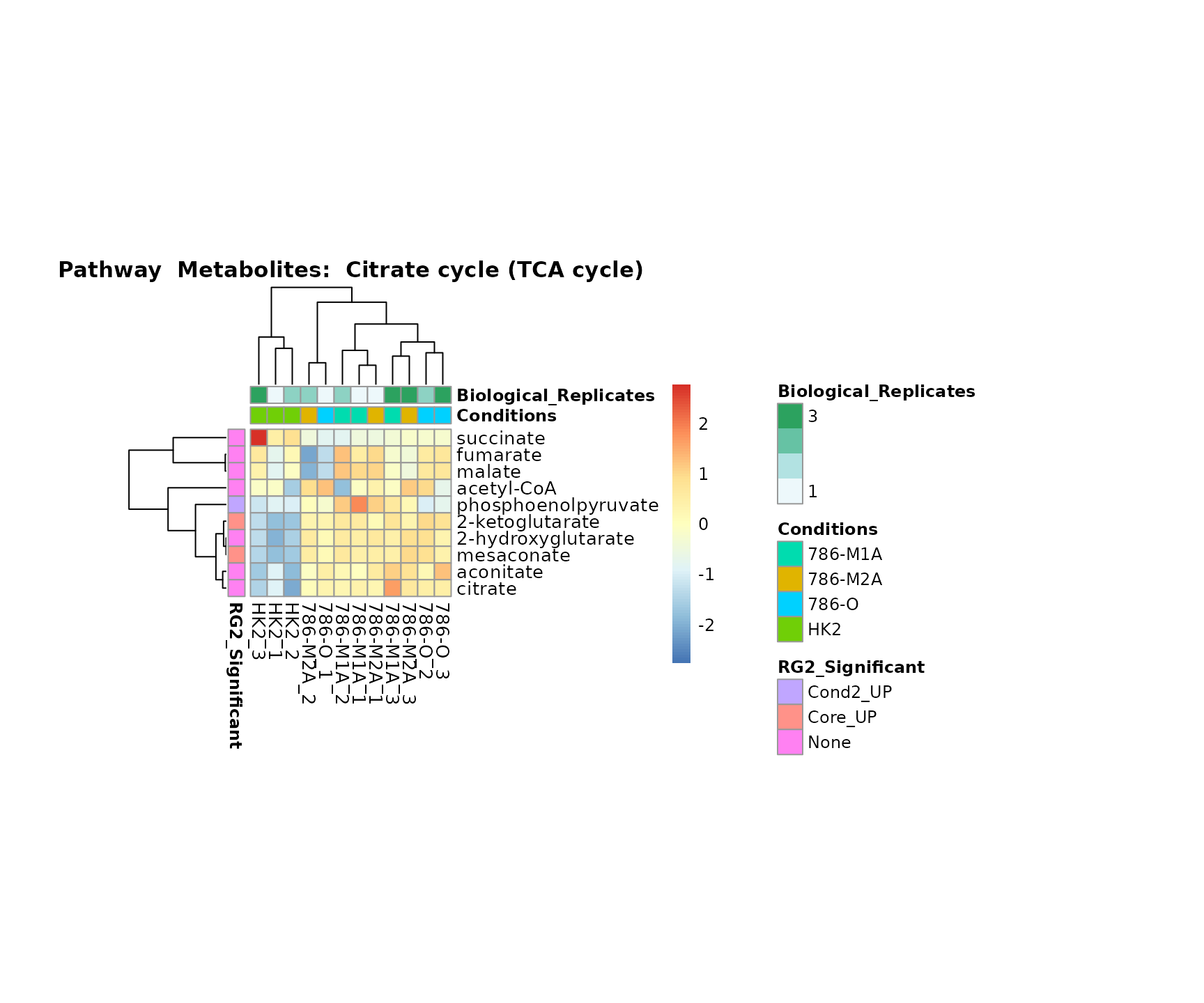

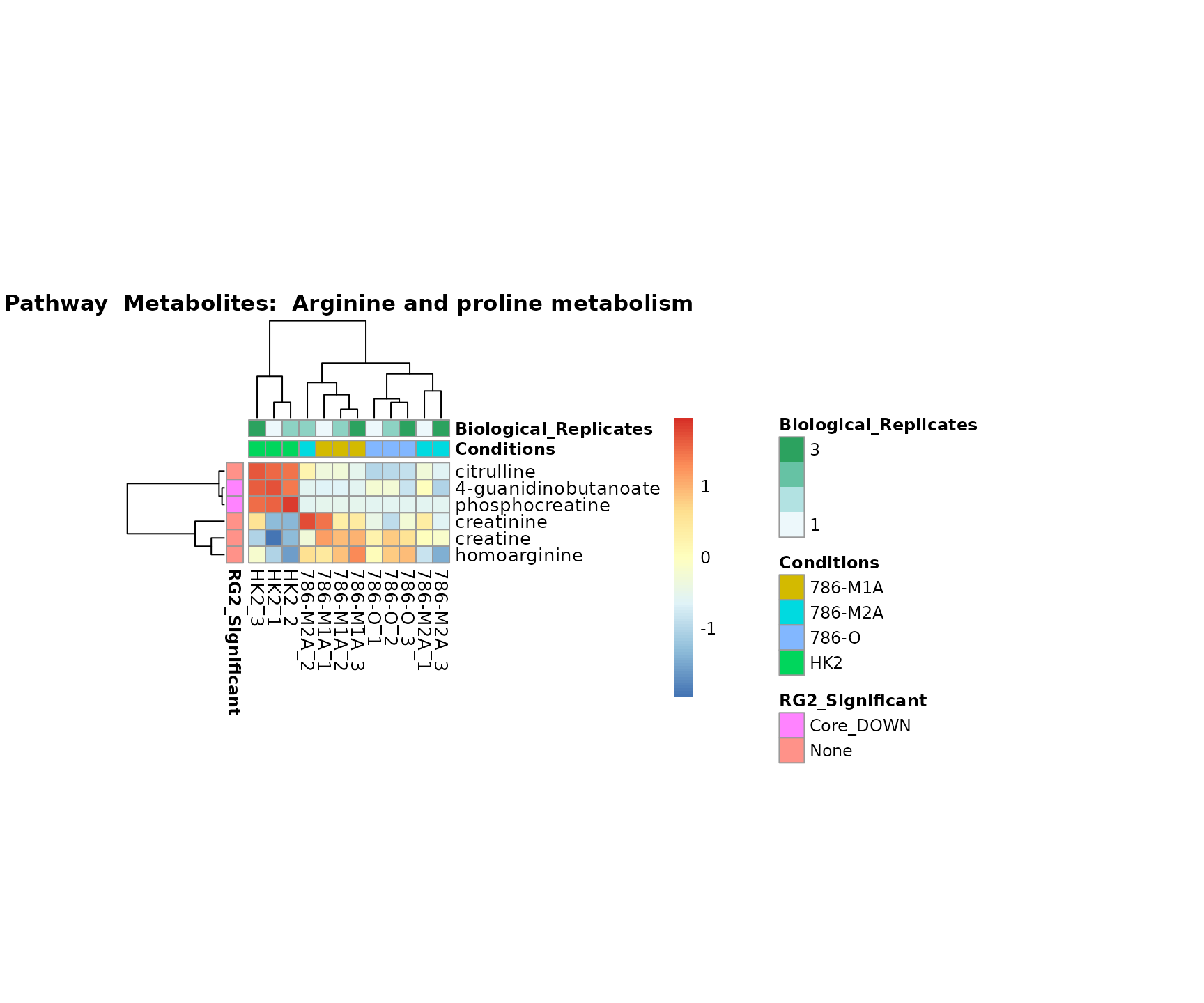

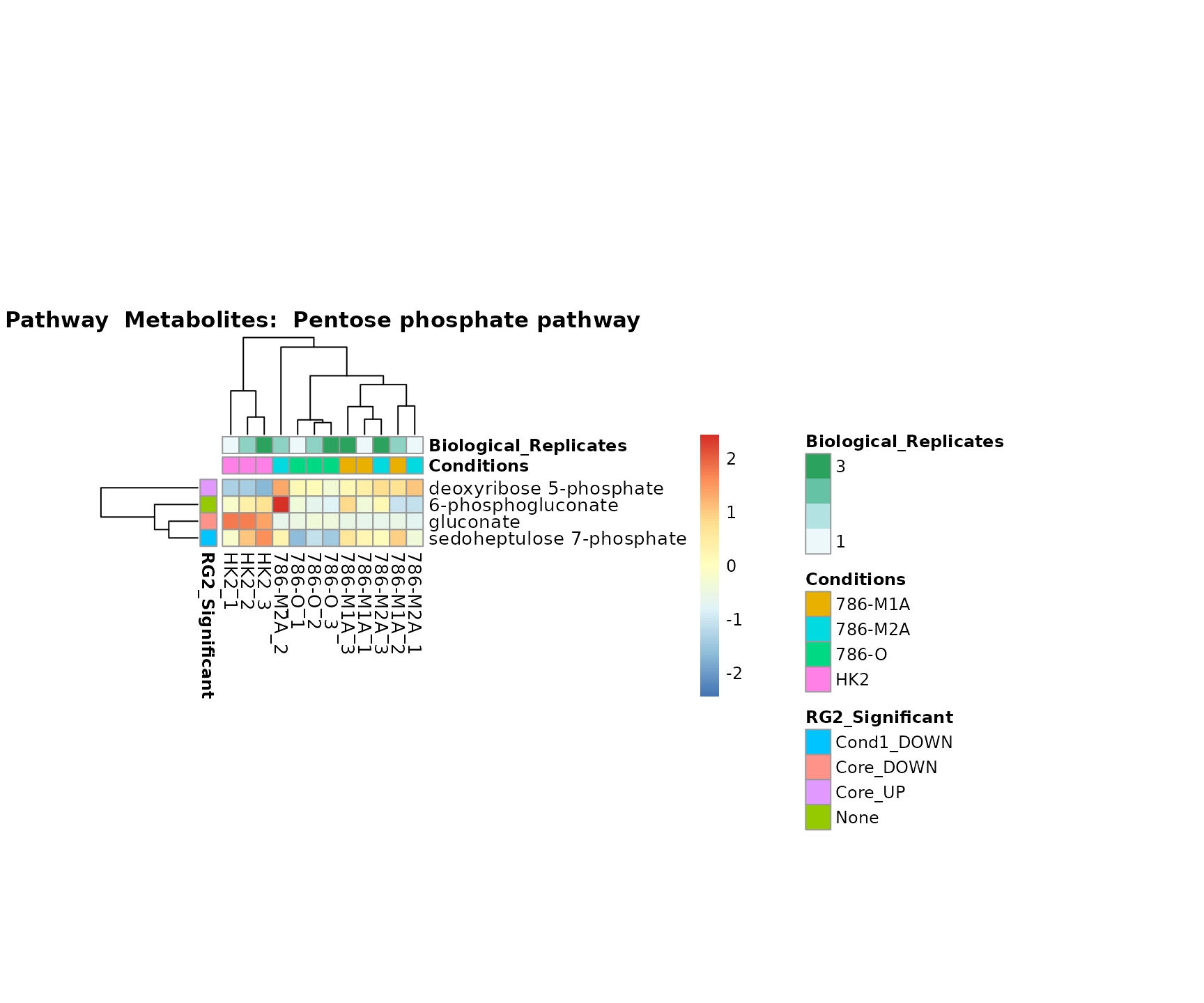
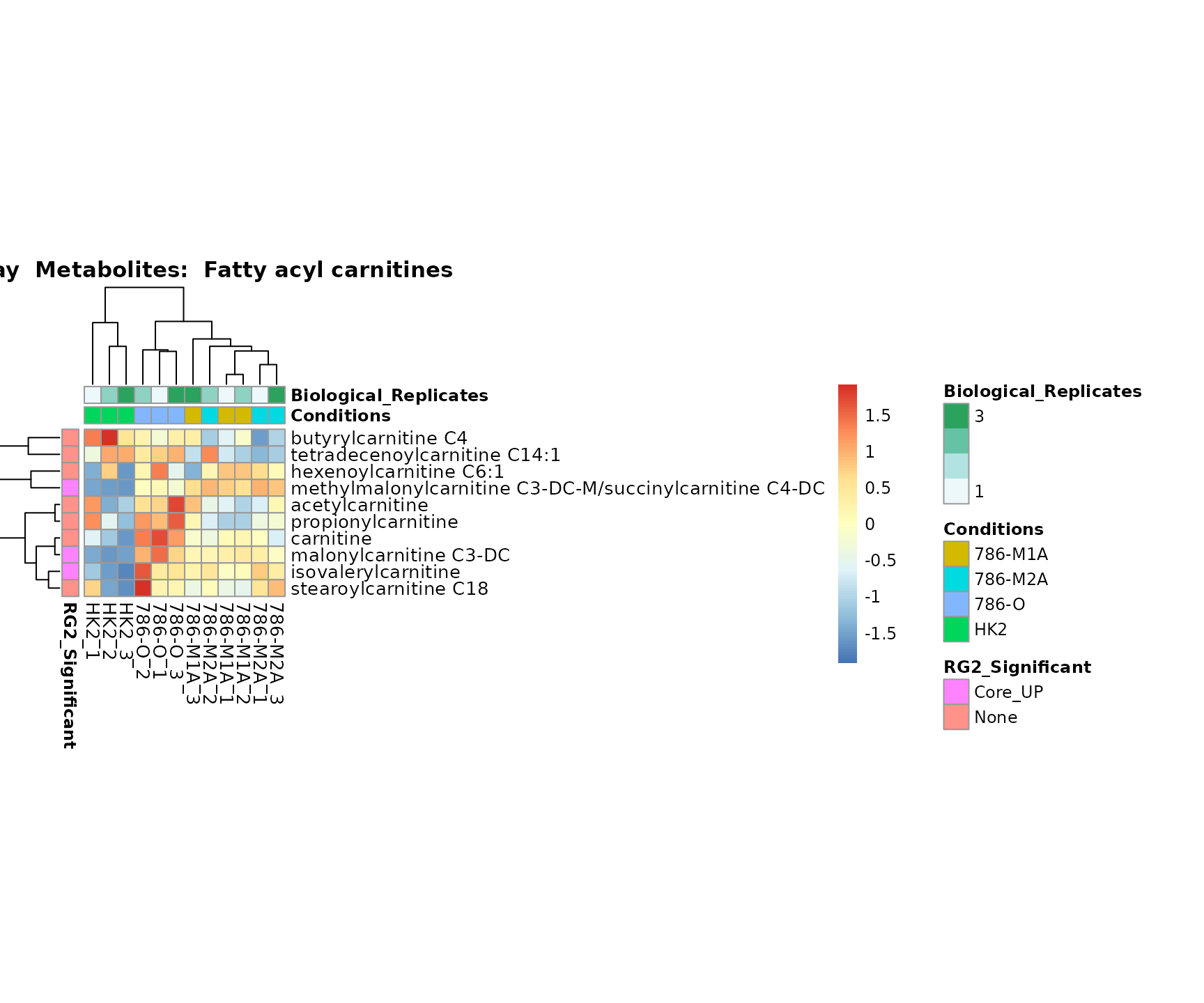

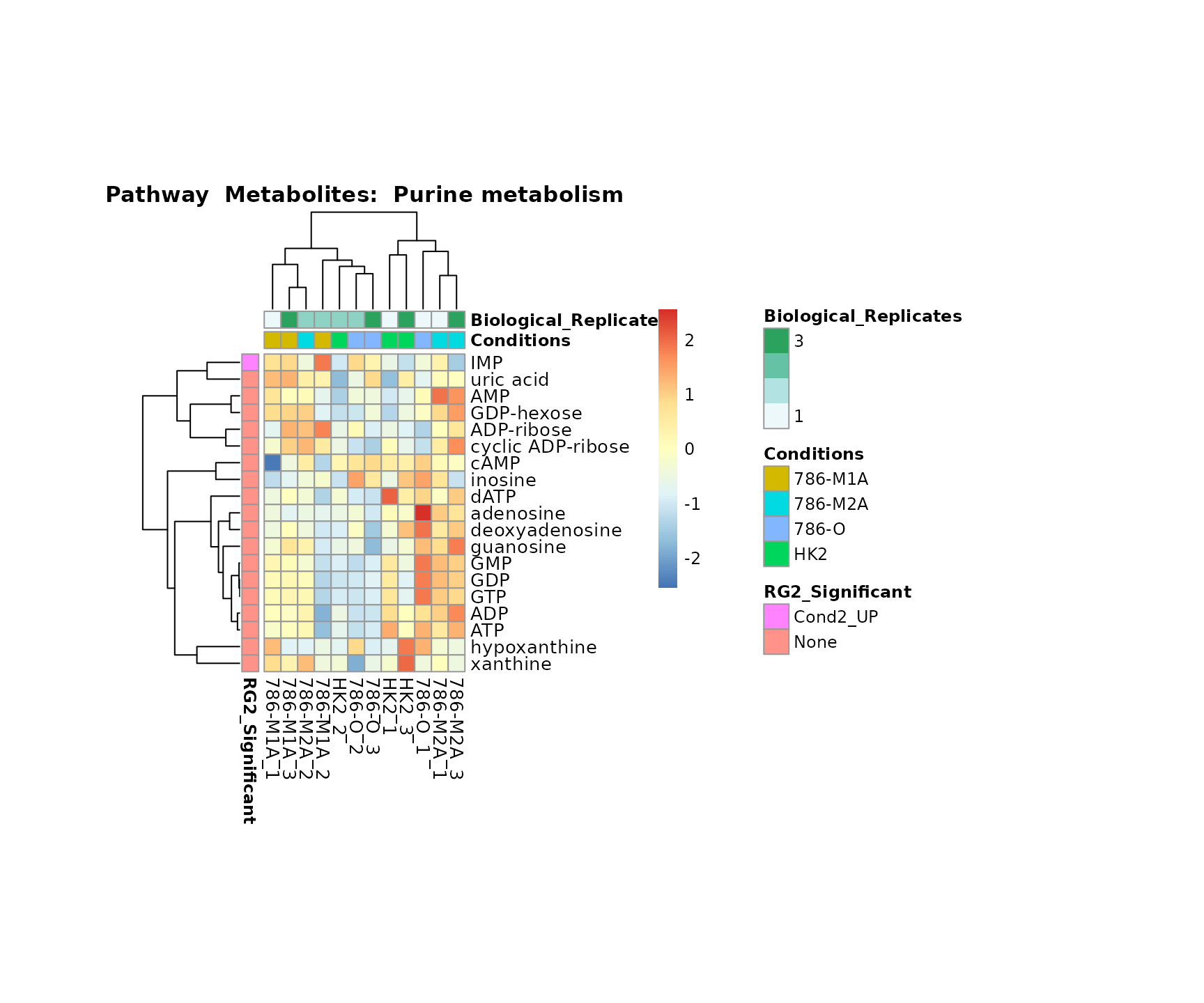
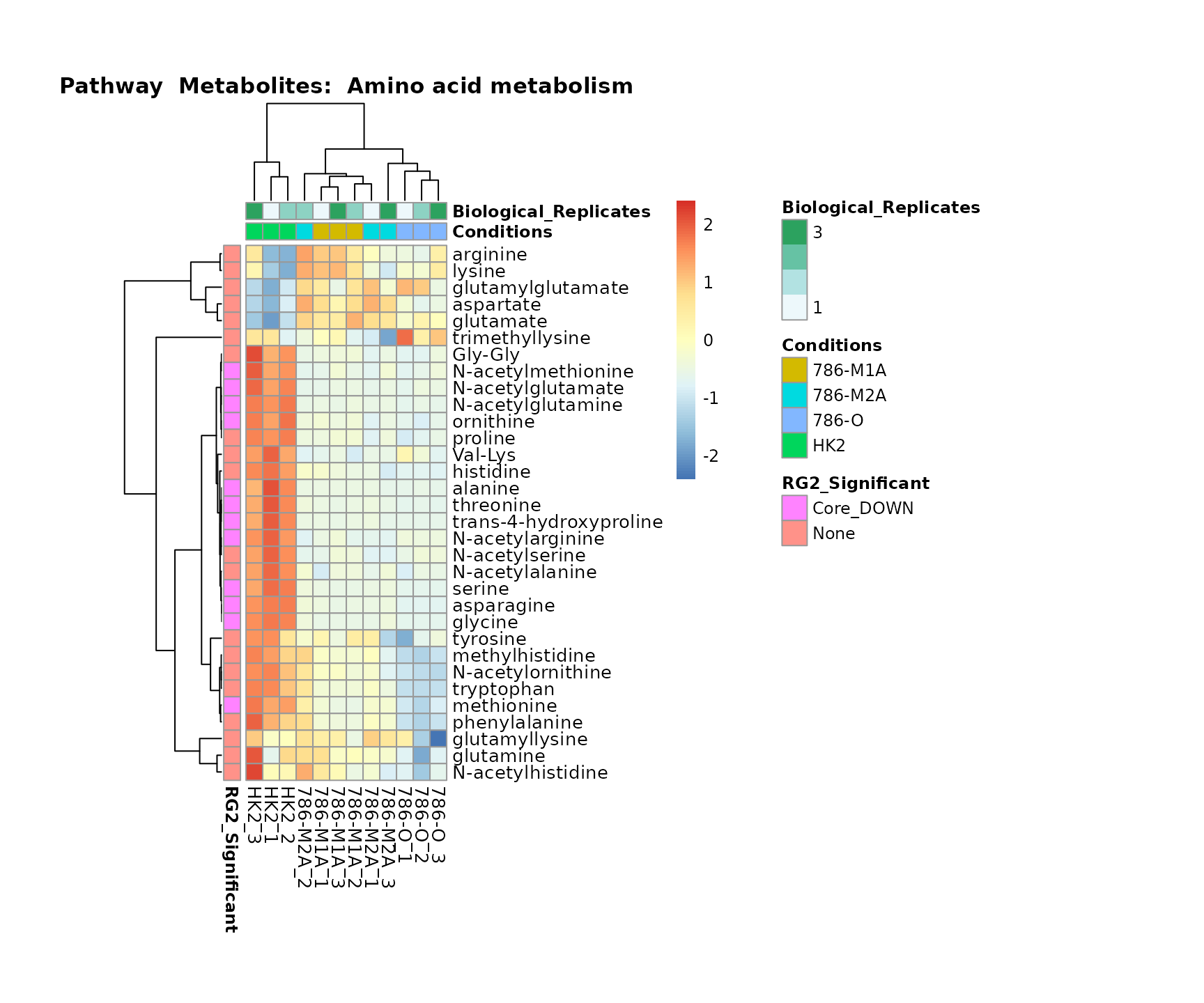

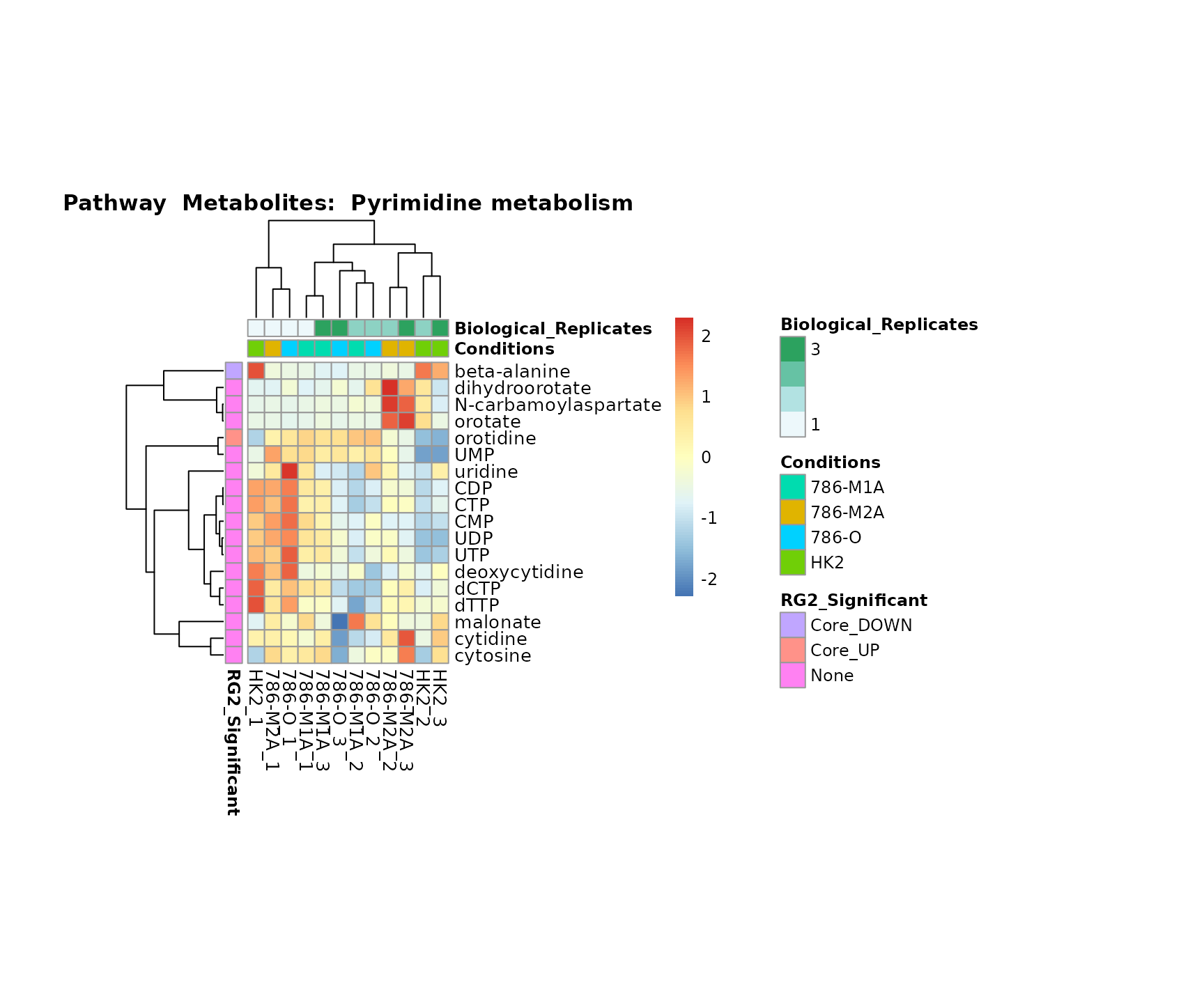



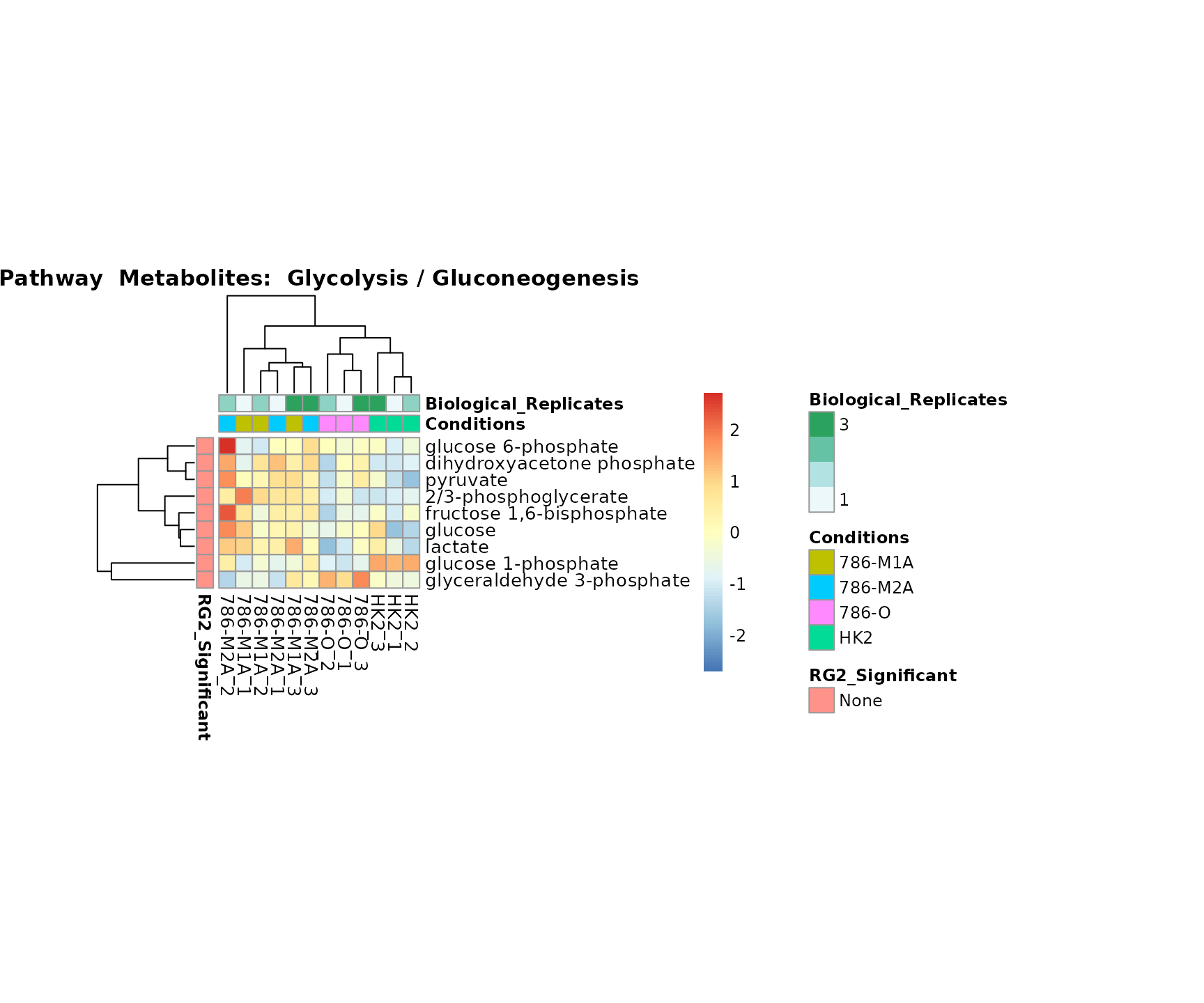




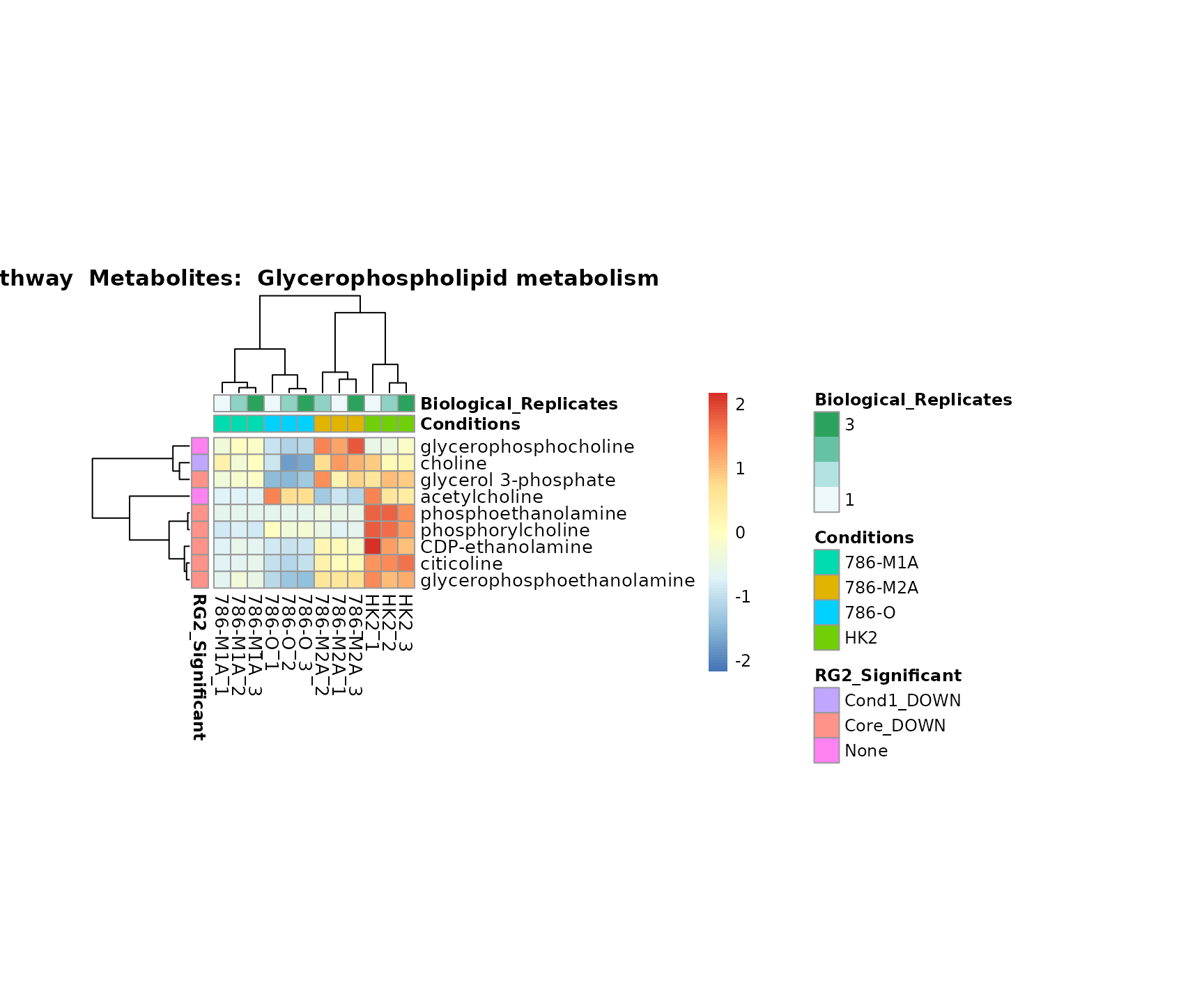
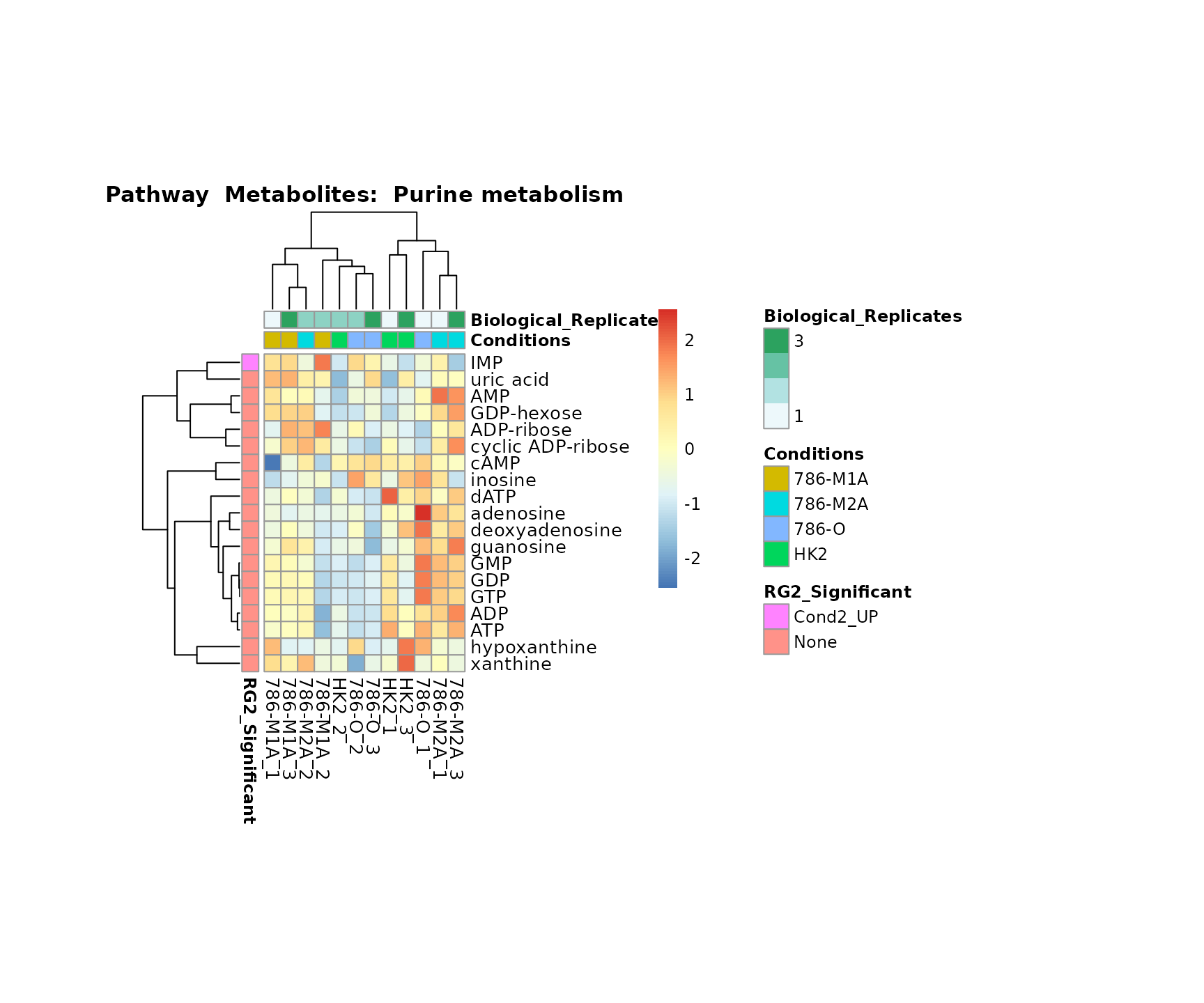

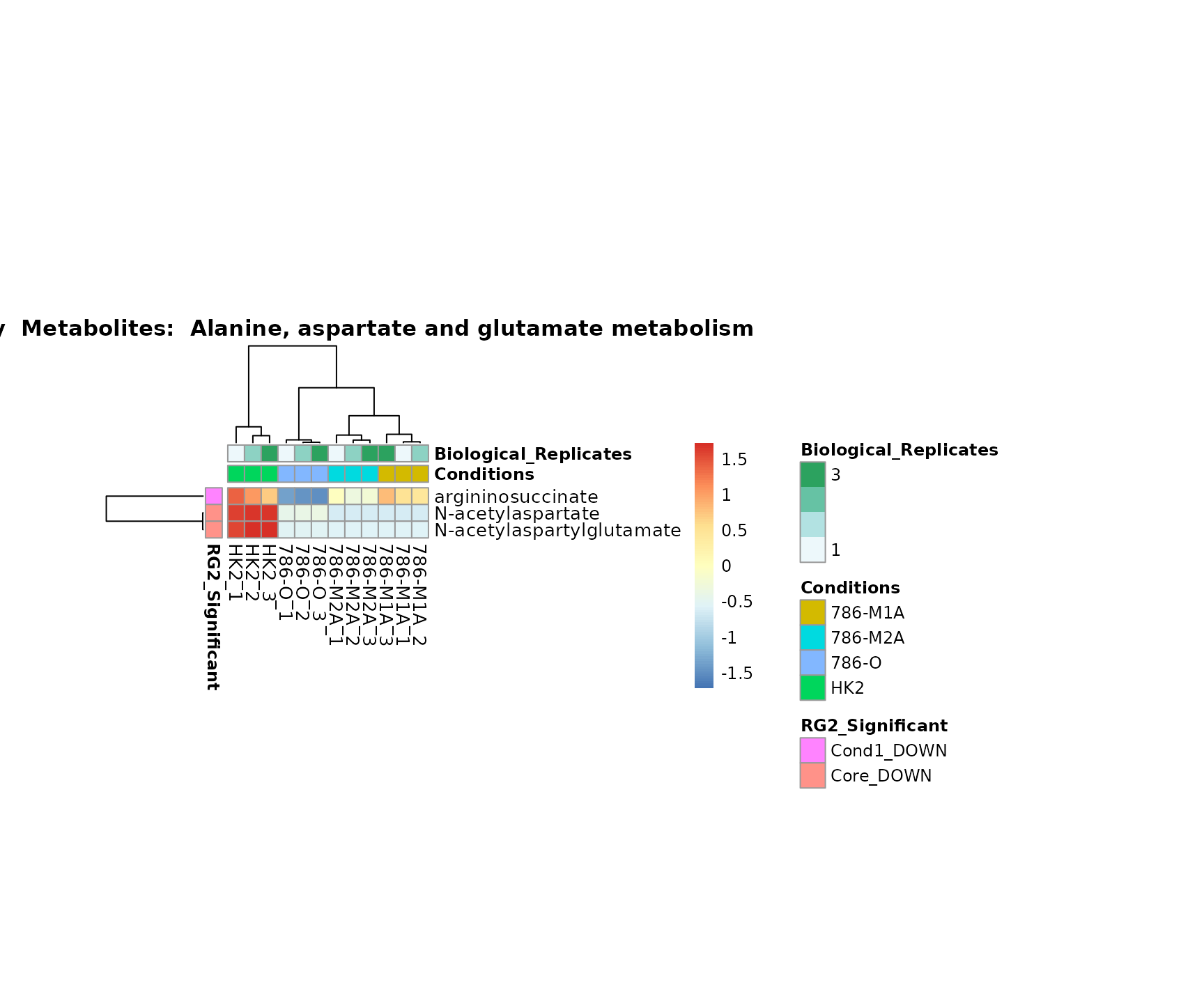
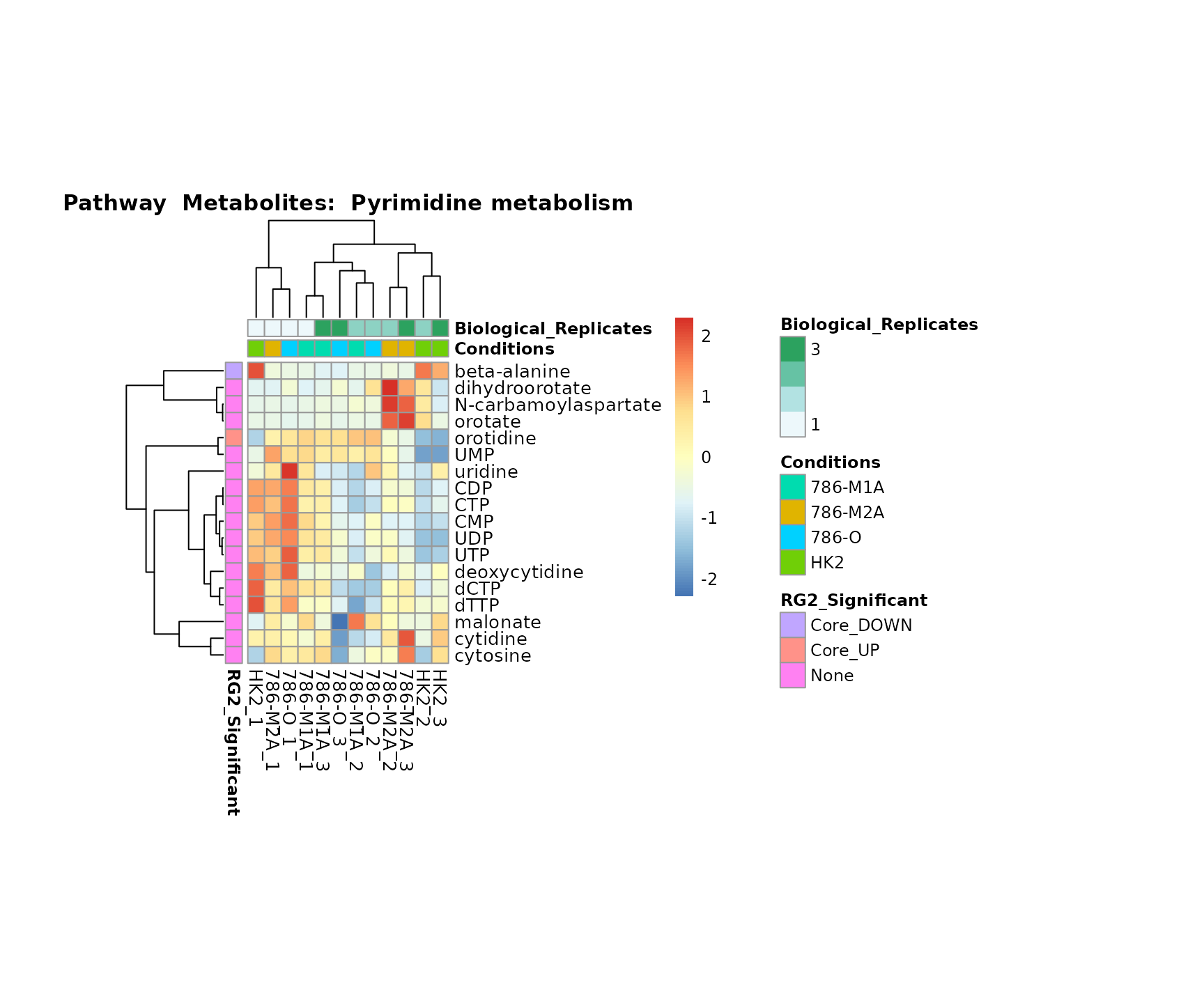
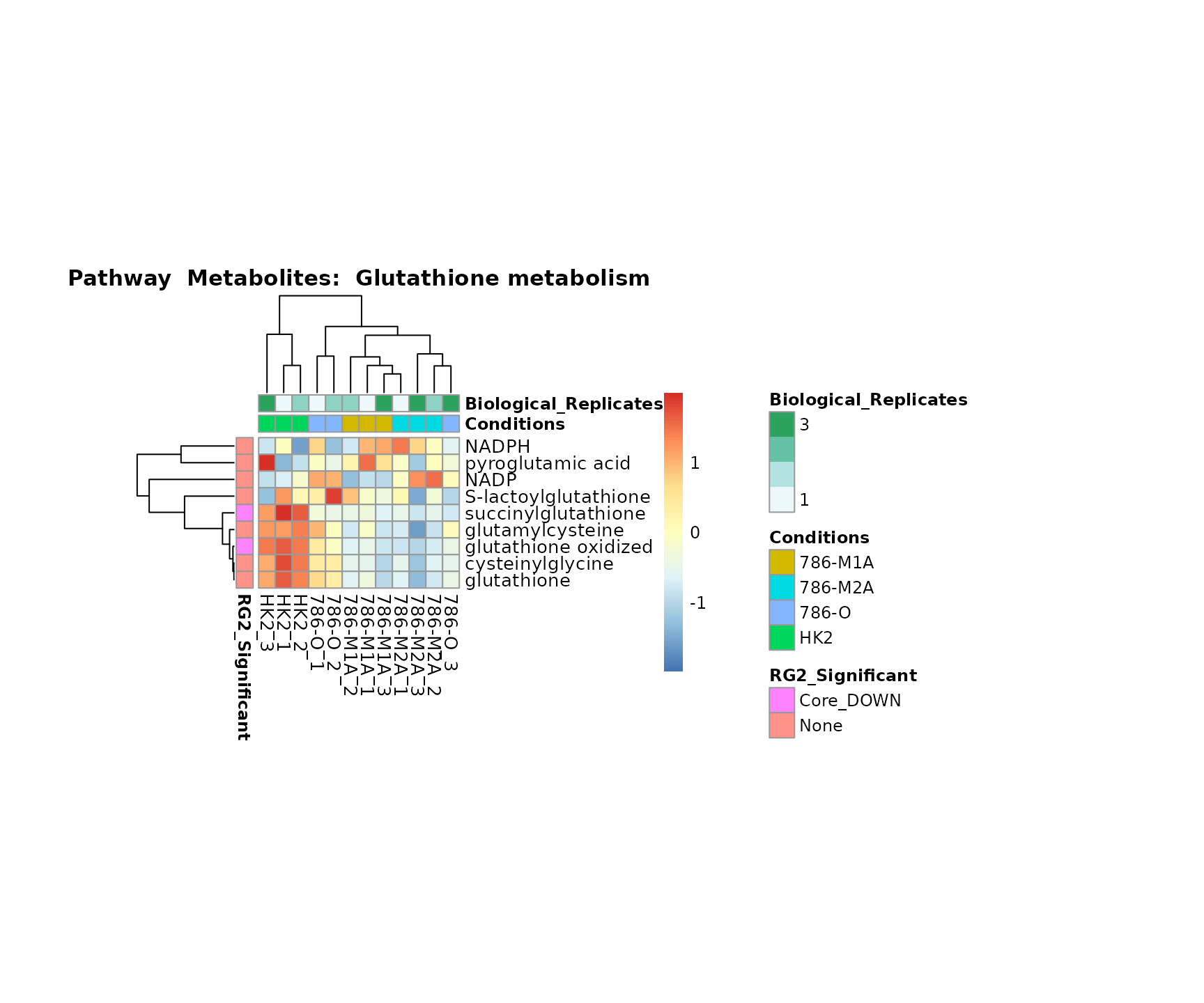
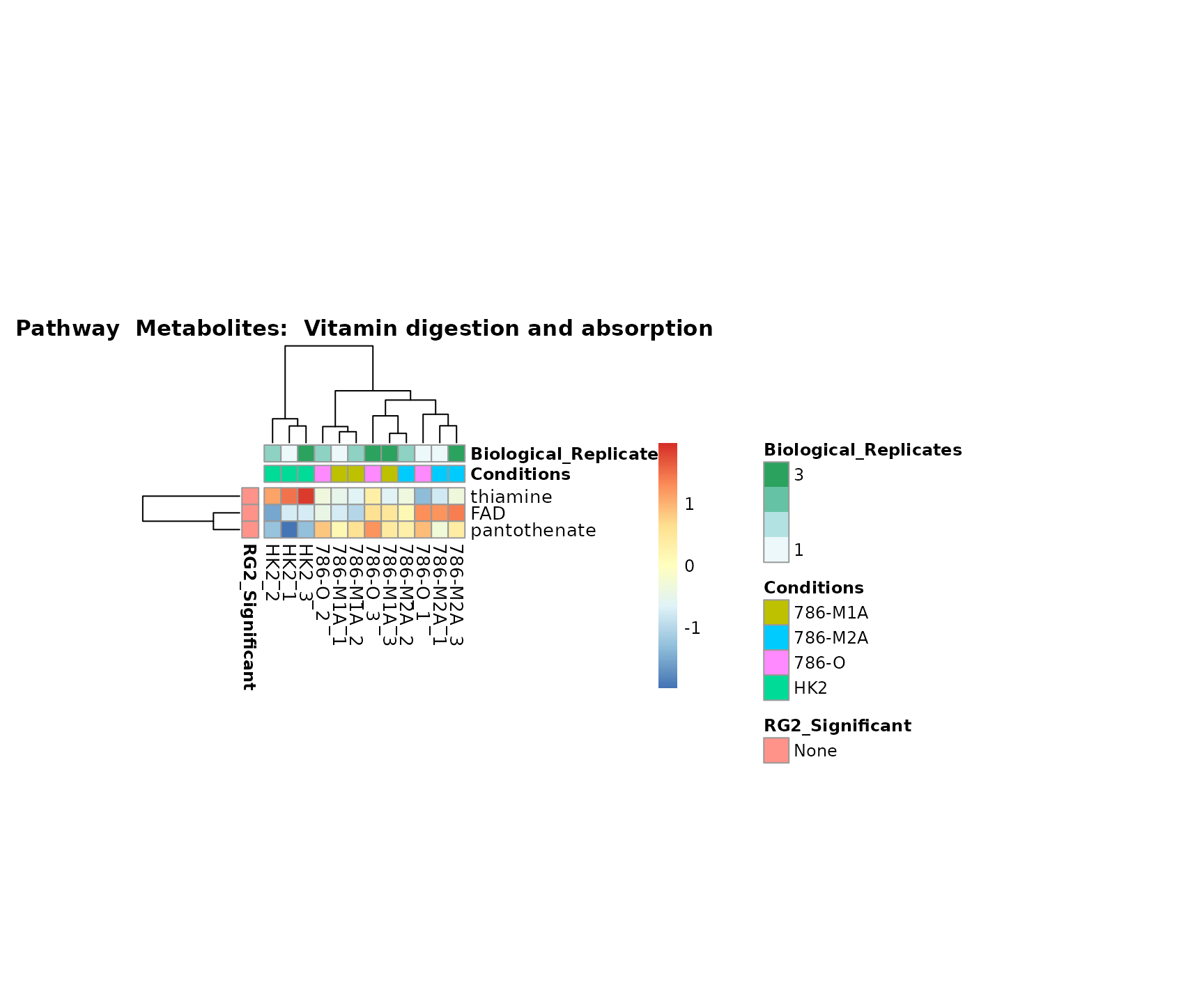
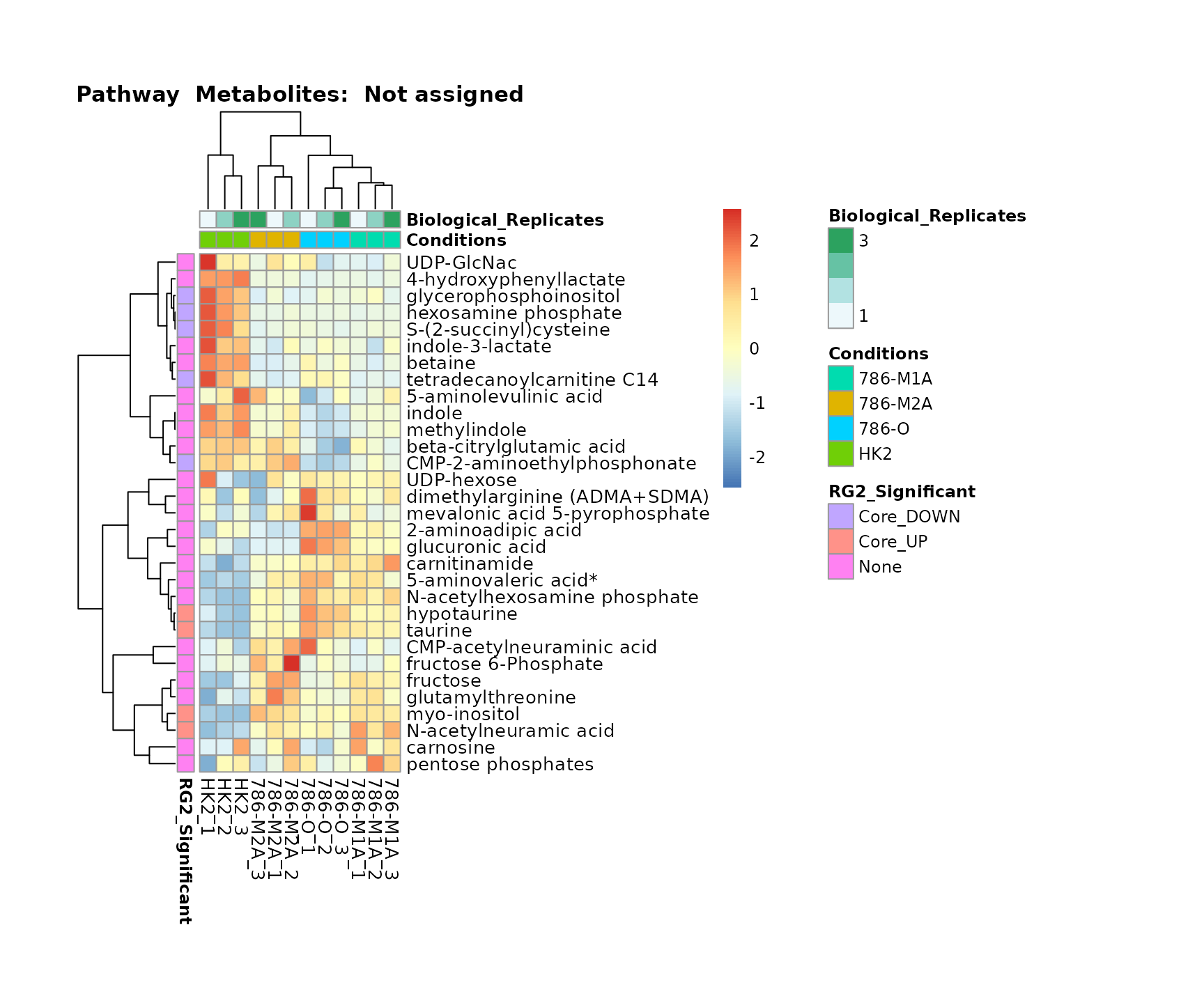
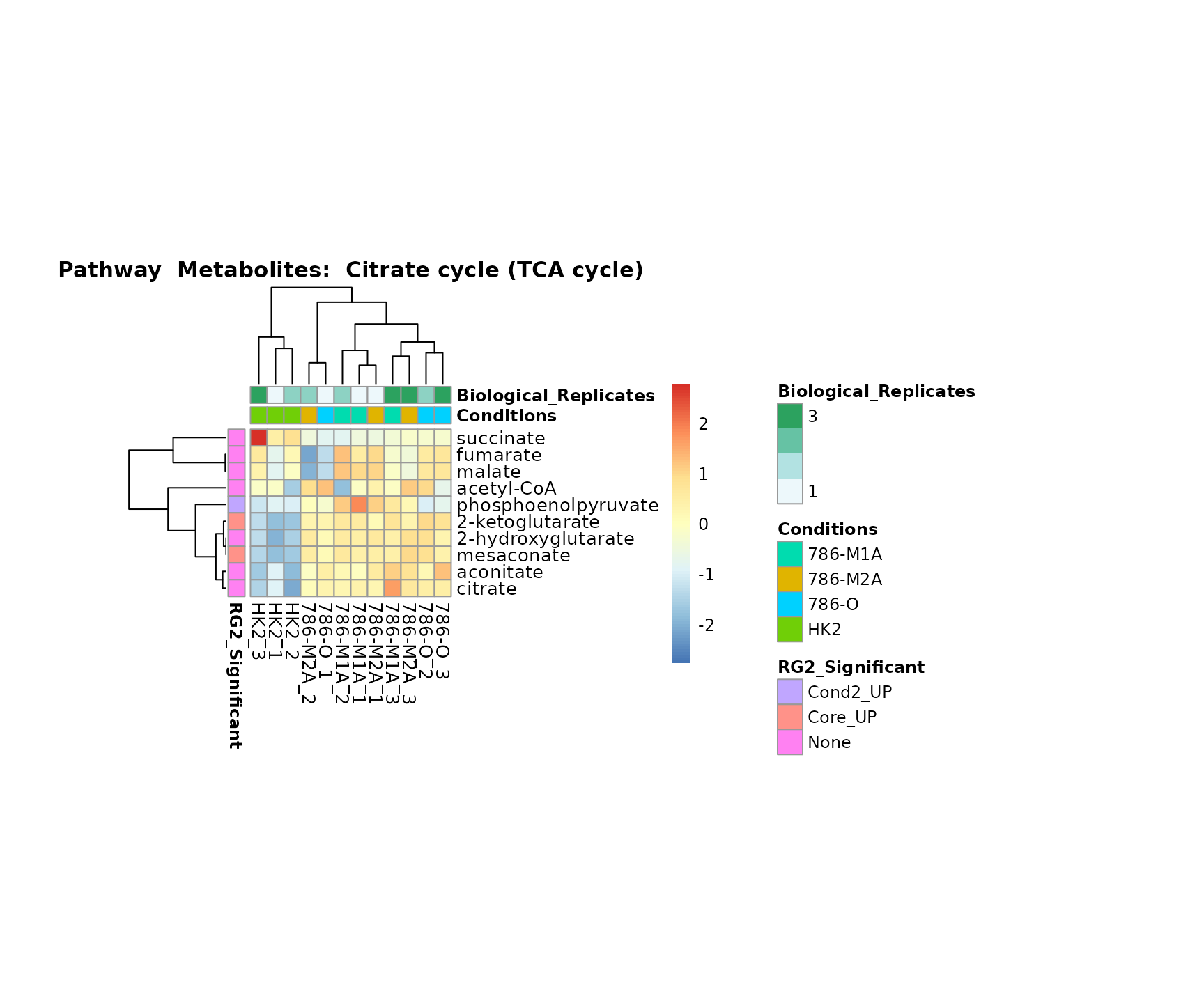



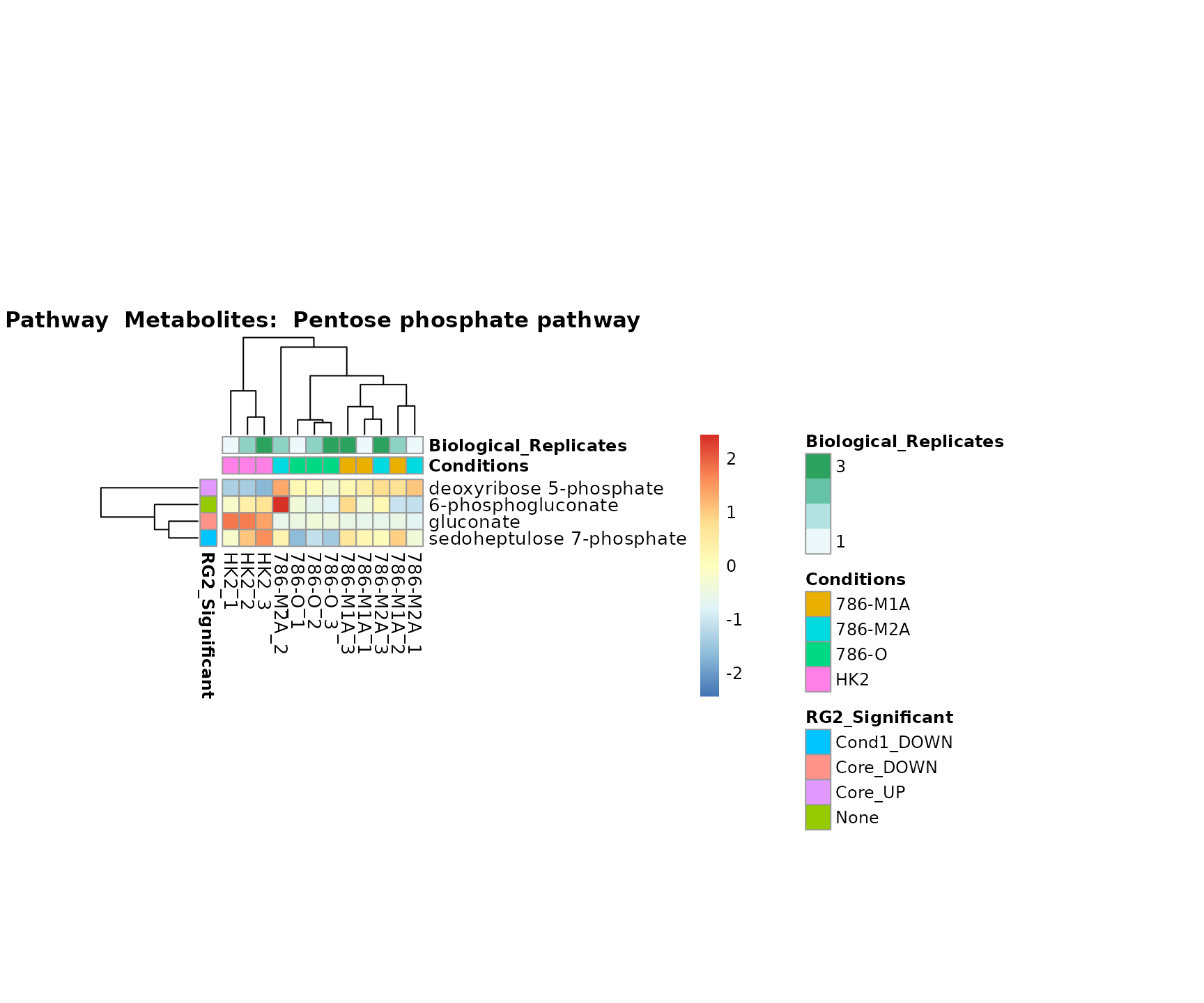

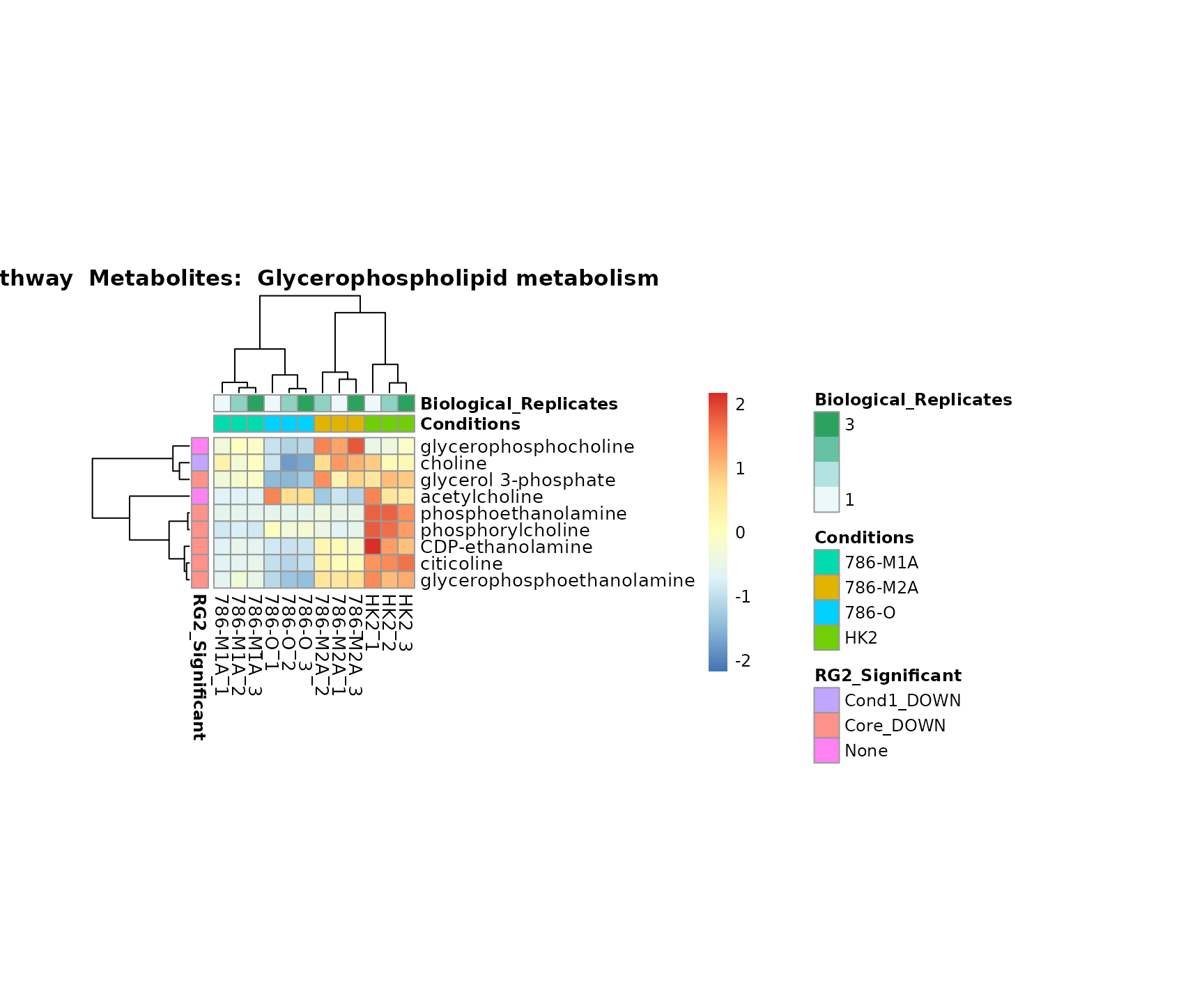


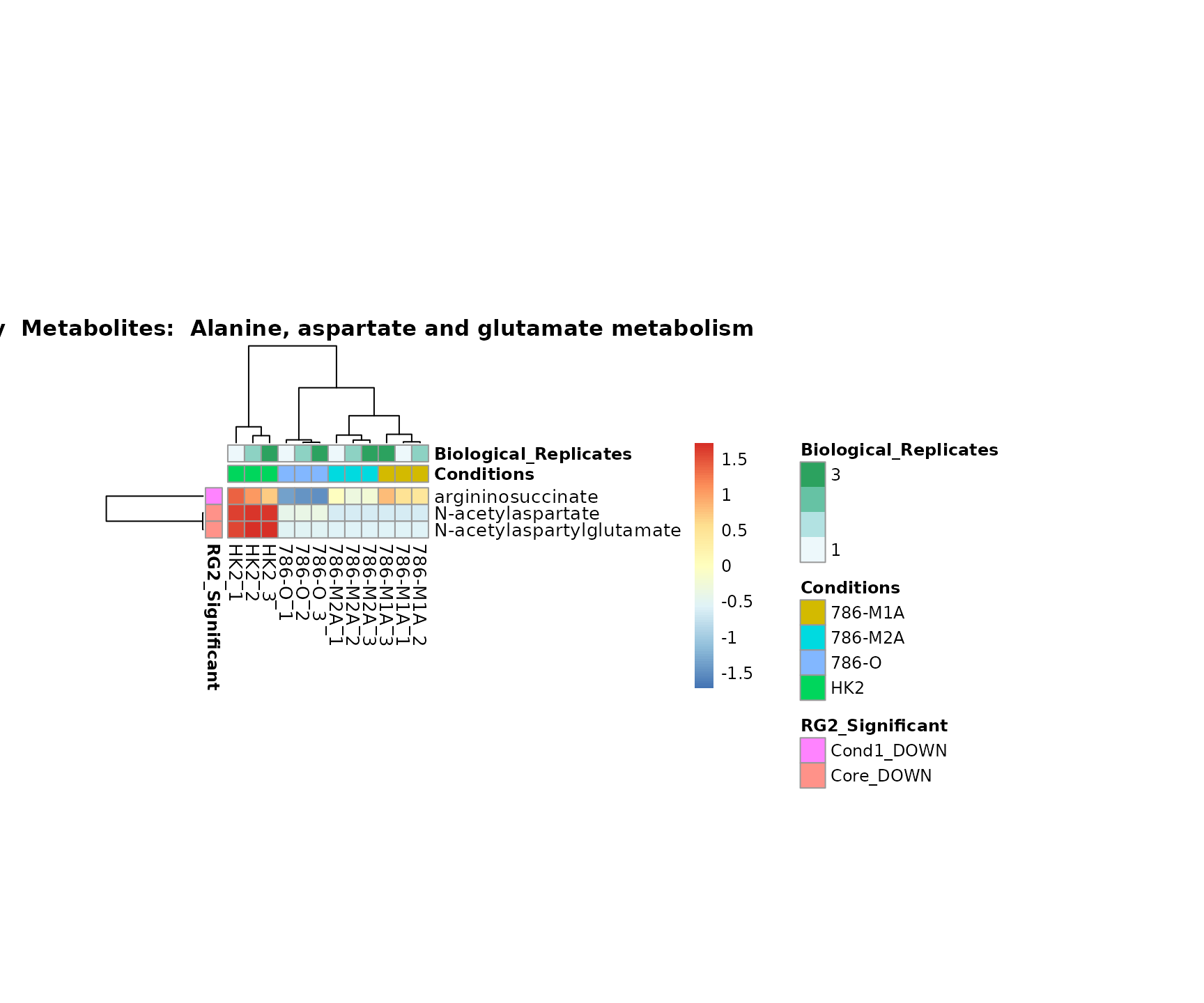
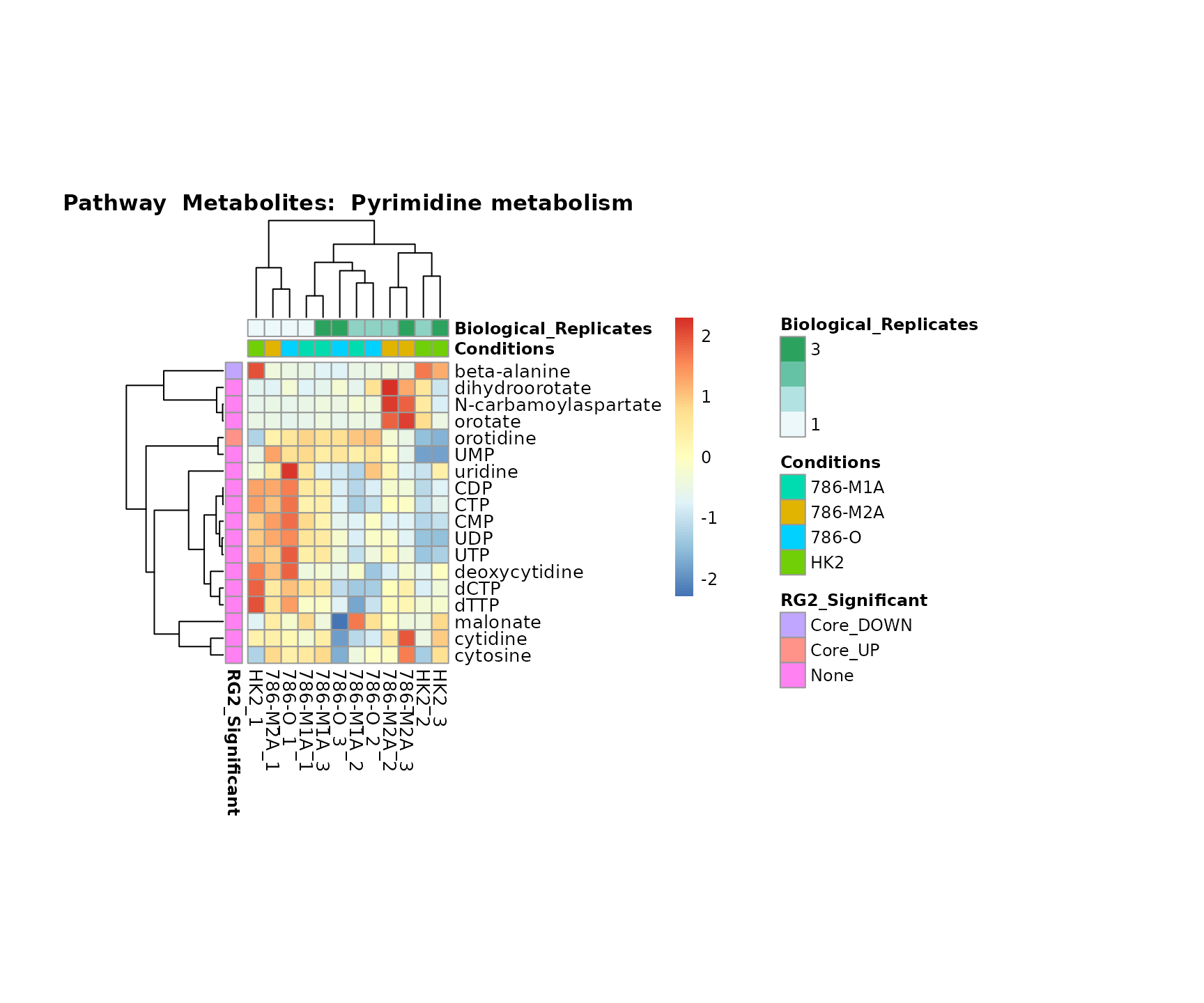
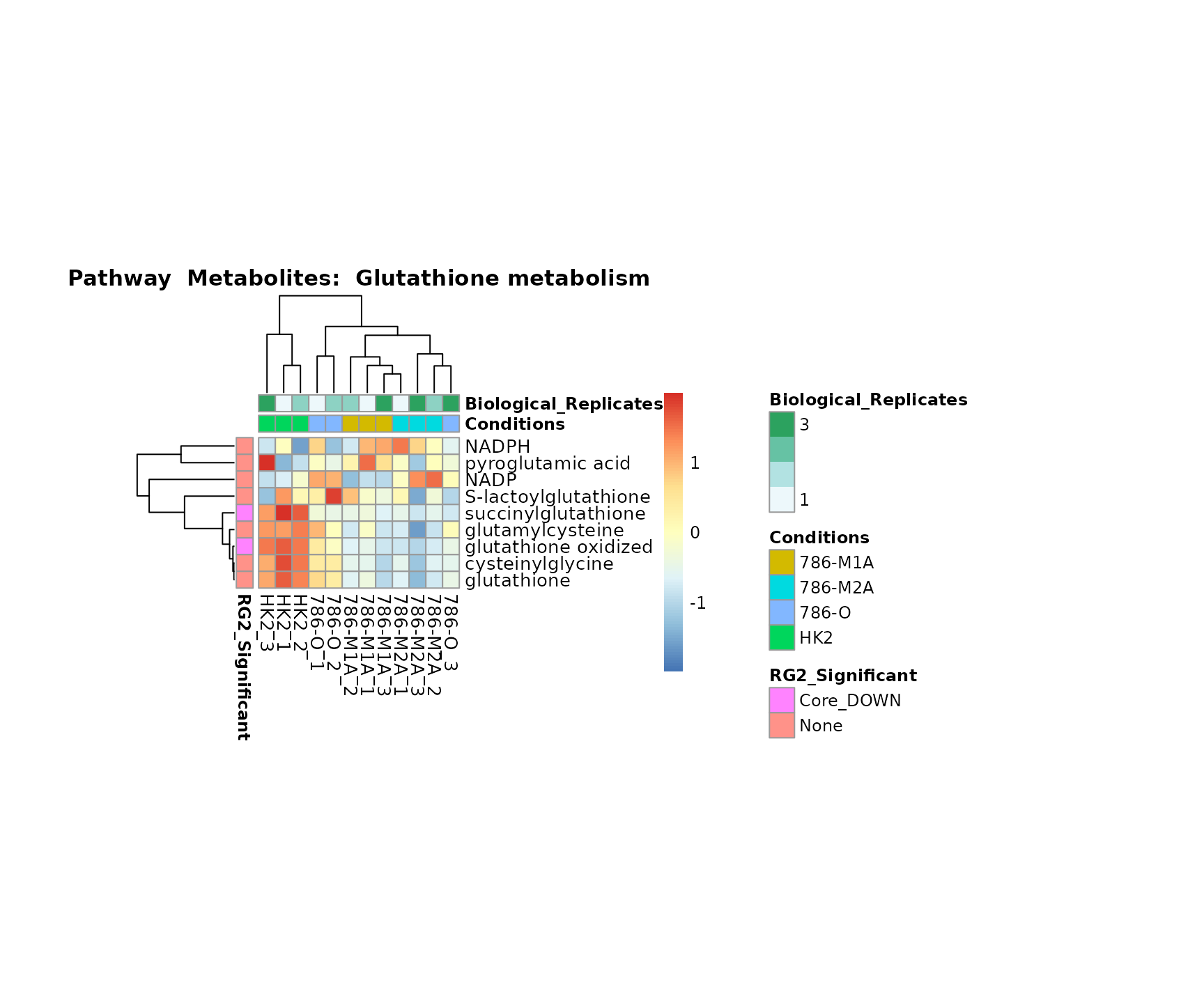
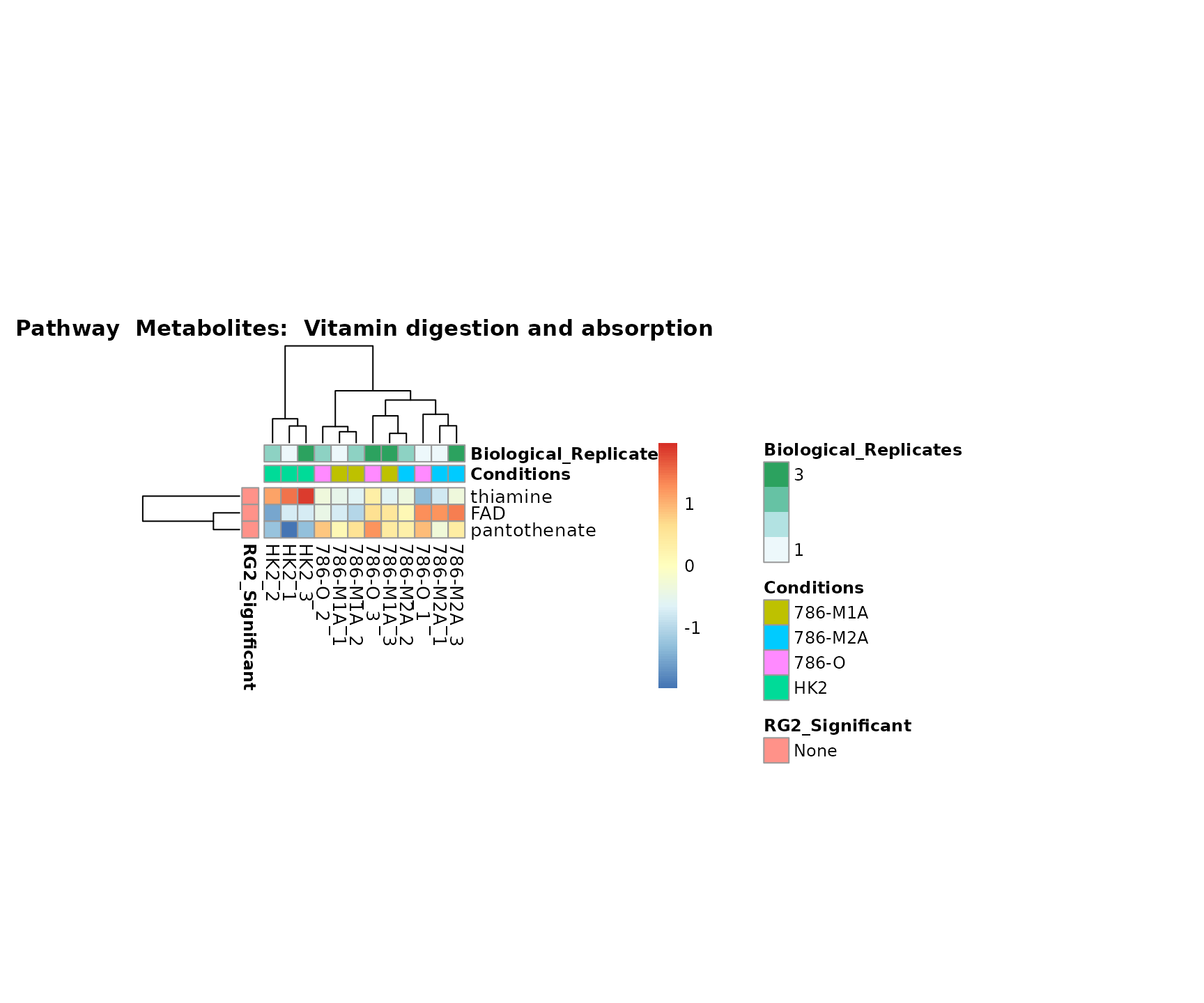
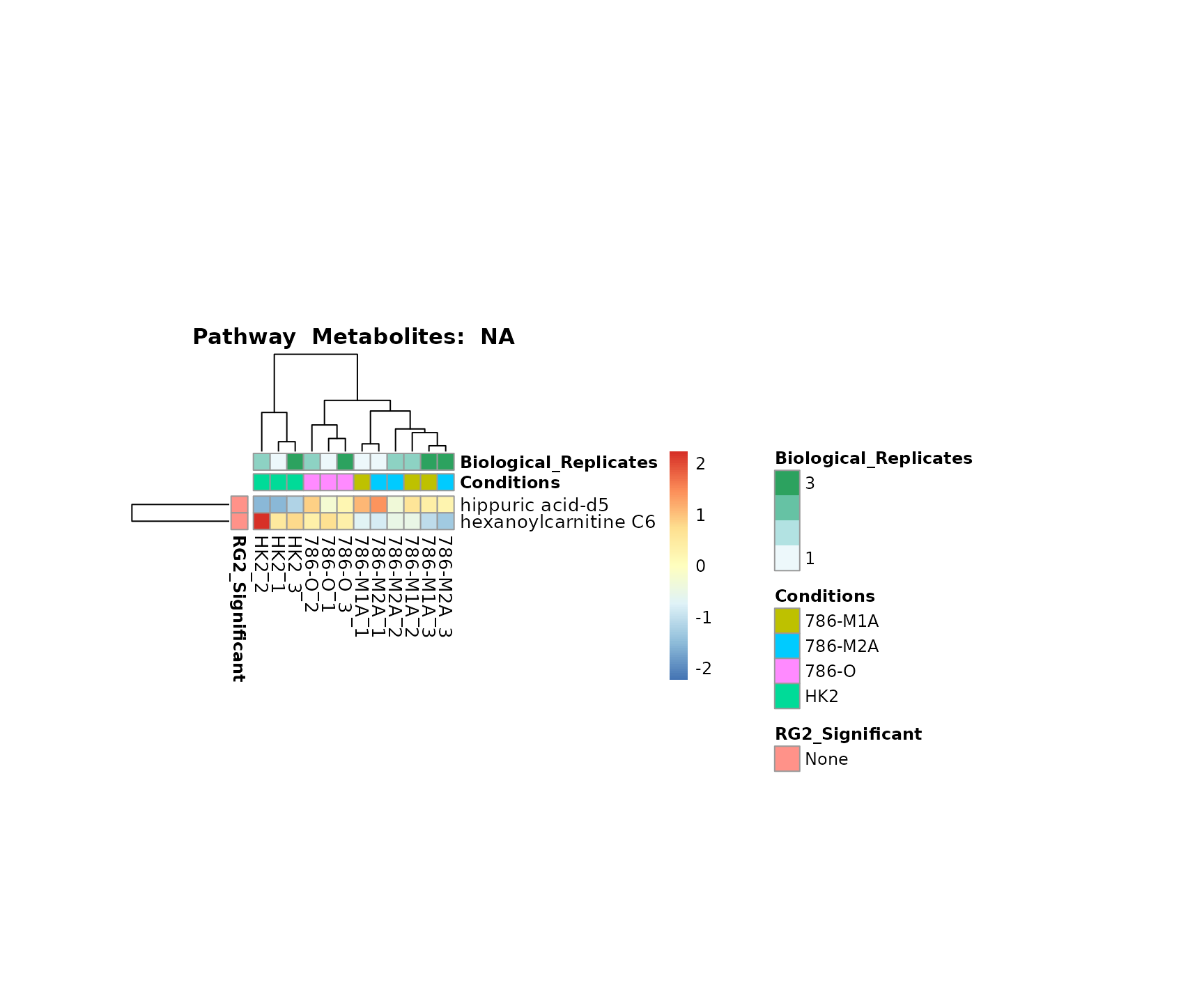




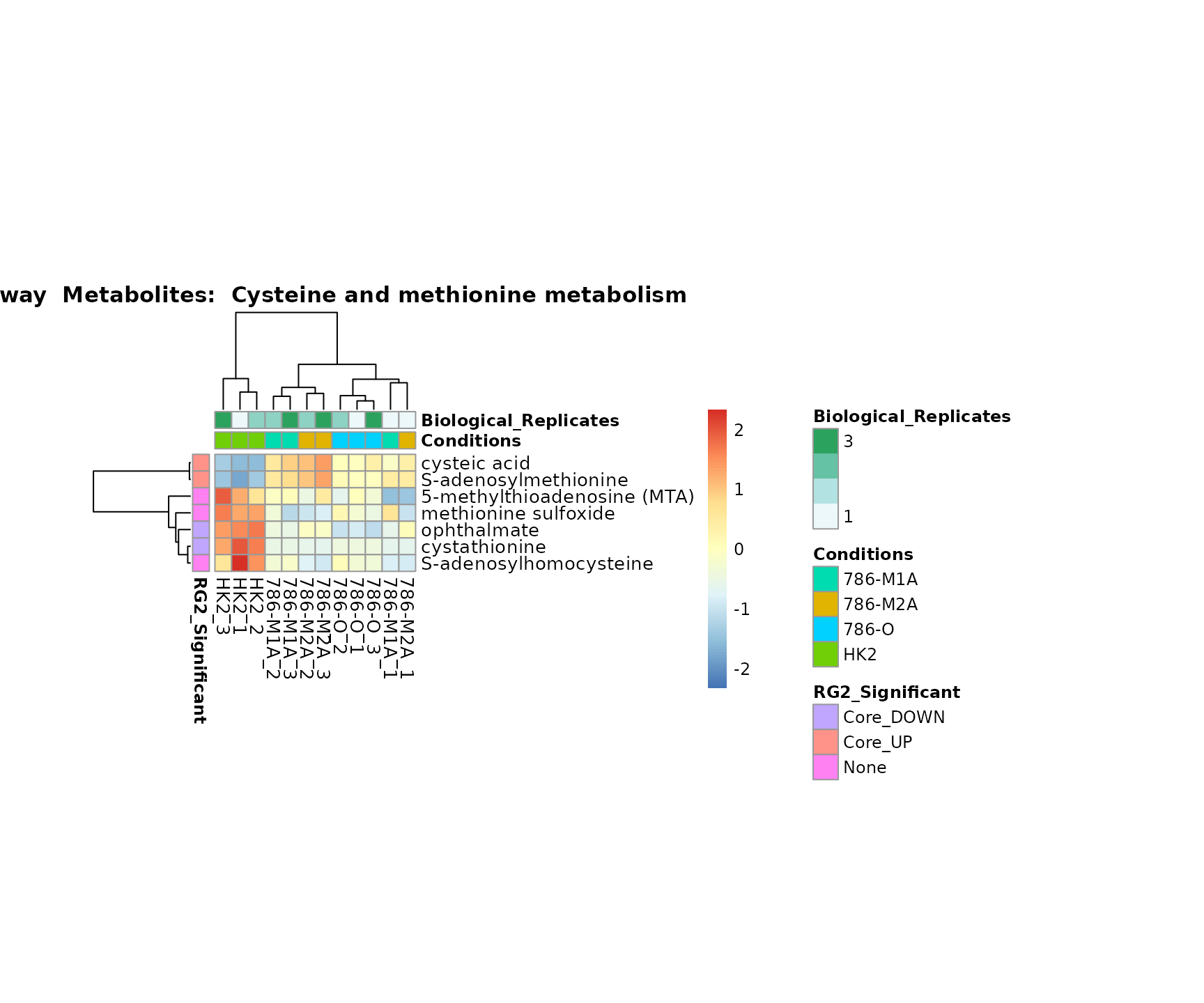
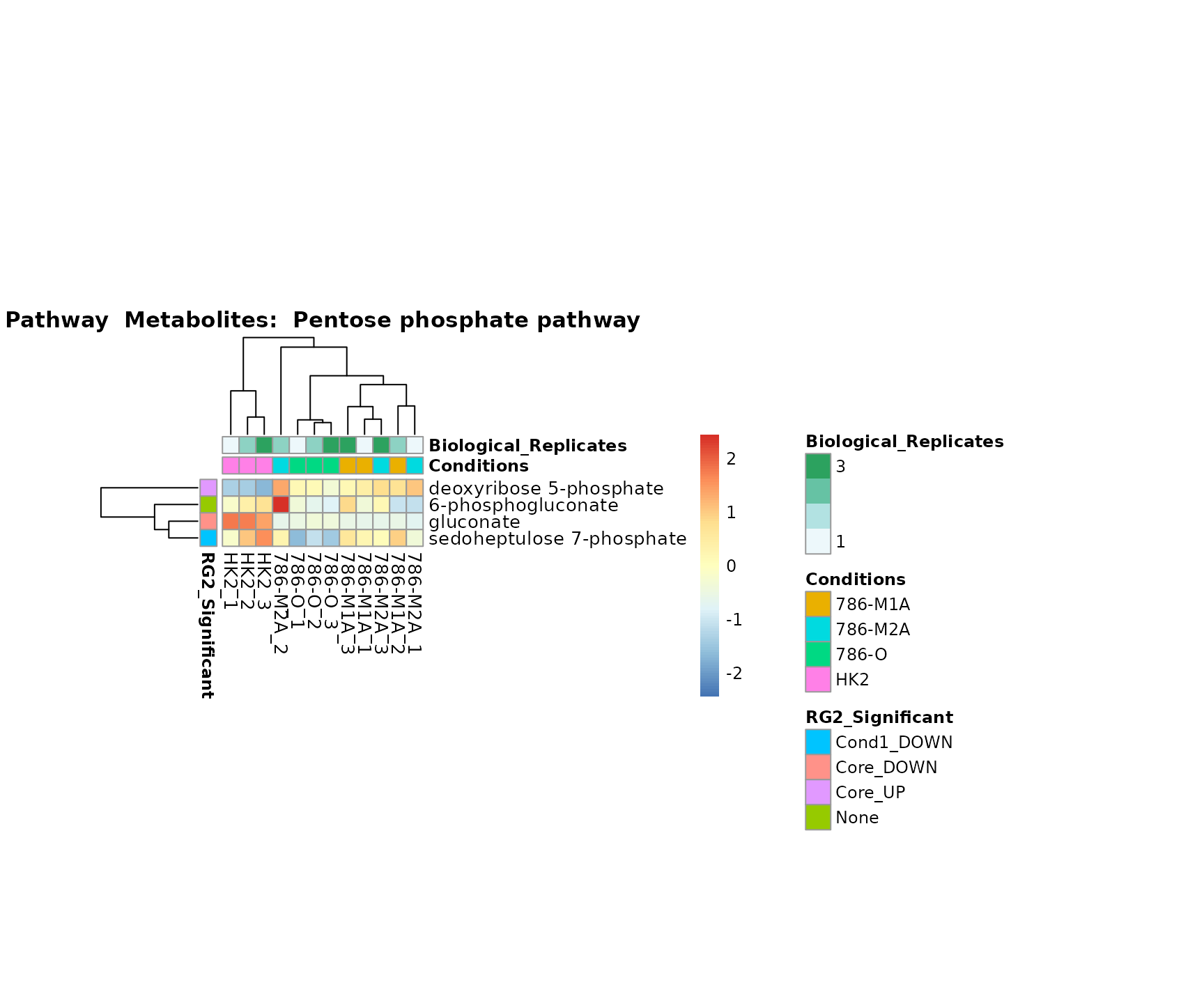
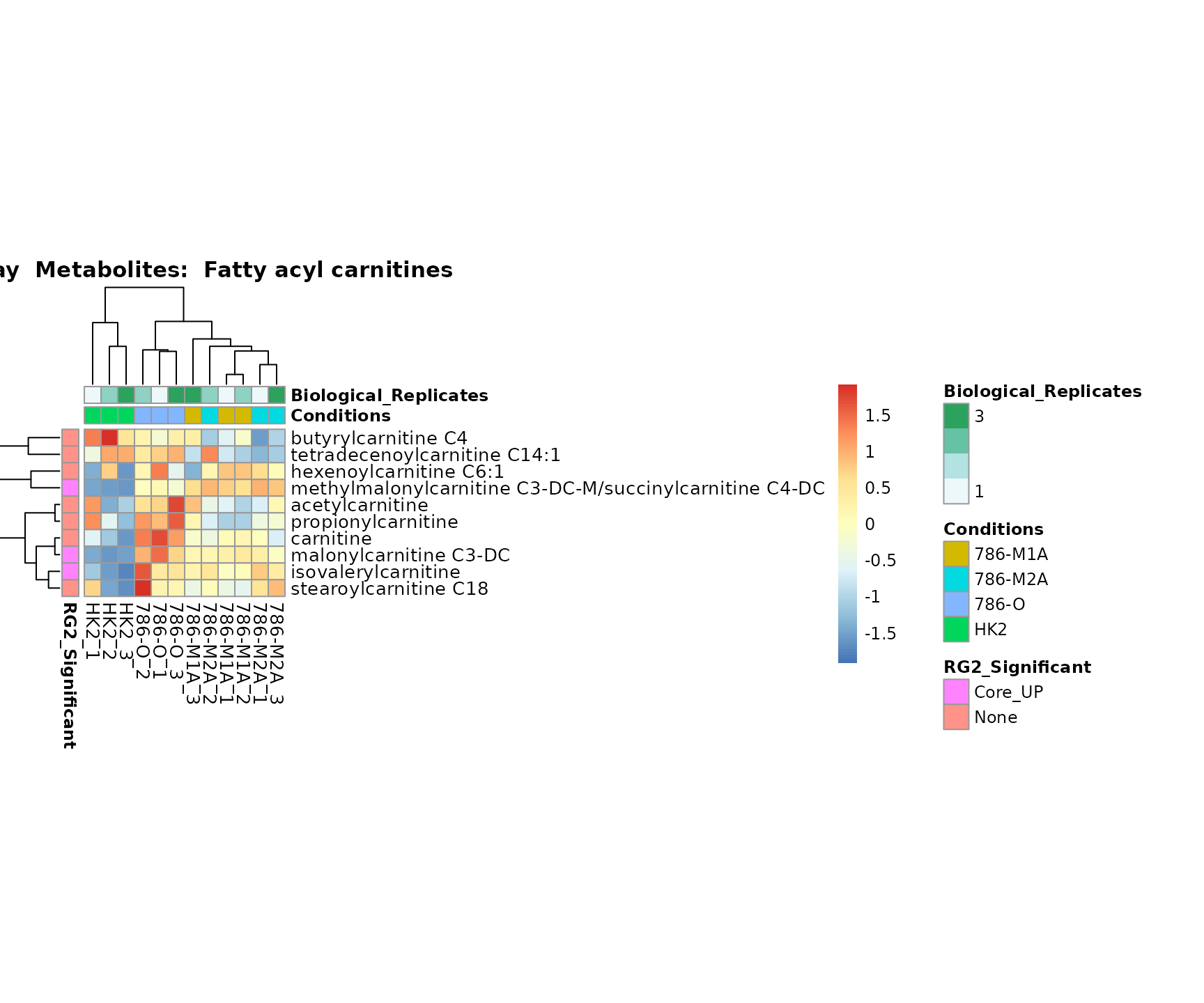

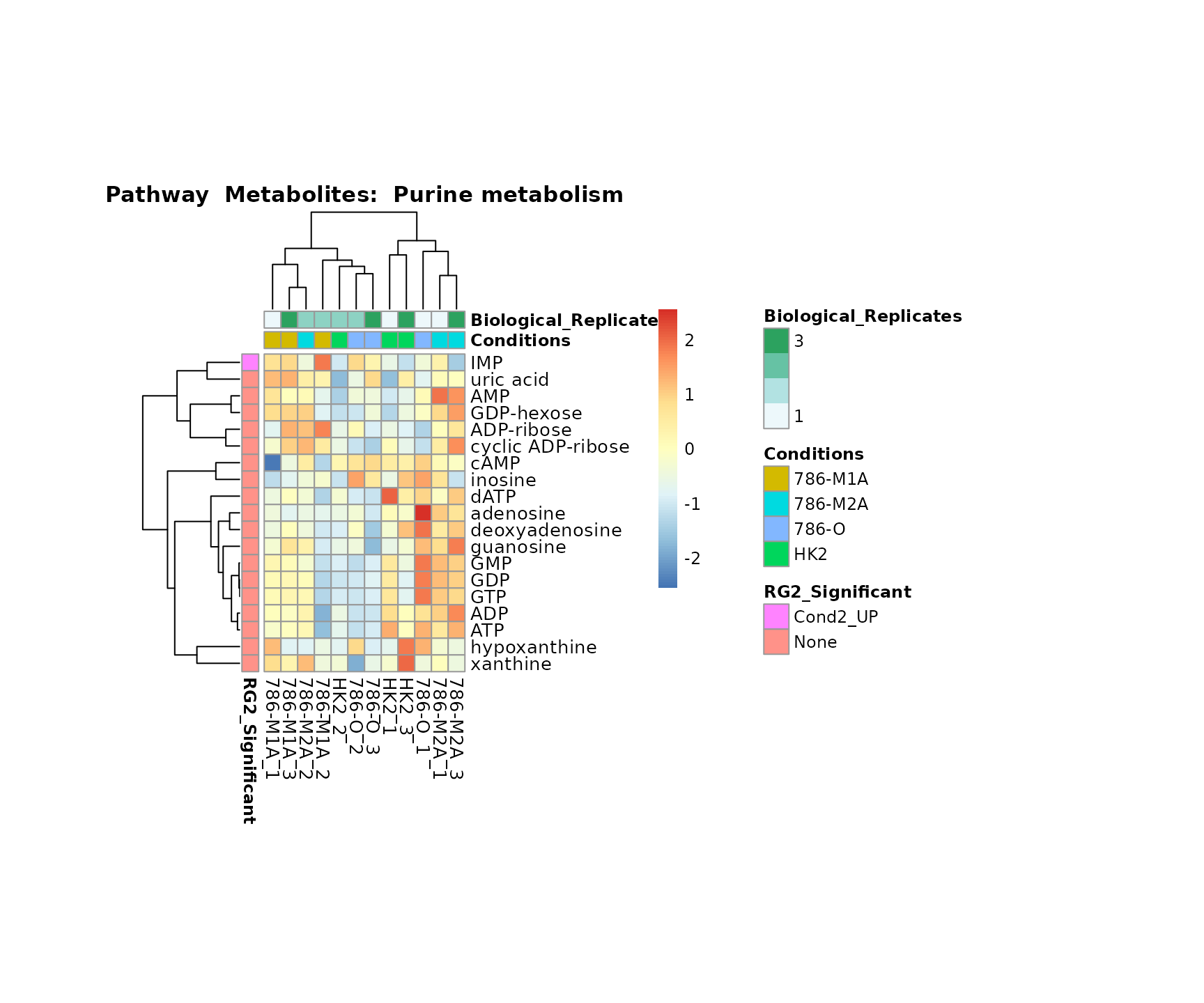
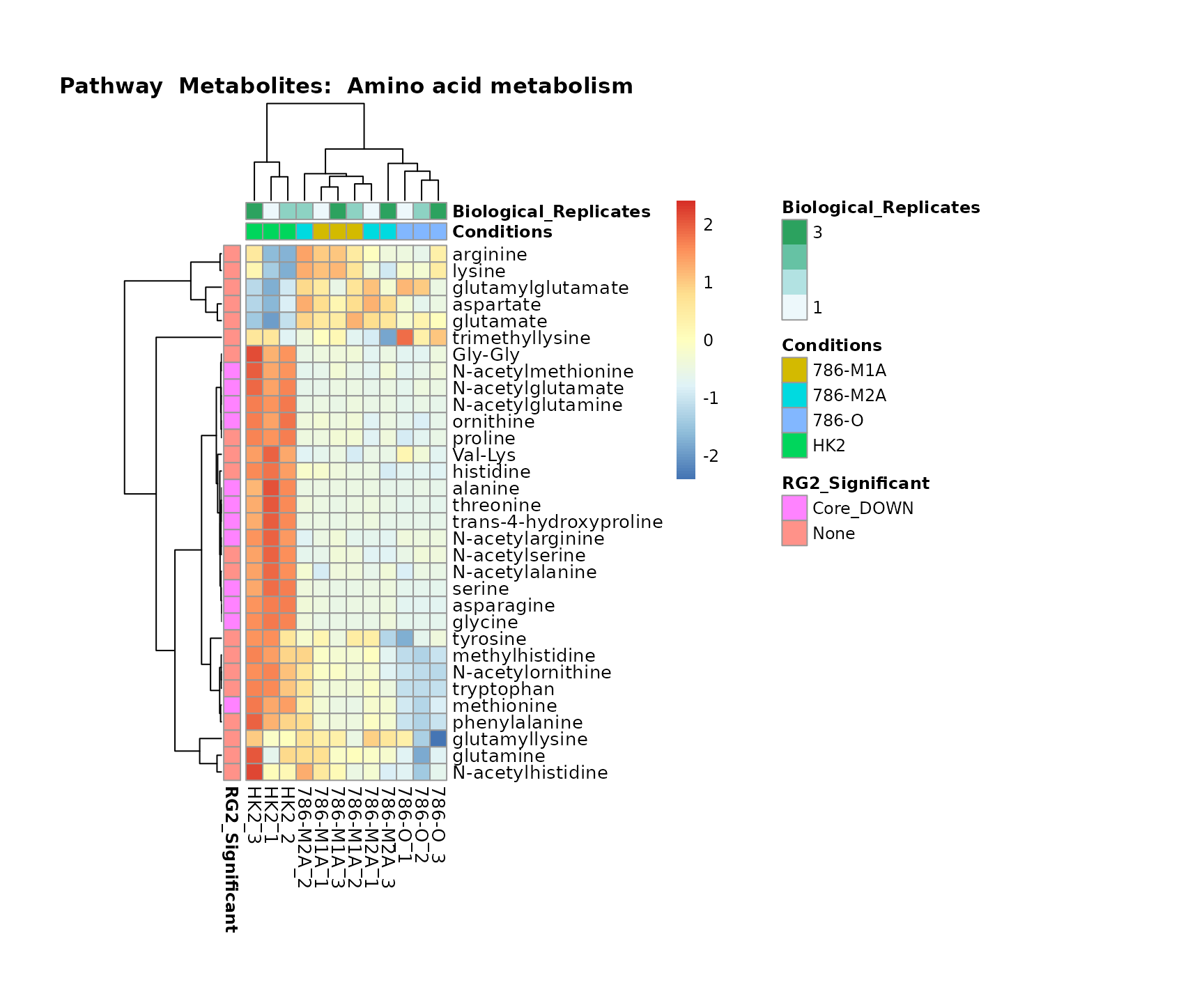
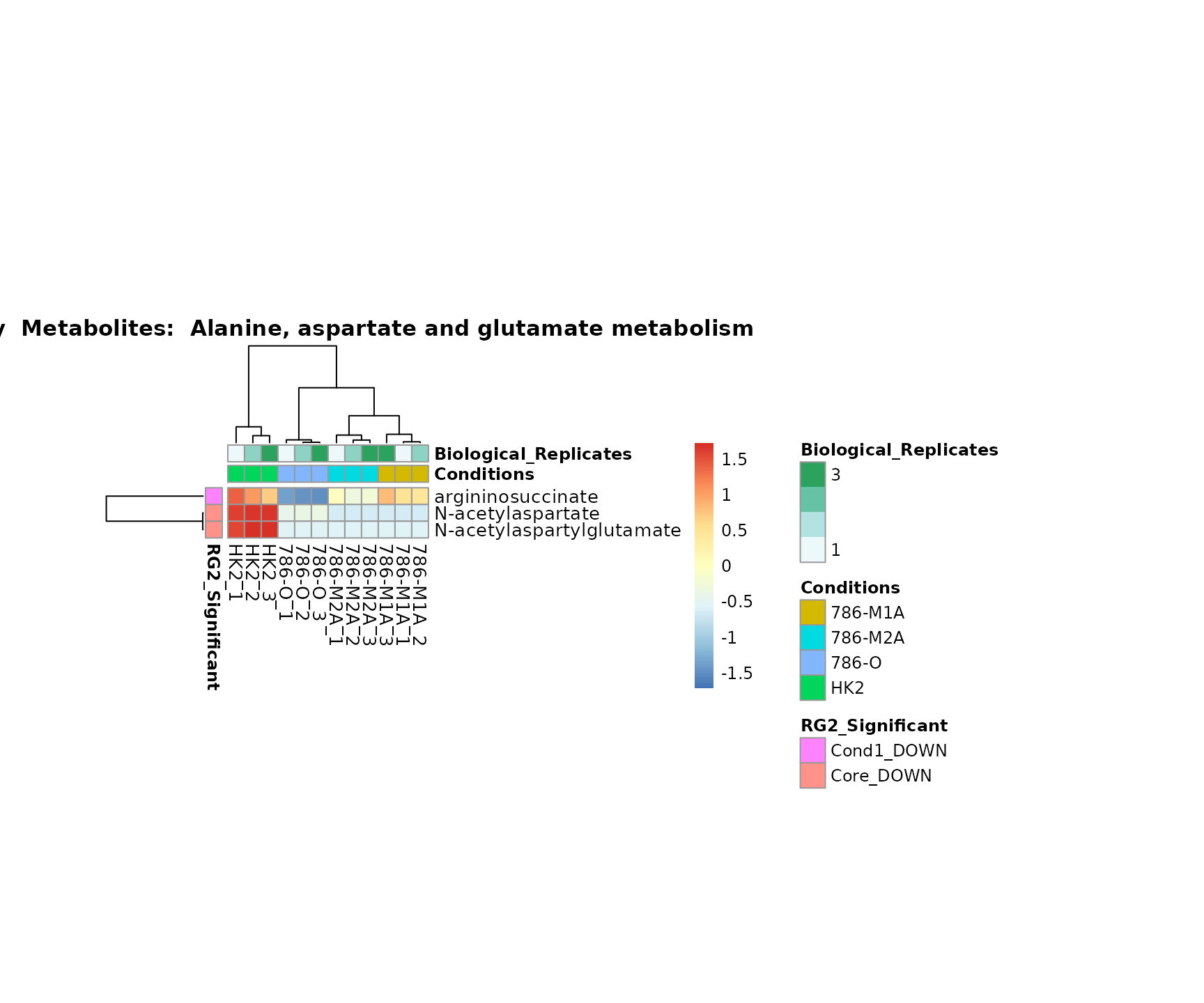

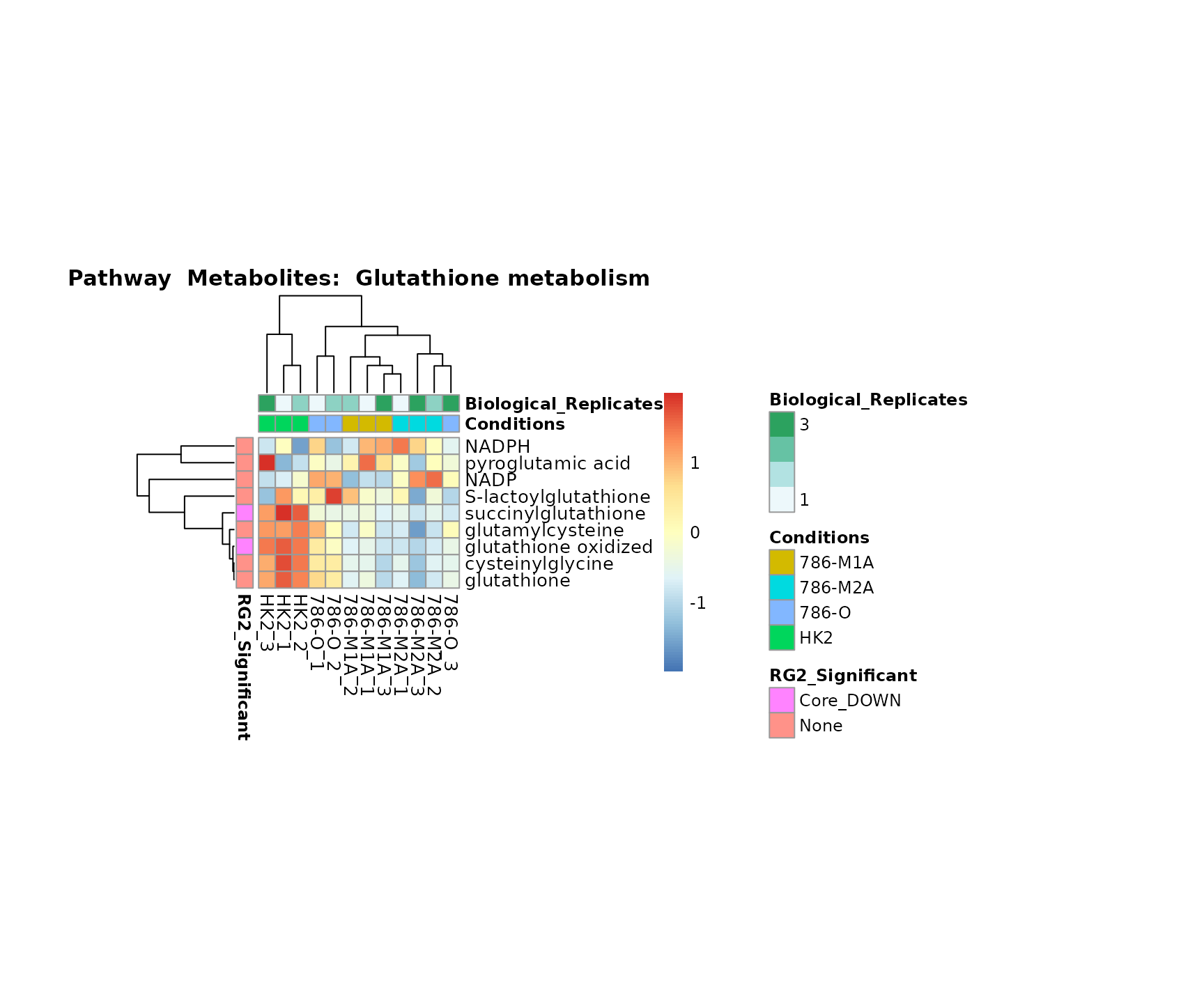
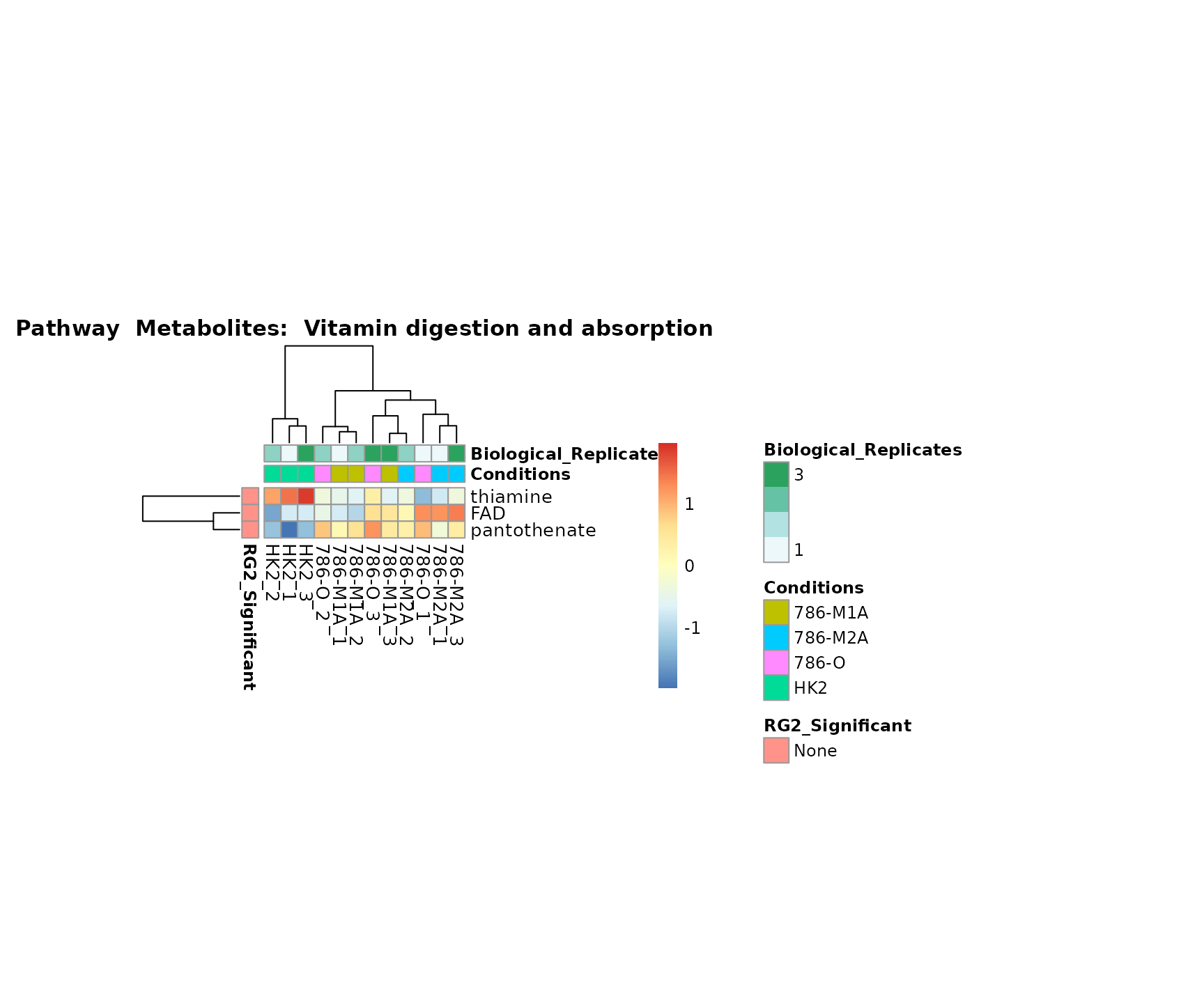

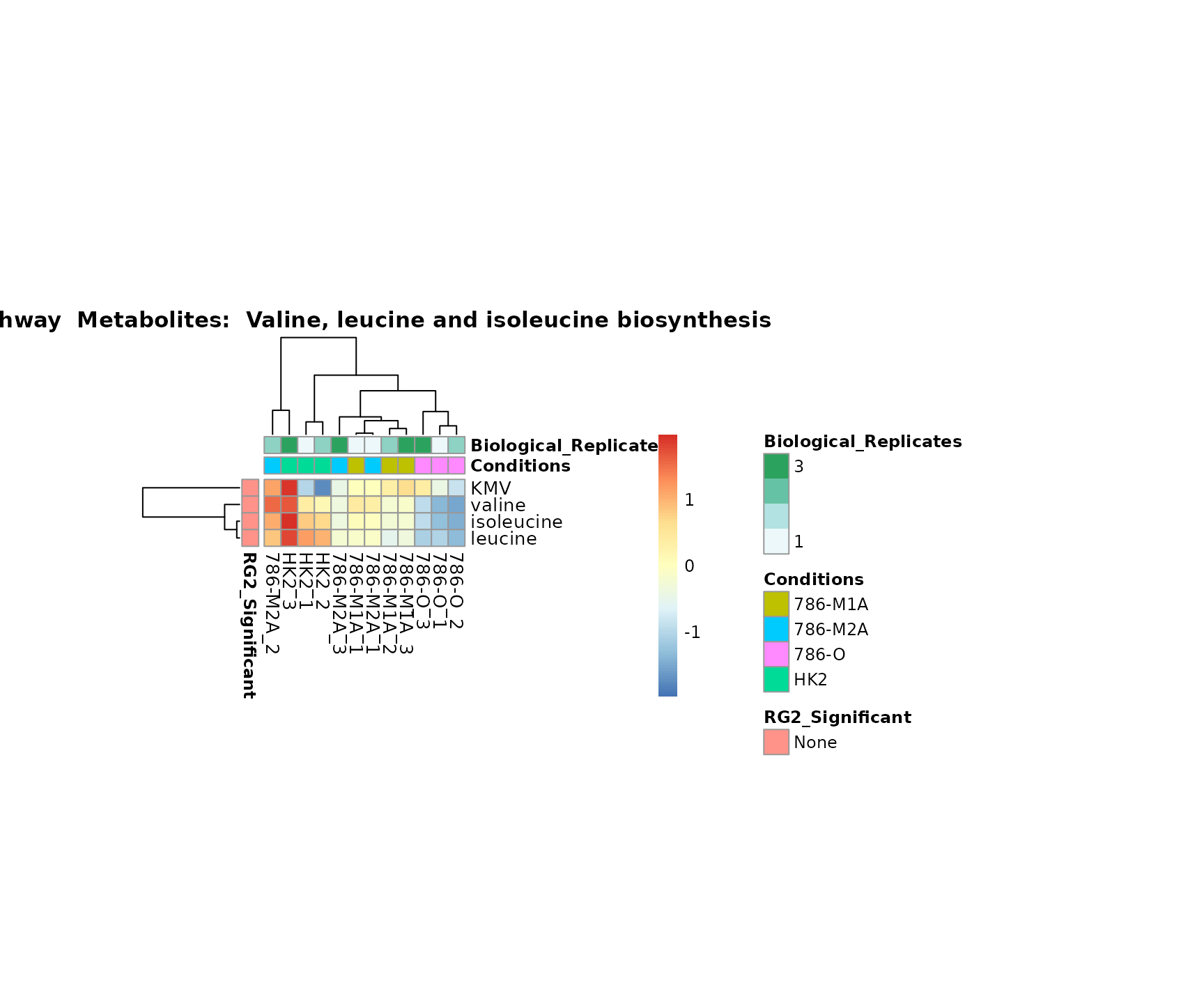
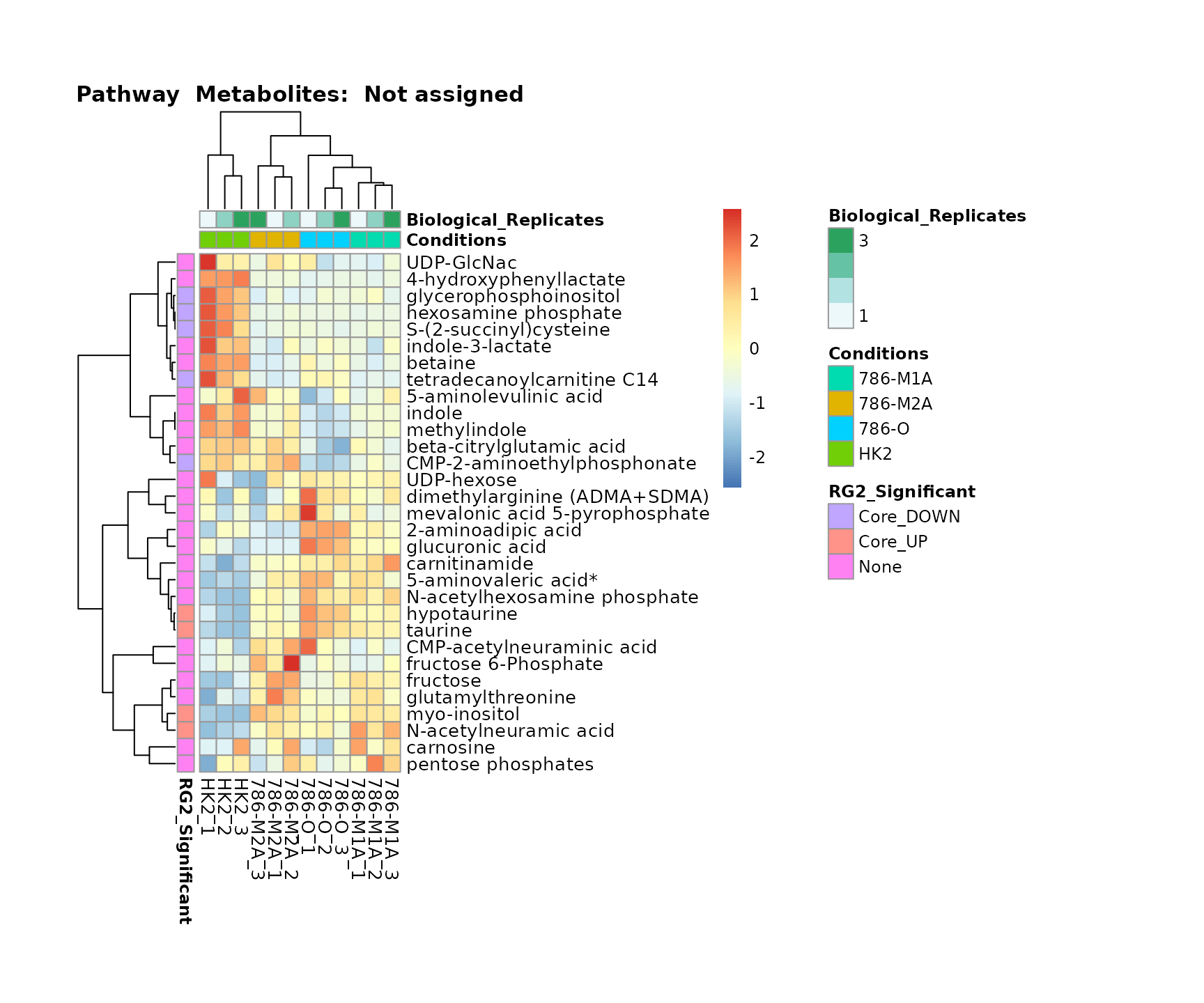

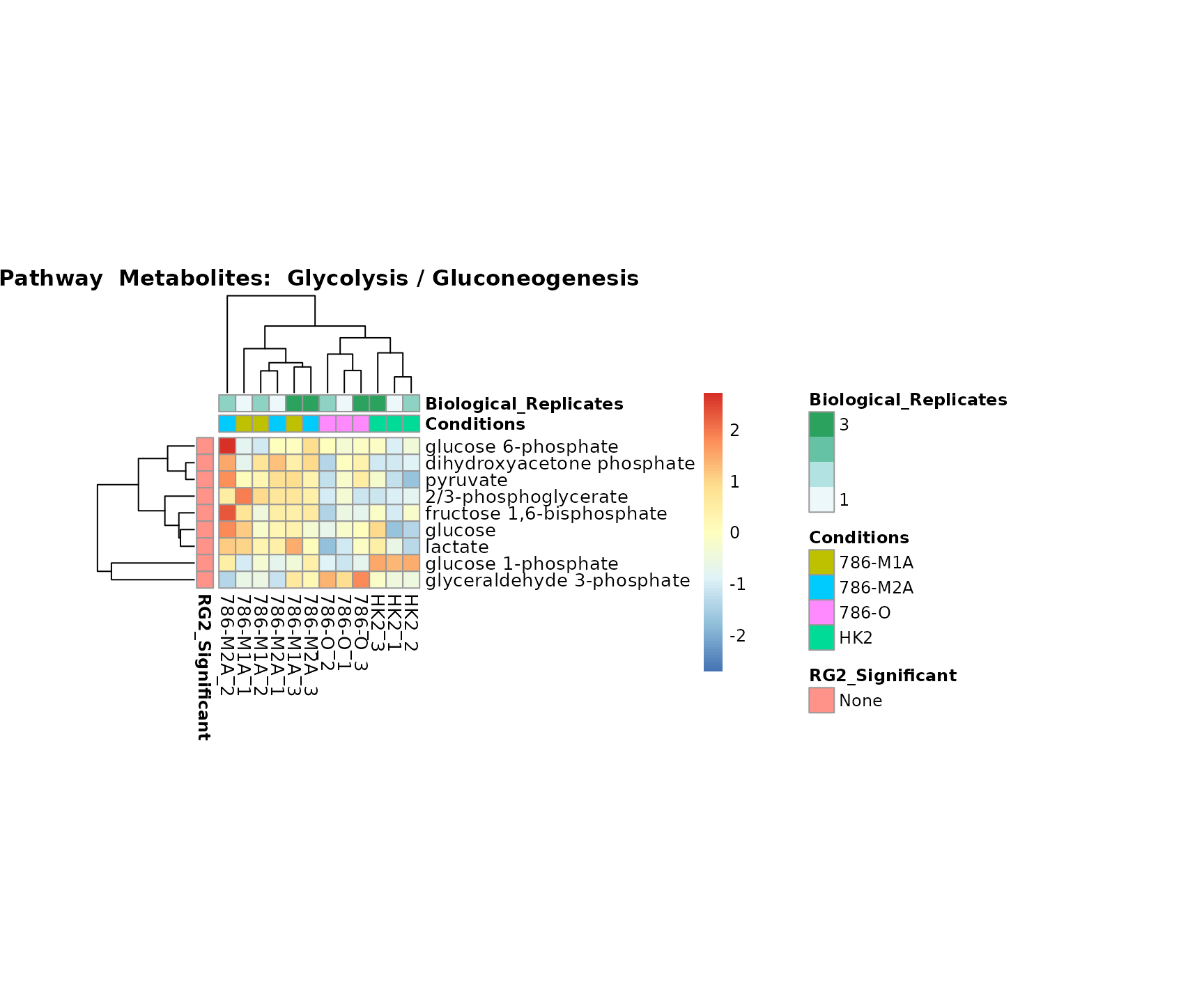

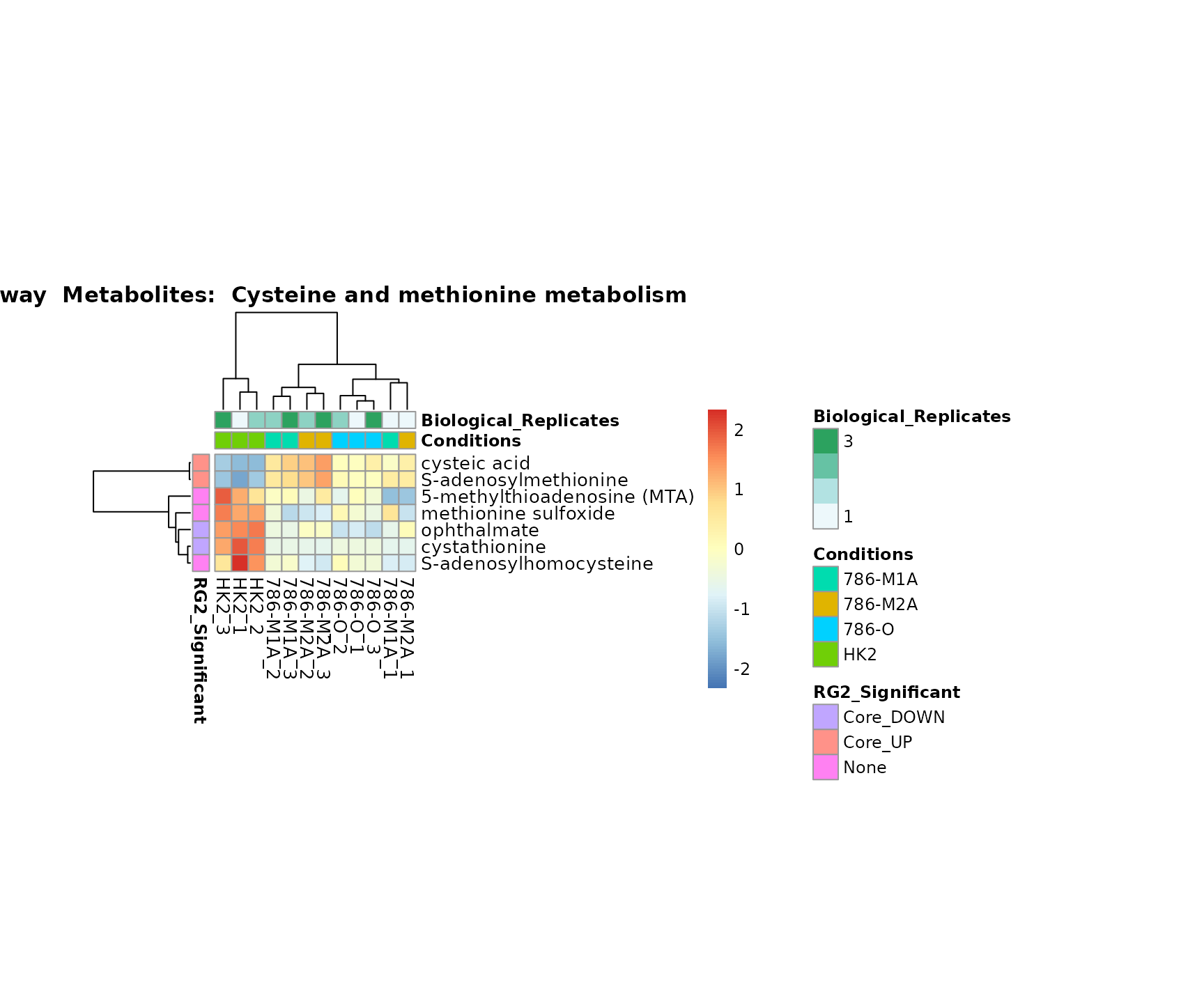
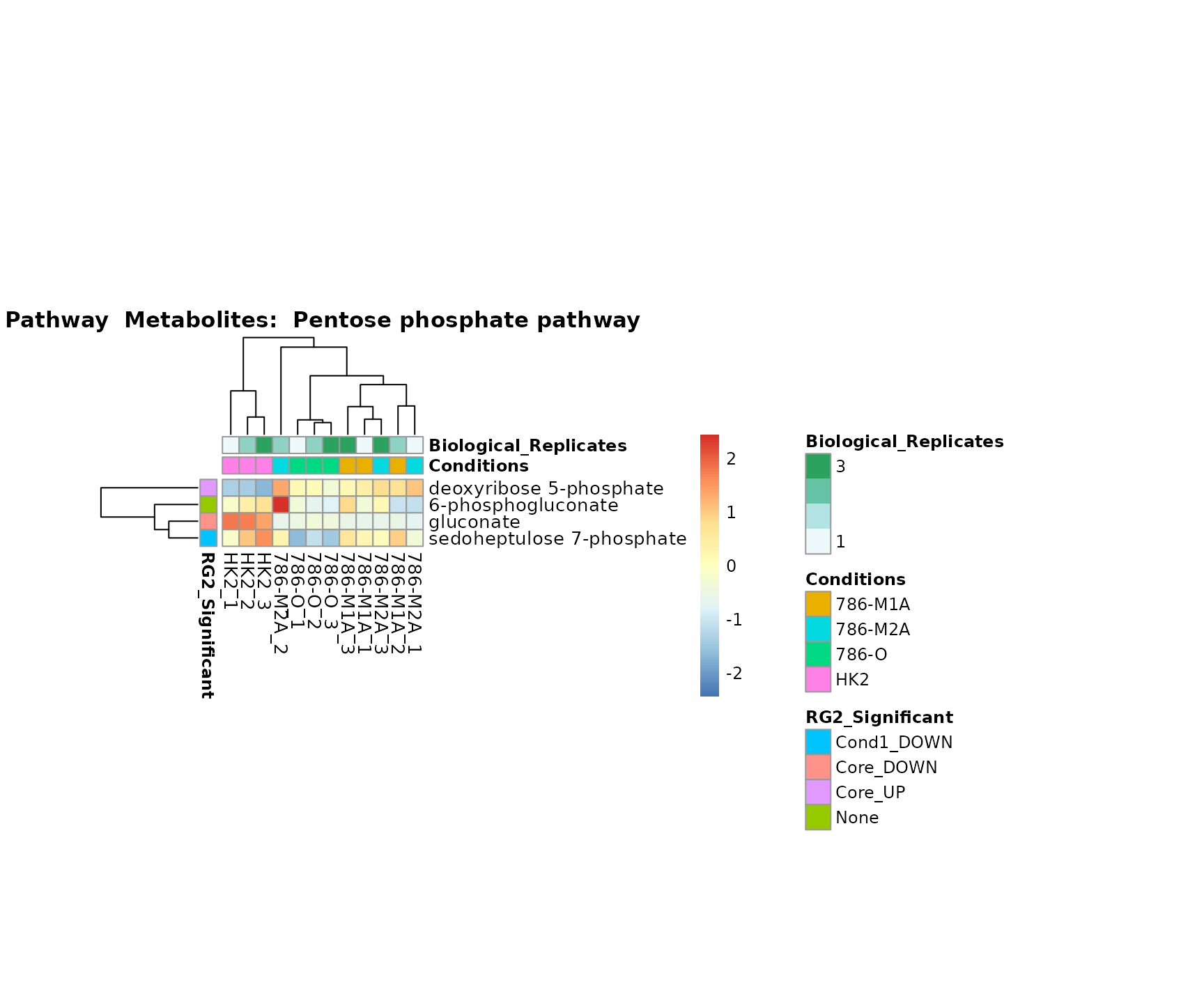




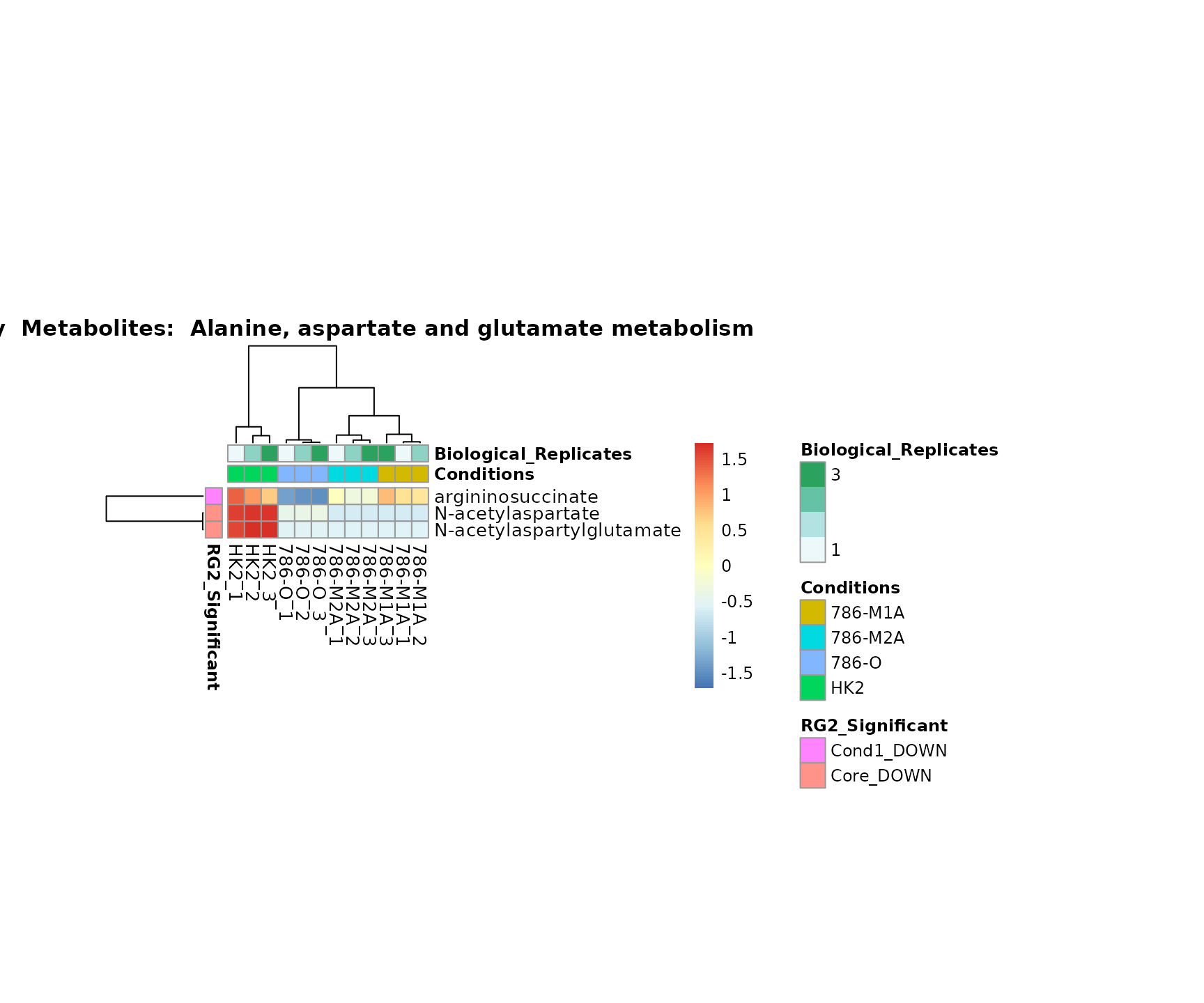
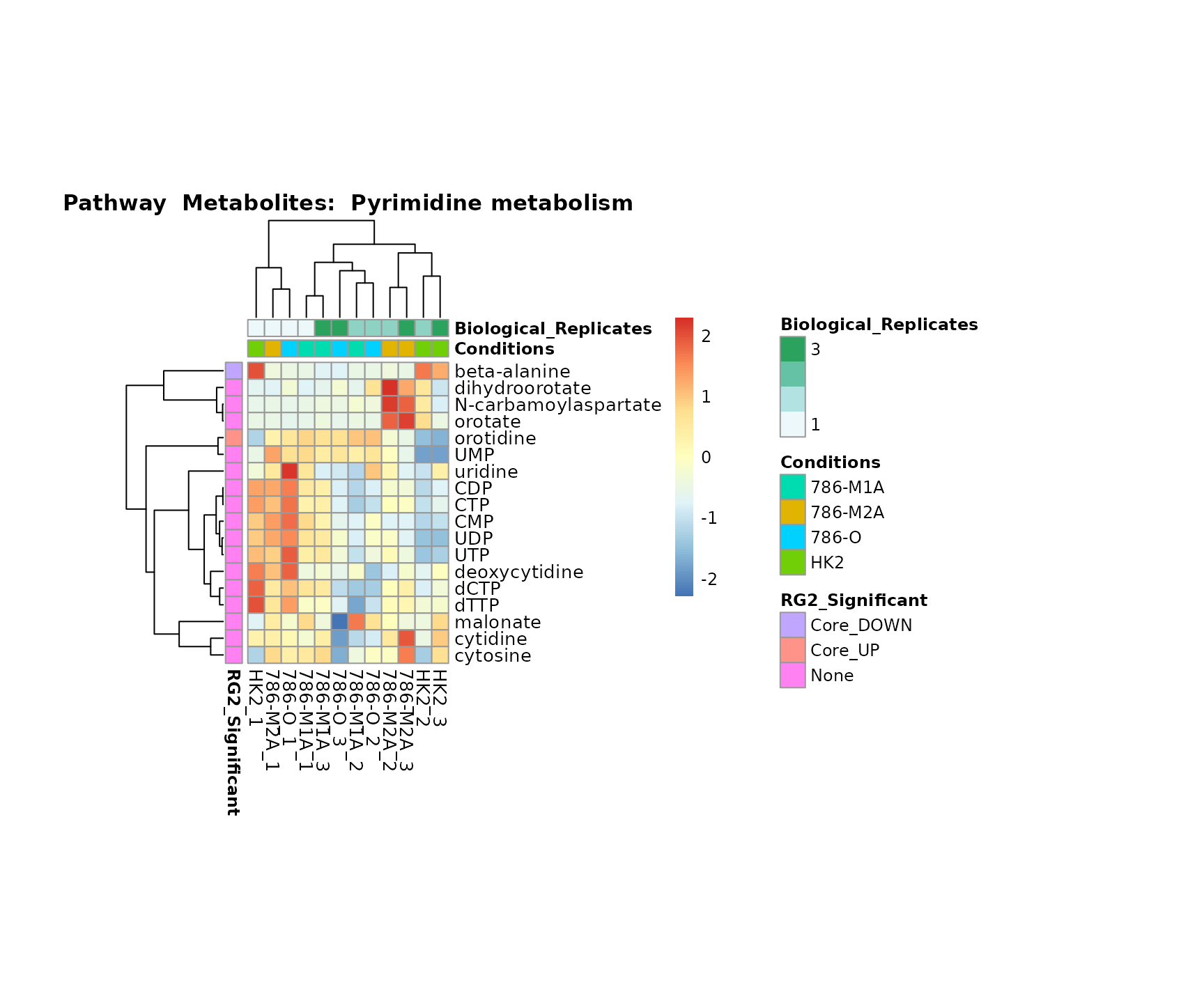
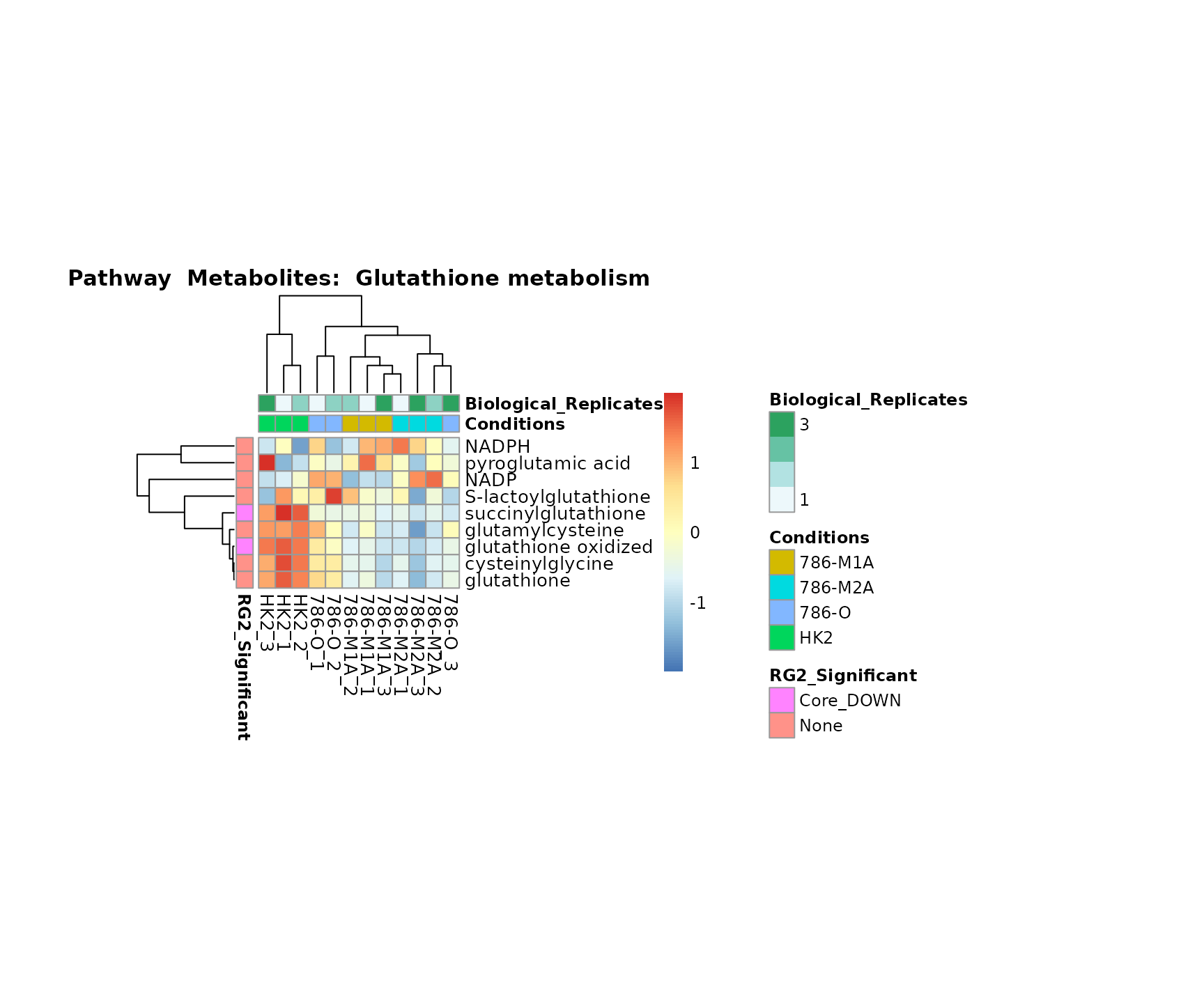


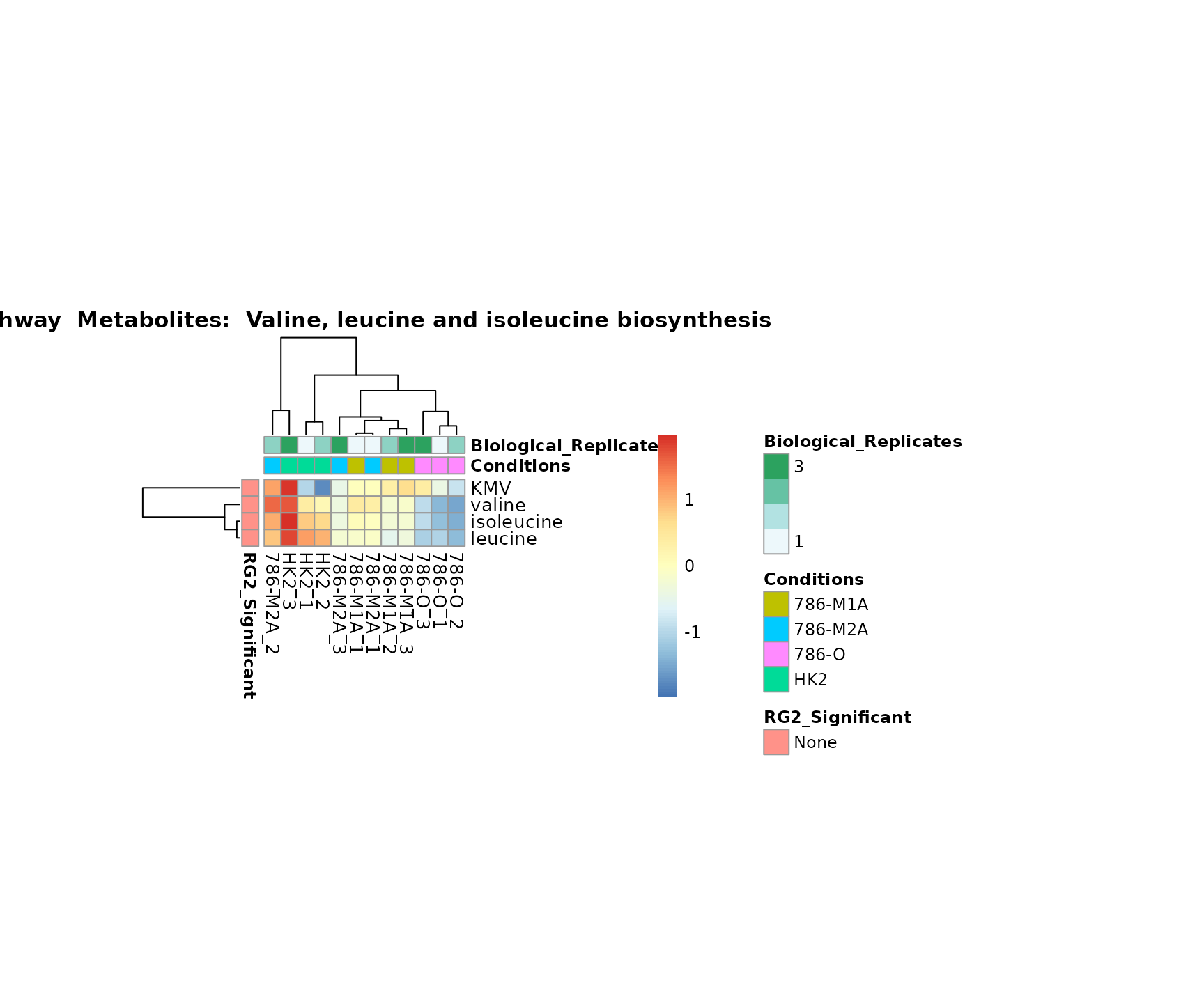
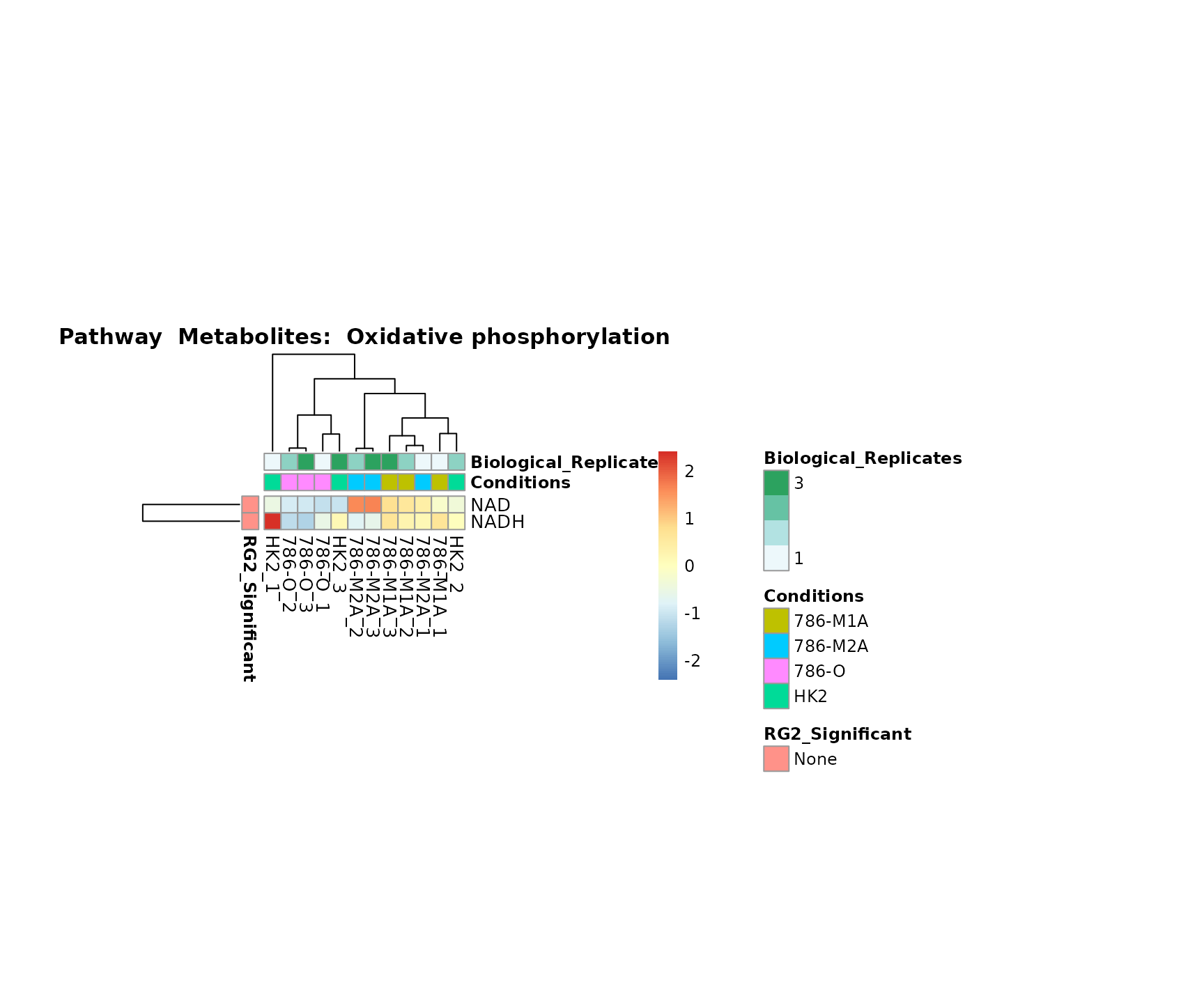
Superplots
Sometimes one might be interested to create individual plots for each
metabolite to understand the differences between specific conditions.
For this common plot types are bargraphs, boxplots or violin plots. As
input, we need a DF that contains the samples as rownames and the
features (=metabolites) as column names:
Input_Superplot <- Intra_Preprocessed[,-c(1:4)]#remove columns that include Metadata such as cell type,...| hippuric acid-d5 | 2/3-phosphoglycerate | 2-aminoadipic acid | 2-hydroxyglutarate | 2-ketoglutarate | 4-guanidinobutanoate | 4-hydroxyphenyllactate | |
|---|---|---|---|---|---|---|---|
| 786-M1A_1 | 4624712907 | 56869710 | 7515755 | 424350094 | 959154968 | 1919685 | 2200691 |
| 786-M1A_2 | 4340353963 | 48343621 | 7794629 | 432815728 | 979152171 | 1885079 | 2038710 |
| 786-M1A_3 | 4214210391 | 45802902 | 7241957 | 417484370 | 1003428045 | 2000096 | 2205282 |
| 786-M2A_1 | 4796131050 | 45783712 | 6136730 | 438371418 | 844281227 | 2623110 | 2253523 |
| 786-M2A_2 | 3846160365 | 44241237 | 6228218 | 432236949 | 885890420 | 1980782 | 2334933 |
| 786-M2A_3 | 4164512249 | 42973150 | 6389024 | 463135059 | 884908893 | 1478488 | 2226276 |
| 786-O_1 | 3896527350 | 36932026 | 8968347 | 389934195 | 887922452 | 2390741 | 2000374 |
| 786-O_2 | 4496764782 | 30493039 | 9089987 | 463318717 | 1057350518 | 2329025 | 2113869 |
| 786-O_3 | 4137100133 | 29305326 | 9025706 | 407917219 | 1012290078 | 1695489 | 2193180 |
| HK2_1 | 3171399130 | 30931592 | 5801816 | 188417805 | 326367919 | 4418820 | 3963104 |
| HK2_2 | 3180479423 | 32564867 | 7322390 | 228825446 | 366703618 | 4133883 | 3971958 |
| HK2_3 | 3365930405 | 29507162 | 7159140 | 251061831 | 459945537 | 4366242 | 4226693 |
We also need the Metadata as we will need to know which conditions to
plot for together. If you have further information such as replicates or
patient ID, we can use this for the colour of the plotted samples per
condition as in the superplots style as described in by Lord et al (Lord et al. 2020).
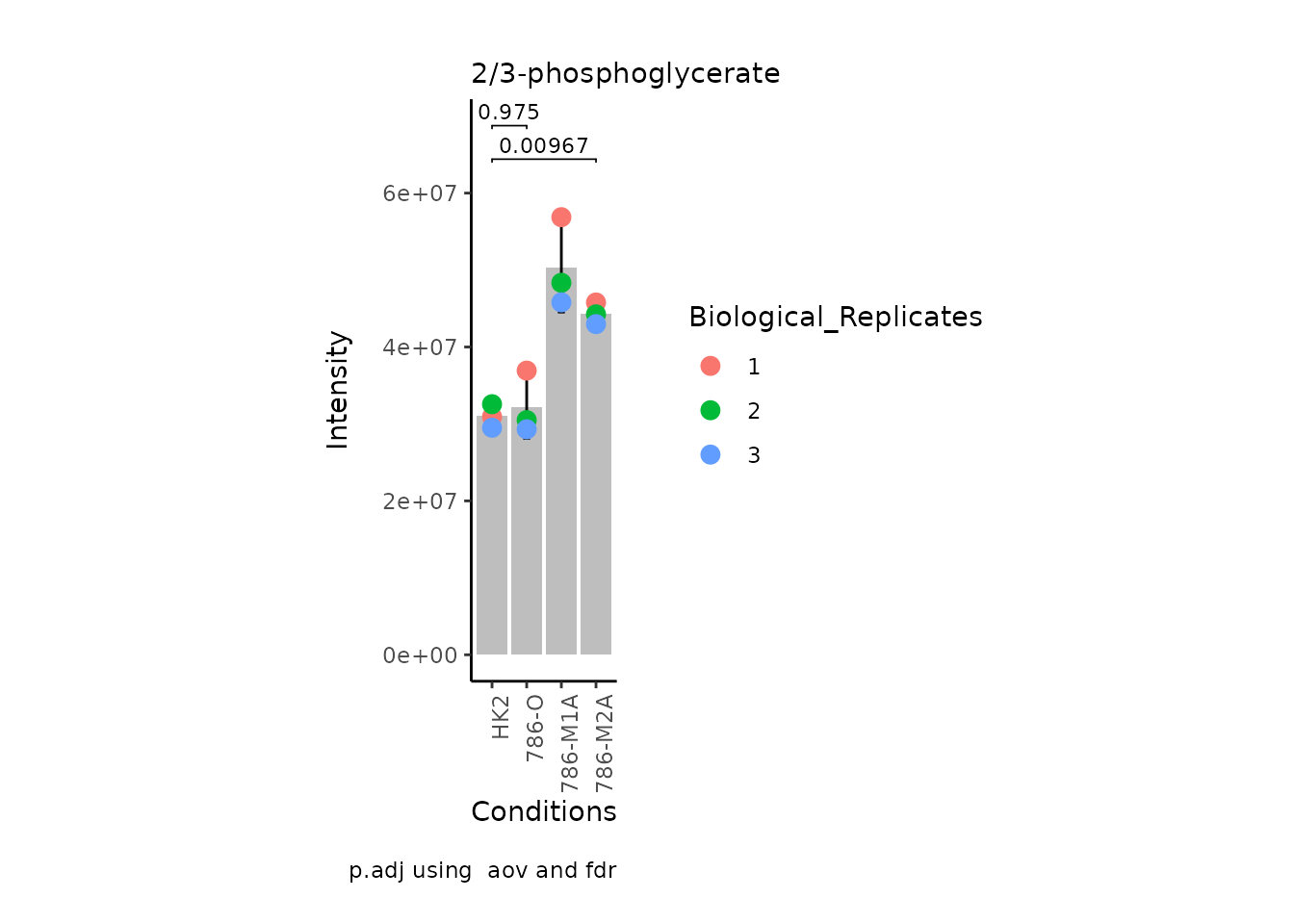
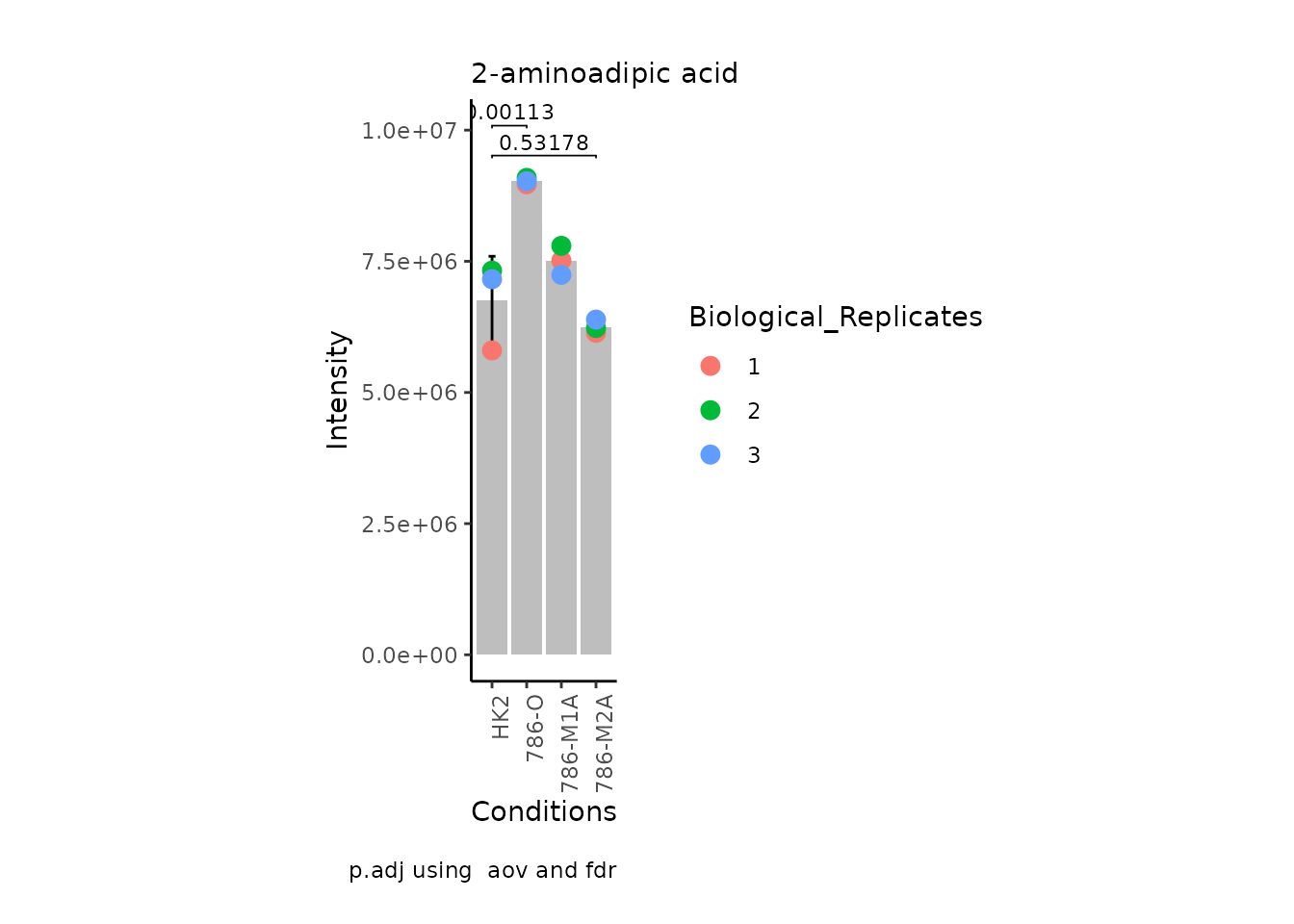
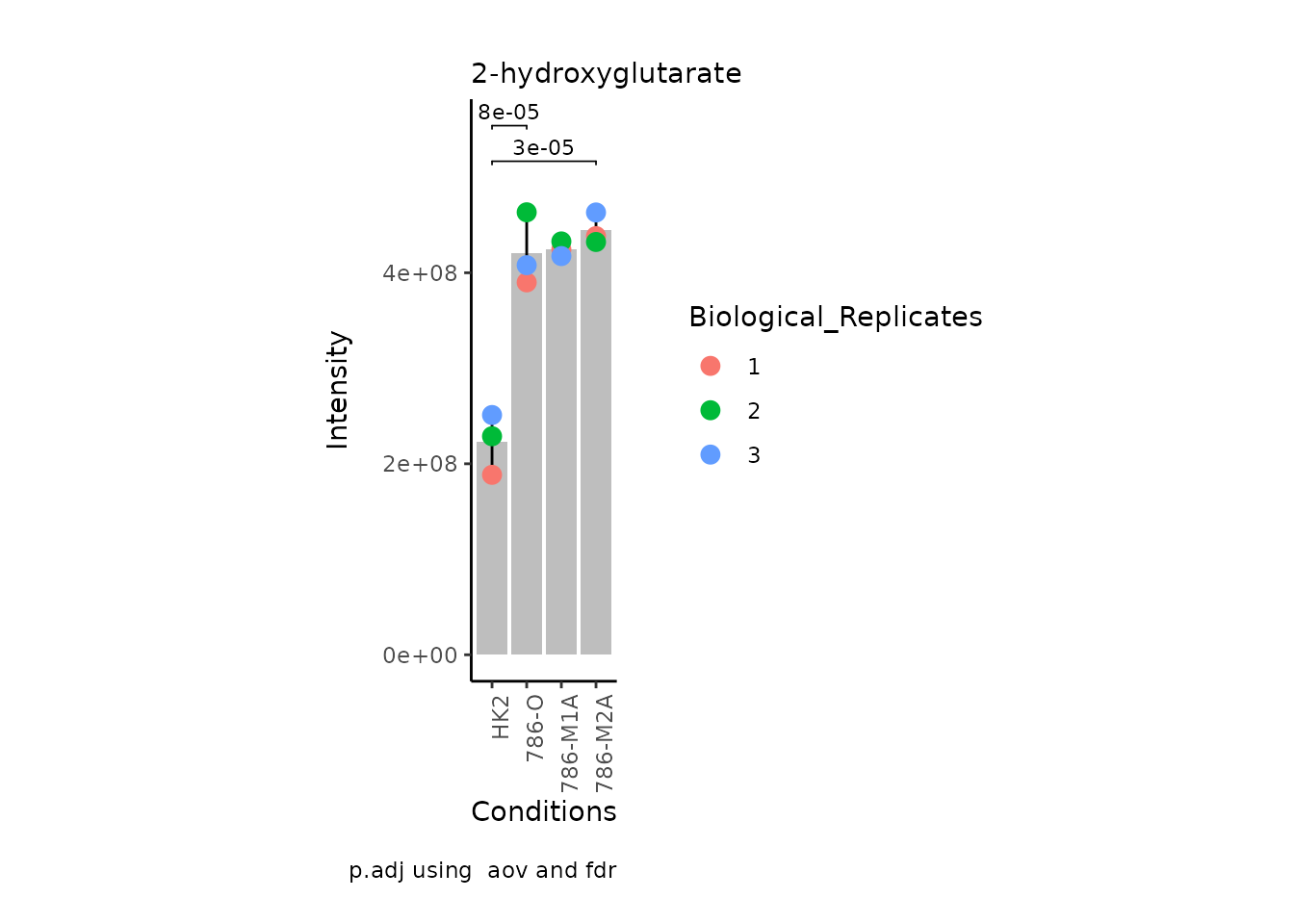
MetaProViz:::VizSuperplot(InputData =Input_Superplot[,c(1:6)],#We just plot six metabolites
SettingsFile_Sample =MetaData_Sample,
SettingsInfo = c(Conditions="Conditions", Superplot = "Biological_Replicates"),
PlotType = "Bar", #Bar, Box, Violin
PlotConditions = c("HK2", "786-O", "786-M1A", "786-M2A"),#sets the order in which the samples should be plotted
StatComparisons = list(c(1,2),c(1,4)))#Stat comparisons to be included on the plot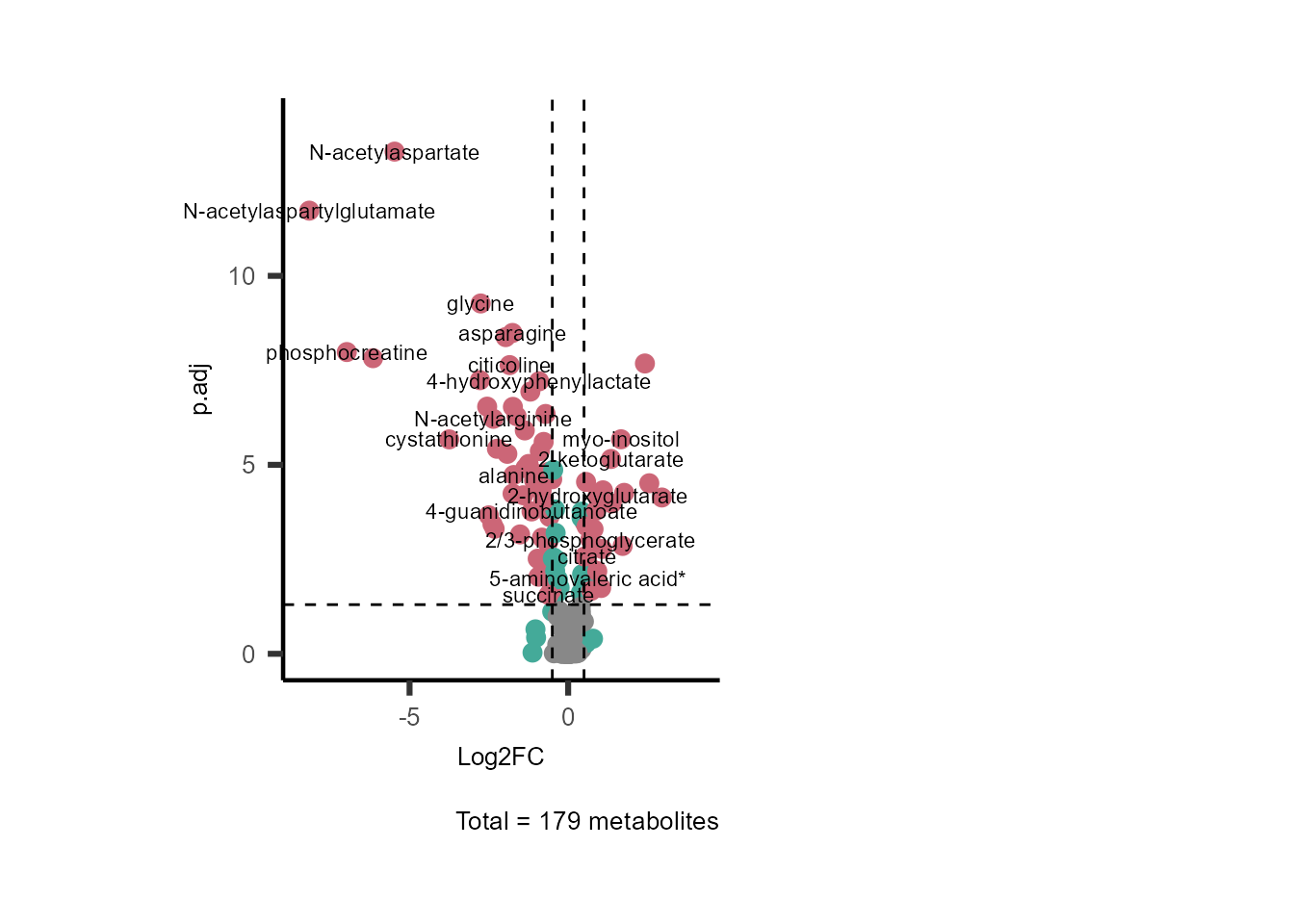
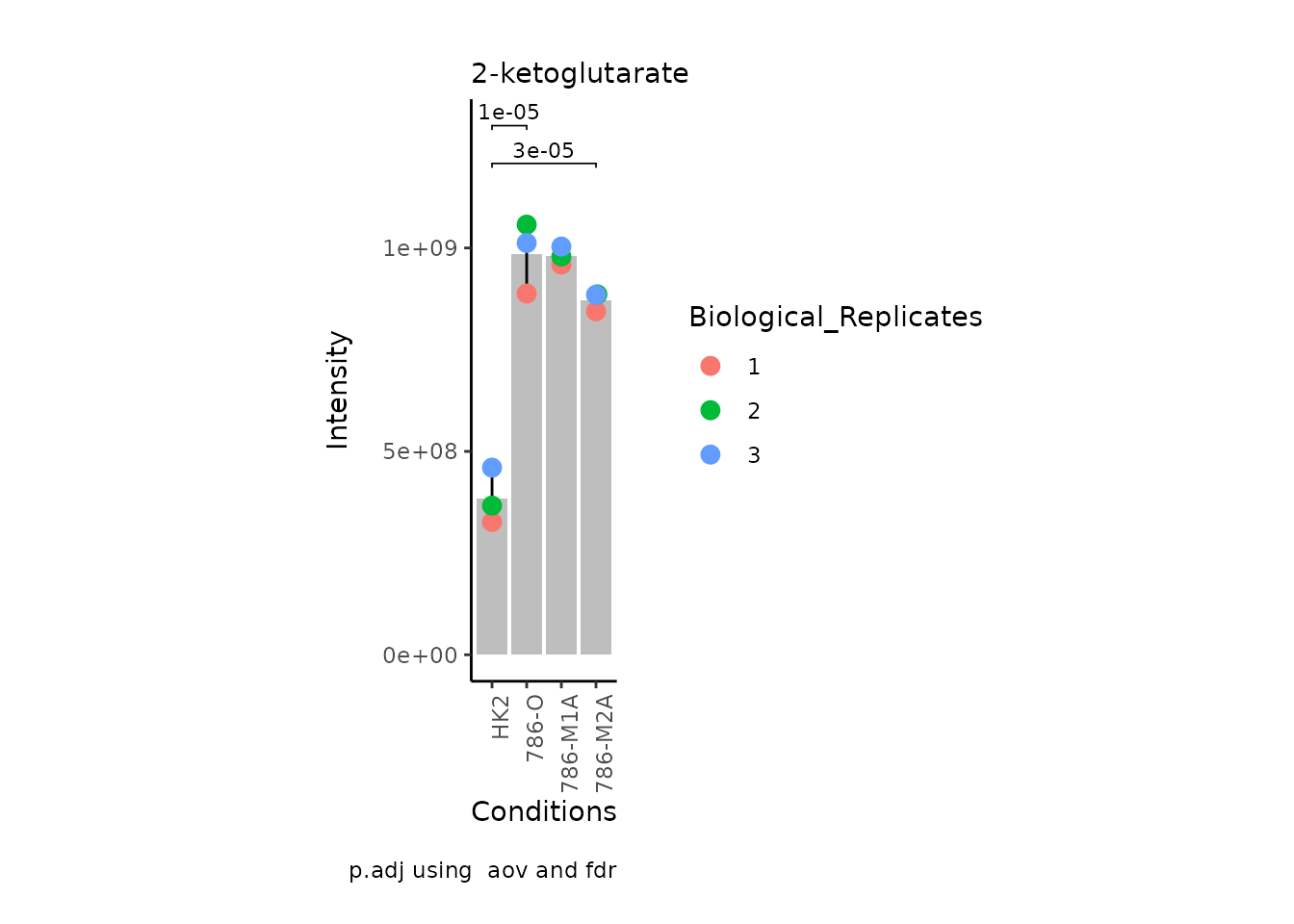
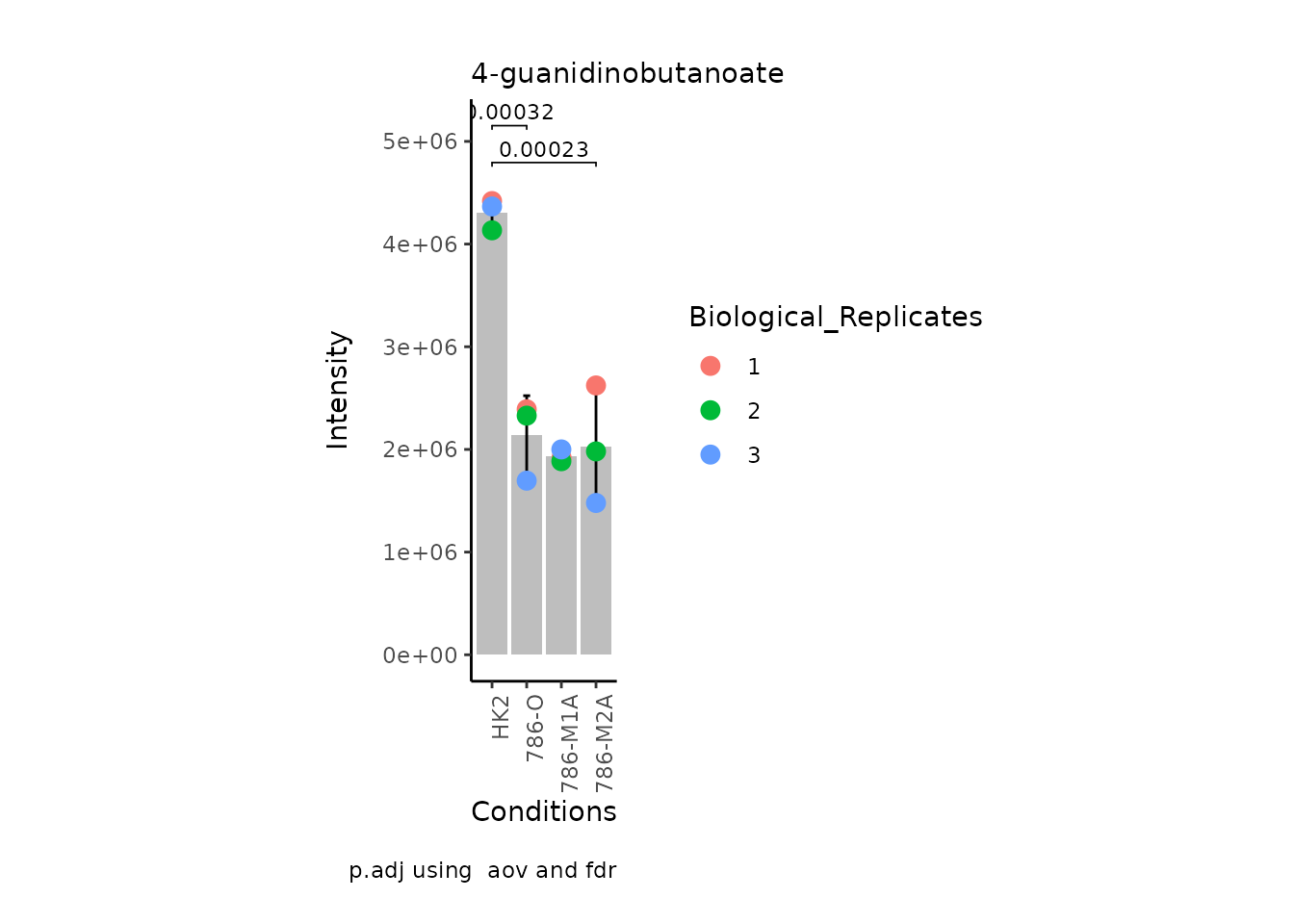
Now, if we for instance prefer boxplots over bargraphs we can simply
change the parameter PlotType:
MetaProViz:::VizSuperplot(InputData =Input_Superplot[,c(1:6)],#We just plot six metabolites
SettingsFile_Sample =MetaData_Sample,
SettingsInfo = c(Conditions="Conditions", Superplot = "Biological_Replicates"),
PlotType = "Box", #Bar, Box, Violin
PlotConditions = c("HK2", "786-O", "786-M1A", "786-M2A"),#sets the order in which the samples should be plotted
StatComparisons = list(c(1,2),c(1,4)))#Stat comparisons to be included on the plot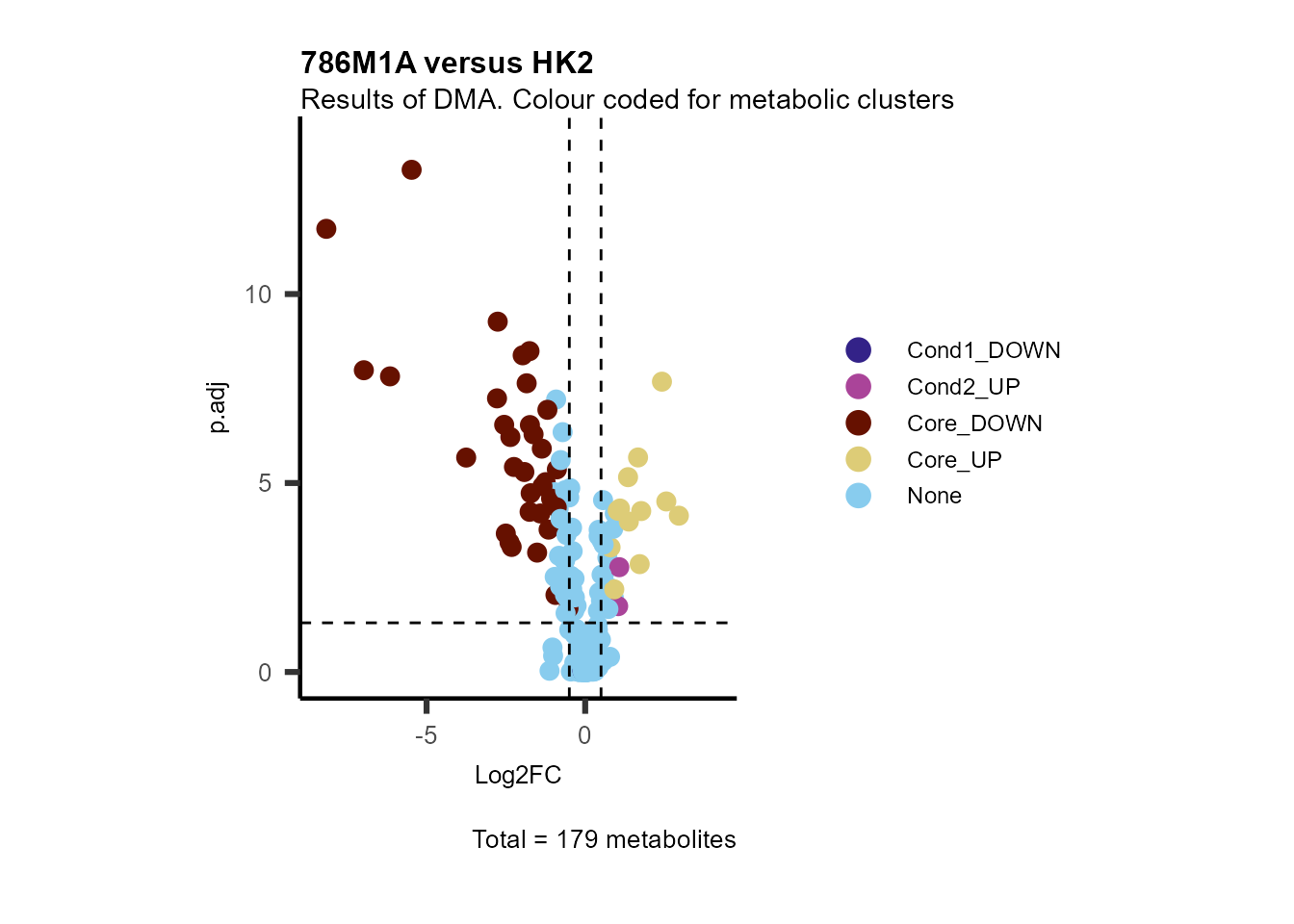

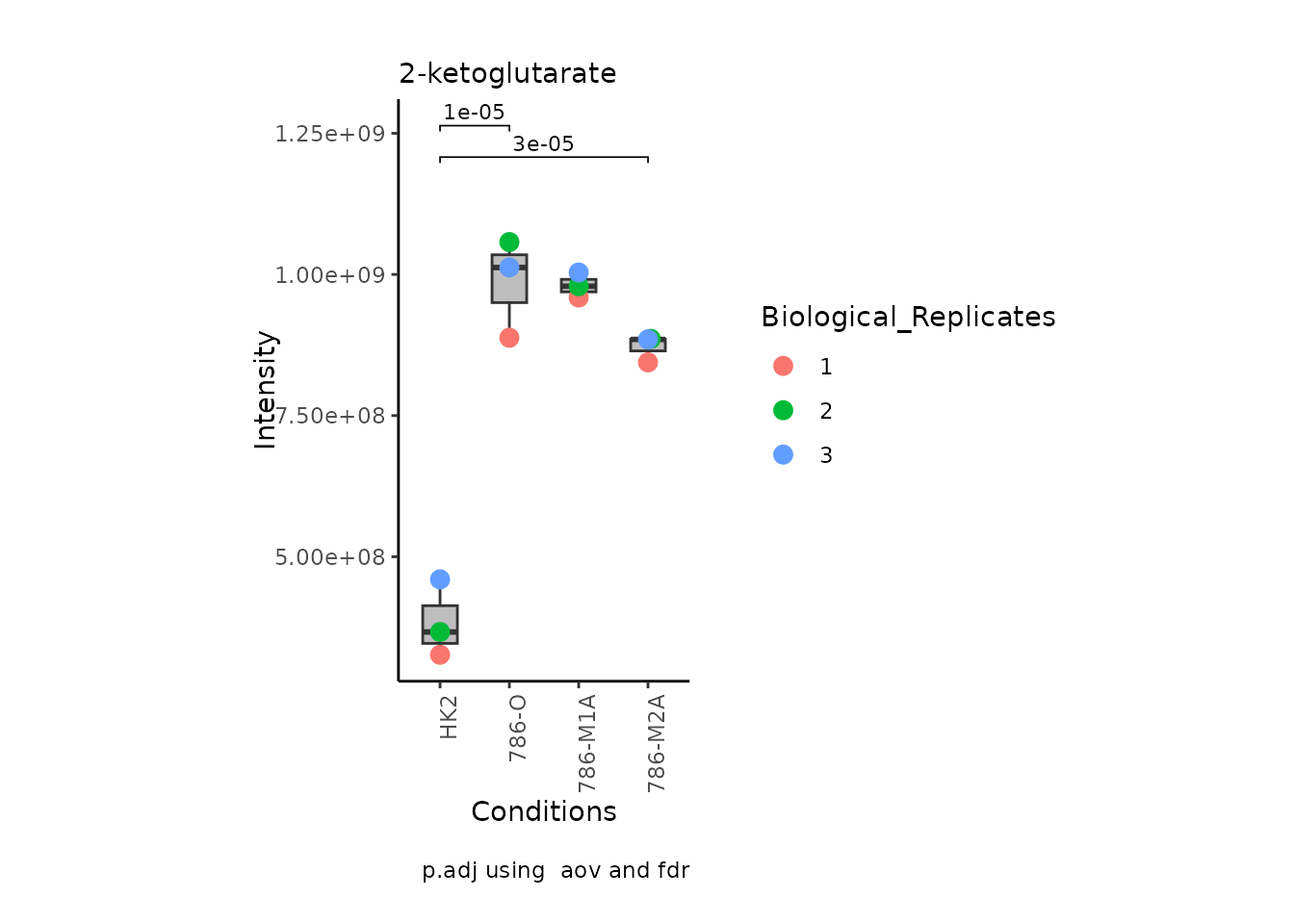
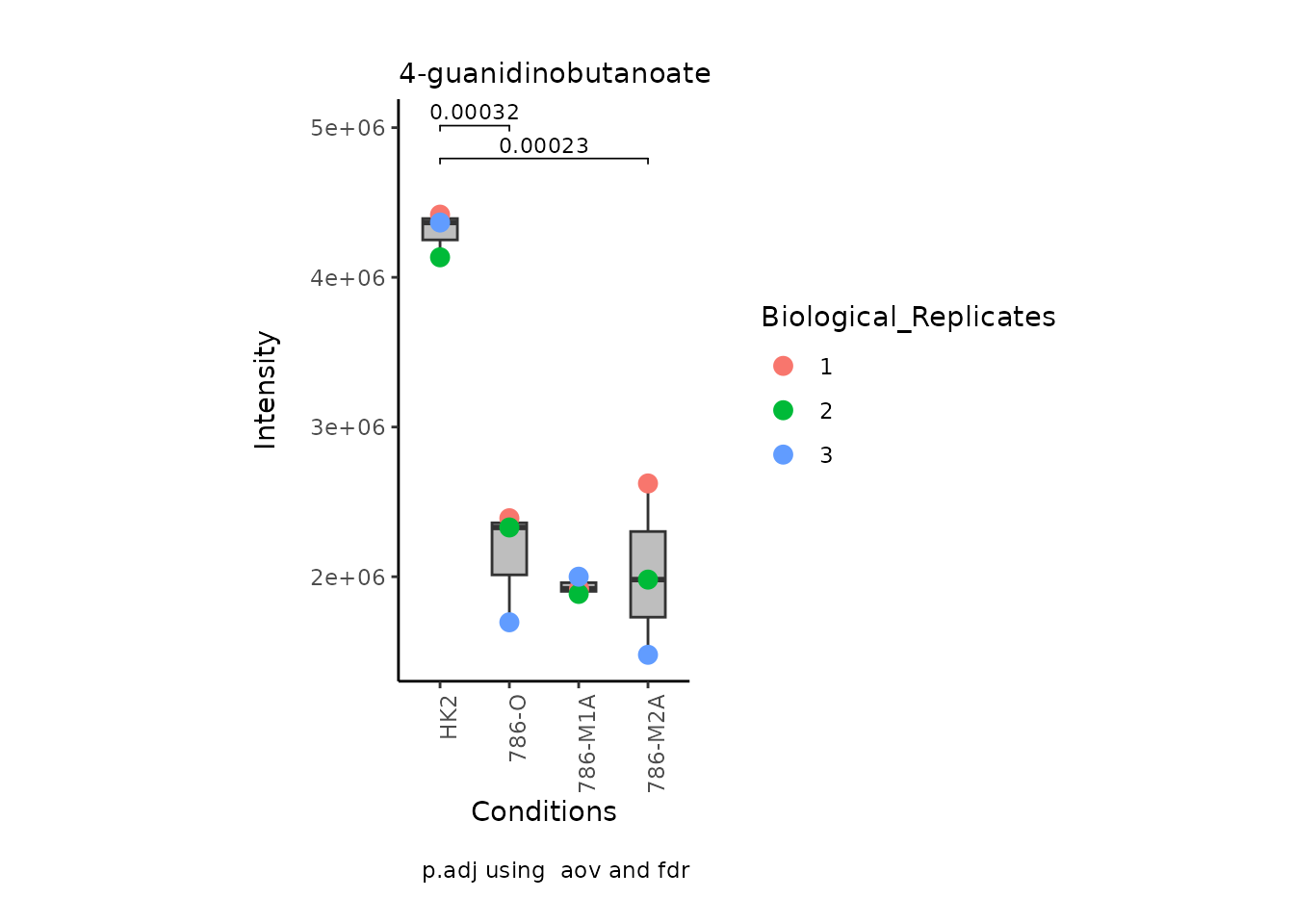
We can also change it to violin plots:
MetaProViz:::VizSuperplot(InputData =Input_Superplot[,c(1:6)],#We just plot six metabolites
SettingsFile_Sample =MetaData_Sample,
SettingsInfo = c(Conditions="Conditions", Superplot = "Biological_Replicates"),
PlotType = "Violin", #Bar, Box, Violin
PlotConditions = c("HK2", "786-O", "786-M1A", "786-M2A"),#sets the order in which the samples should be plotted
StatComparisons = list(c(1,2),c(1,4)))#Stat comparisons to be included on the plot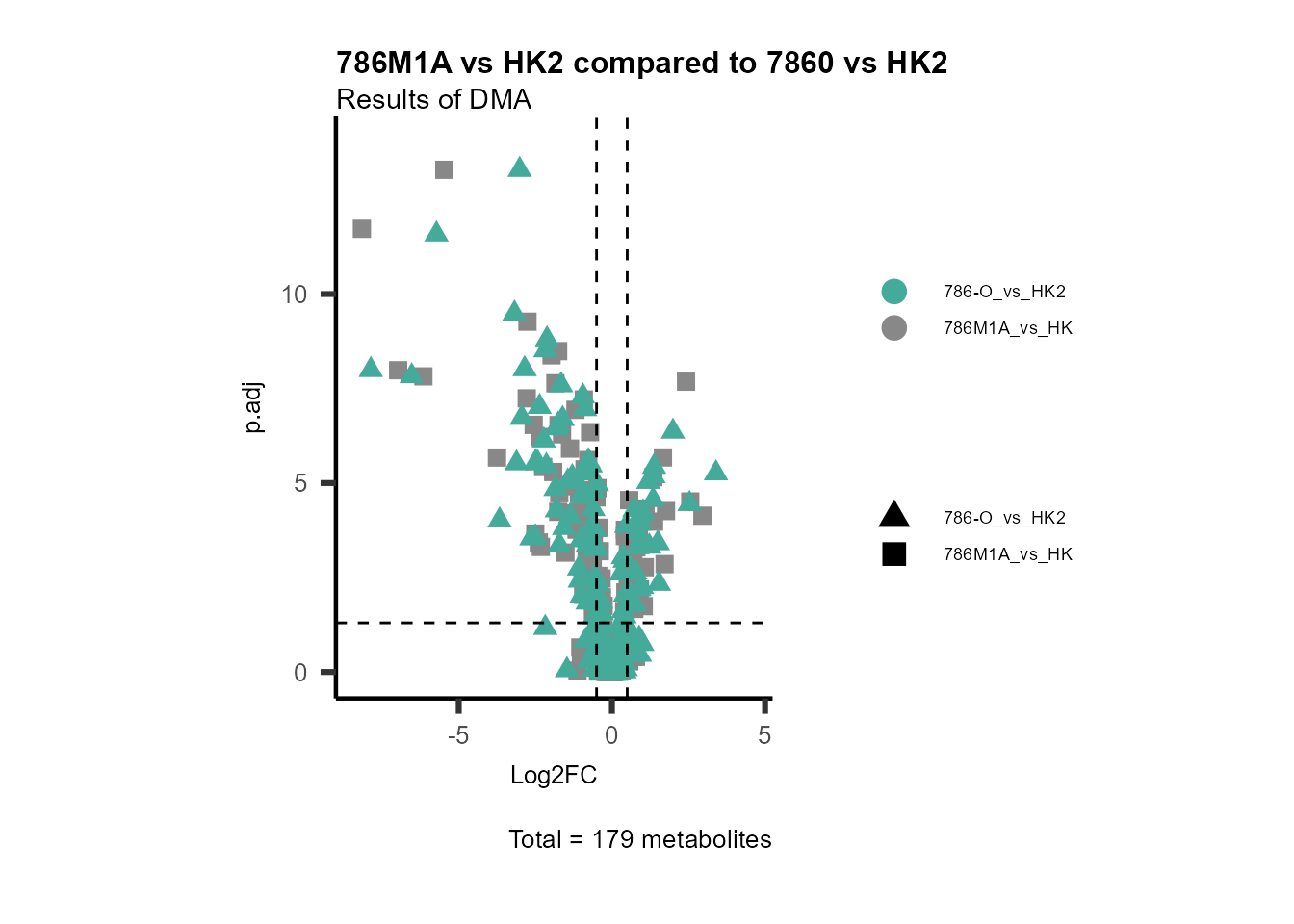
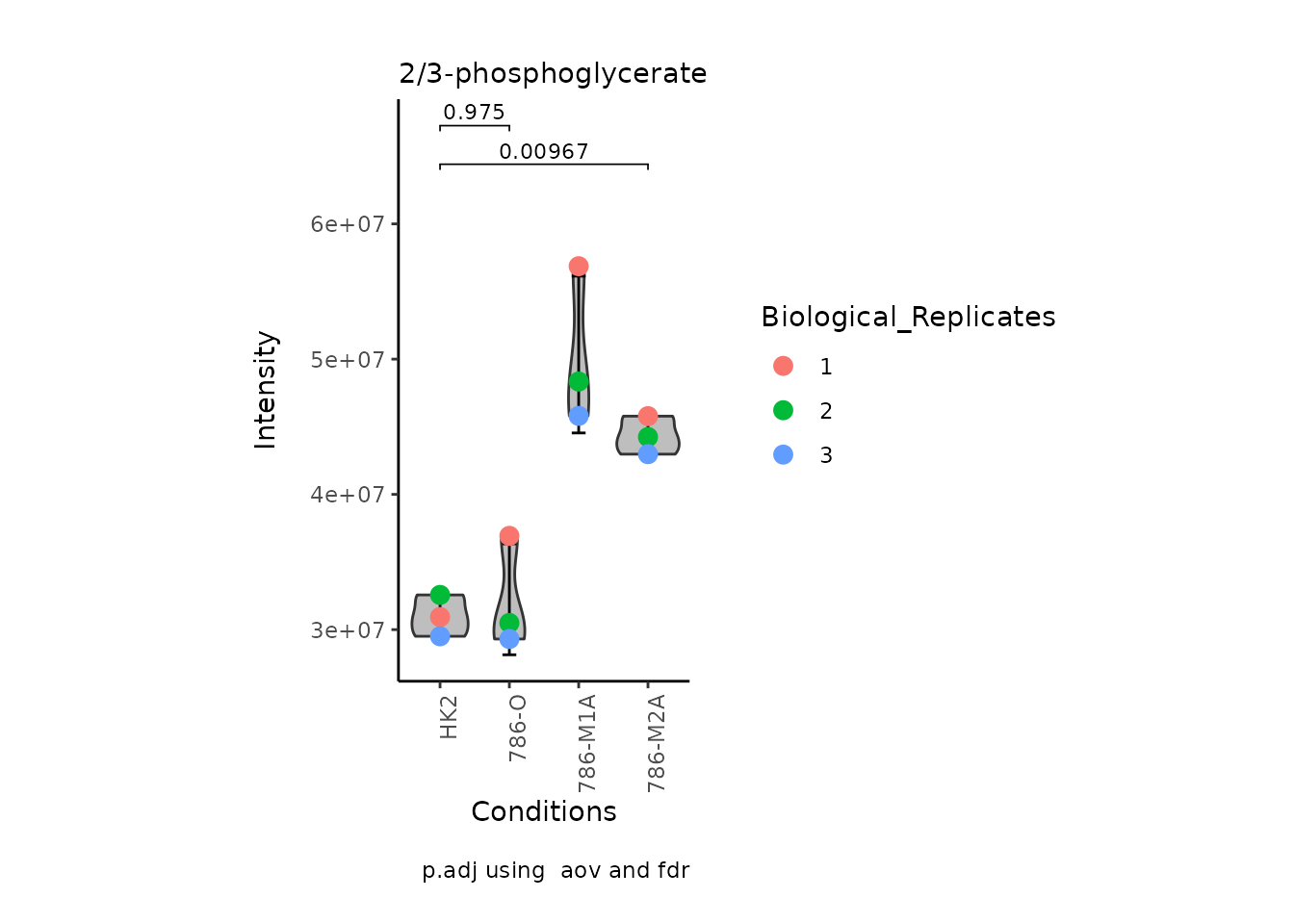
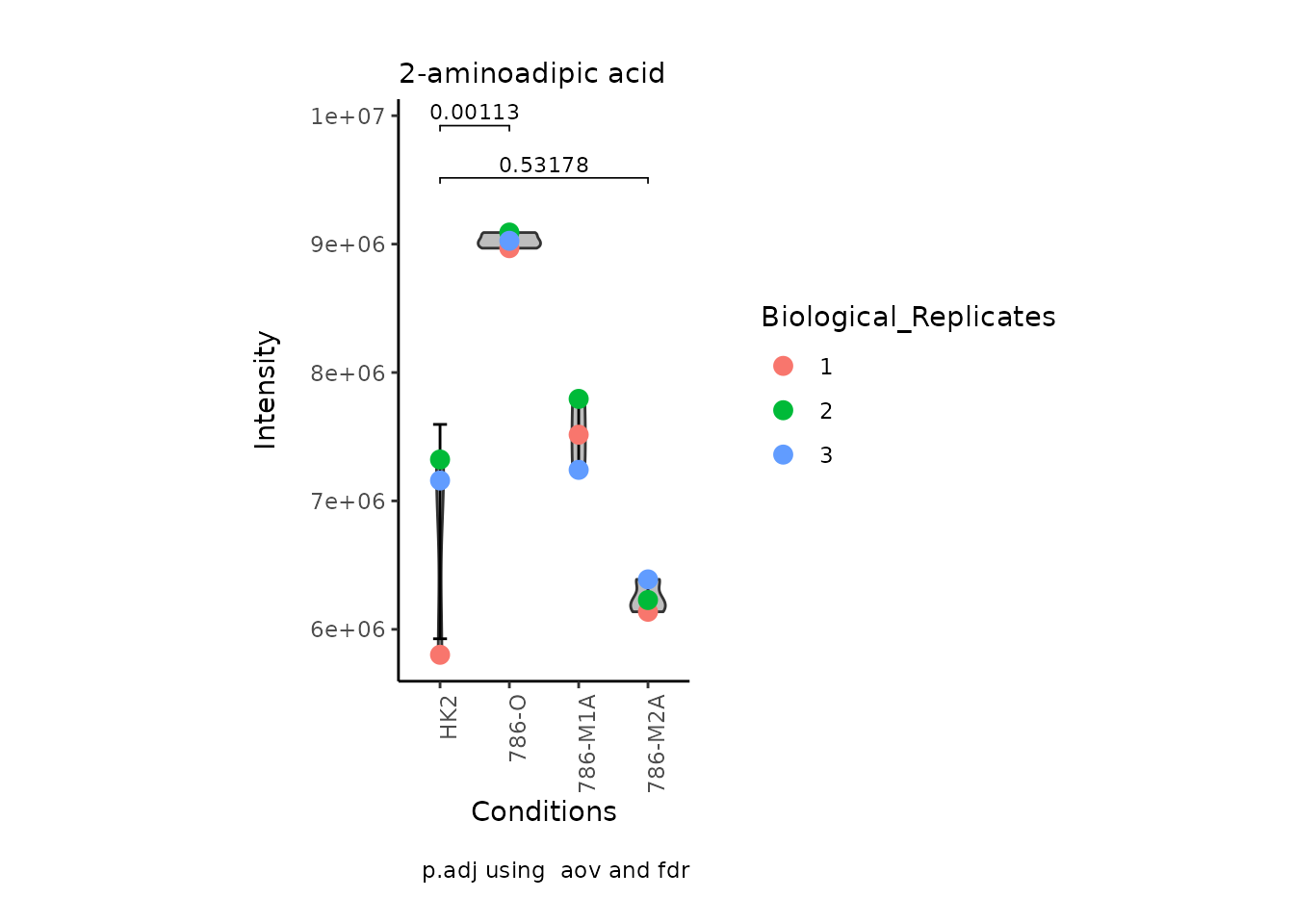
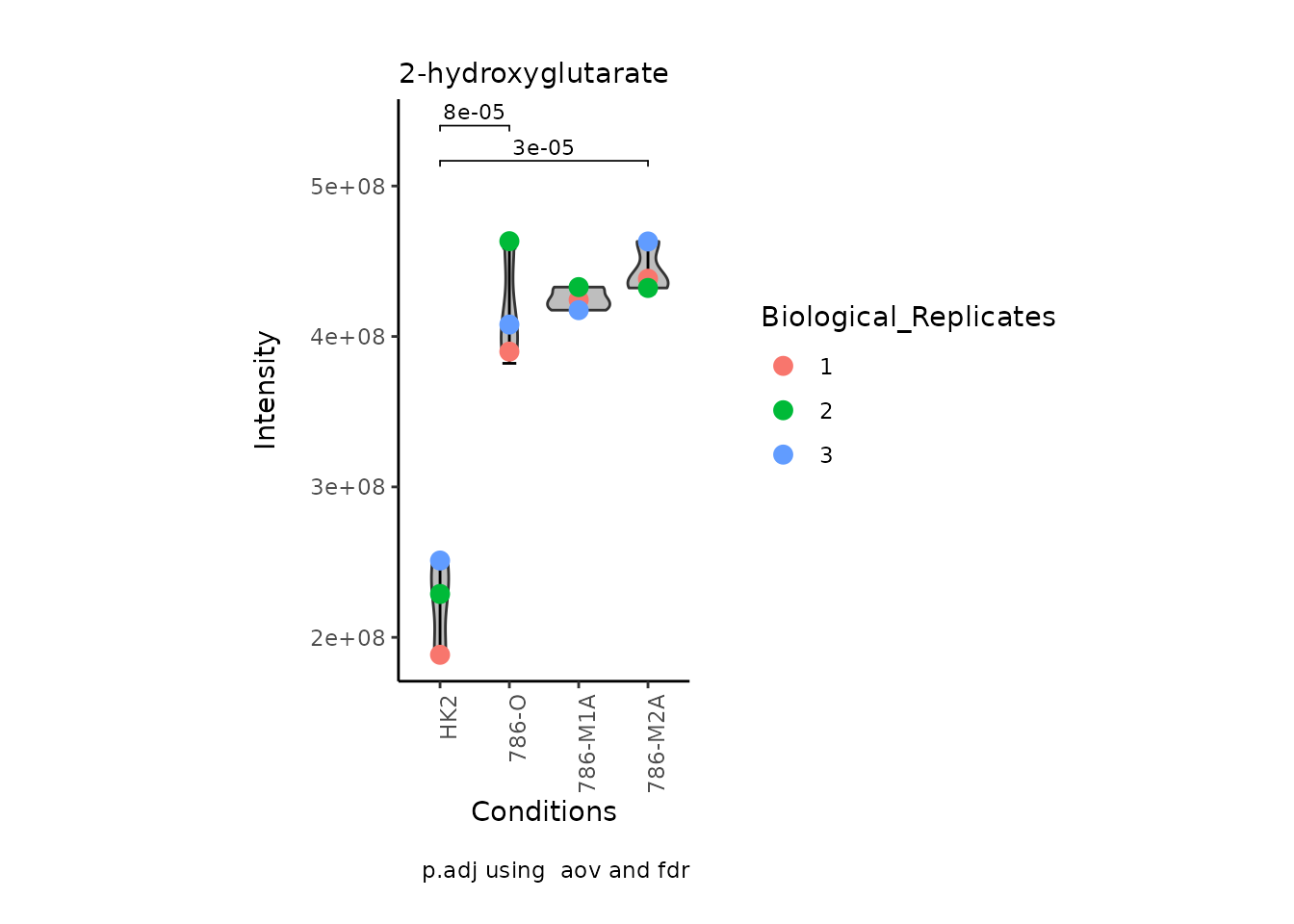
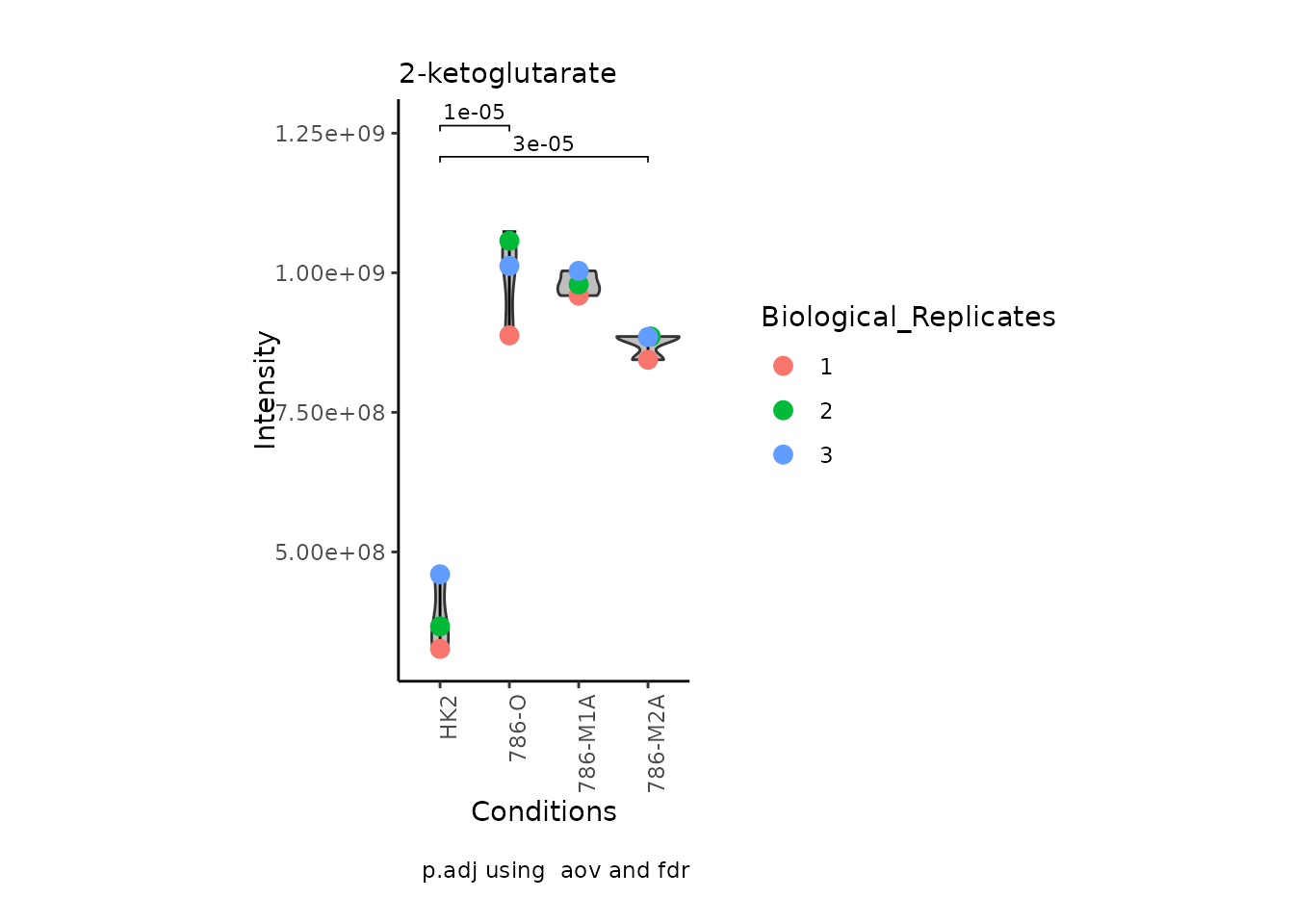
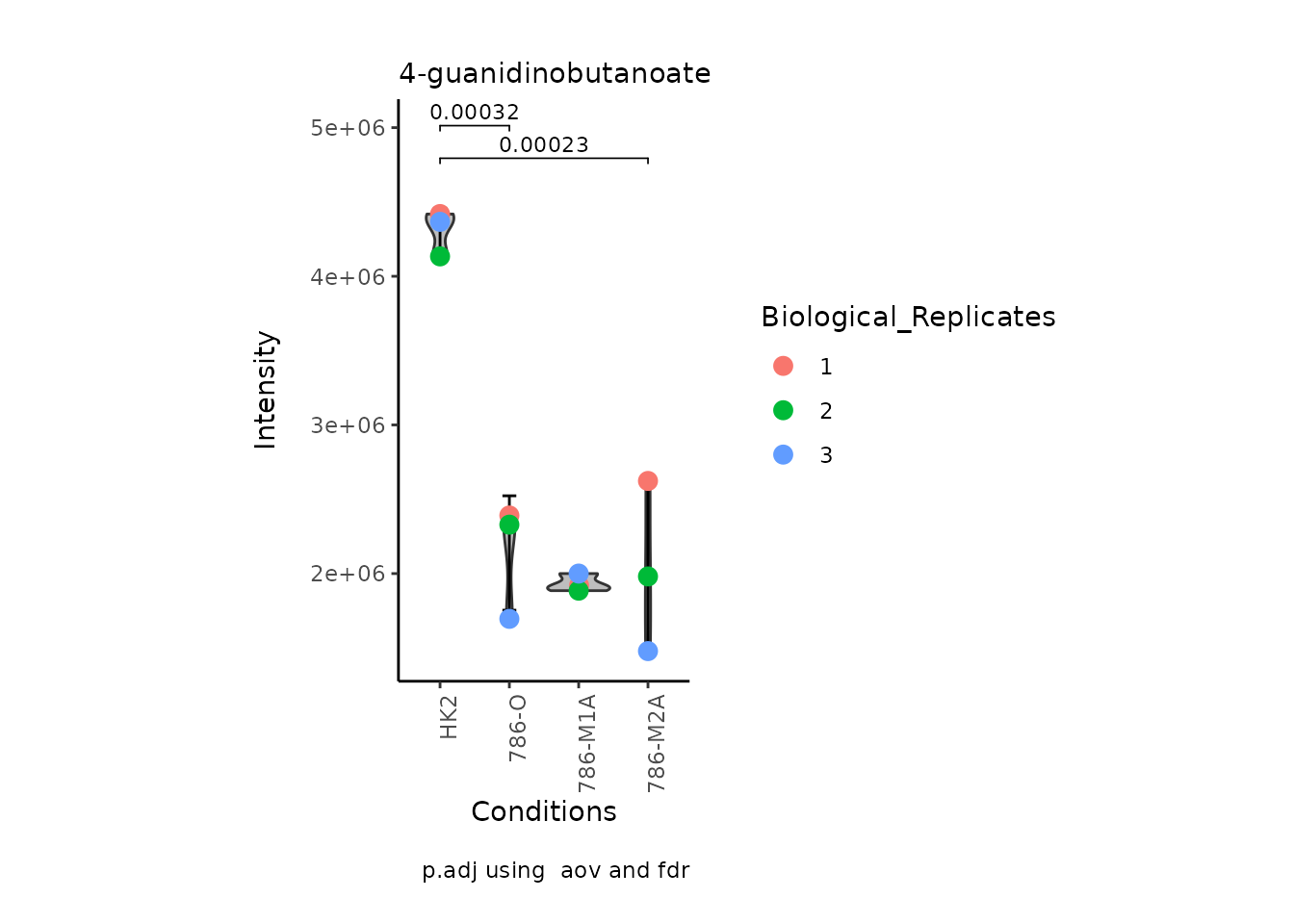
Volcano plot
In general,we have three differentPlot_Settings, which
will also be used for other plot types such as lollipop graphs.1. "Standard" is the standard version of the
plot, with one dataset being plotted.2. "Conditions" here two or more datasets will
be plotted together. How datasets can be plotted together depends on the
plot type.3. "PEA" stands for Pathway Enrichment
Analysis, and is used if the results of an GSE analysis should be
plotted as here the figure legends will be adapted.Here we will look at all the different options we have to display our results from the different analysis (DMA, PEA), which will help us to interpret our results as this can be sometimes difficult to do from the many data tables.
Just a quick reminder, how the input data look like:
1. Results of Differential Metabolite Analysis (DMA): Log2FC and stats:
| Metabolite | Log2FC | p.adj | t.val | 786-M1A_1 | 786-M1A_2 | 786-M1A_3 | HK2_1 | HK2_2 | HK2_3 | HMDB | KEGG.ID | KEGGCompound | Pathway |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2-aminoadipic acid | 0.1529816 | 0.2378483 | -756331.9 | 7515755 | 7794629 | 7241957 | 5801816 | 7322390 | 7159140 | HMDB0302754 | NA | NA | Not assigned |
| 2-hydroxyglutarate | 0.9315226 | 0.0000645 | -202115036.9 | 424350094 | 432815728 | 417484370 | 188417805 | 228825446 | 251061831 | HMDB0059655 | C02630 | 2-Hydroxyglutarate | Citrate cycle (TCA cycle) |
| 2-ketoglutarate | 1.3512535 | 0.0000070 | -596239369.8 | 959154968 | 979152171 | 1003428045 | 326367919 | 366703618 | 459945537 | HMDB0000208 | C00026 | 2-Oxoglutarate | Citrate cycle (TCA cycle) |
| 2/3-phosphoglycerate | 0.6993448 | 0.0009461 | -19337537.4 | 56869710 | 48343621 | 45802902 | 30931592 | 32564867 | 29507162 | HMDB0060180 | C00197 | 3-Phospho-D-glycerate | Glycolysis / Gluconeogenesis |
| 4-guanidinobutanoate | -1.1541552 | 0.0001710 | 2371361.7 | 1919685 | 1885079 | 2000096 | 4418820 | 4133883 | 4366242 | HMDB0003464 | C01035 | 4-Guanidinobutanoate | Arginine and proline metabolism |
| 4-hydroxyphenyllactate | -0.9161702 | 0.0000001 | 1905691.0 | 2200691 | 2038710 | 2205282 | 3963104 | 3971958 | 4226693 | HMDB0000755 | C03672 | 3-(4-Hydroxyphenyl)lactate | Not assigned |
| 5-aminolevulinic acid | -0.1777271 | 0.4915165 | 525130.3 | 3774613 | 3938304 | 4303746 | 4028435 | 4373207 | 5190412 | HMDB0001149 | C00430 | 5-Aminolevulinate | Not assigned |
2. Results from Pathway Enrichment Analysis (PEA): Score (e.g. NES score) and stats
| GeneRatio | BgRatio | pvalue | p.adjust | qvalue | Count | Metabolites_in_Pathway | Percentage_of_Pathway_detected |
|---|---|---|---|---|---|---|---|
| 12/25 | 32/129 | 0.0043514 | 0.2210152 | 0.2035666 | 12 | 130 | 9.23 |
| 8/25 | 18/129 | 0.0078934 | 0.2210152 | 0.2035666 | 8 | 69 | 11.59 |
| 4/25 | 6/129 | 0.0129138 | 0.2410577 | 0.2220268 | 4 | 47 | 8.51 |
| 6/25 | 14/129 | 0.0295646 | 0.3613164 | 0.3327915 | 6 | 27 | 22.22 |
Standard
Here we will first look into the results from the differential
analysis (see section DMA above) for the comparison of
786-M1A_vs_HK2:
# Run with default parameter --> only need to provide Input_data and the title we like
MetaProViz::VizVolcano(InputData=DMA_786M1A_vs_HK2%>%tibble::column_to_rownames("Metabolite"))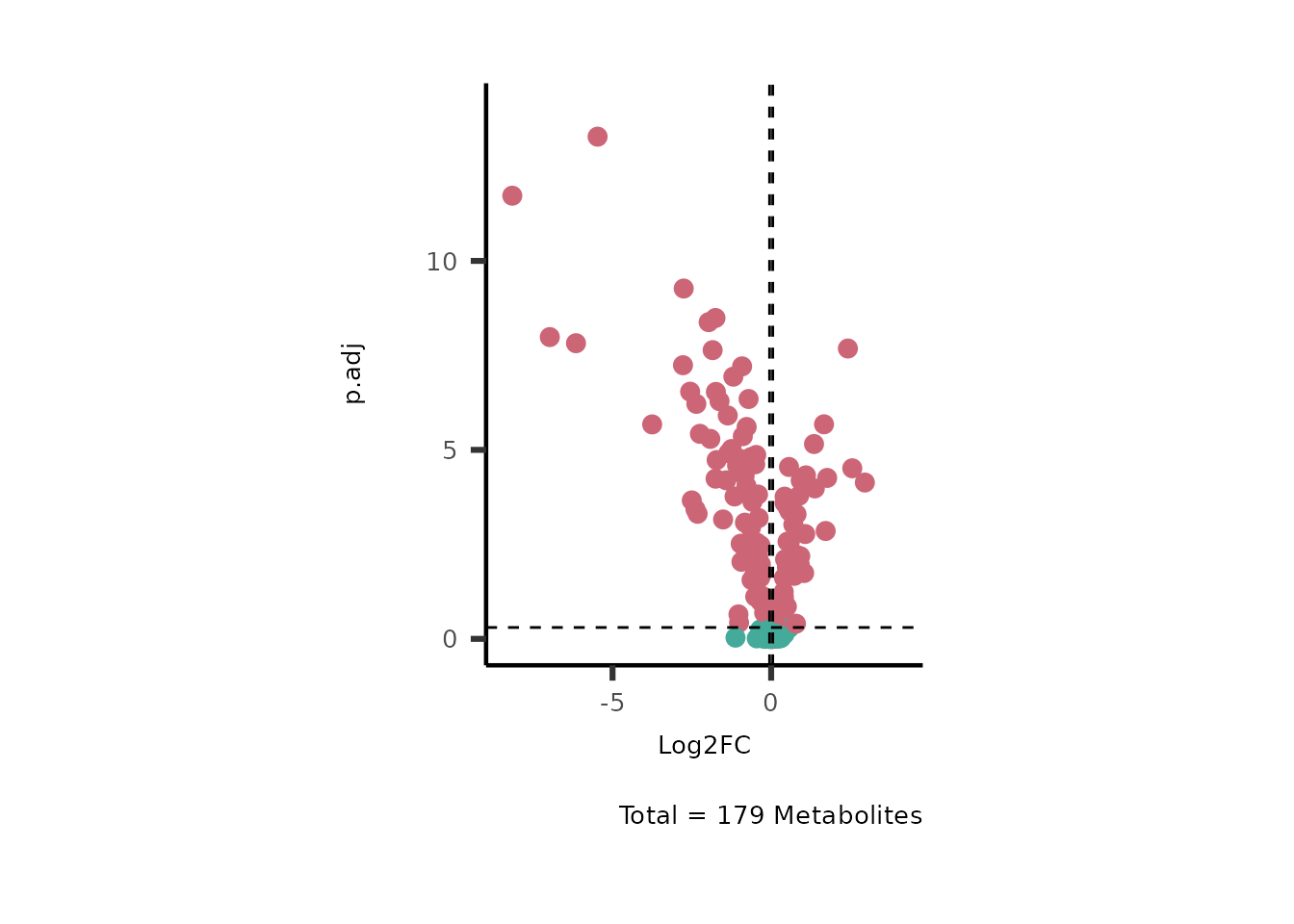
Figure: Standard figure displaying DMA results.
If you seek to plot the metabolite names you can change the paramter
SelectLab from its default (SelectLab="") to
NULL and the metabolite names will be plotted randomly.
# Run with default parameter --> only need to provide Input_data and the title we like
MetaProViz::VizVolcano(InputData=DMA_786M1A_vs_HK2%>%tibble::column_to_rownames("Metabolite"),
SelectLab = NULL)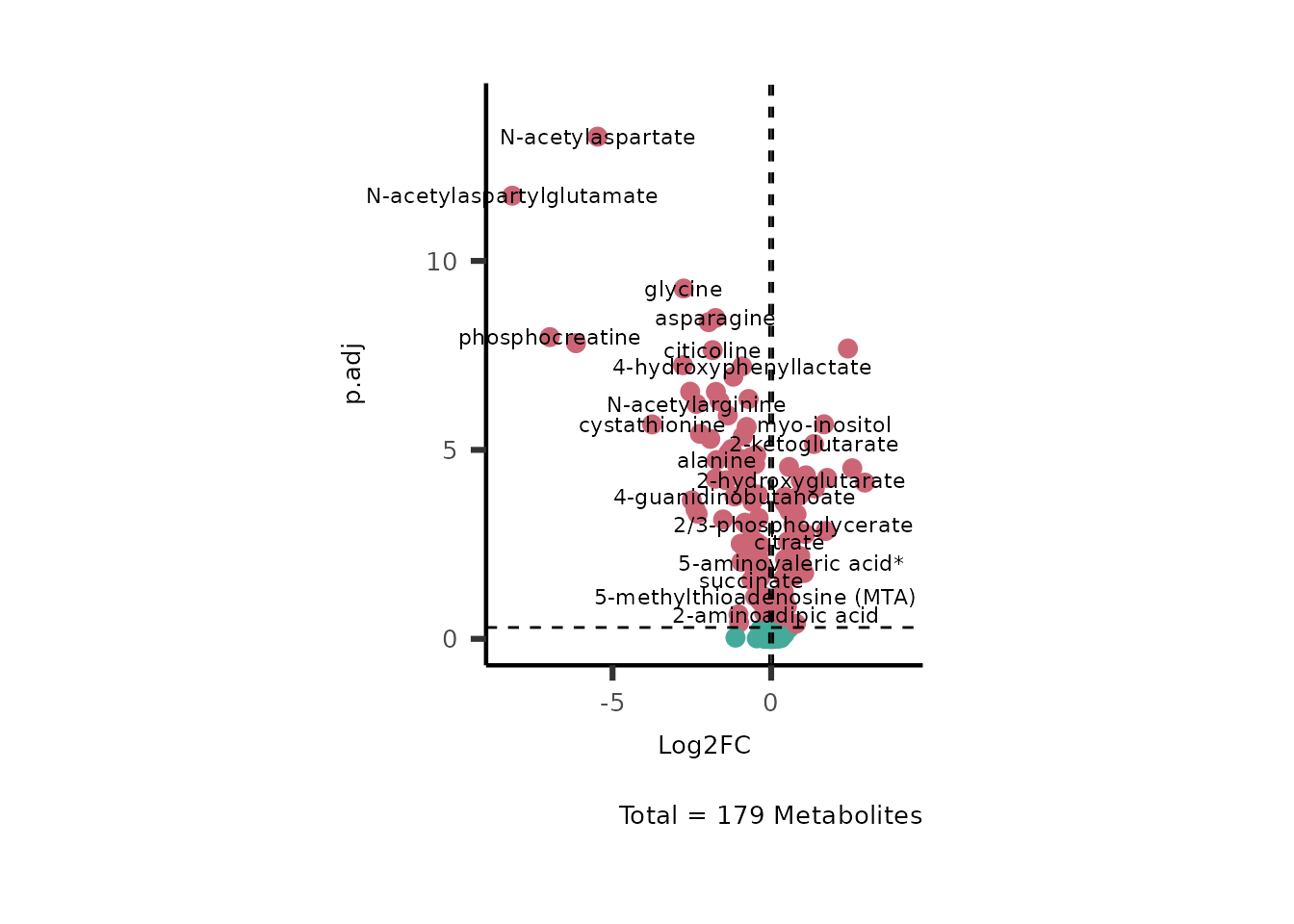
Figure: Standard figure displaying DMA results.
With the parameter SelectLab you can also pass a vector
with Metabolite names that should be labeled:
# Run with default parameter --> only need to provide Input_data and the title we like
MetaProViz::VizVolcano(InputData=DMA_786M1A_vs_HK2%>%tibble::column_to_rownames("Metabolite"),
SelectLab = c("N-acetylaspartylglutamate", "cystathionine", "orotidine"))
Figure: Standard figure displaying DMA results.
Next we may be interested to understand which metabolite clusters based
on our MCA the metabolites of the plot correspond to. In order to do
this we can provide a Plot_SettingsFile with this additional information
and use this information to color code and/or to shape the dots on the
volcano plot. In order to choose the right column we need to provide a
vector Plot_SettingsInfo with this information.
#Now we need to add our Plot_SettingsFile and the Plot_SettingsInfo:
MetaProViz::VizVolcano(PlotSettings="Standard",
SettingsInfo= c(color="RG2_Significant"),
SettingsFile_Metab= MetaData_Metab,
InputData=DMA_786M1A_vs_HK2%>%tibble::column_to_rownames("Metabolite"),
PlotName= "786M1A versus HK2",
Subtitle= "Results of DMA. Colour coded for metabolic clusters" )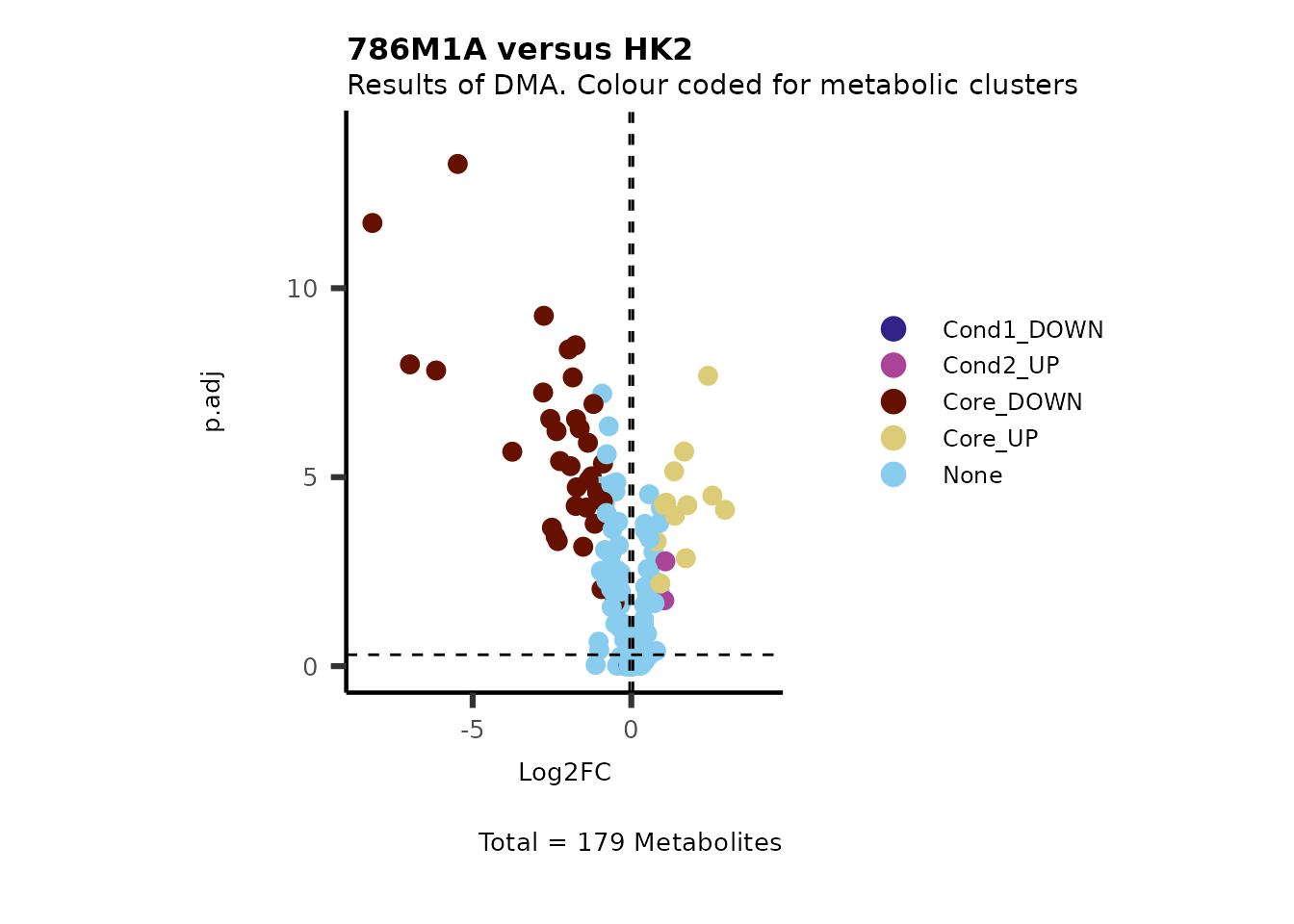
Figure: Standard figure displaying DMA results colour coded/shaped for metabolic clusters from MCA results.
#If we want to use the shape instead of the colour for the cluster info, we can just change our Plot_SettingsInfo
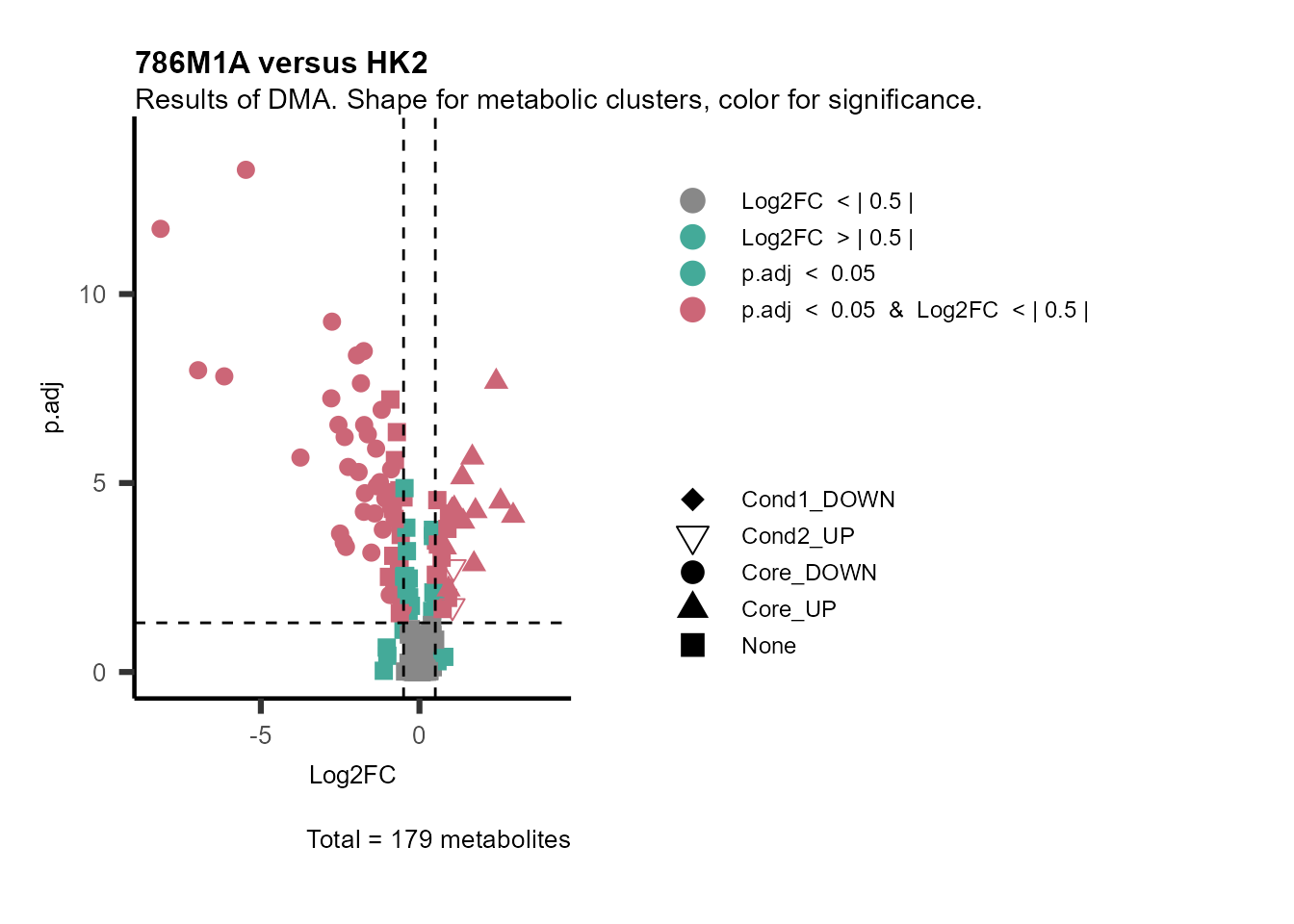
MetaProViz::VizVolcano(PlotSettings="Standard",
SettingsInfo= c(shape="RG2_Significant"),
SettingsFile= MetaData_Metab,
InputData=DMA_786M1A_vs_HK2%>%tibble::column_to_rownames("Metabolite"),
PlotName= "786M1A versus HK2",
Subtitle= "Results of DMA. Shape for metabolic clusters, color for significance." )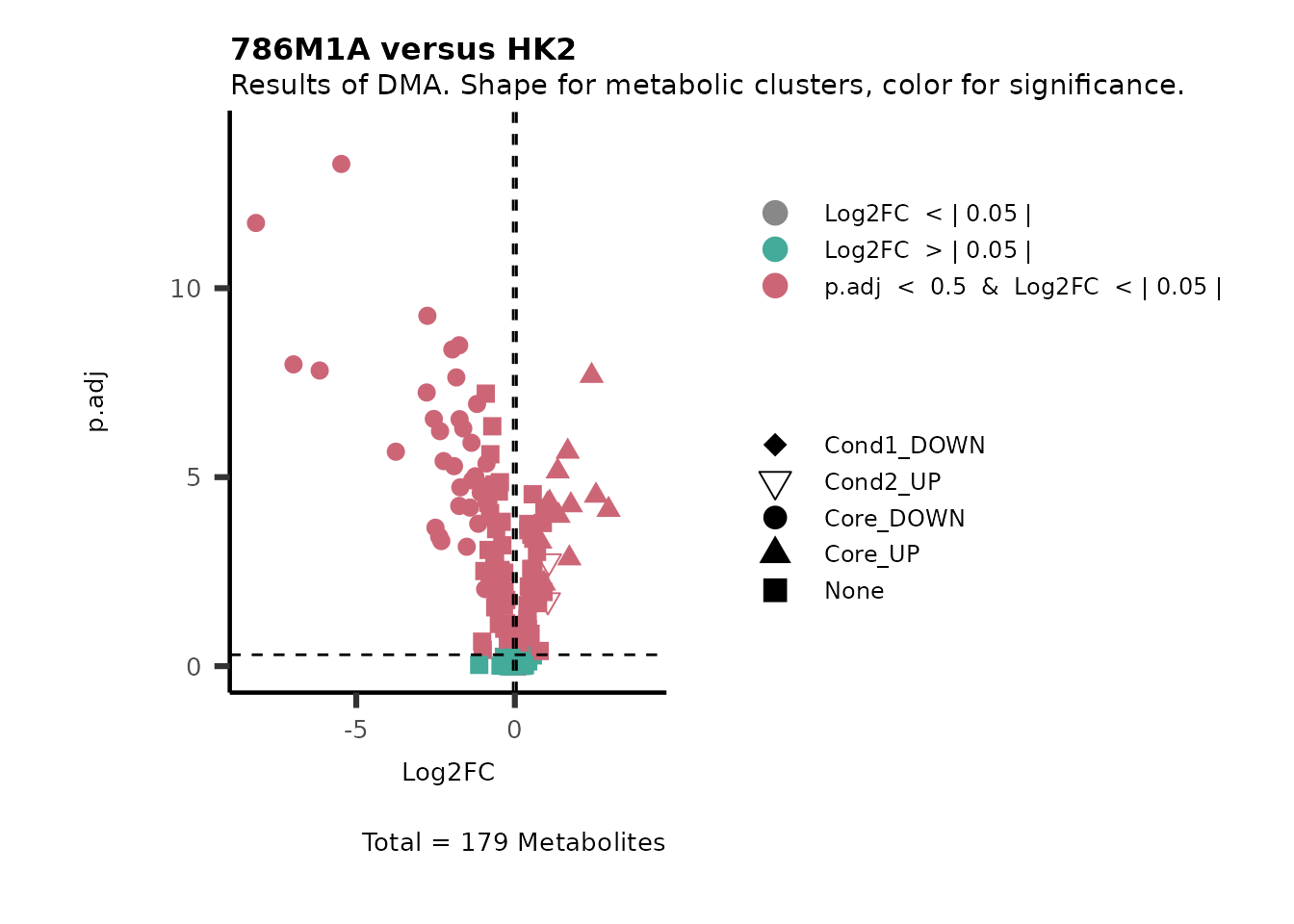
Figure: Standard figure displaying DMA results colour coded/shaped for metabolic clusters from MCA results.
#Of course, we can also adapt both, color and shape for the same parameter:
MetaProViz::VizVolcano(PlotSettings="Standard",
SettingsInfo= c(shape="RG2_Significant", color="RG2_Significant"),
SettingsFile= MetaData_Metab,
InputData=DMA_786M1A_vs_HK2%>%tibble::column_to_rownames("Metabolite"),
PlotName= "786M1A versus HK2",
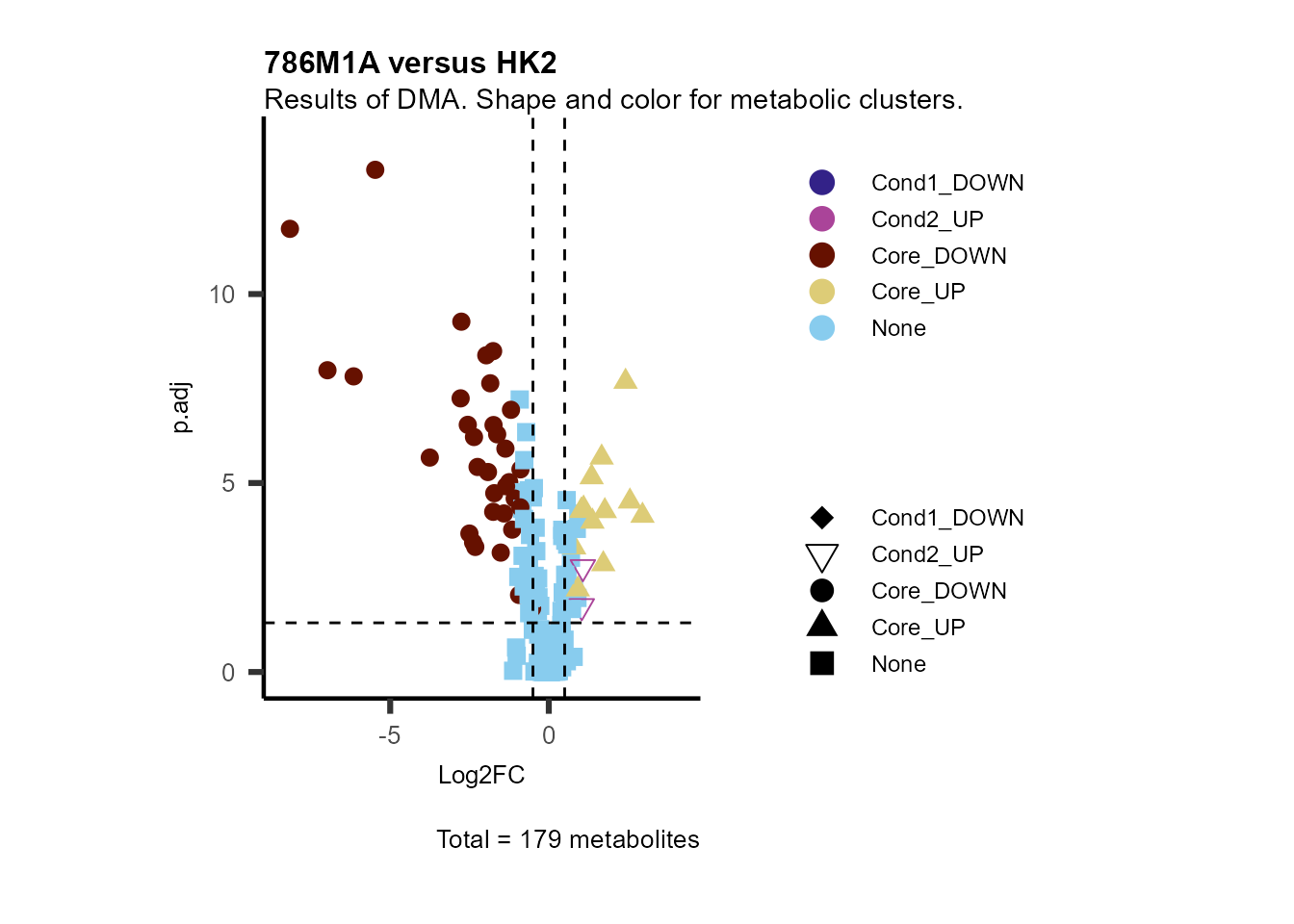
Subtitle= "Results of DMA. Shape and color for metabolic clusters." )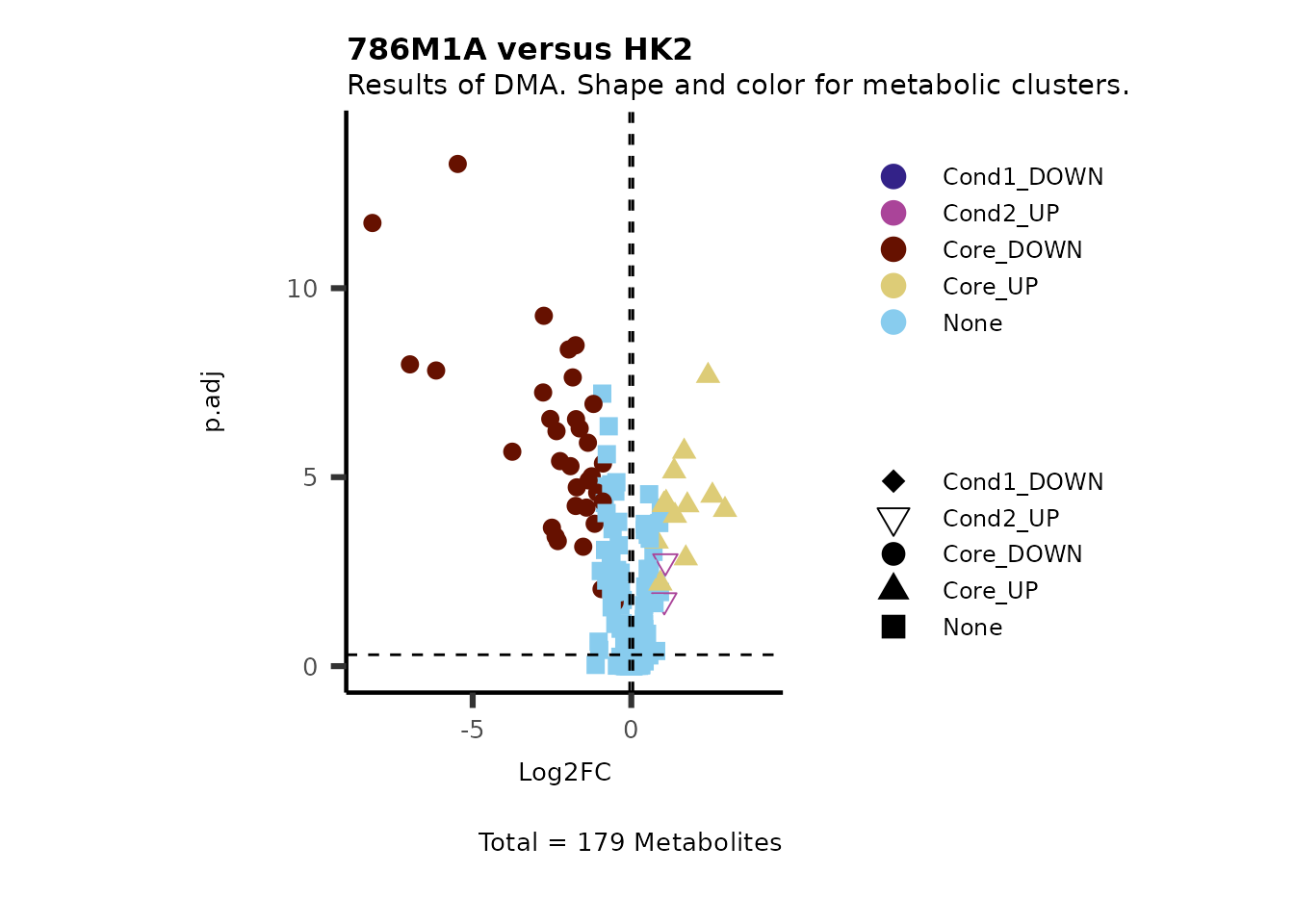
Figure: Standard figure displaying DMA results colour coded/shaped for metabolic clusters from MCA results.
Given that we also know, which metabolic pathway the metabolites
correspond to, we can add this information into the plot. This is also a
good example to showcase the flexibility of the visualisation function:
Either you use the parameter
Plot_SettingsFile= MetaData_Metab as above, but as we have
the column “Pathway” also in our Input_data you can also pass
Plot_SettingsFile= DMA_786-M1A_vs_HK2 or simply use the
default Plot_SettingsFile=NULL, in which case the
Plot_SettingsInfo information (here color)
will be used from Input_data.
#Now we can use color for the pathways and shape for the metabolite clusters:
MetaProViz::VizVolcano(PlotSettings="Standard",
SettingsInfo= c(color="Pathway"),
SettingsFile_Metab= MappingInfo,
InputData=DMA_786M1A_vs_HK2%>%tibble::column_to_rownames("Metabolite"),
PlotName= "786M1A versus HK2 Results of DMA. Colour for metabolic pathways.",
Subtitle= "Results of DMA. Colour for metabolic pathways." )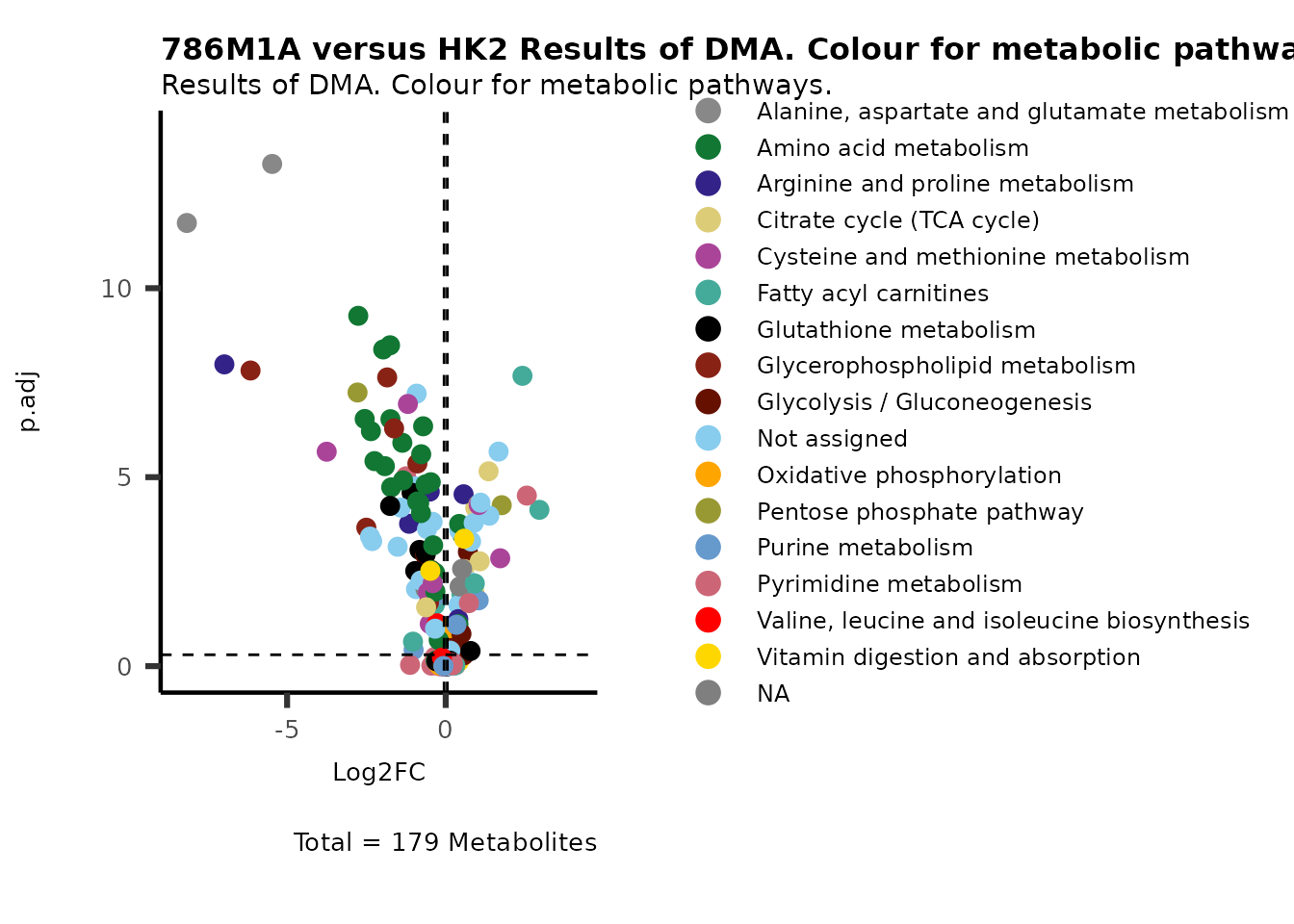
Figure: Standard figure displaying DMA results colour coded for metabolic pathways and shaped for metabolic clusters from MCA results.
We immediately see that there are many pathways displayed on the plot,
which can make it difficult to interpret. Hence, we will change our plot
settings in order to get individual plots for each of the pathways:
#Now we can generate a plot for each pathway and color for the metabolite clusters:
MetaProViz::VizVolcano(PlotSettings="Standard",
SettingsInfo= c(color="RG2_Significant", individual="Pathway"),
SettingsFile_Metab= MetaData_Metab,
InputData=DMA_786M1A_vs_HK2%>%tibble::column_to_rownames("Metabolite"),
PlotName= "786M1A versus HK2",
Subtitle= "Results of DMA. Colour for metabolic pathways." )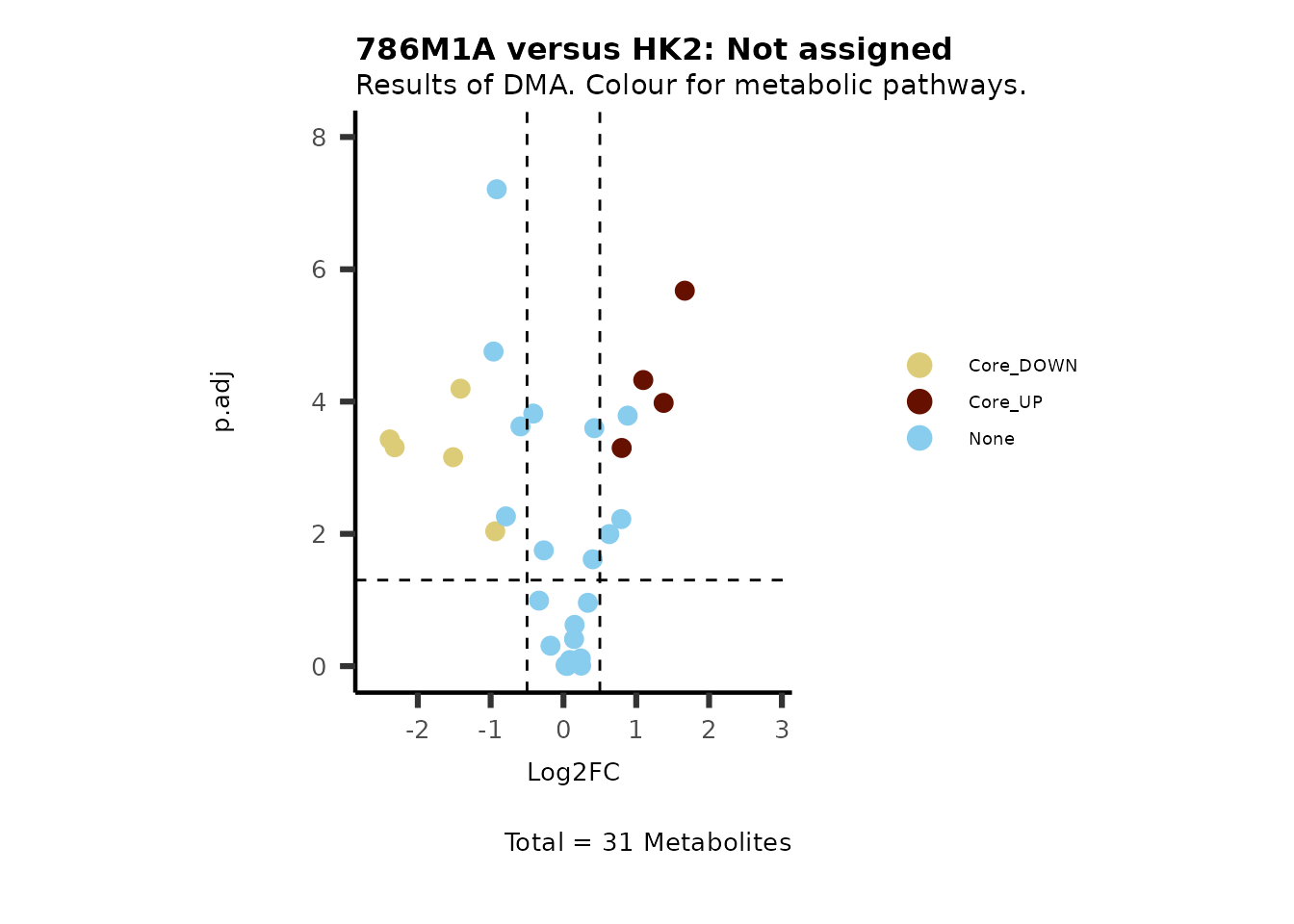
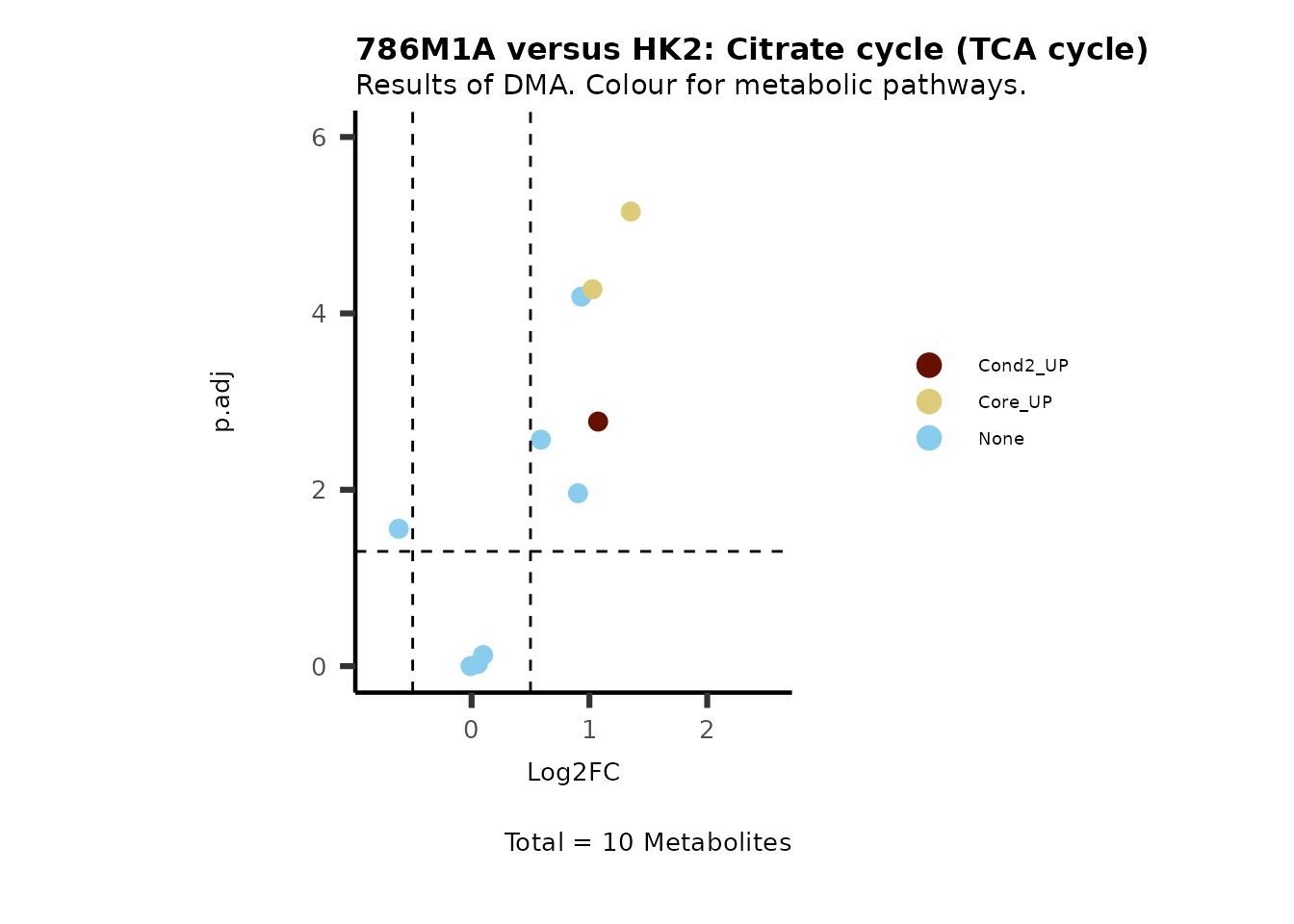

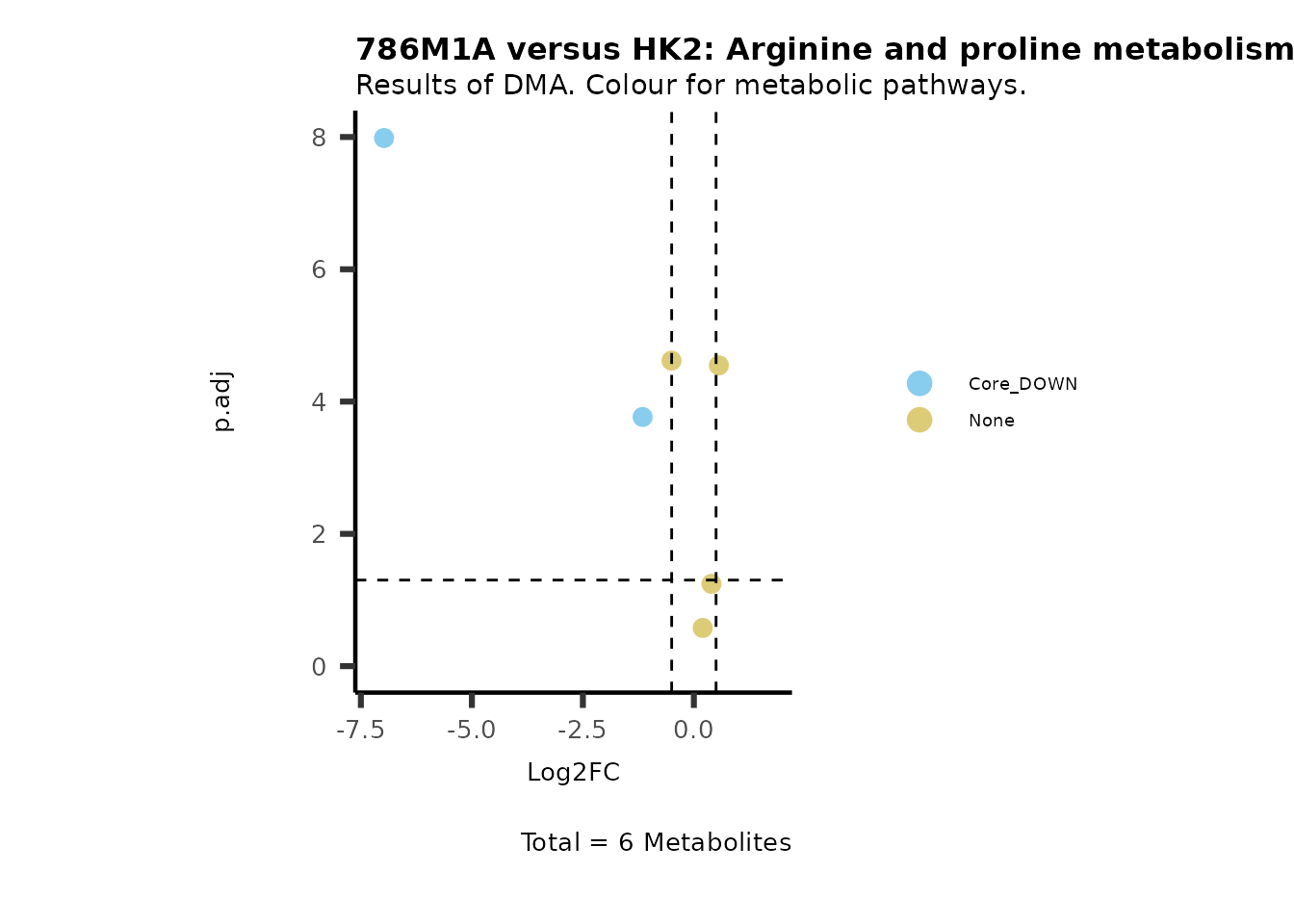
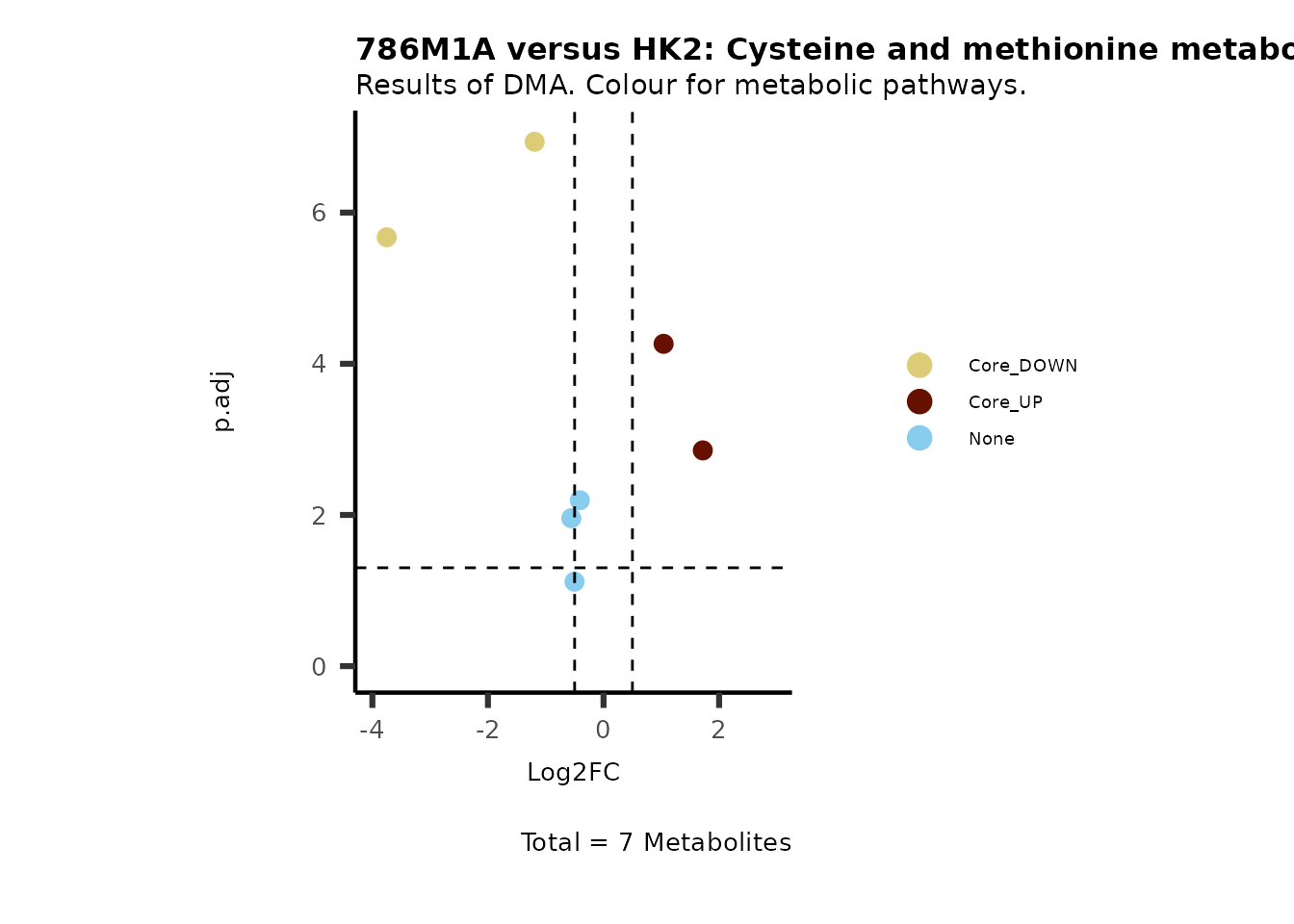

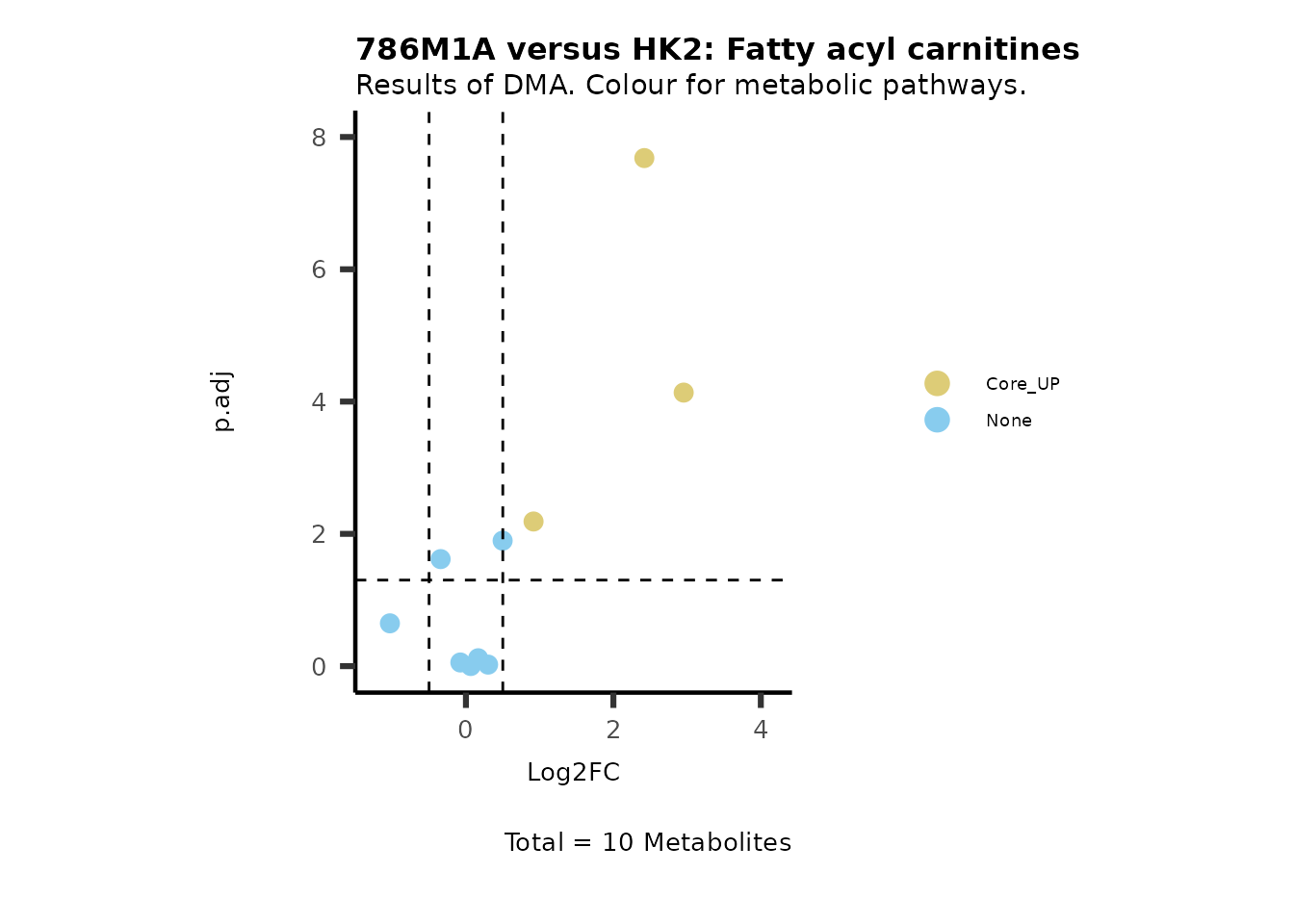
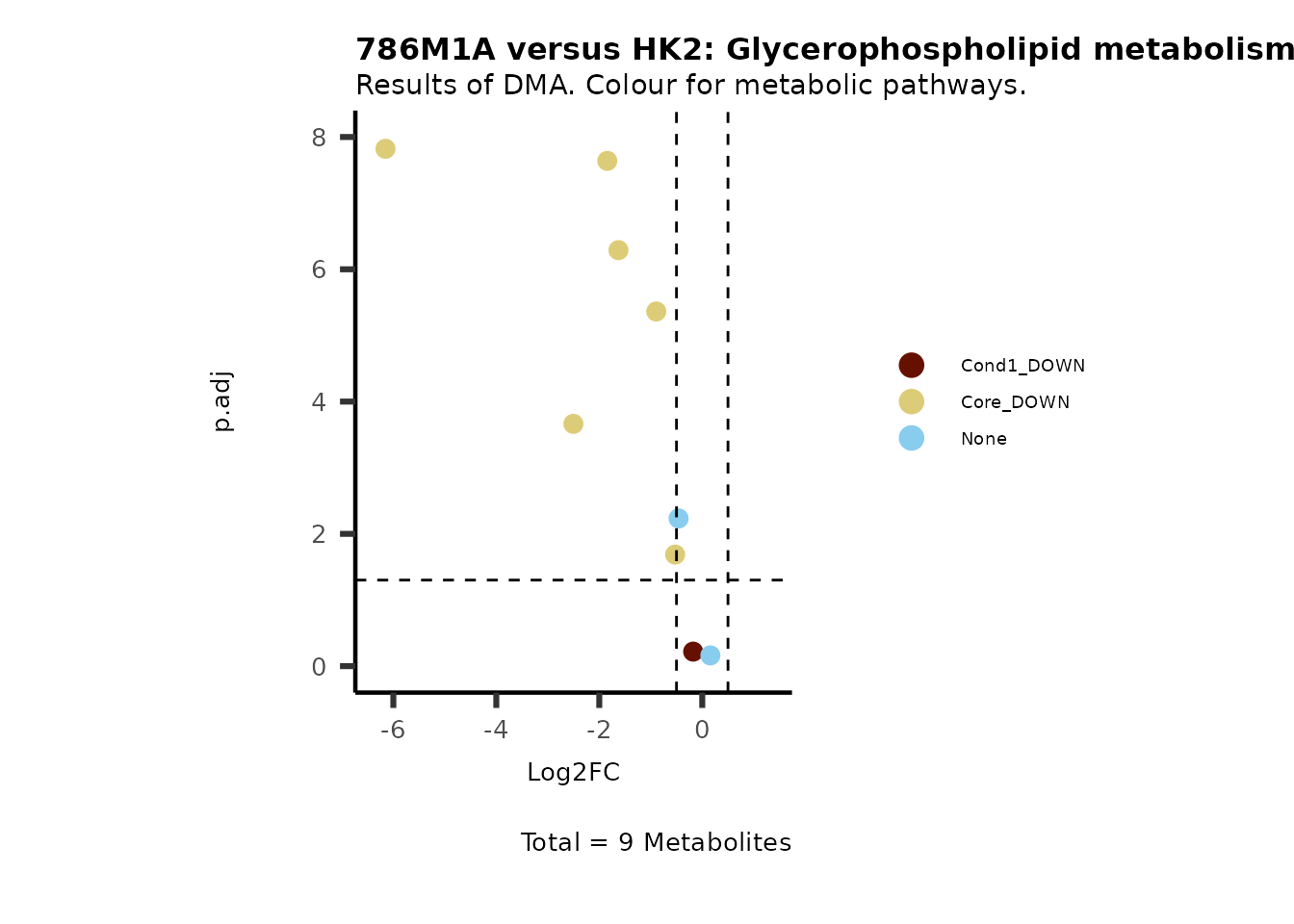
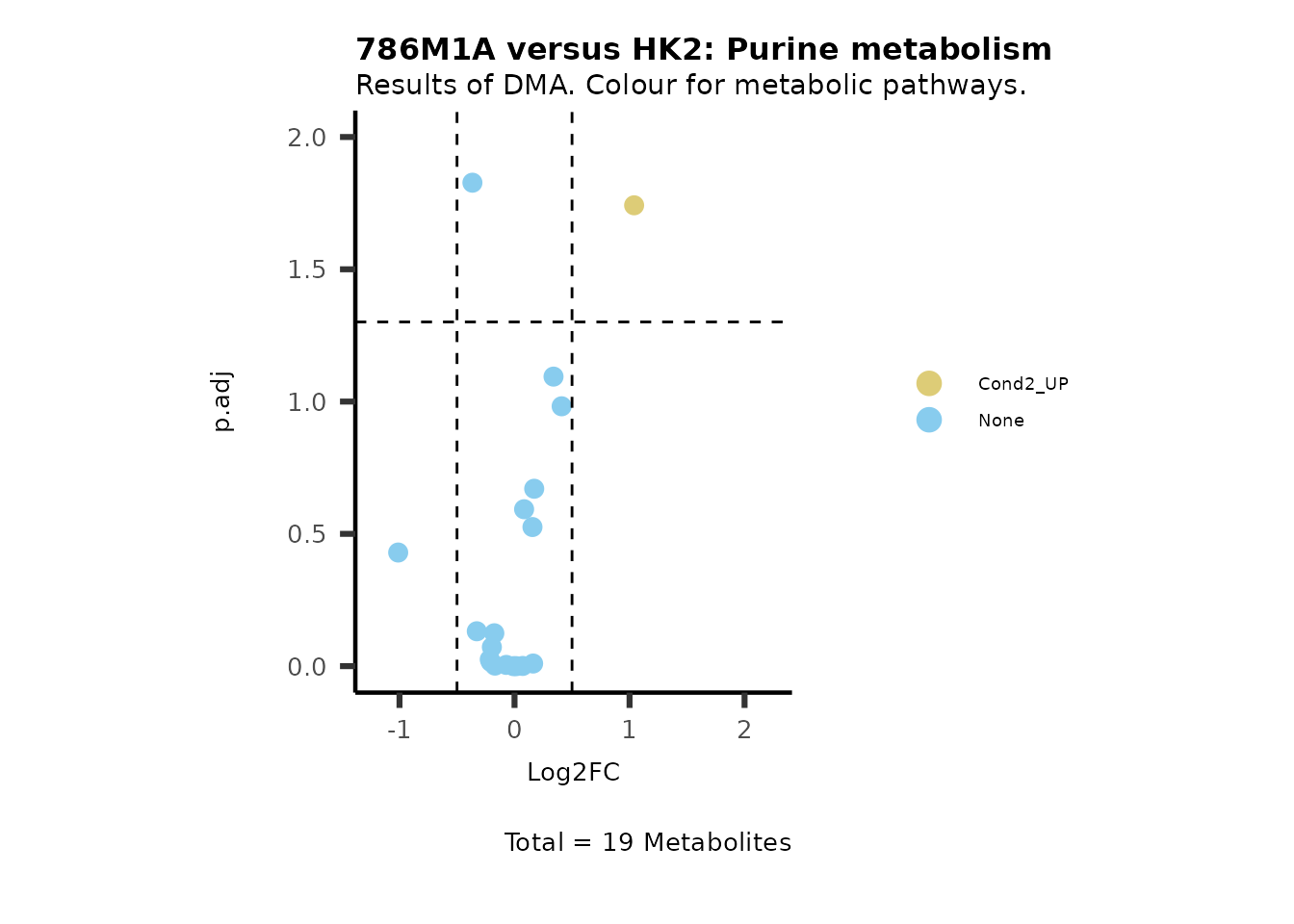

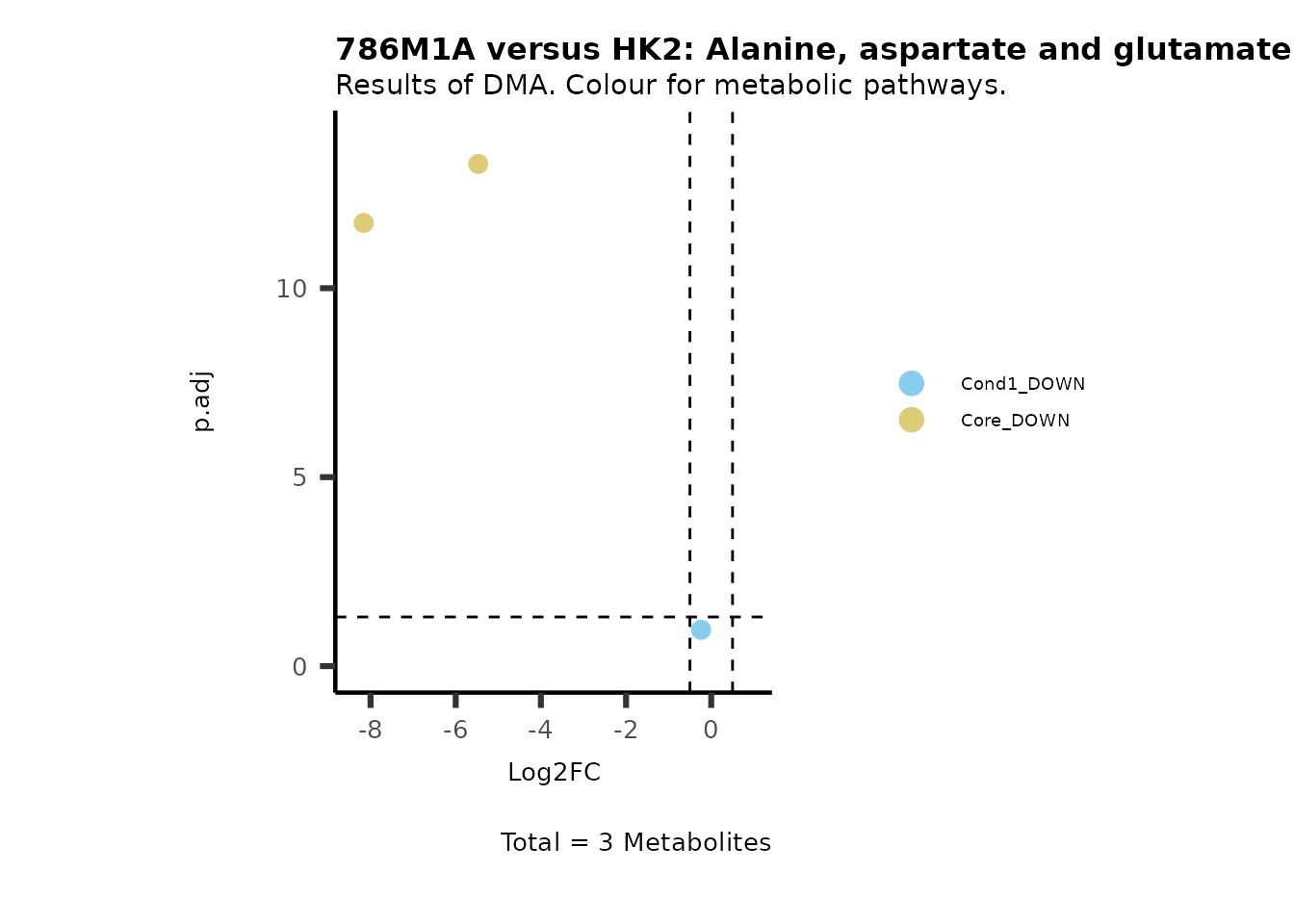
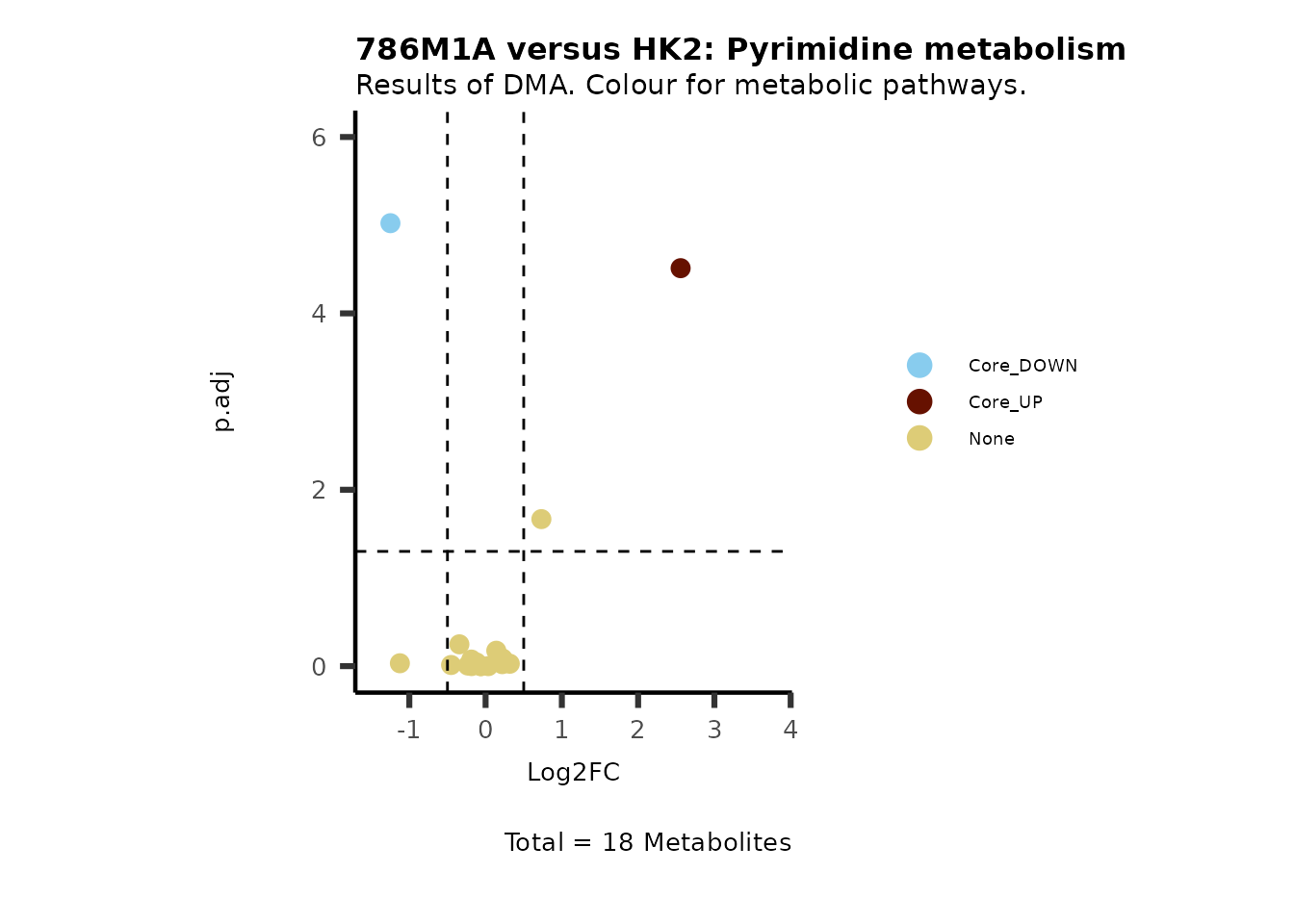

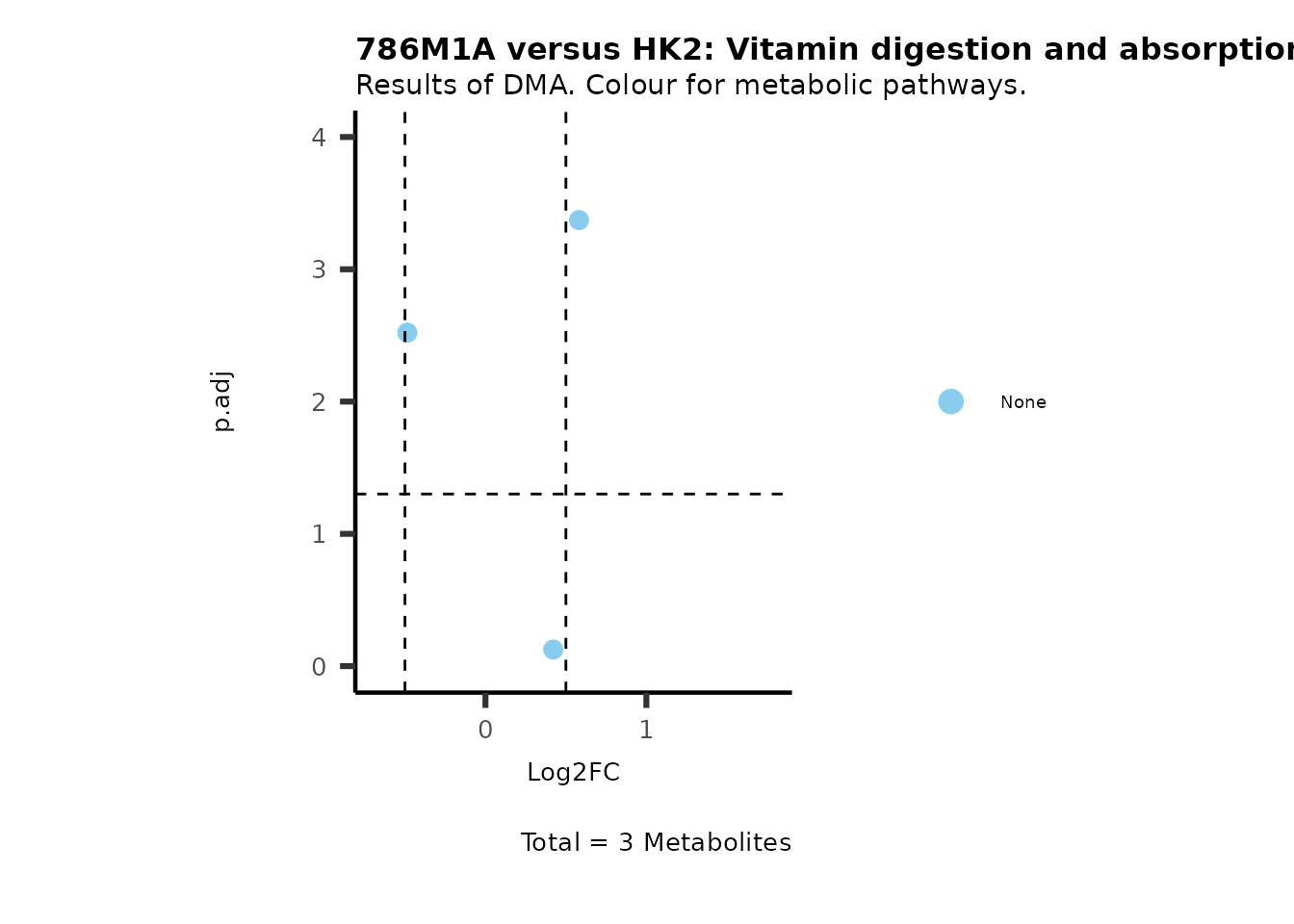
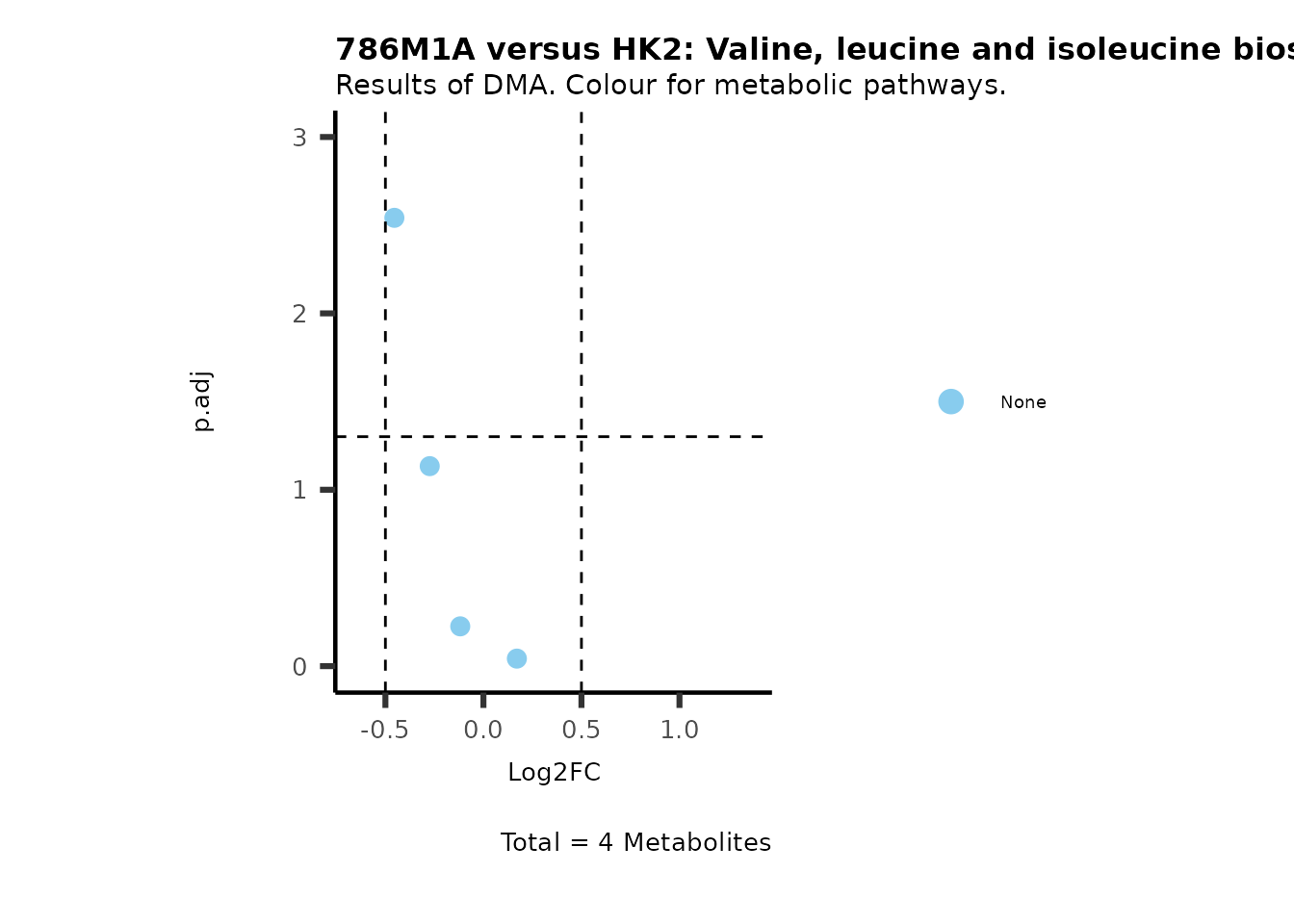
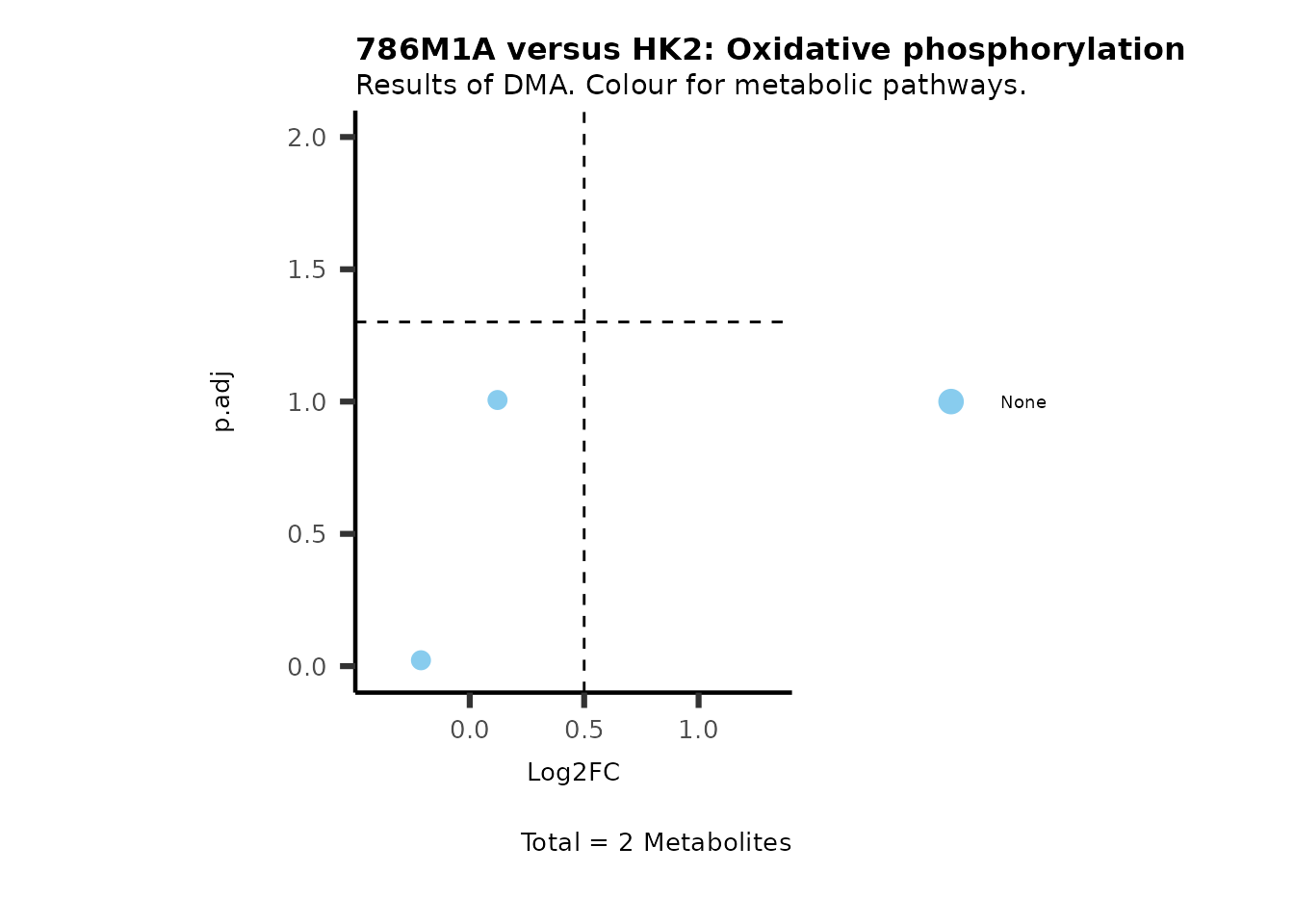
Comparison
MetaProViz::VizVolcano(PlotSettings="Compare",
InputData=DMA_786M1A_vs_HK2%>%tibble::column_to_rownames("Metabolite"),
InputData2= DMA_Annova[["DMA"]][["786-O_vs_HK2"]]%>%tibble::column_to_rownames("Metabolite"),
ComparisonName= c(InputData="786M1A_vs_HK", InputData2= "786-O_vs_HK2"),
PlotName= "786M1A vs HK2 compared to 7860 vs HK2",
Subtitle= "Results of DMA" )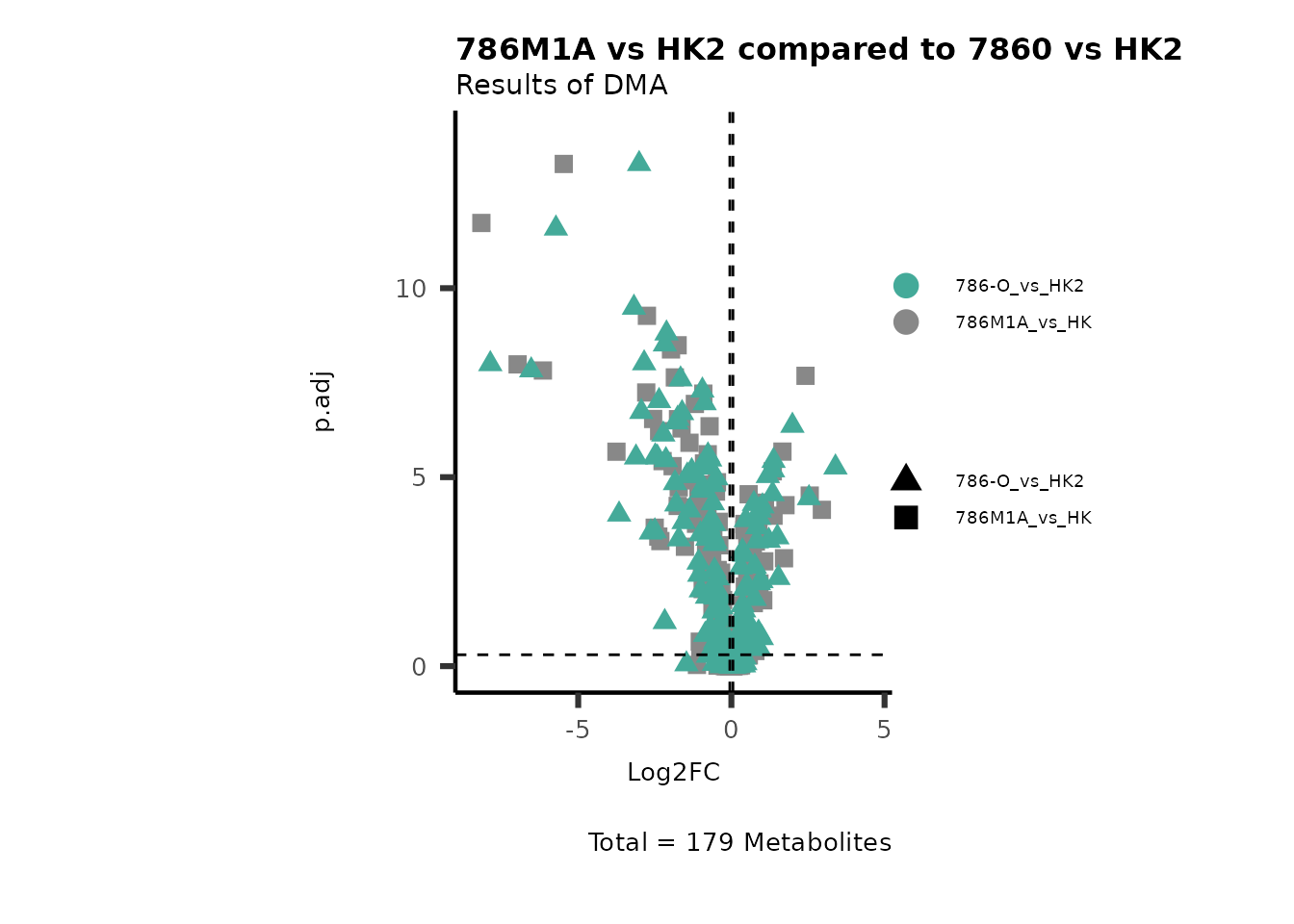
Figure: Comparison.
Now we do individual plots again:
MetaProViz::VizVolcano(PlotSettings="Compare",
SettingsInfo= c(individual="Pathway"),
SettingsFile_Metab= MappingInfo,
InputData=DMA_786M1A_vs_HK2%>%tibble::column_to_rownames("Metabolite"),
InputData2= DMA_Annova[["DMA"]][["786-O_vs_HK2"]]%>%tibble::column_to_rownames("Metabolite"),
PlotName= "786M1A vs HK2 compared to 7860 vs HK2",
Subtitle= "Results of DMA" )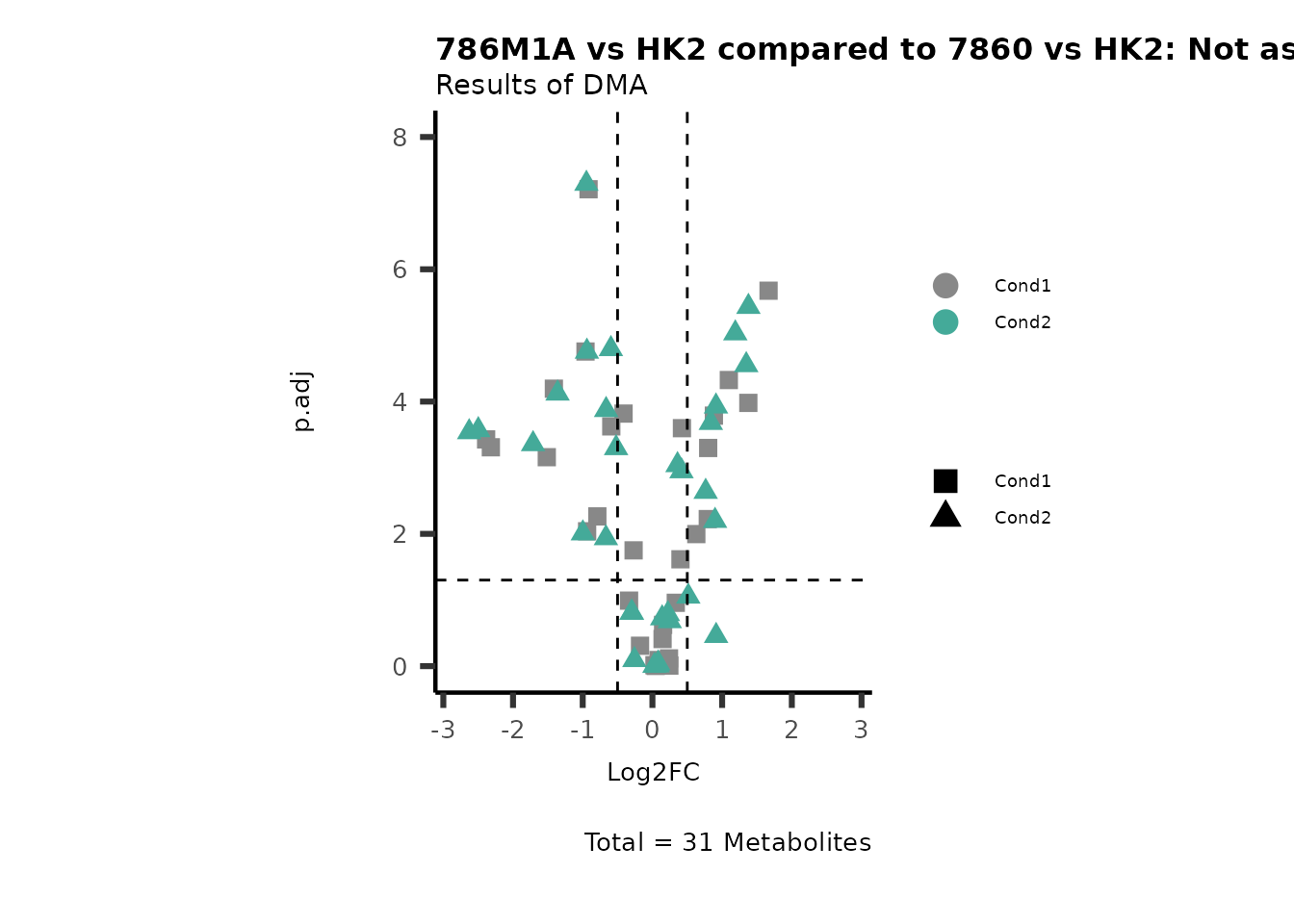
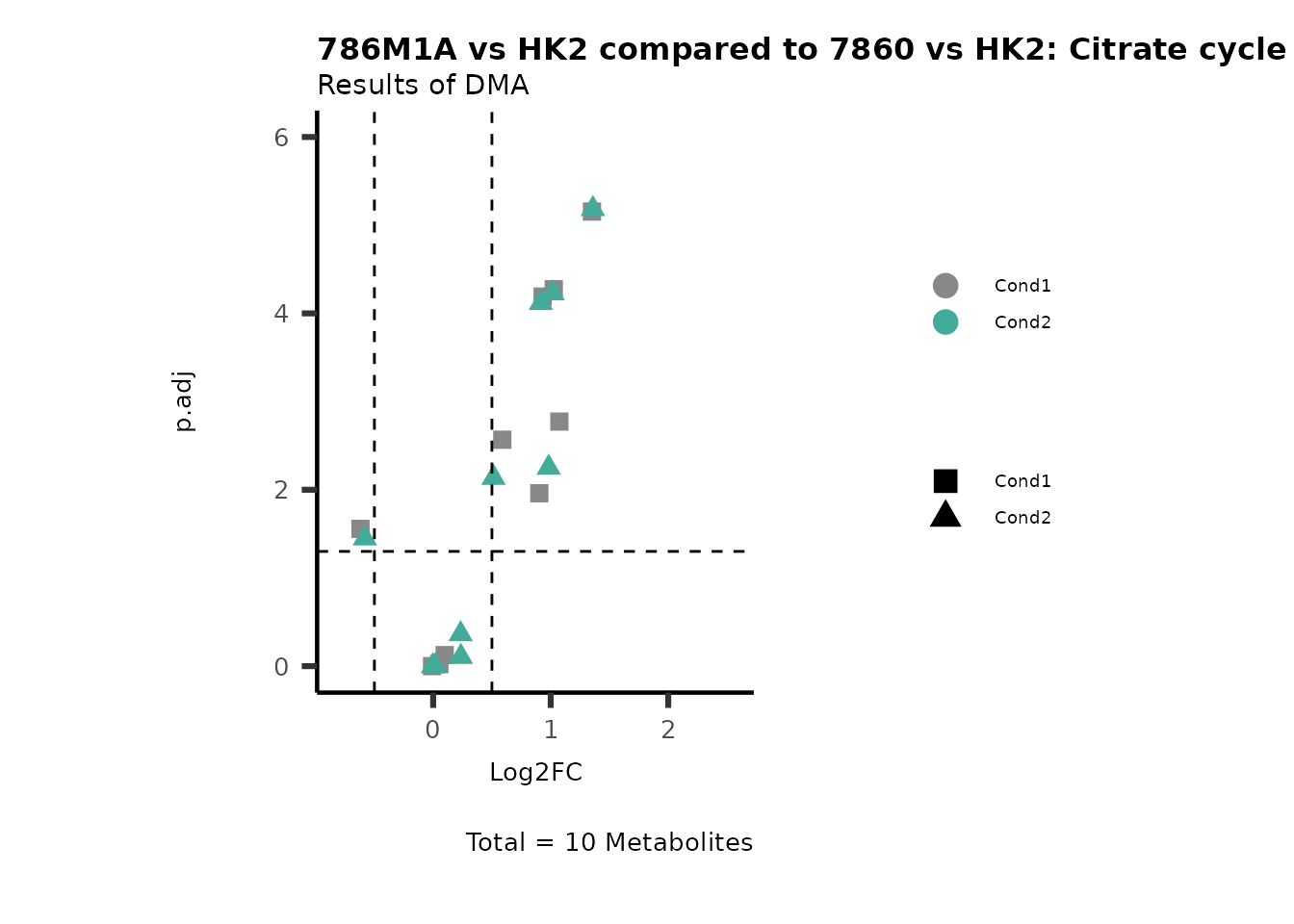
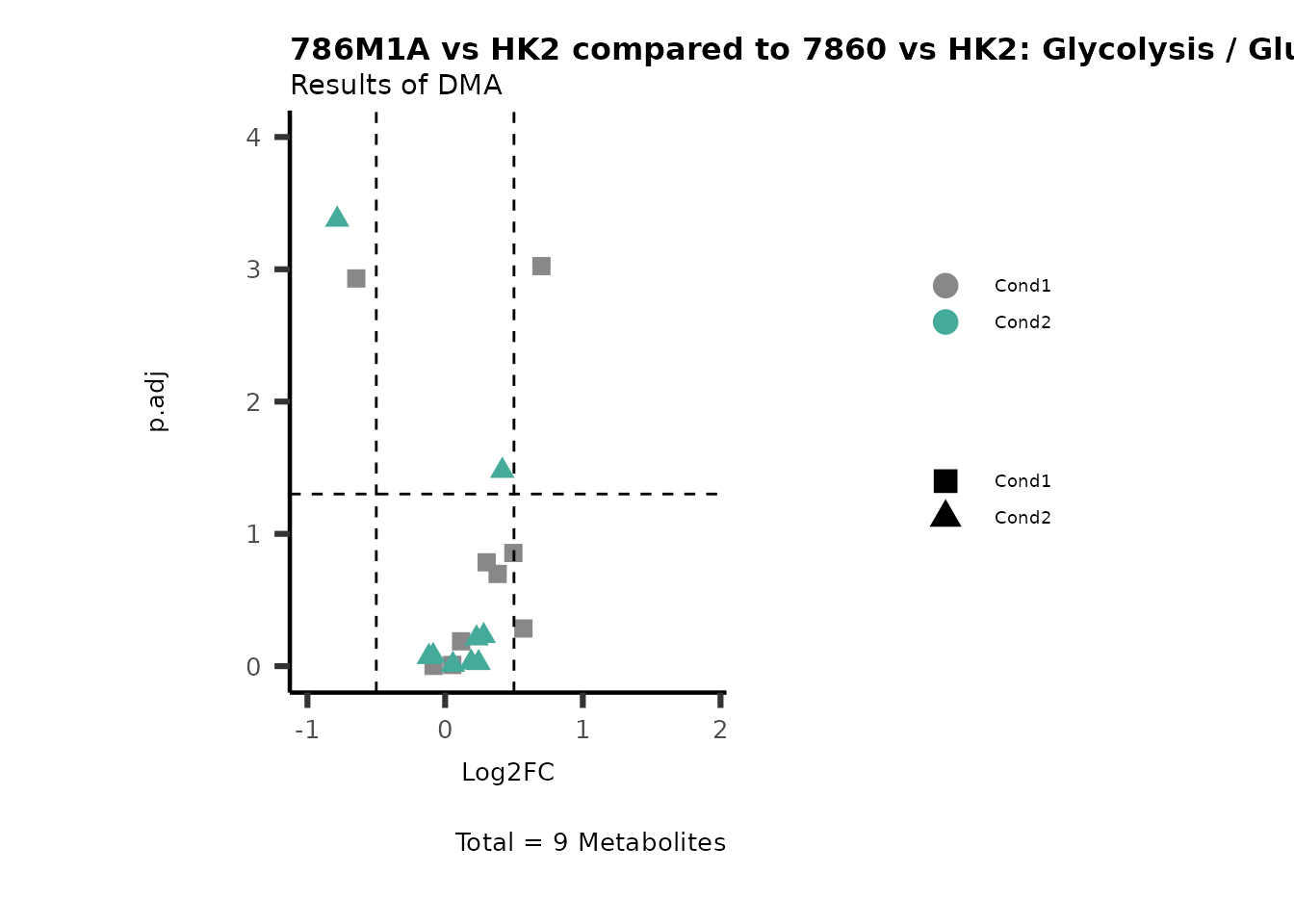
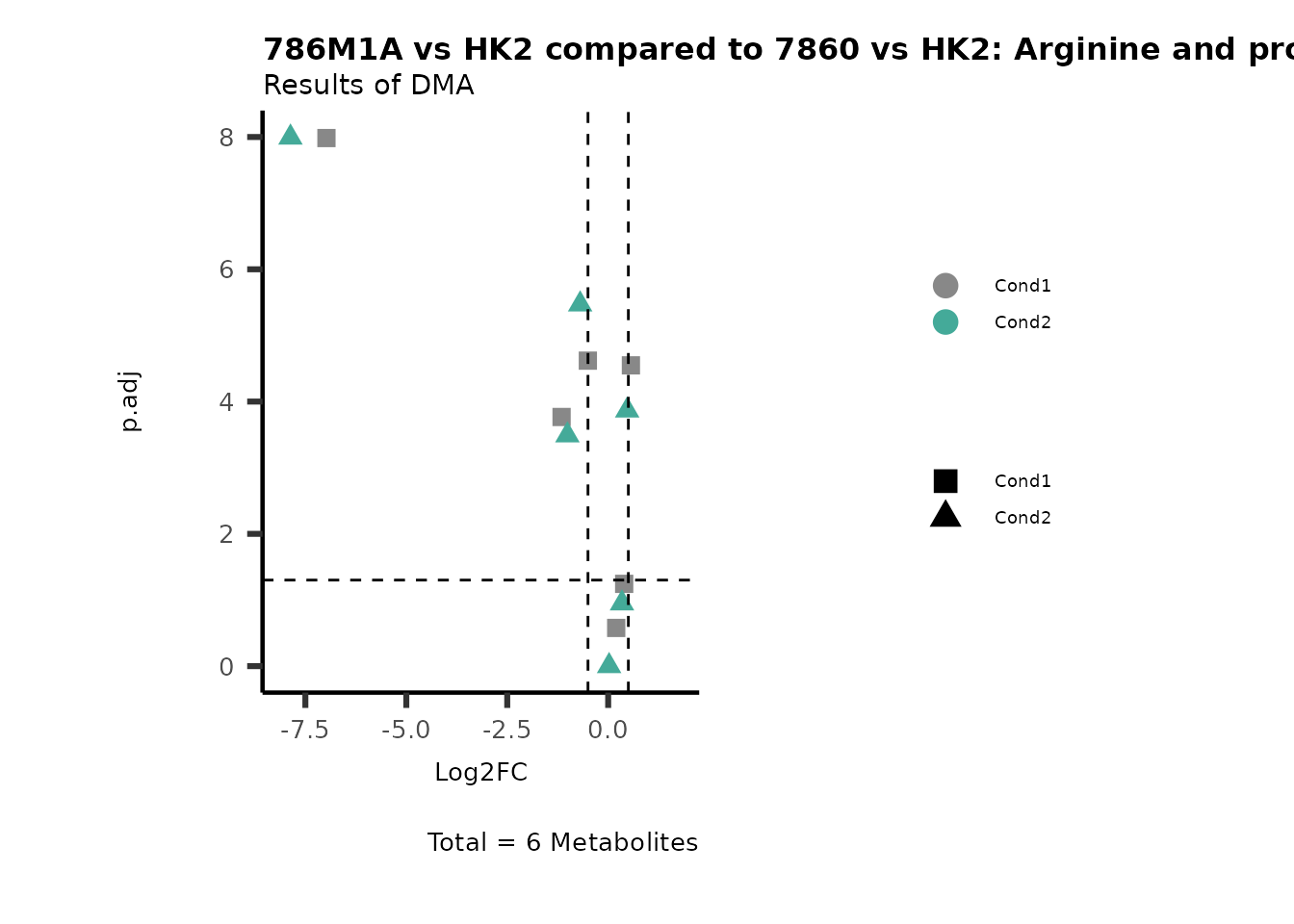
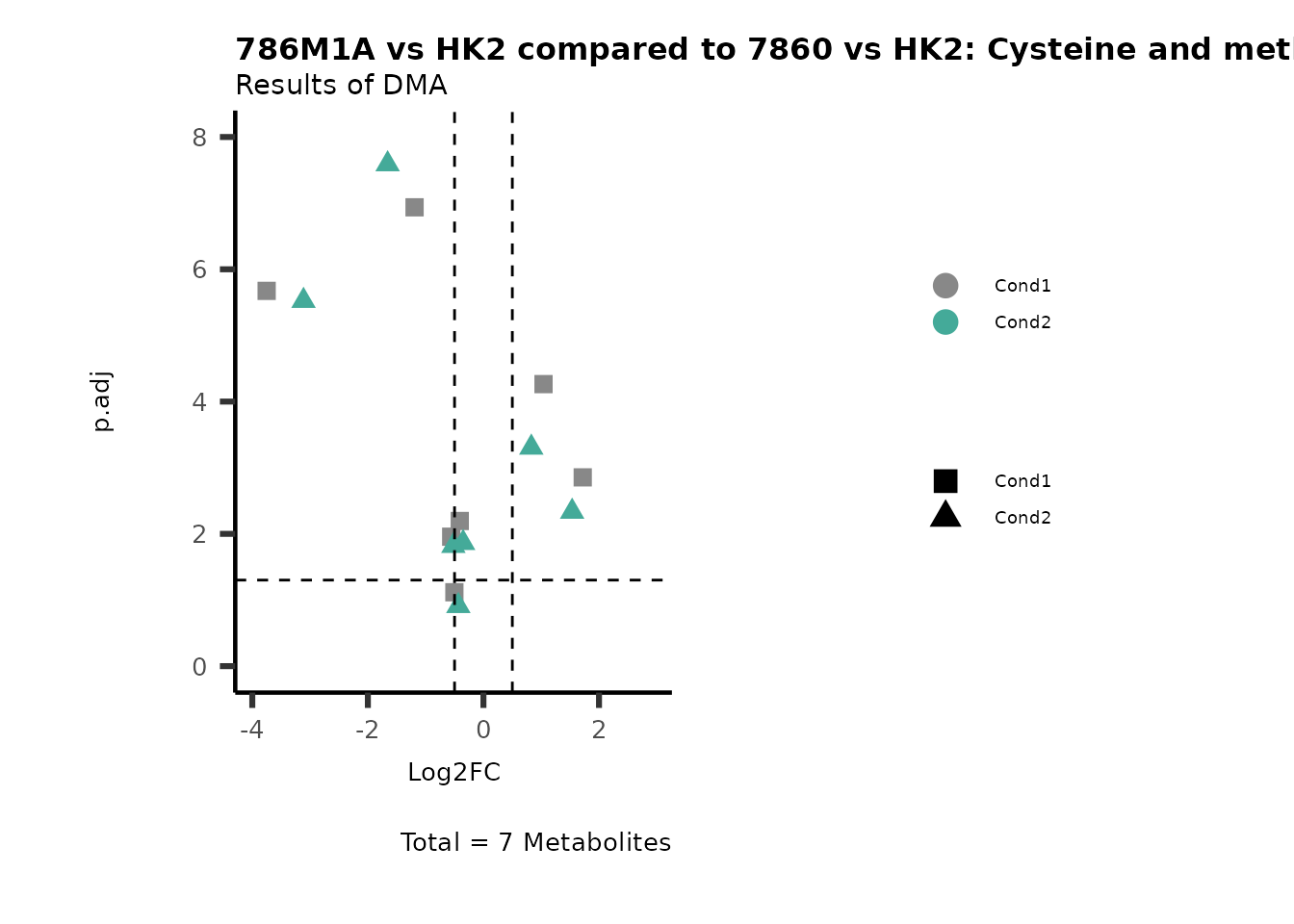
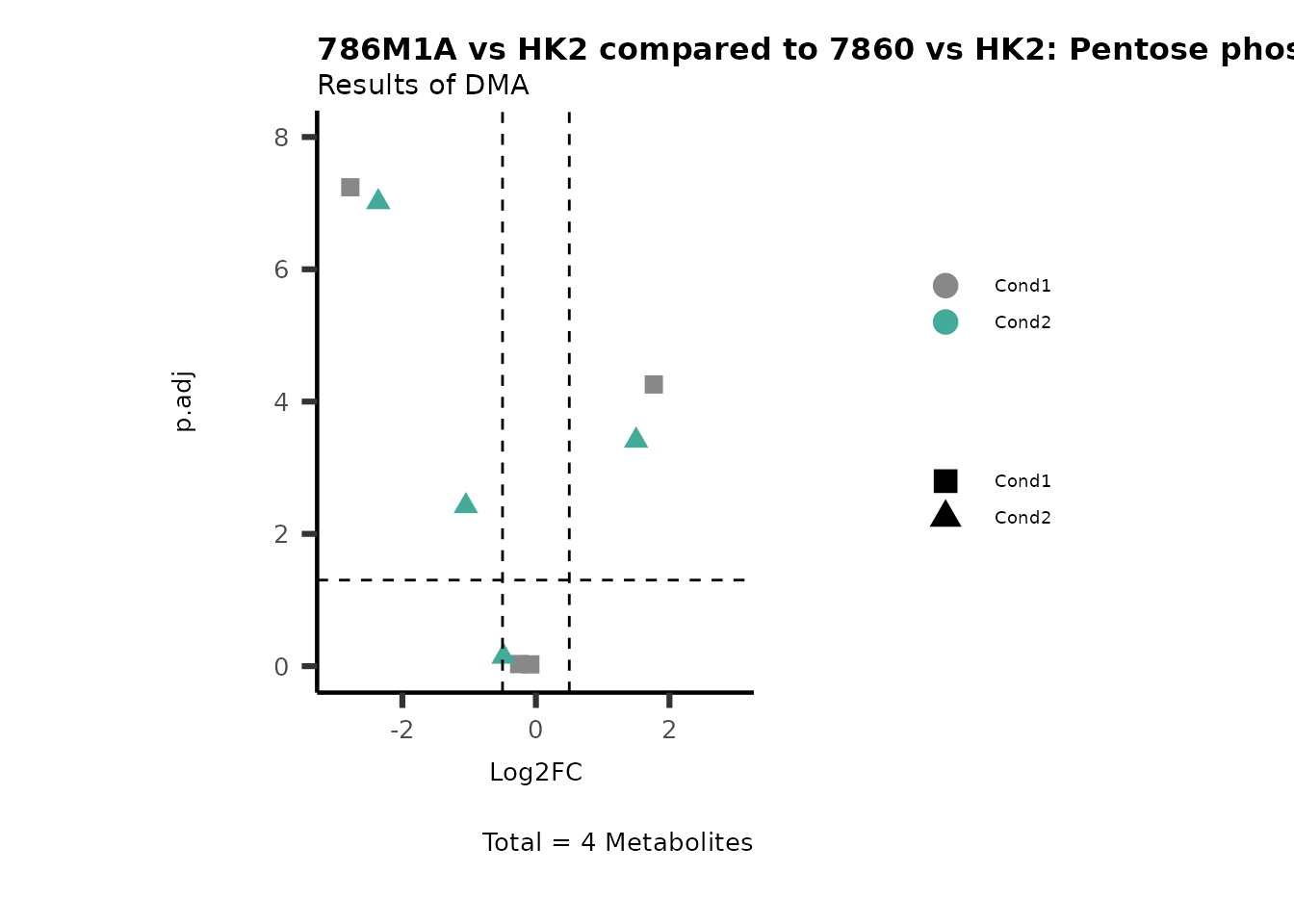
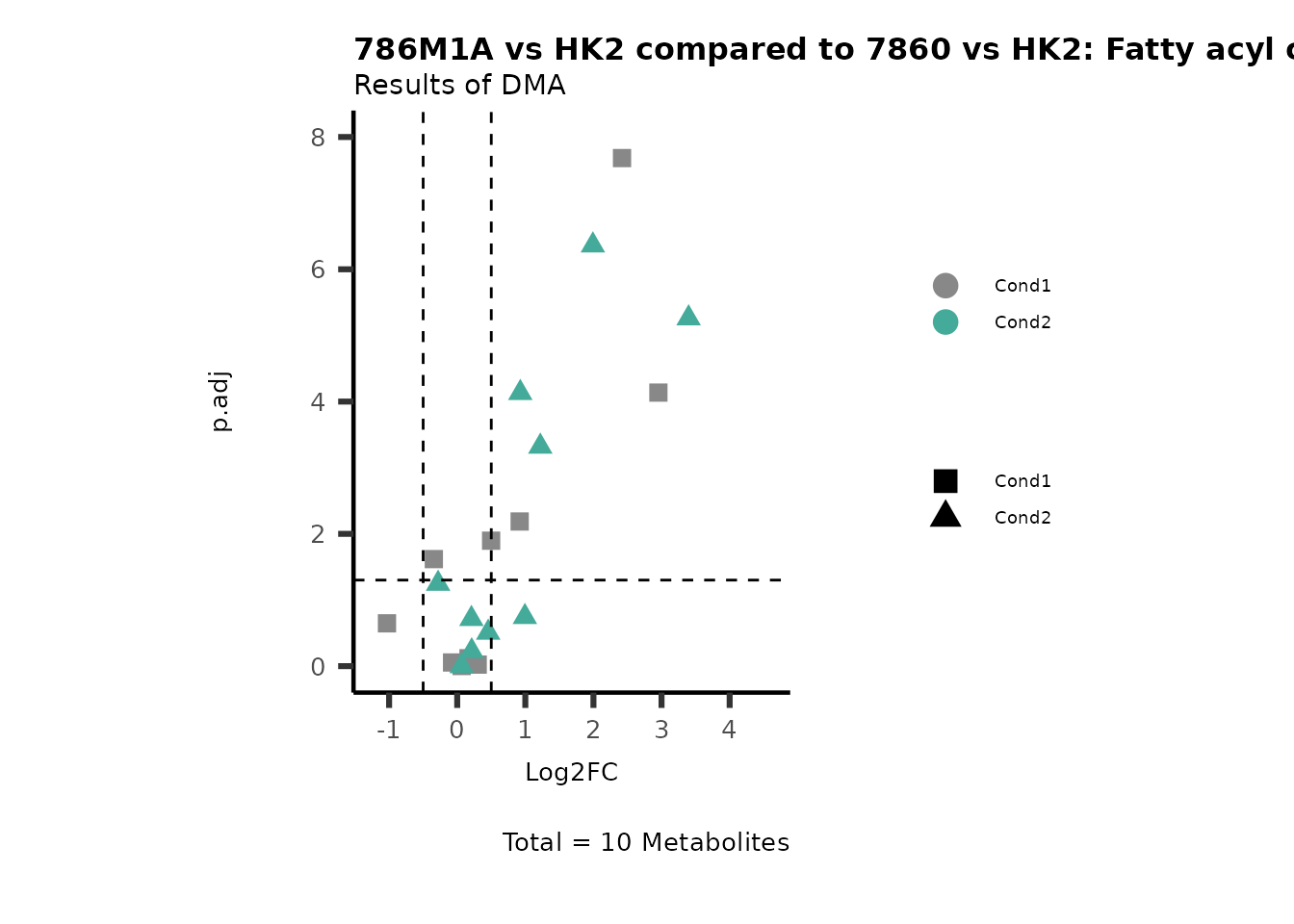

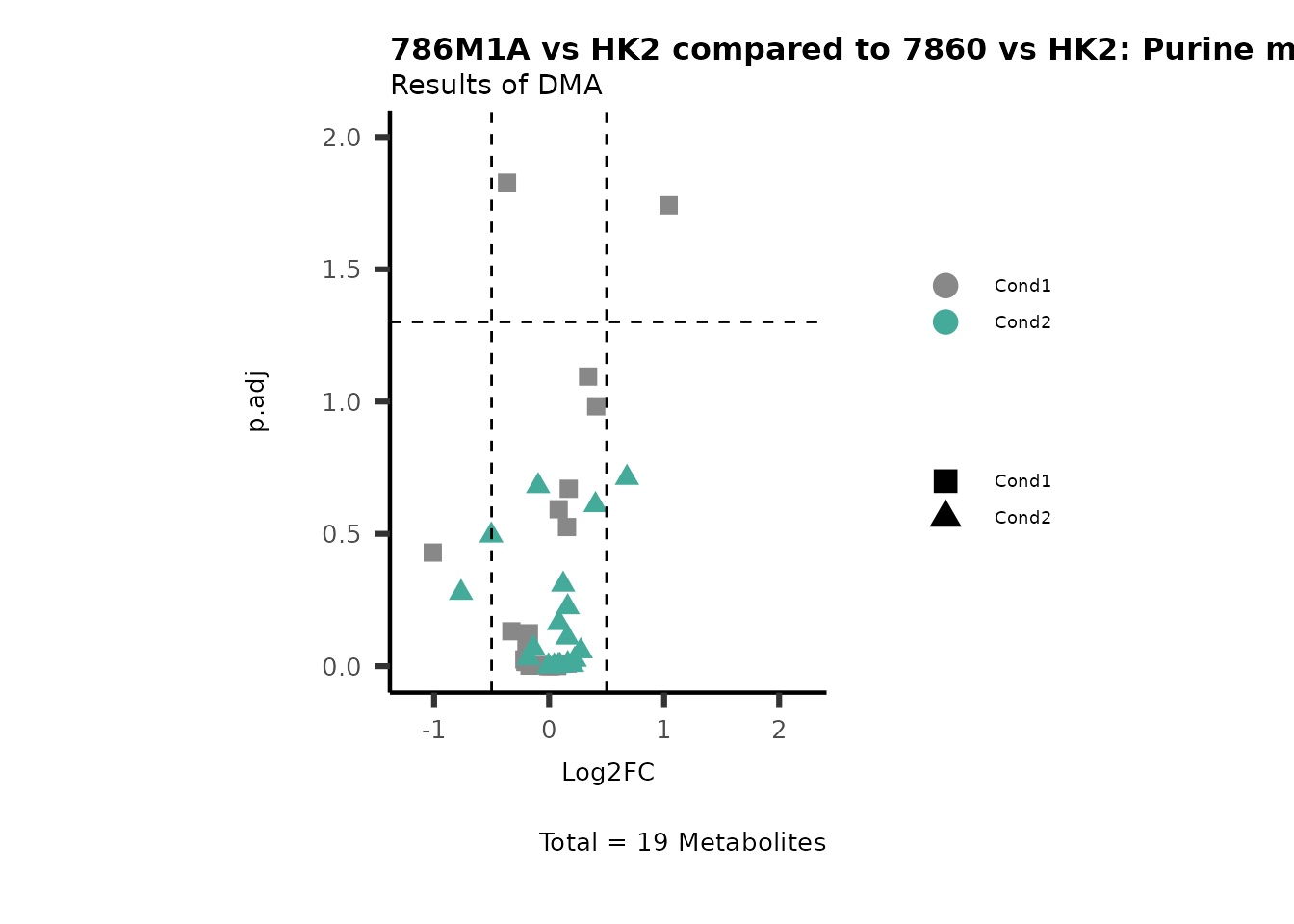
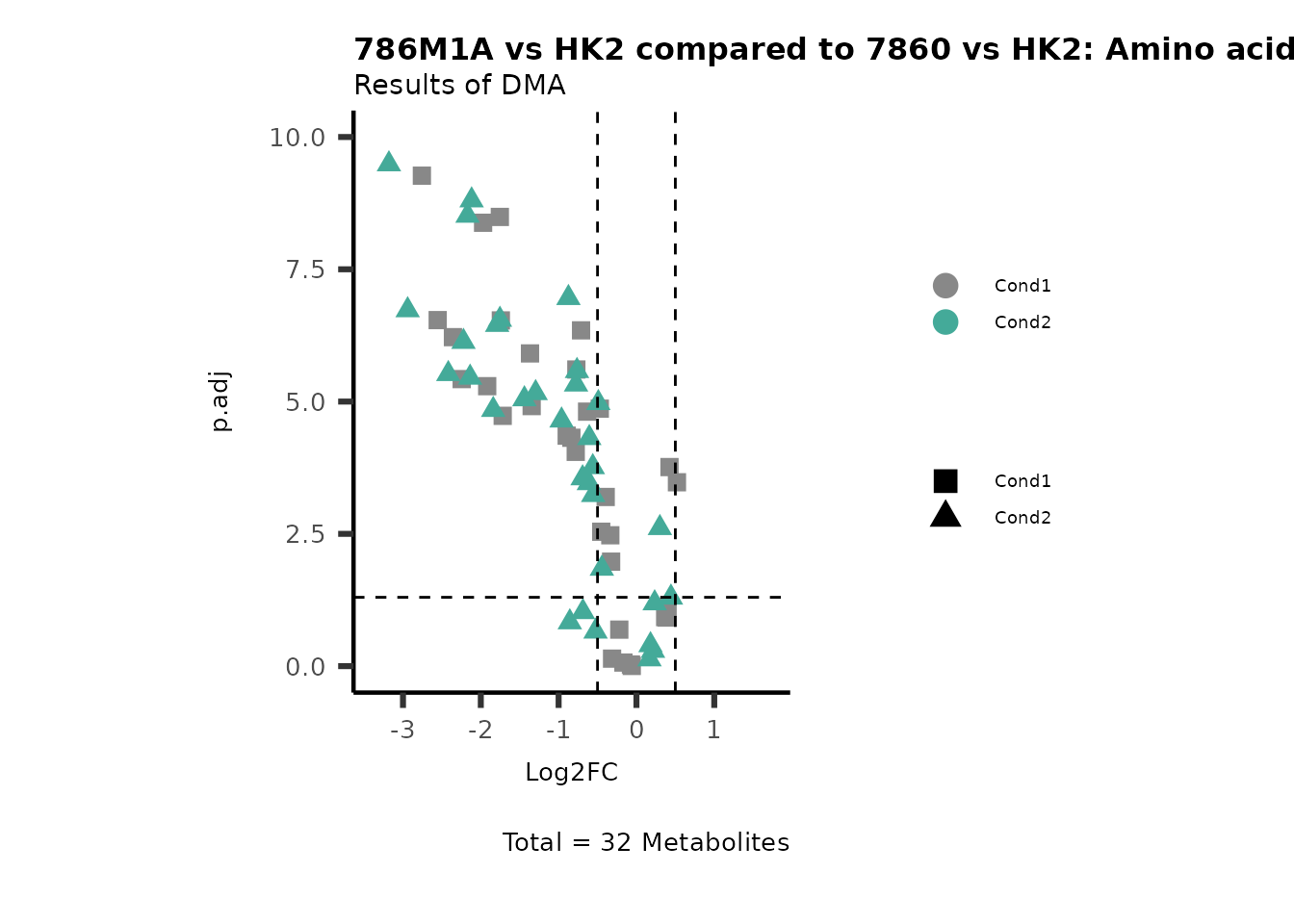
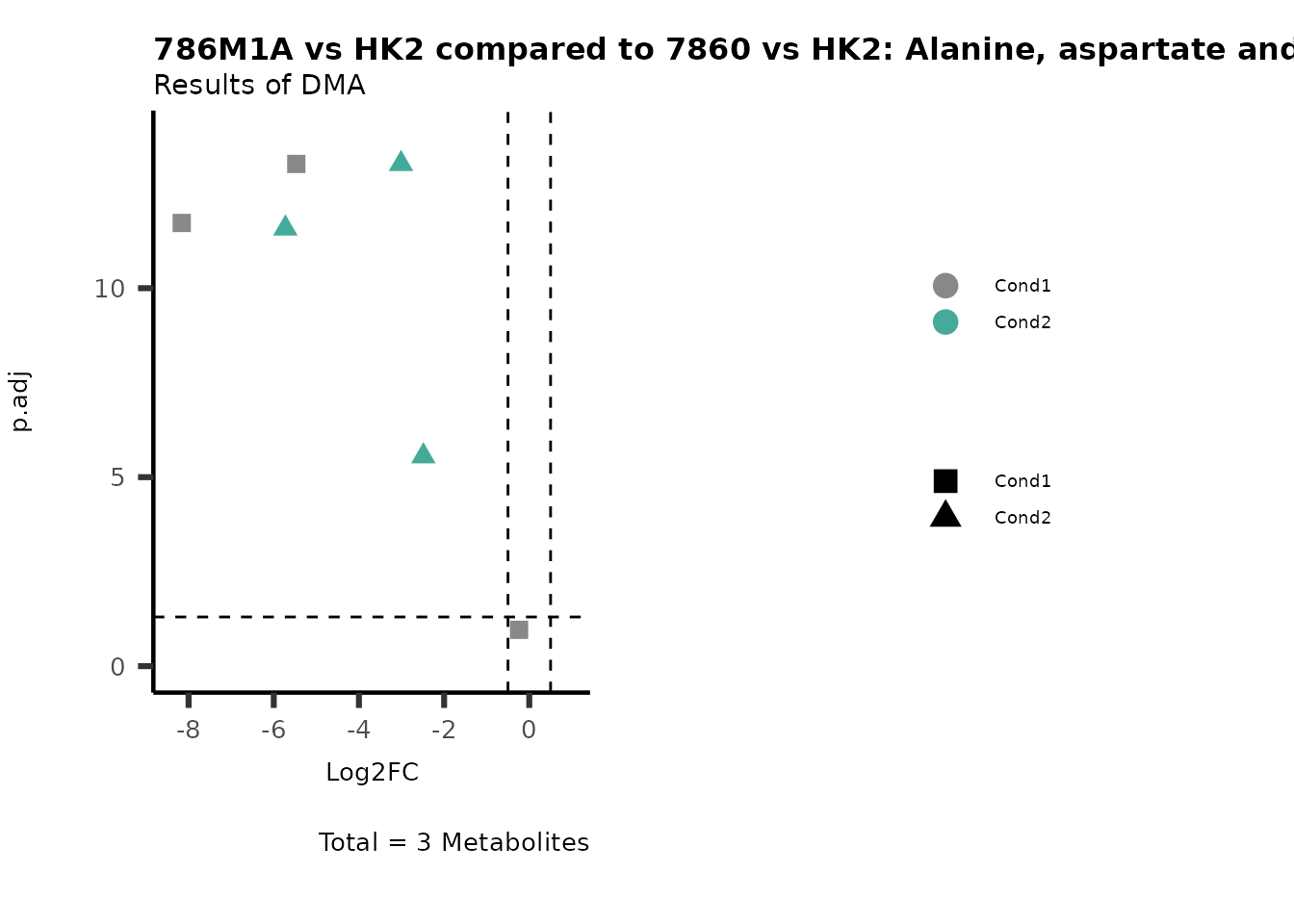
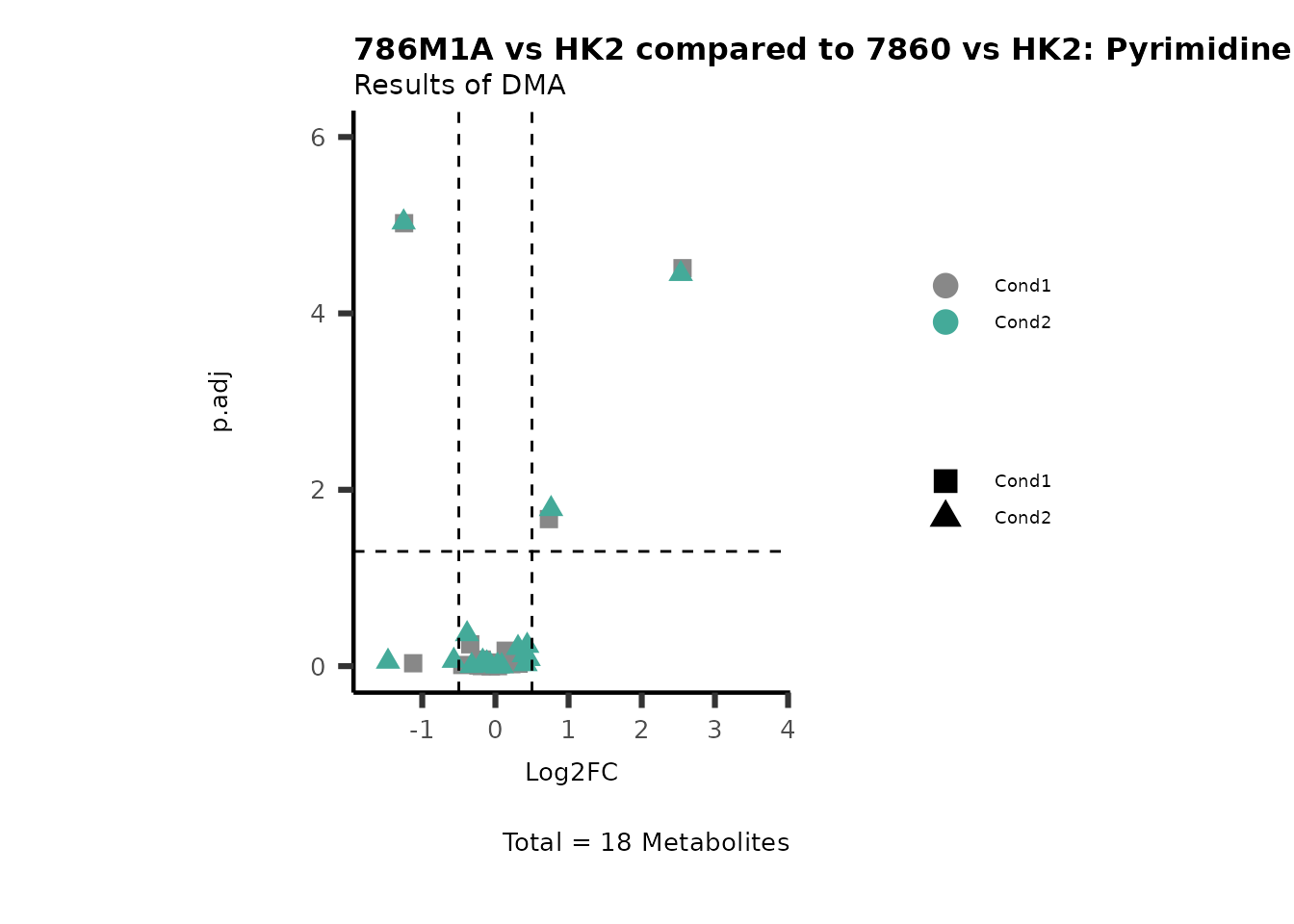


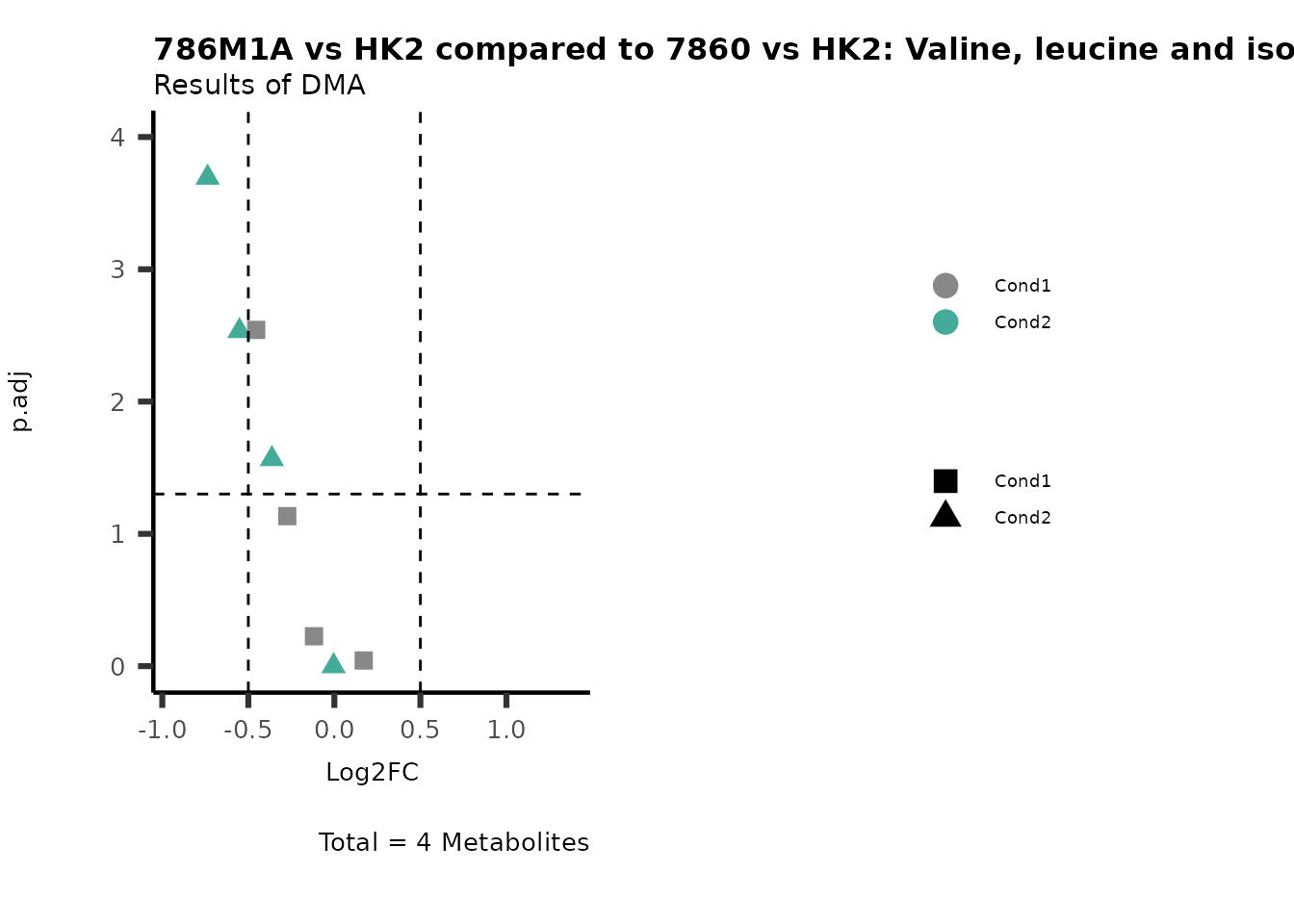
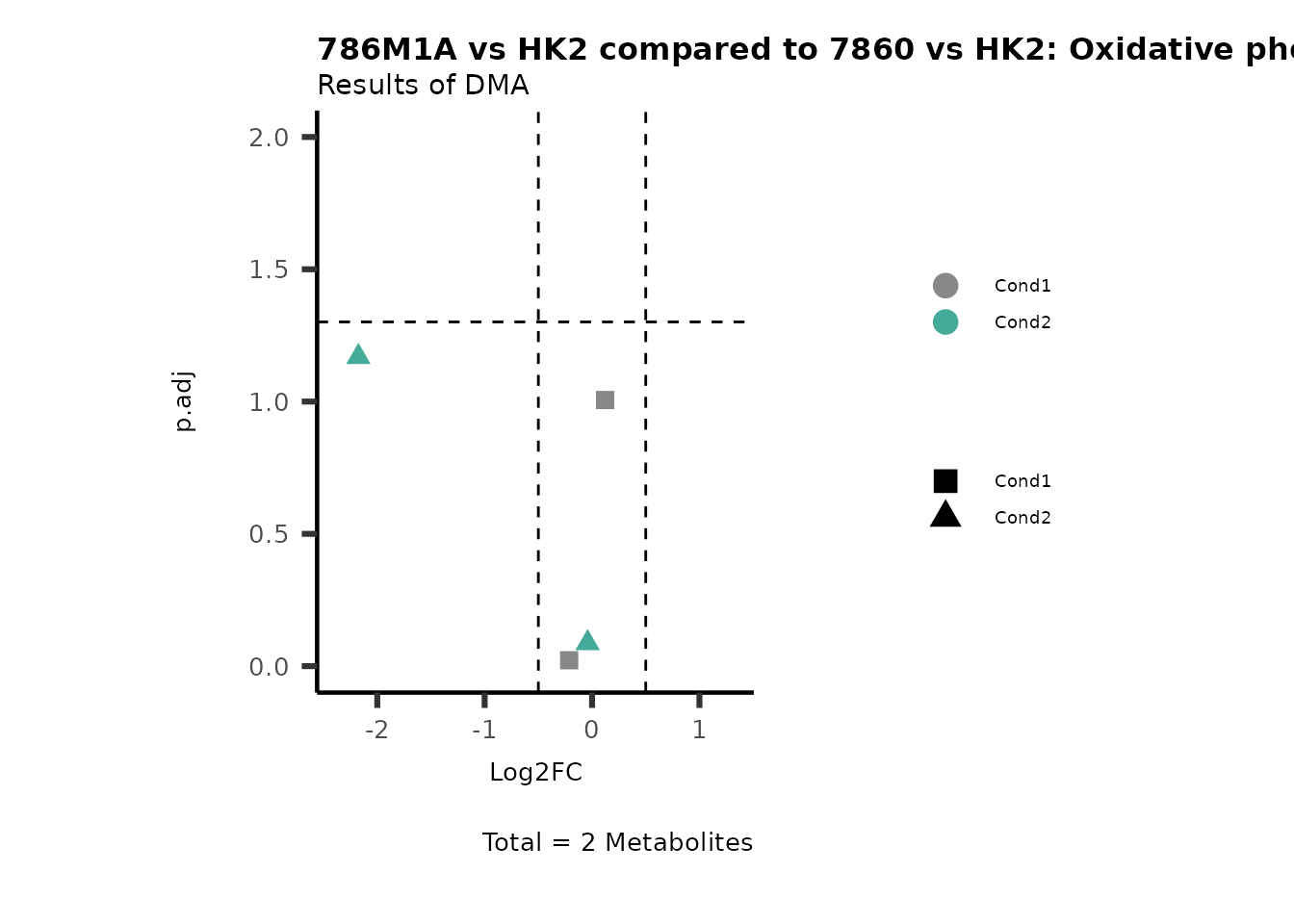
PathwayEnrichmentAnalysis
If you have performed Pathway Enrichment Analysis (PEA) such as ORA
or GSEA, we can also plot the results and add the information into the
Figure legends.
For this we need to prepare the correct input data including the
pathways used to run the pathway analysis, the differential metabolite
data used as input for the pathway analysis and the results of the
pathway analysis:
#Prepare the Input:
#1. InputData=Pathway analysis input: Must have features as column names. Those feature names need to match features in the pathway analysis file SettingsFile_Metab.
InputPEA <- DMA_786M1A_vs_HK2 %>%
filter(!is.na(KEGGCompound)) %>%
tibble::column_to_rownames("KEGGCompound")
#2. InputData2=Pathway analysis output: Must have same column names as SettingsFile_Metab for Pathway name
InputPEA2 <- DM_ORA_786M1A_vs_HK2 %>%
dplyr::rename("term"="ID")
#3. SettingsFile_Metab= Pathways used for pathway analysis: Must have same column names as SettingsFile_Metab for Pathway name and feature names need to match features in the InputData. PEA_Feature passes this column name!
Now we can produce the plots:
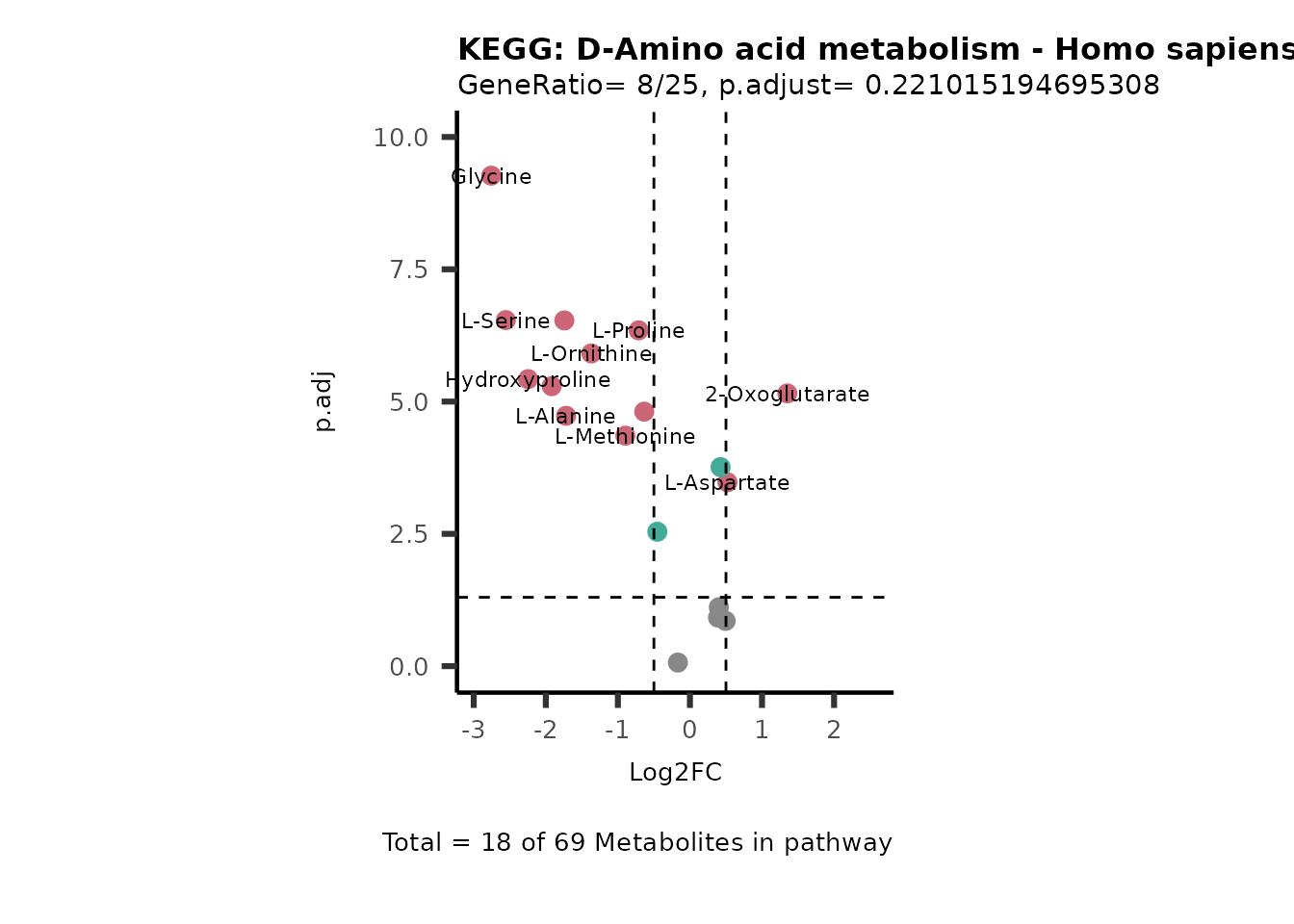
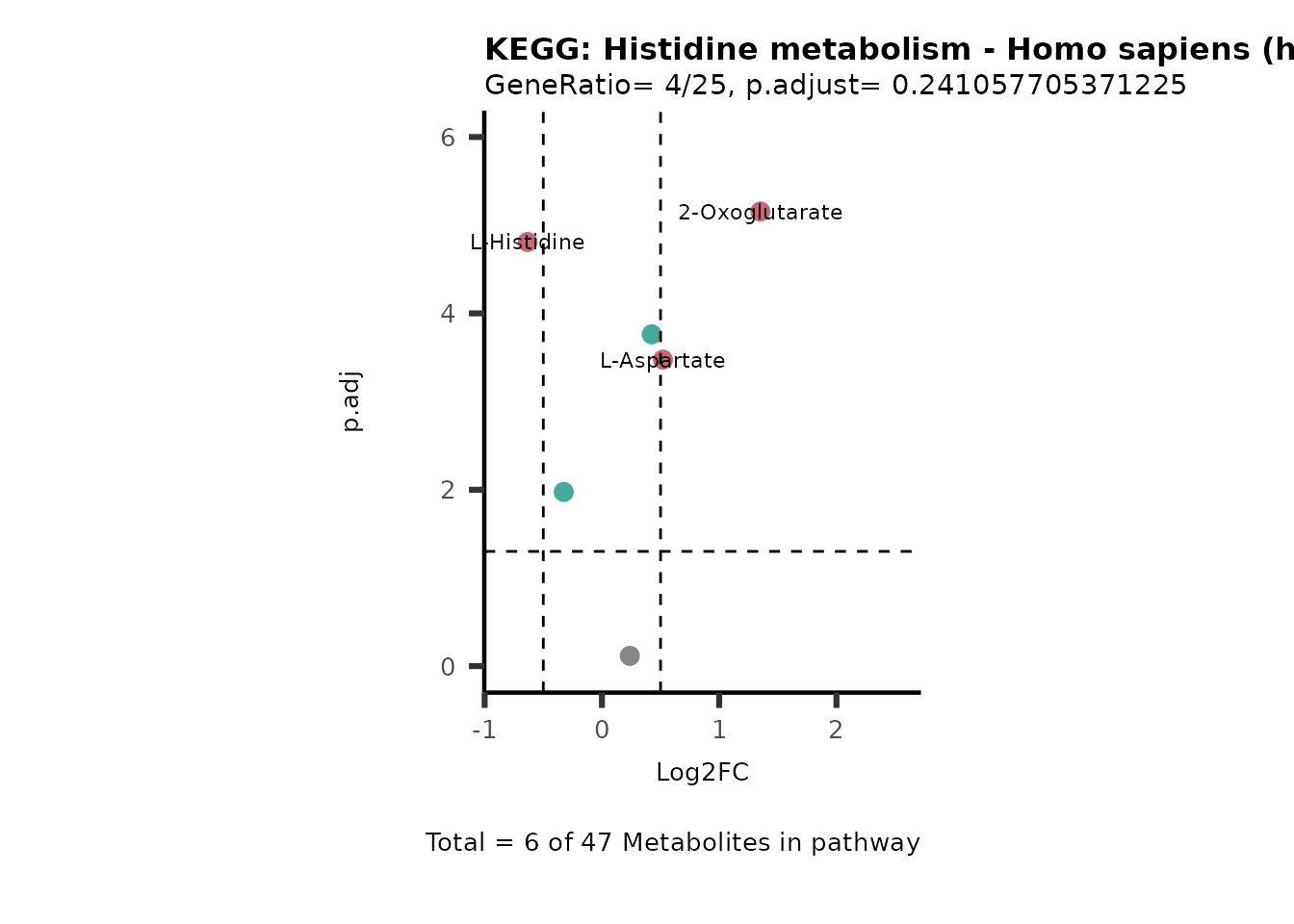
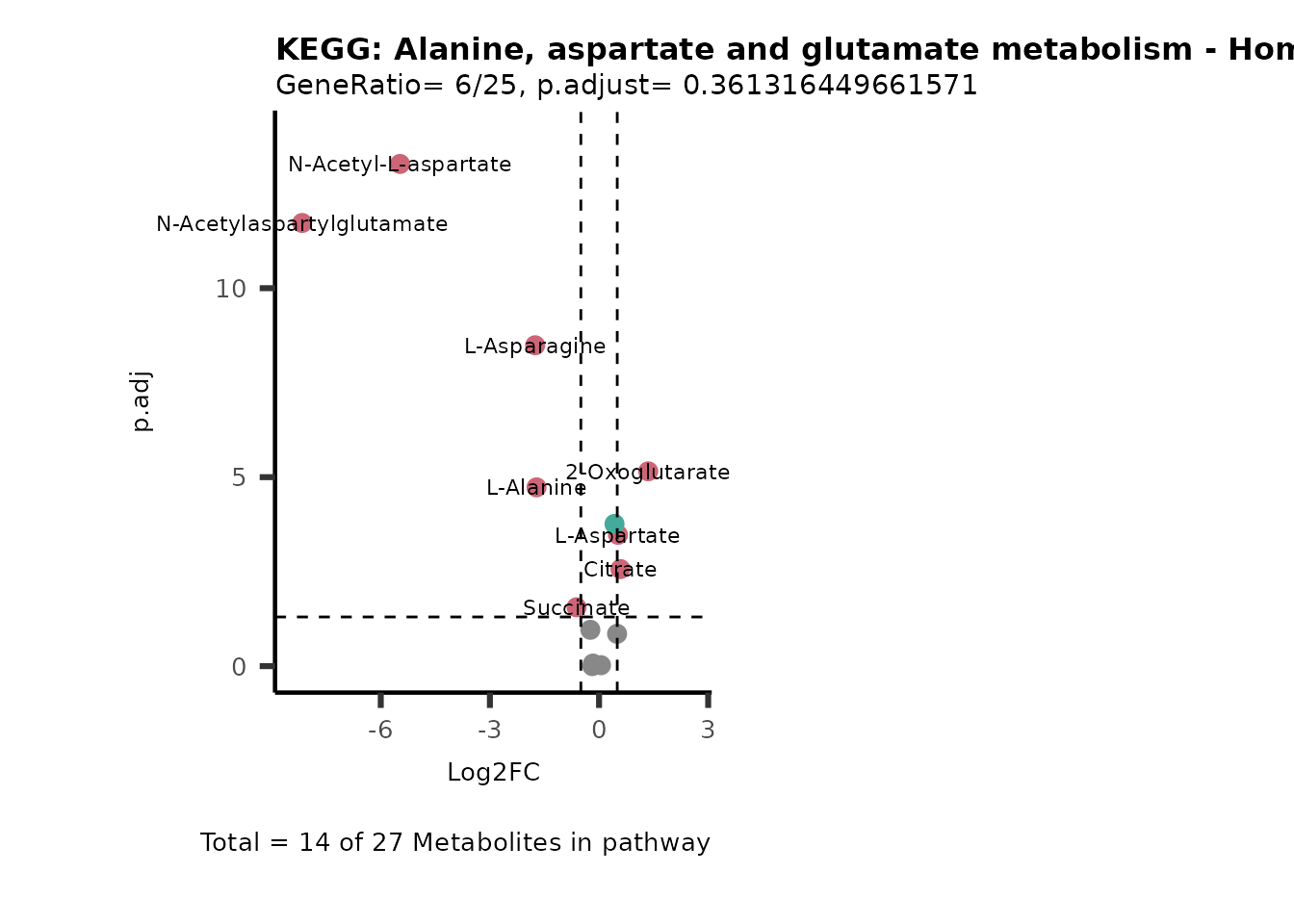
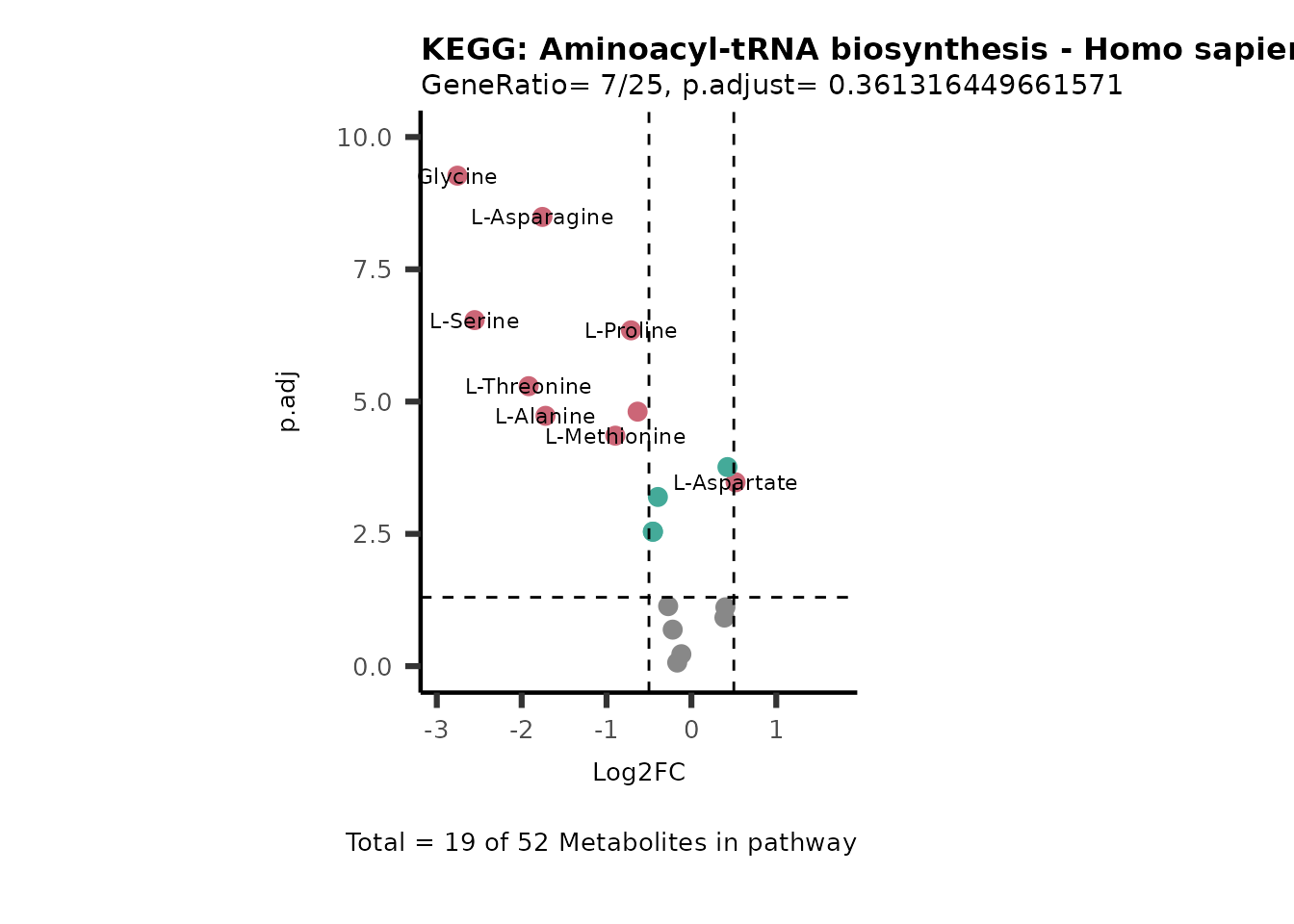
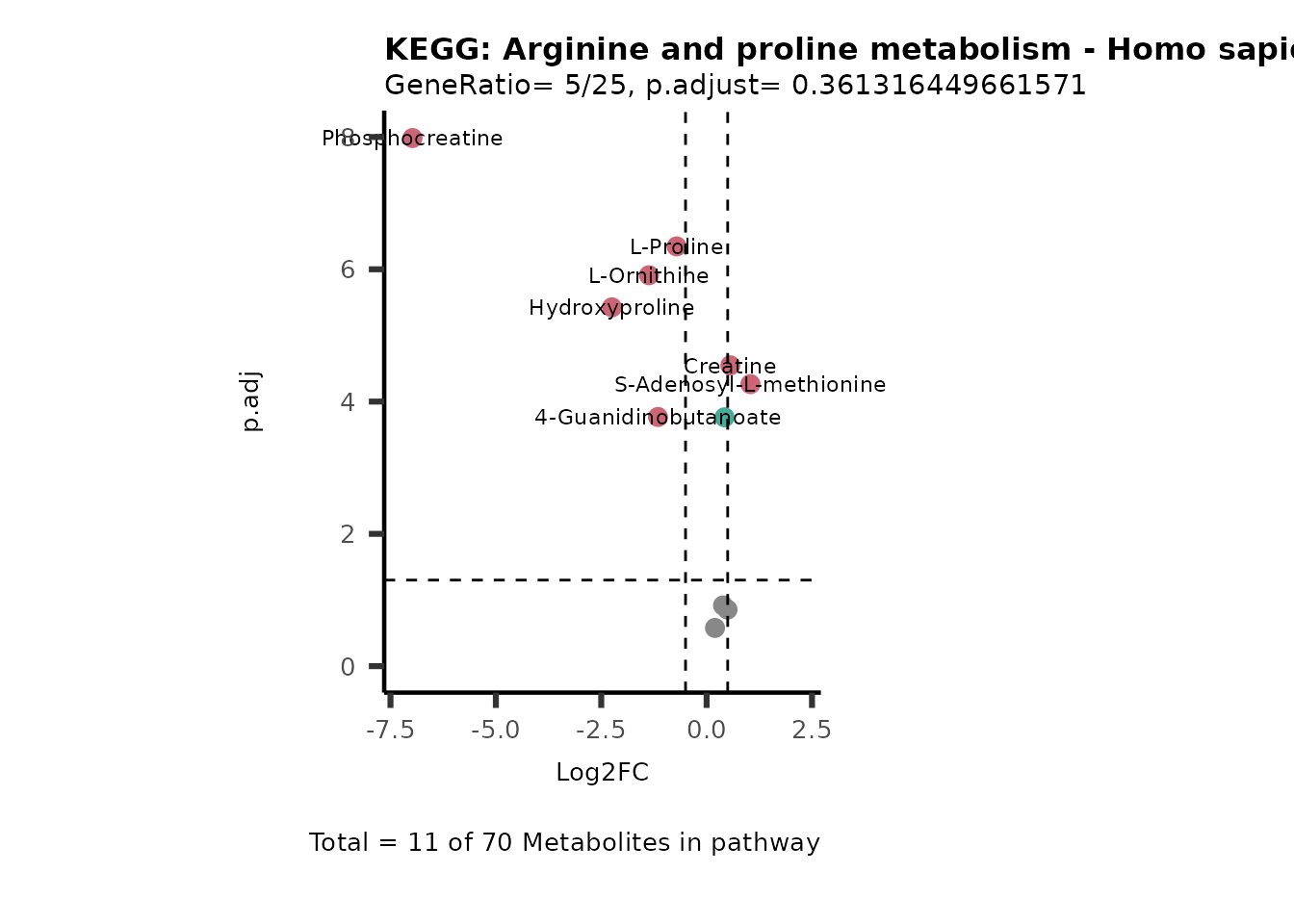
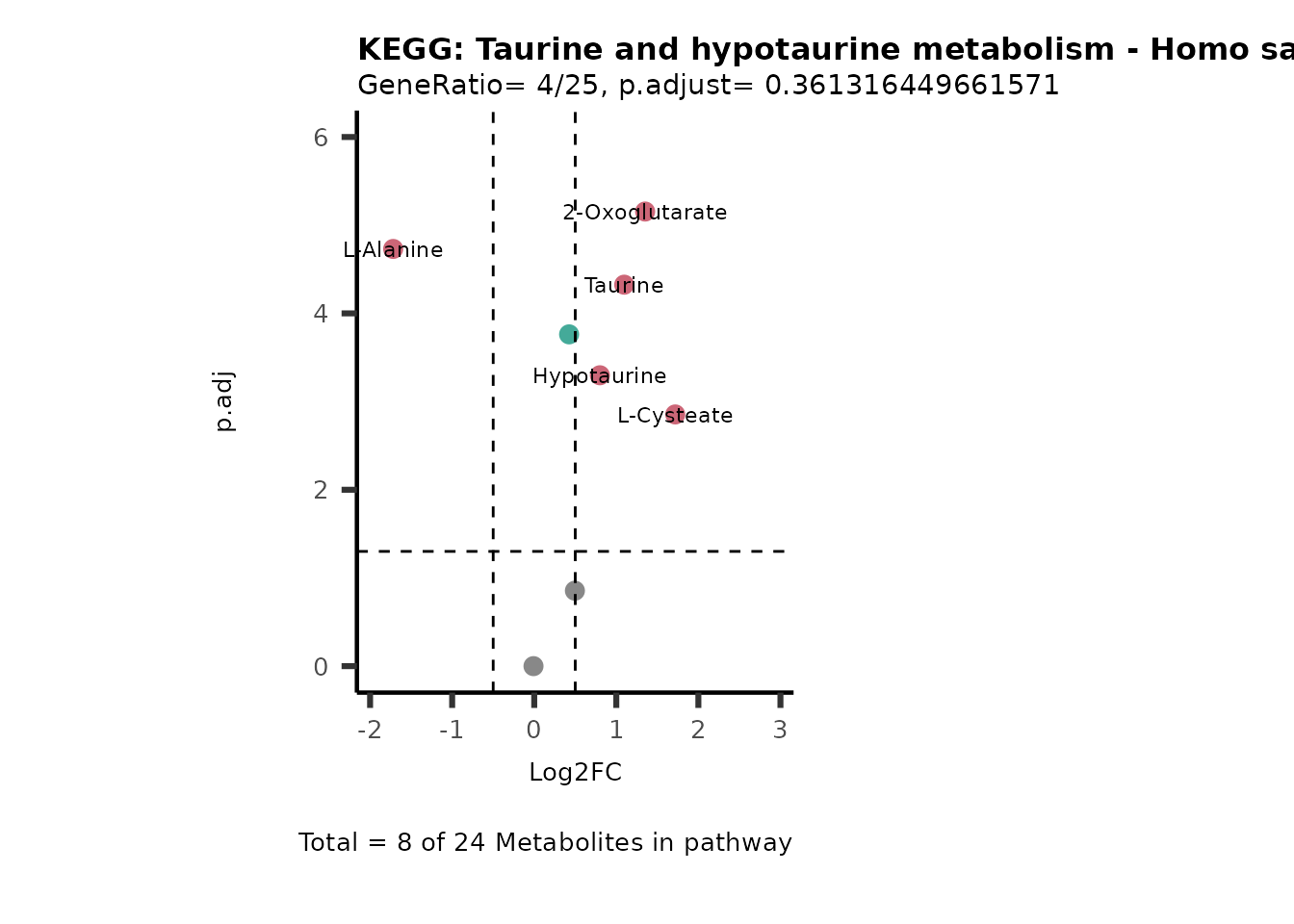
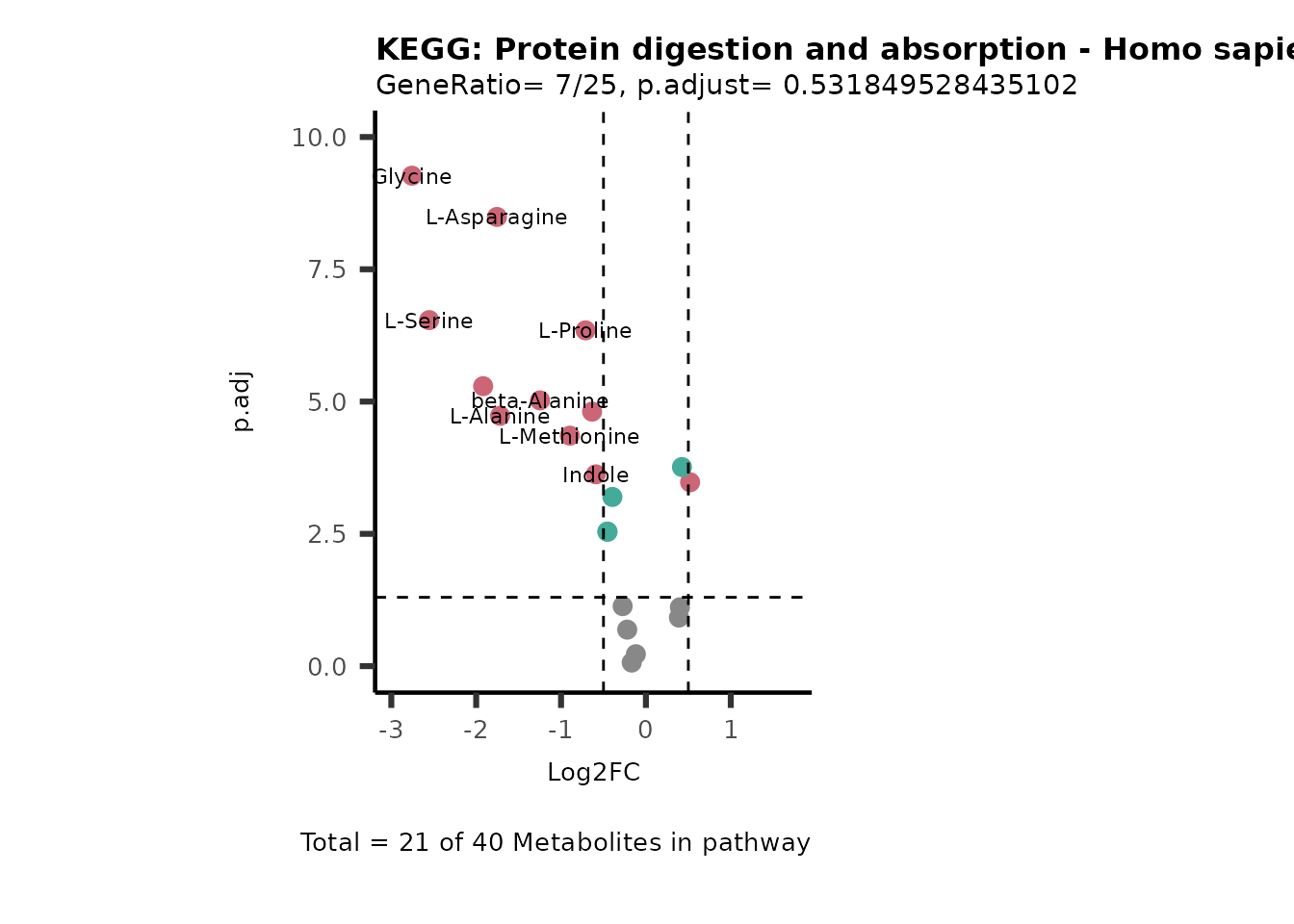
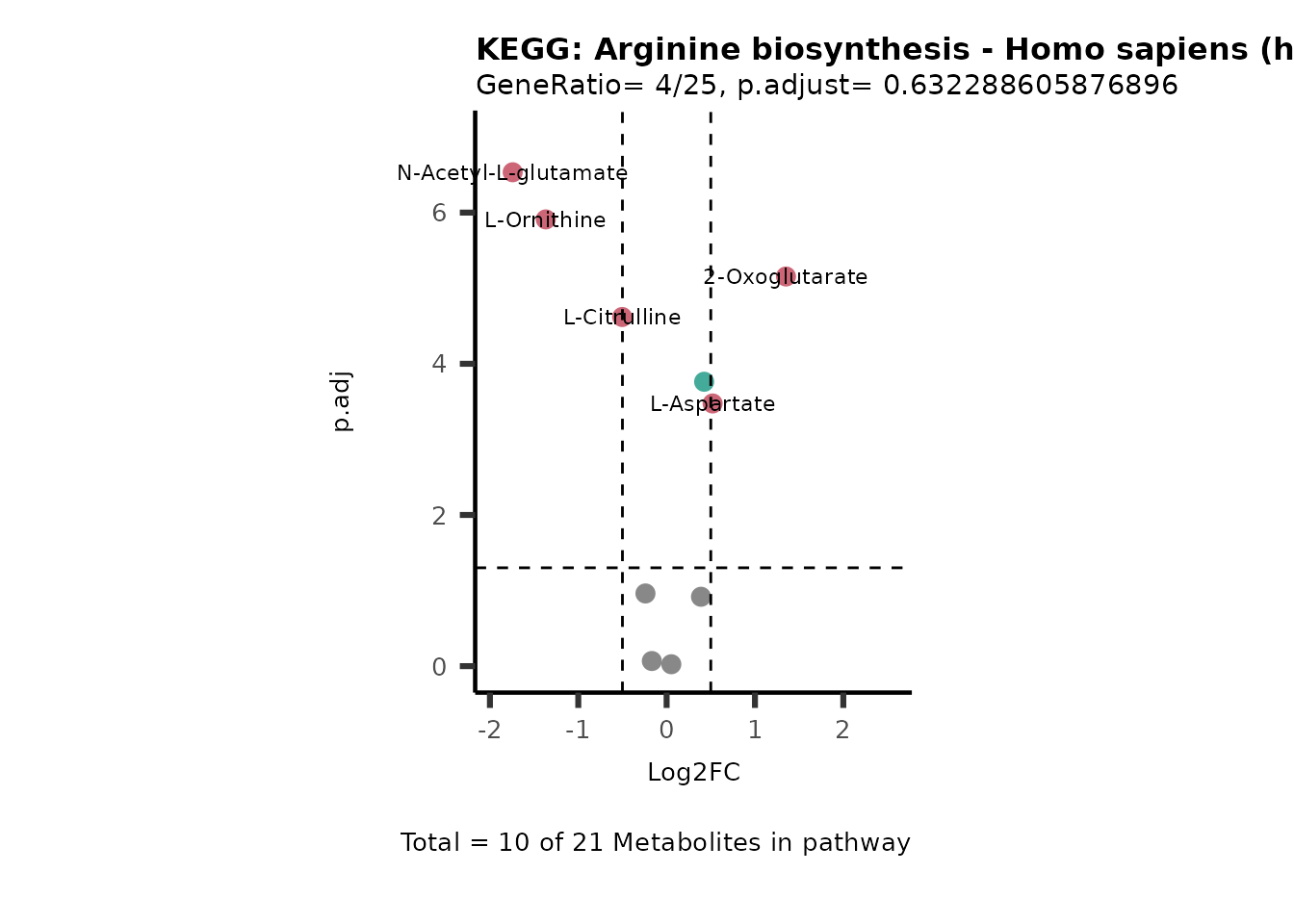
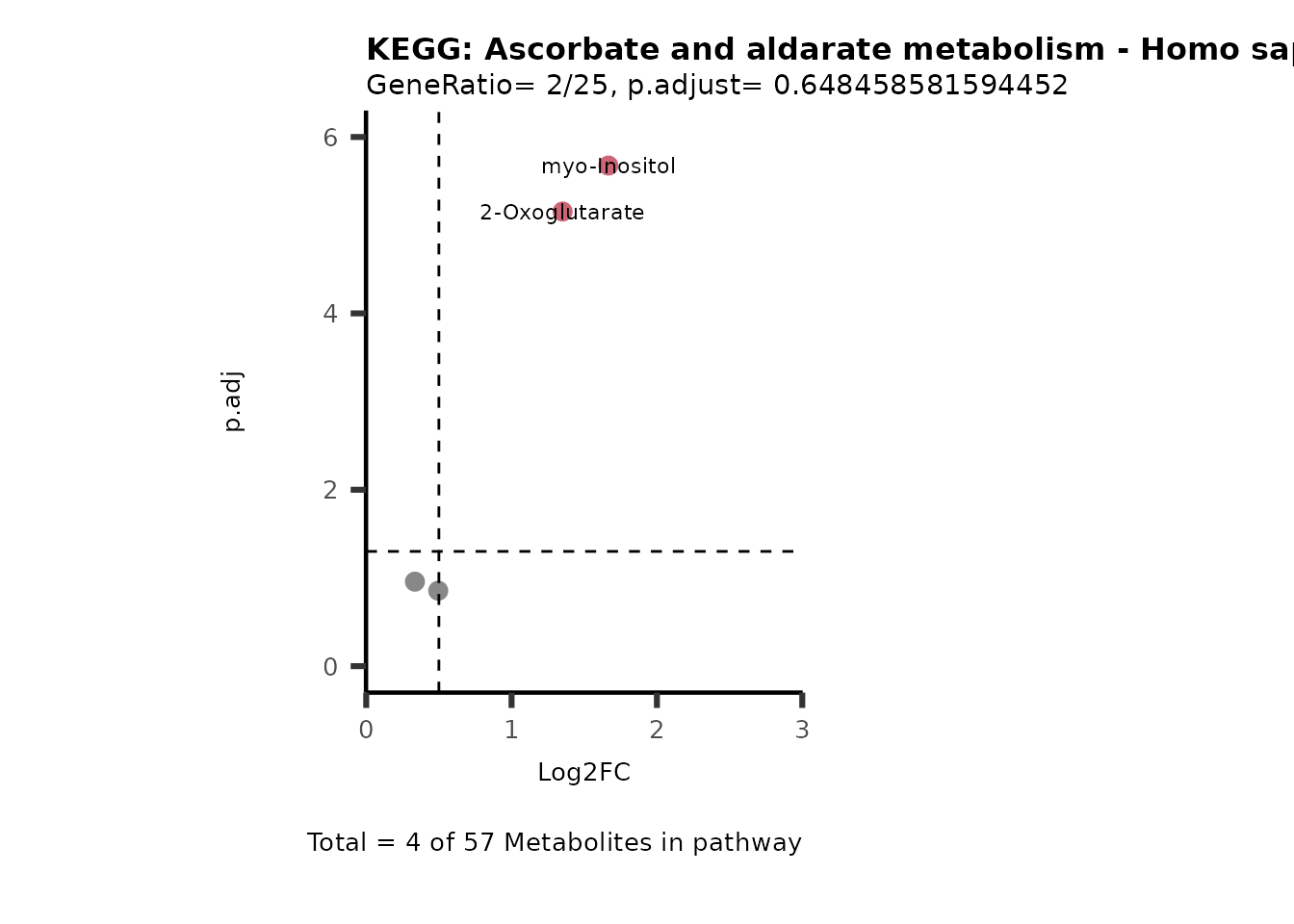
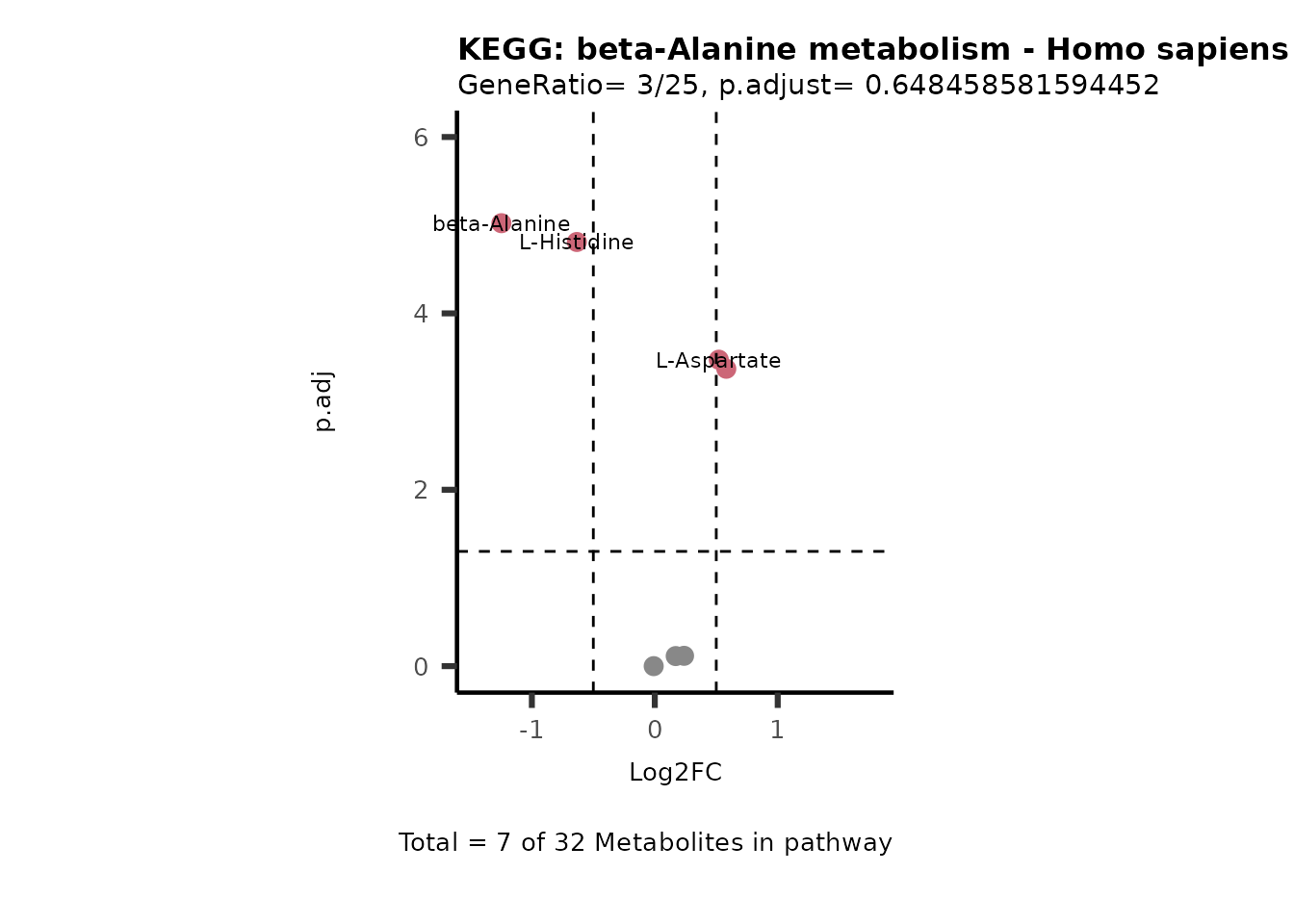
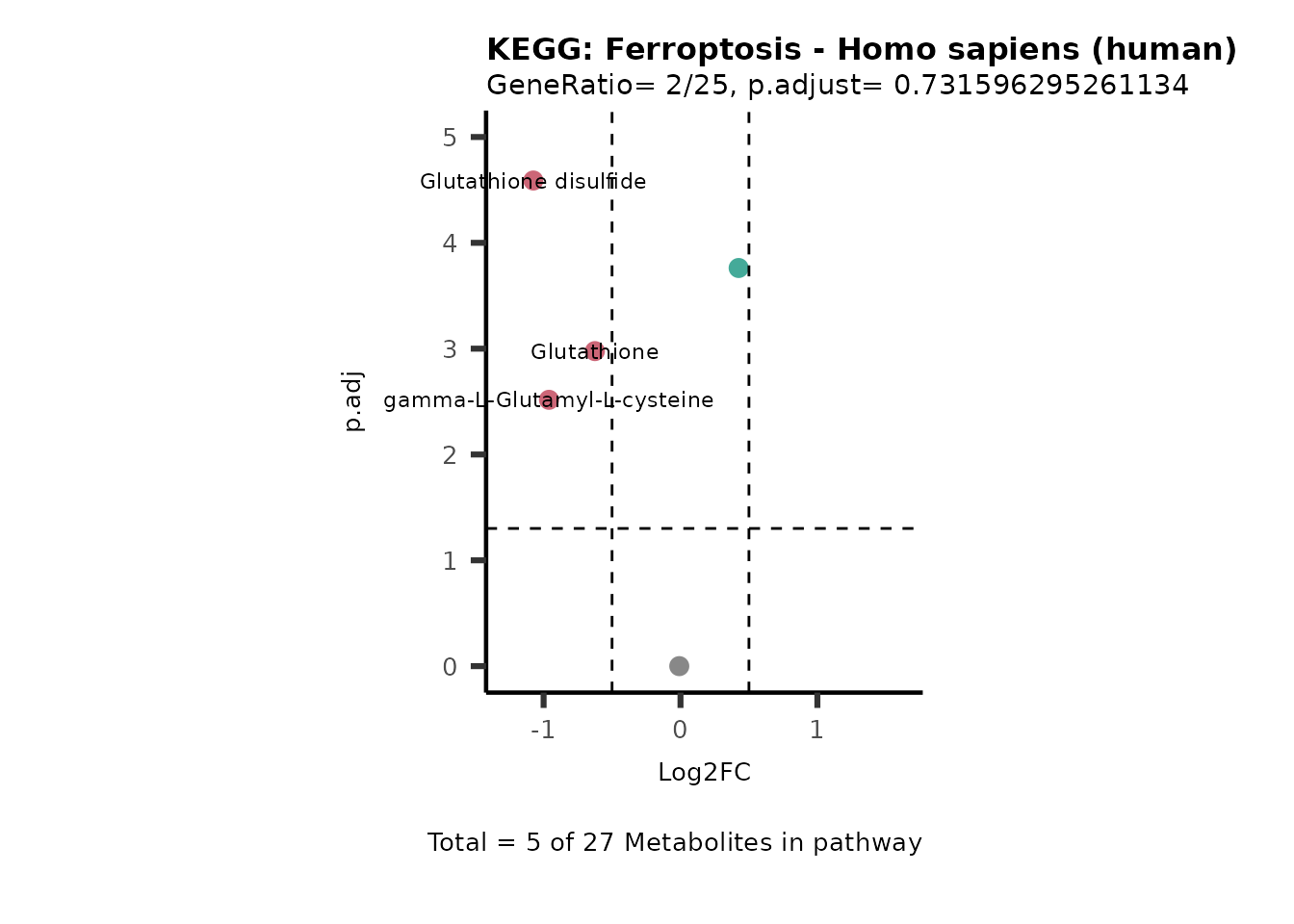
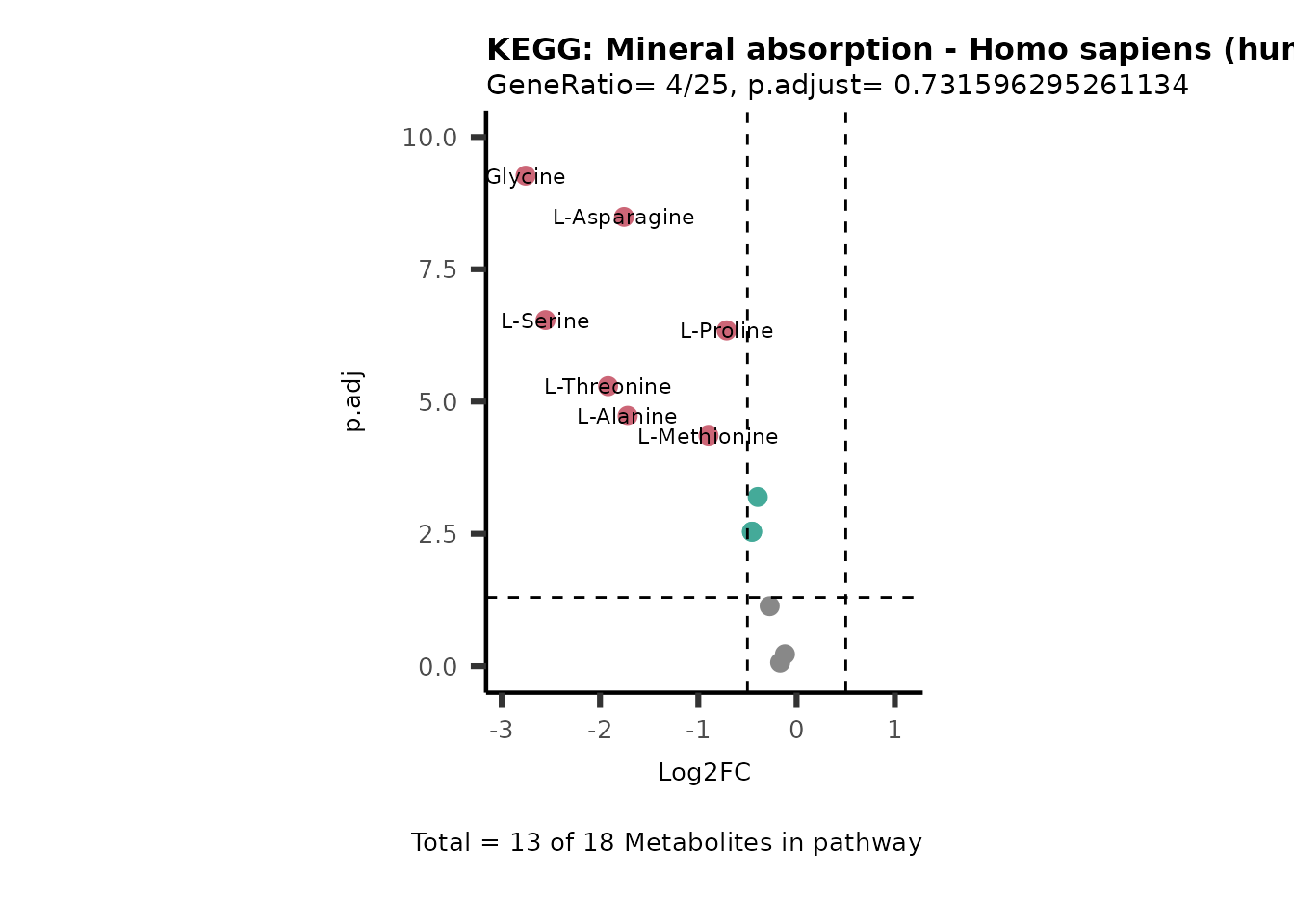
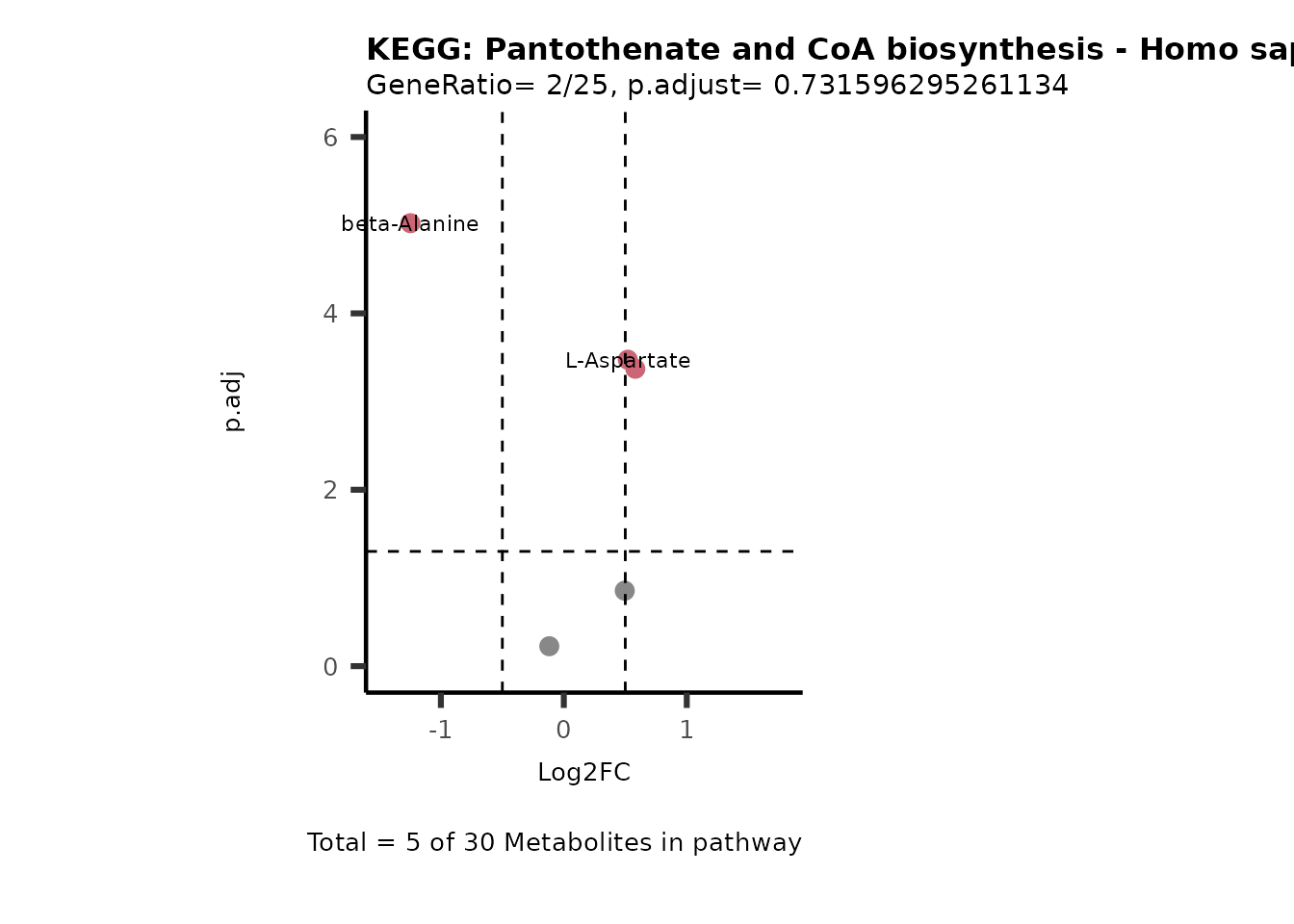
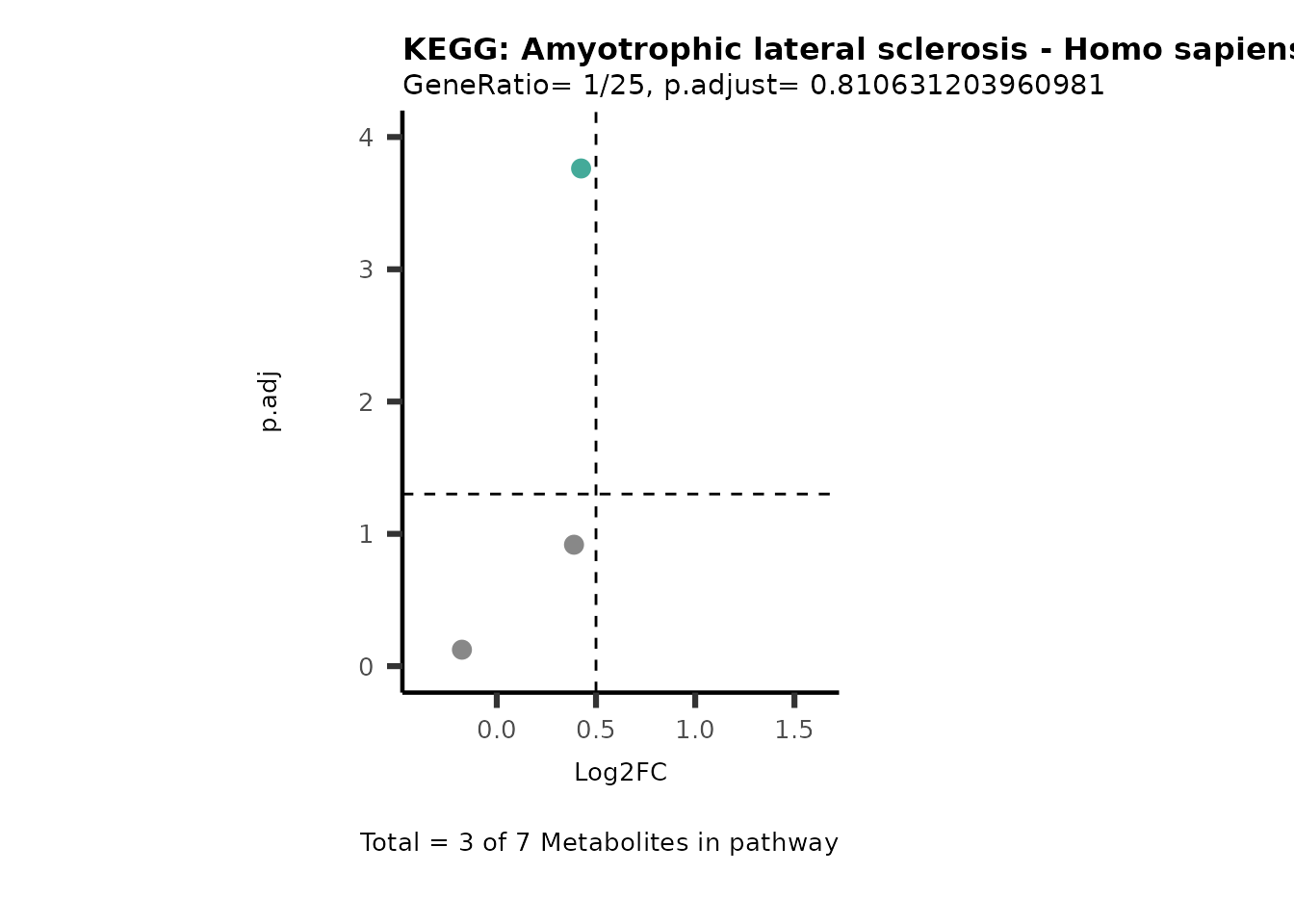
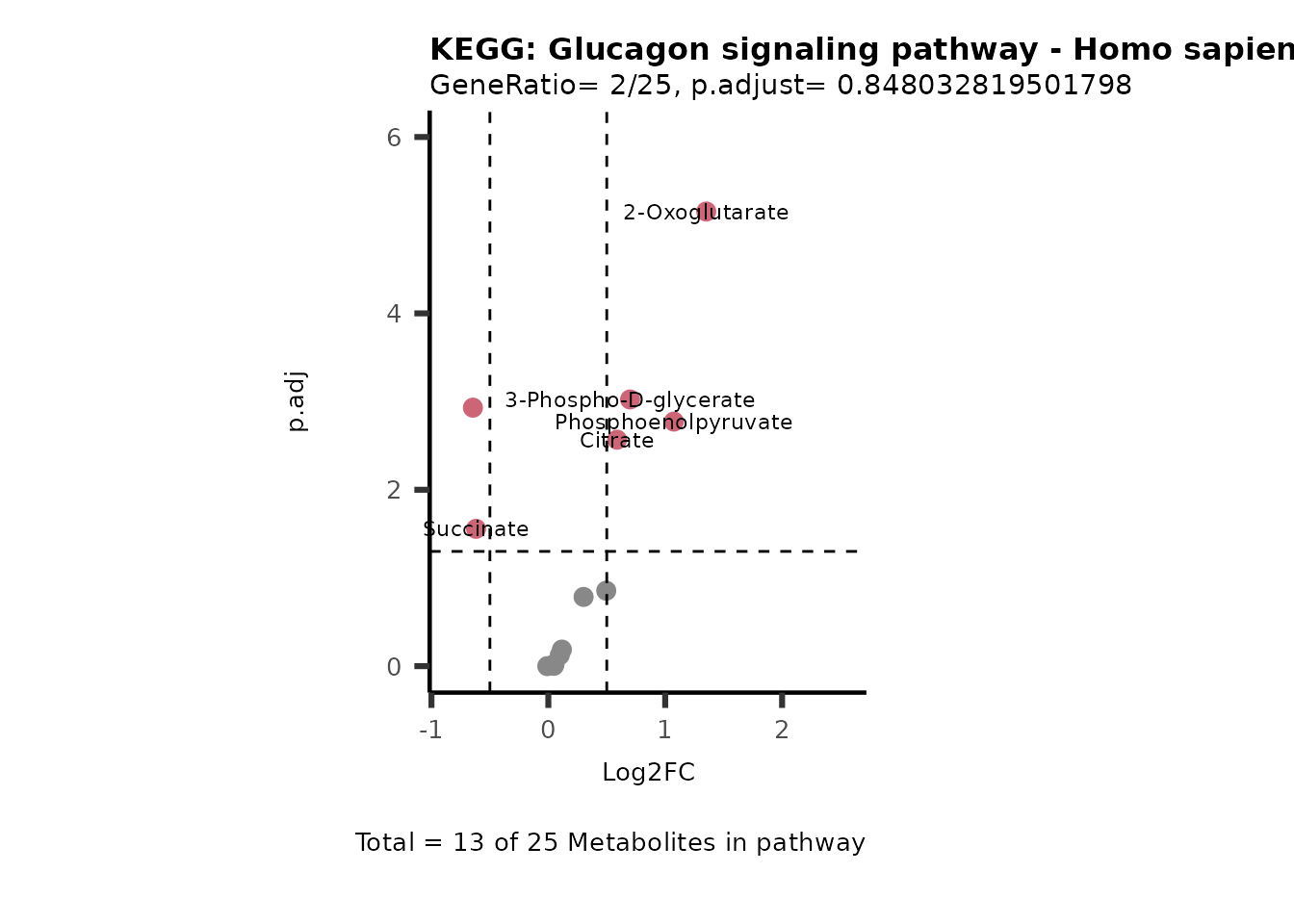
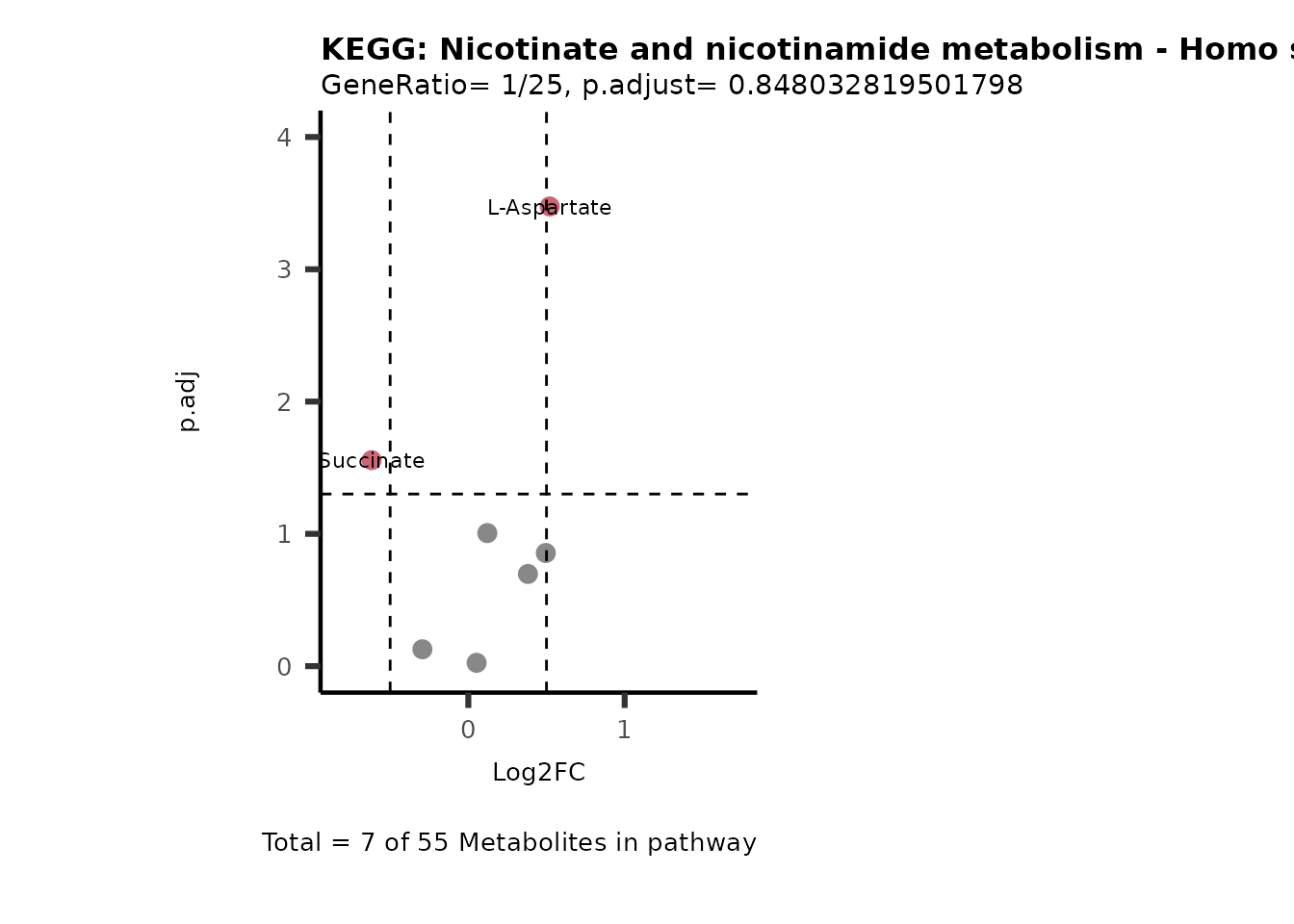
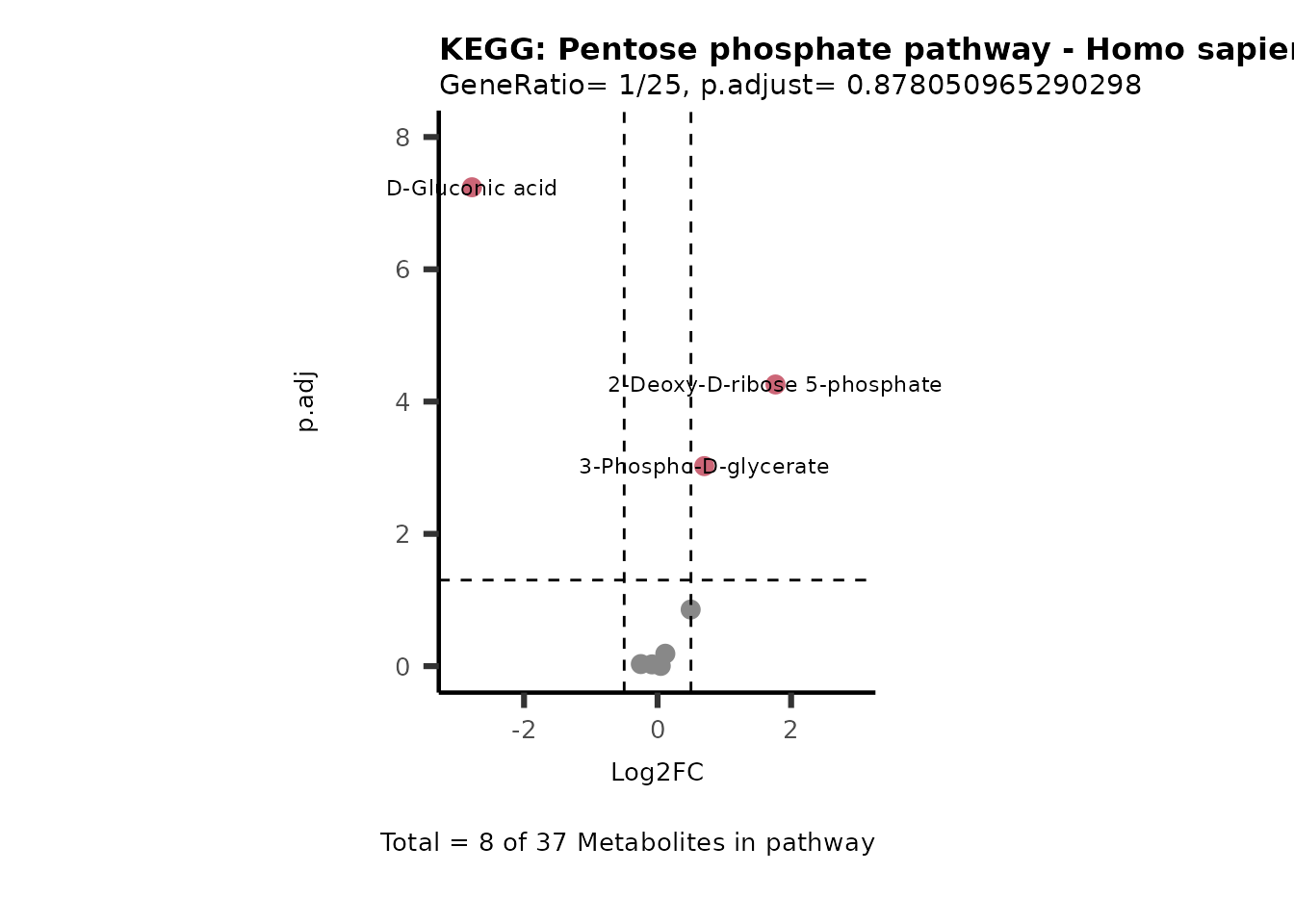
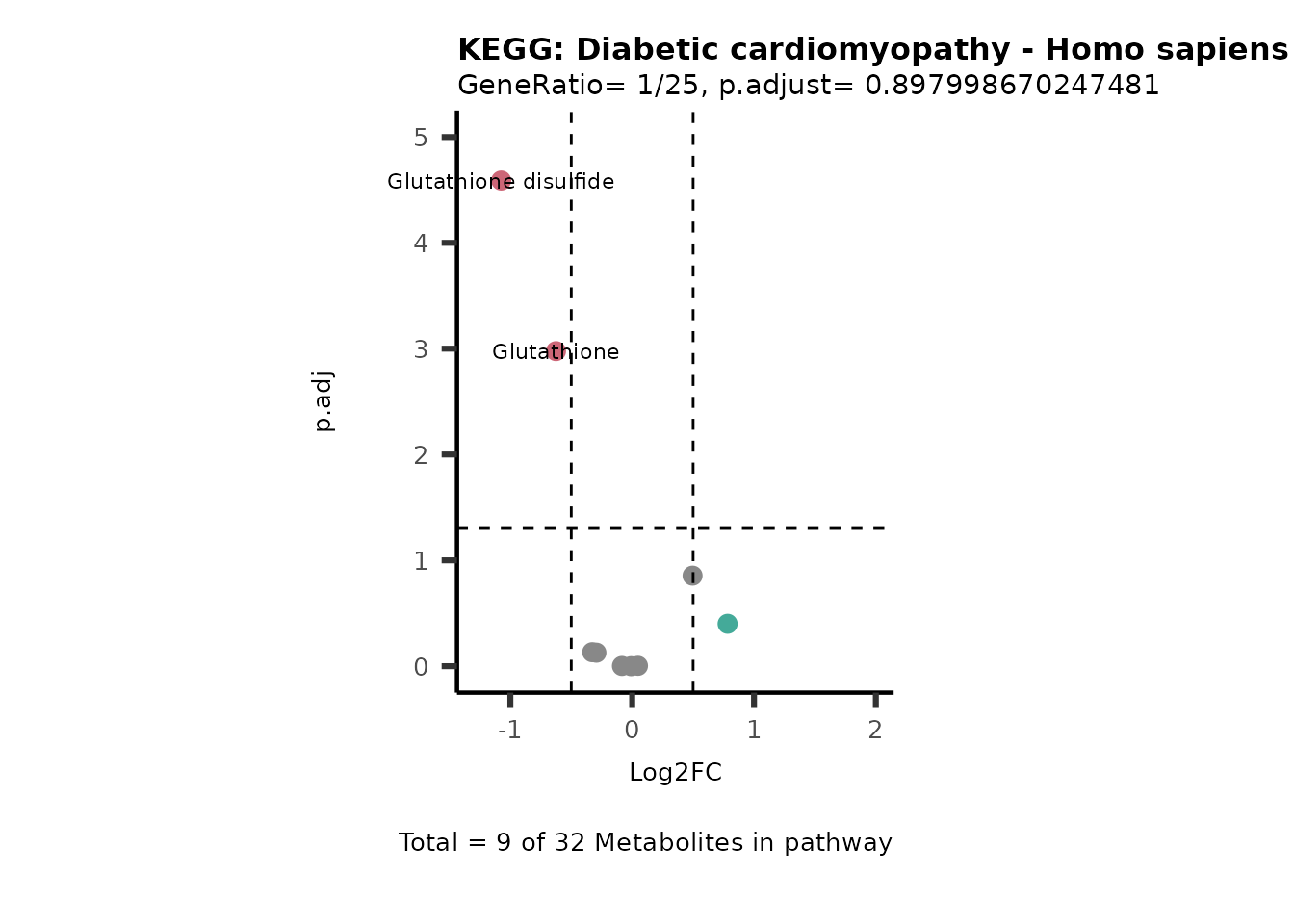
MetaProViz::VizVolcano(PlotSettings="PEA",
SettingsInfo= c(PEA_Pathway="term",# Needs to be the same in both, SettingsFile_Metab and InputData2.
PEA_stat="p.adjust",#Column InputData2
PEA_score="GeneRatio",#Column InputData2
PEA_Feature="Metabolite"),# Column SettingsFile_Metab (needs to be the same as row names in InputData)
SettingsFile_Metab= KEGG_Pathways,#Must be the pathways used for pathway analysis
InputData= InputPEA, #Must be the data you have used as an input for the pathway analysis
InputData2= InputPEA2, #Must be the results of the pathway analysis
PlotName= "KEGG",
Subtitle= "PEA" ,
SelectLab = NULL)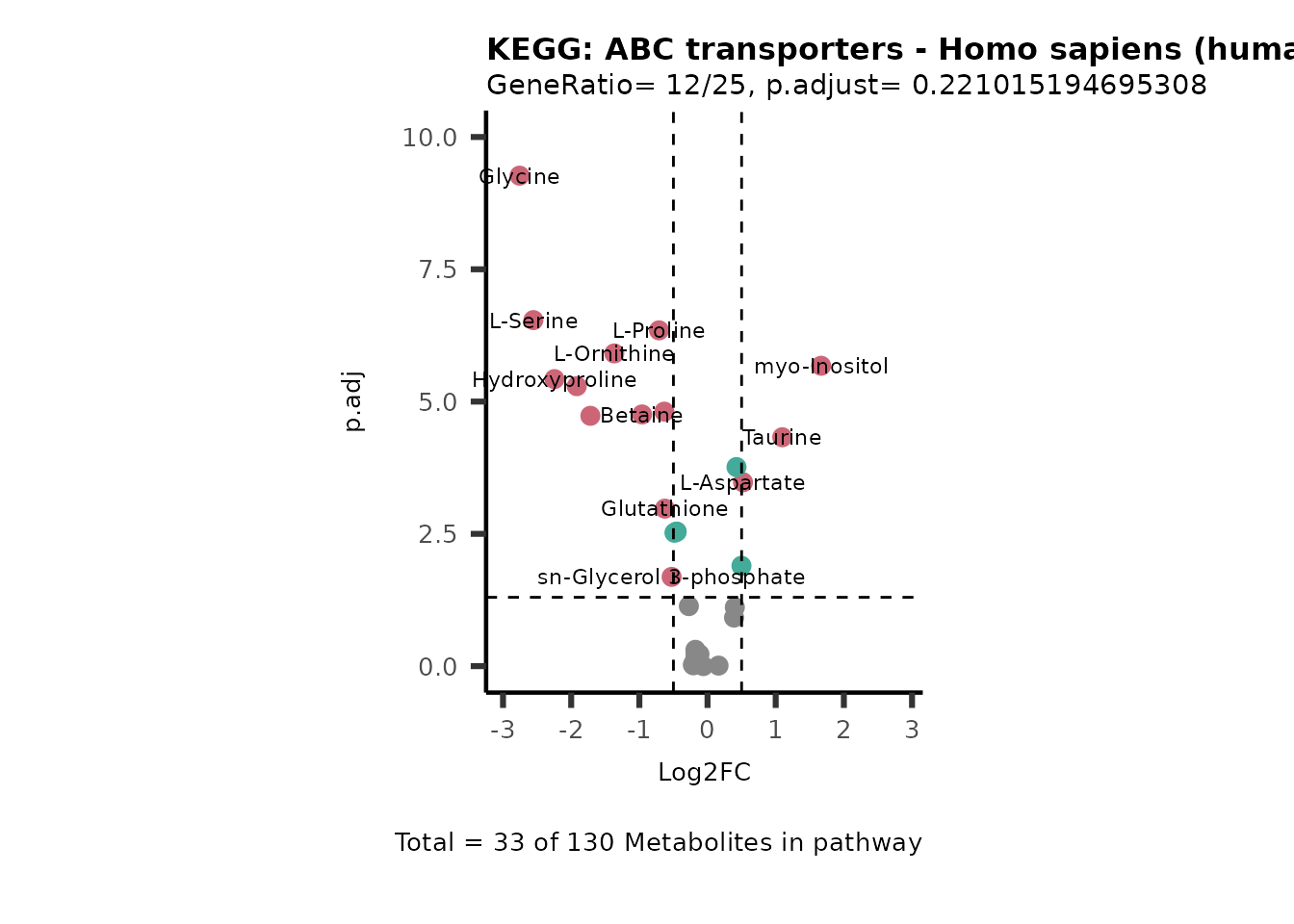
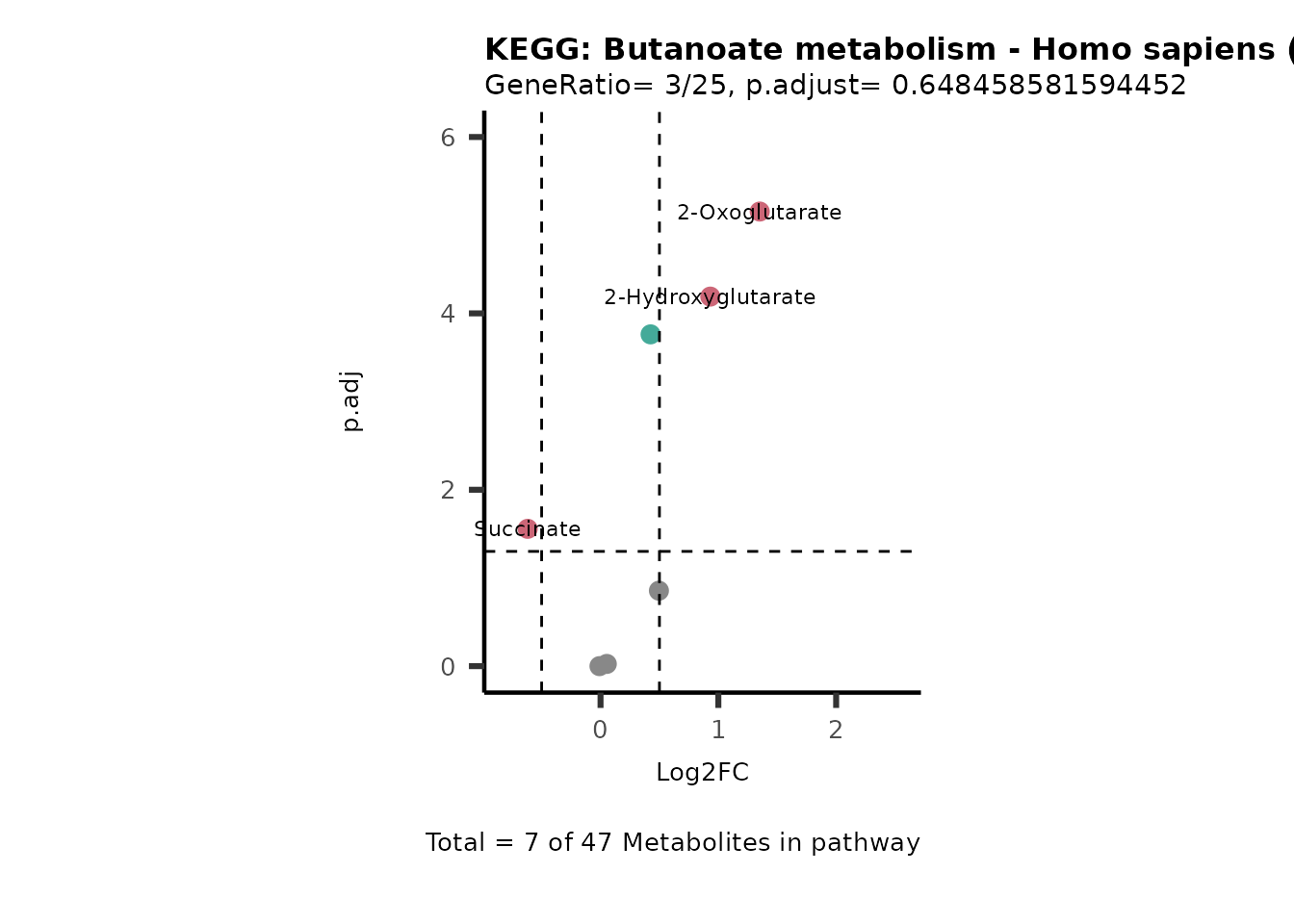
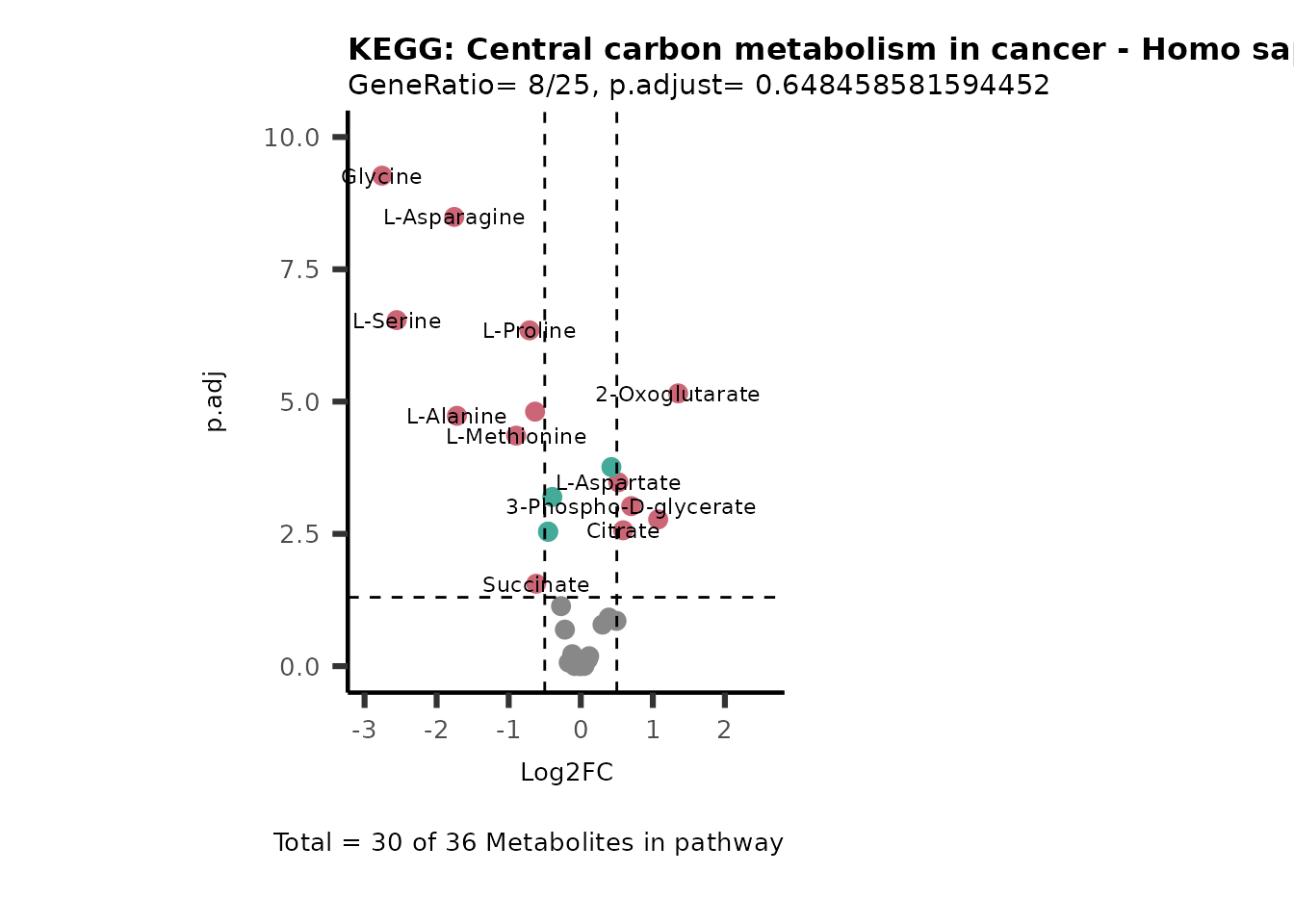

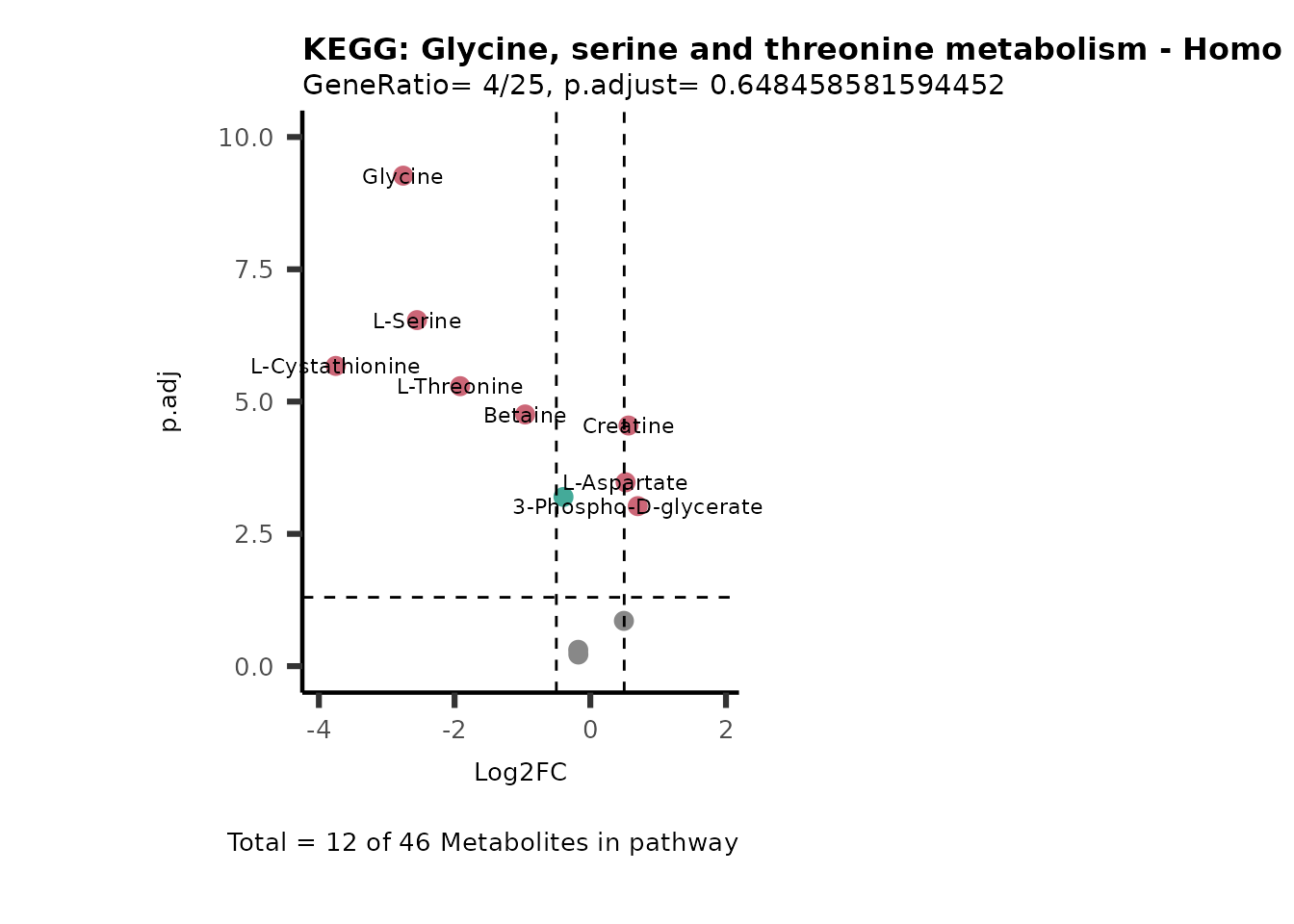
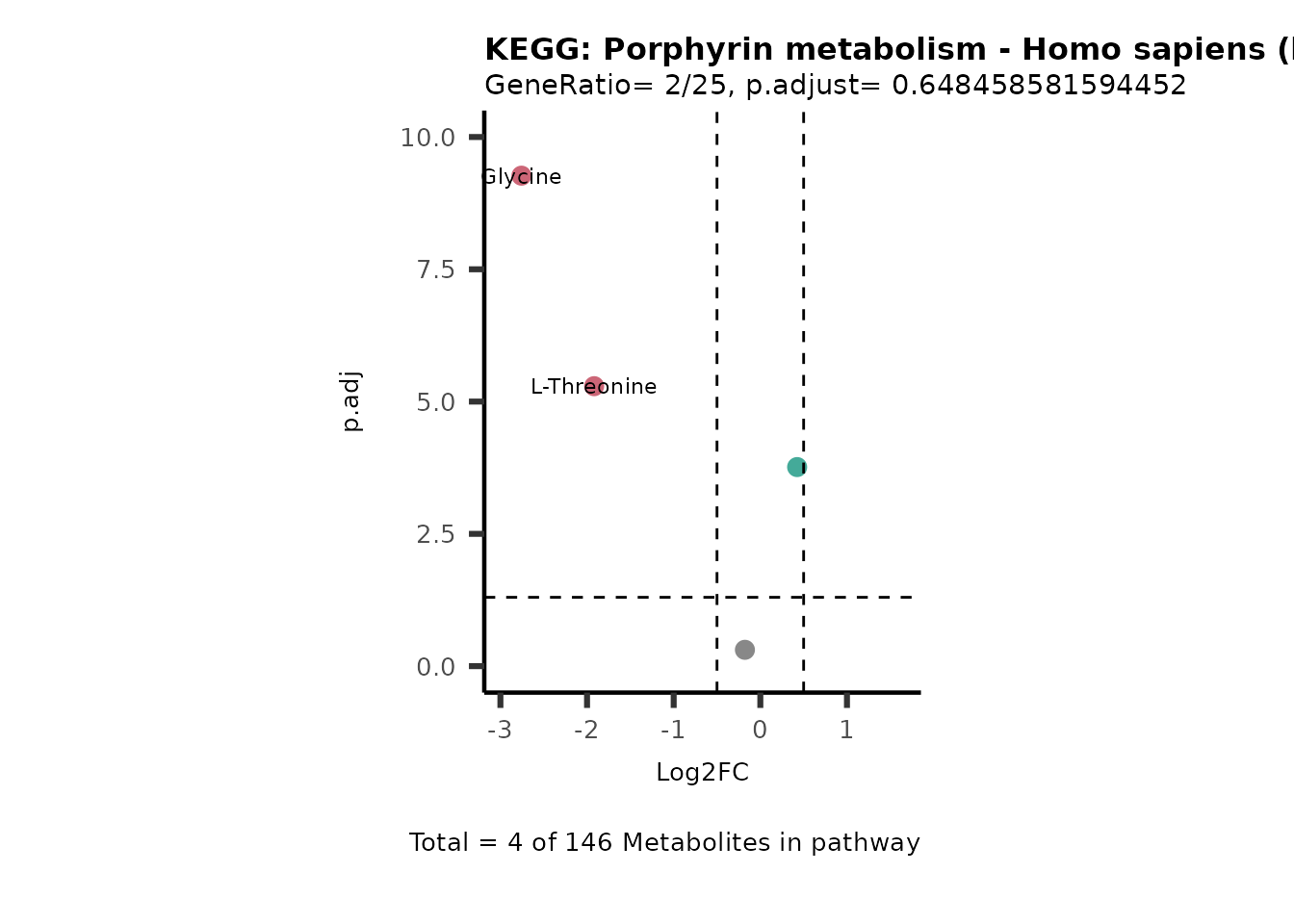

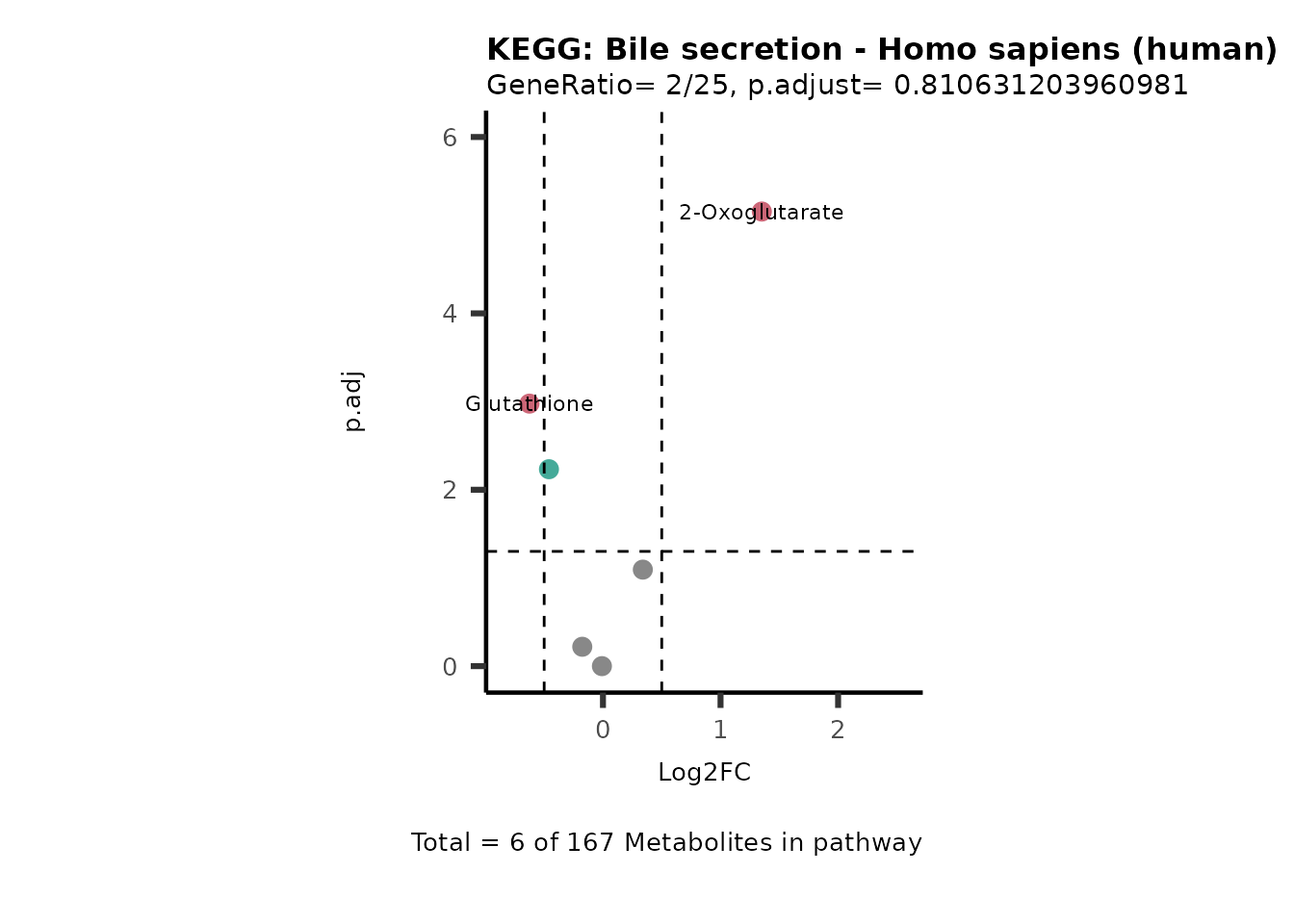
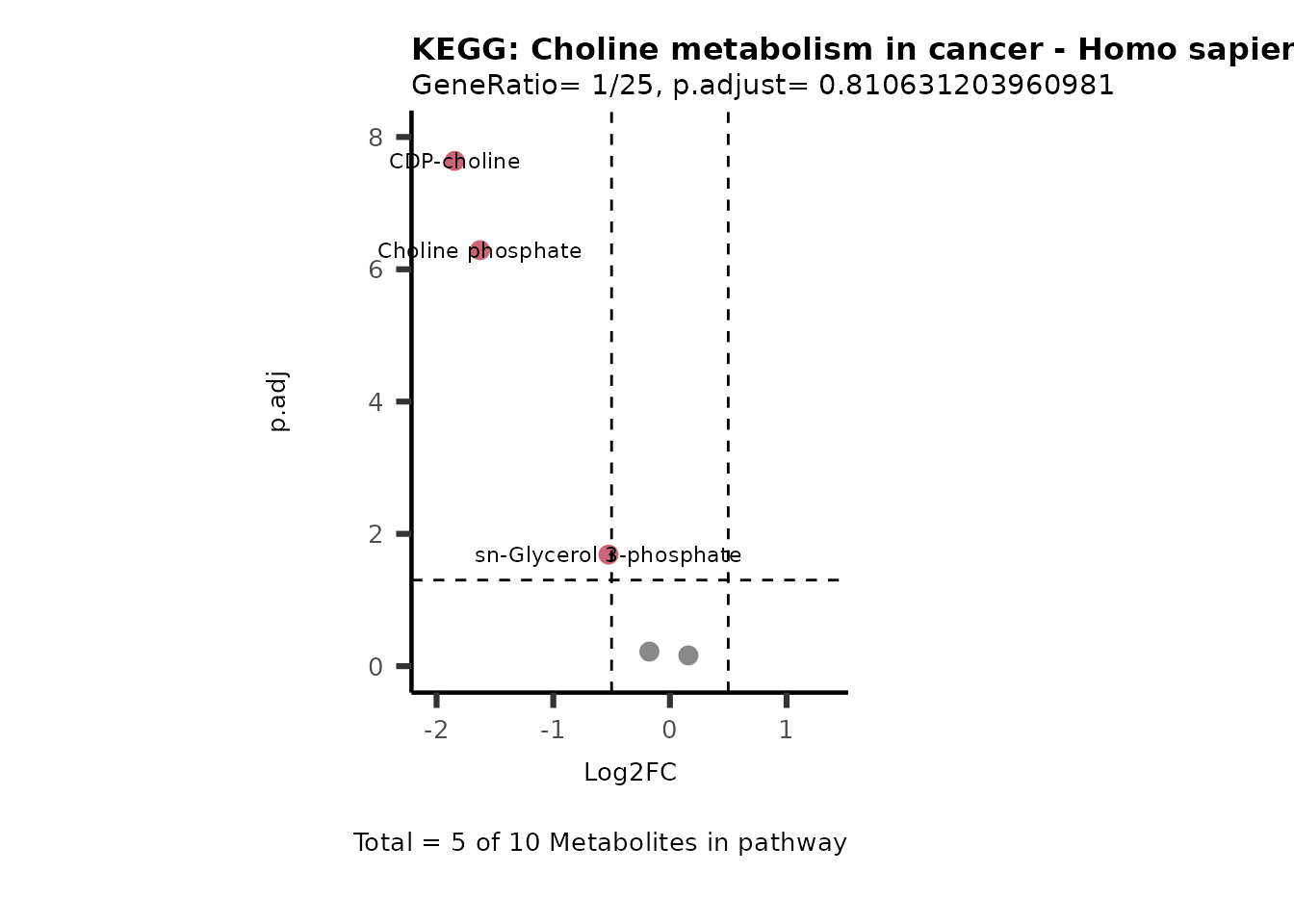
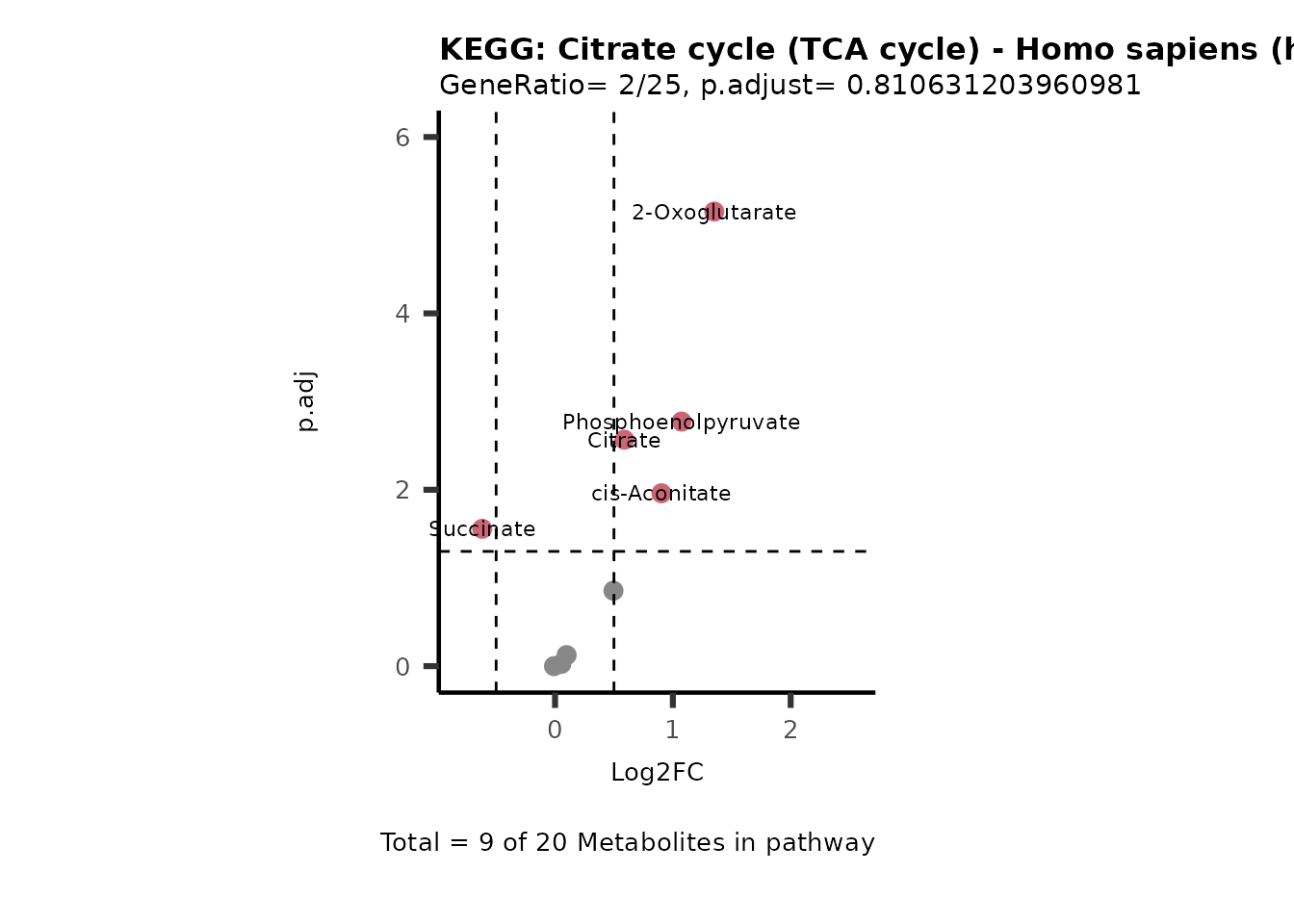
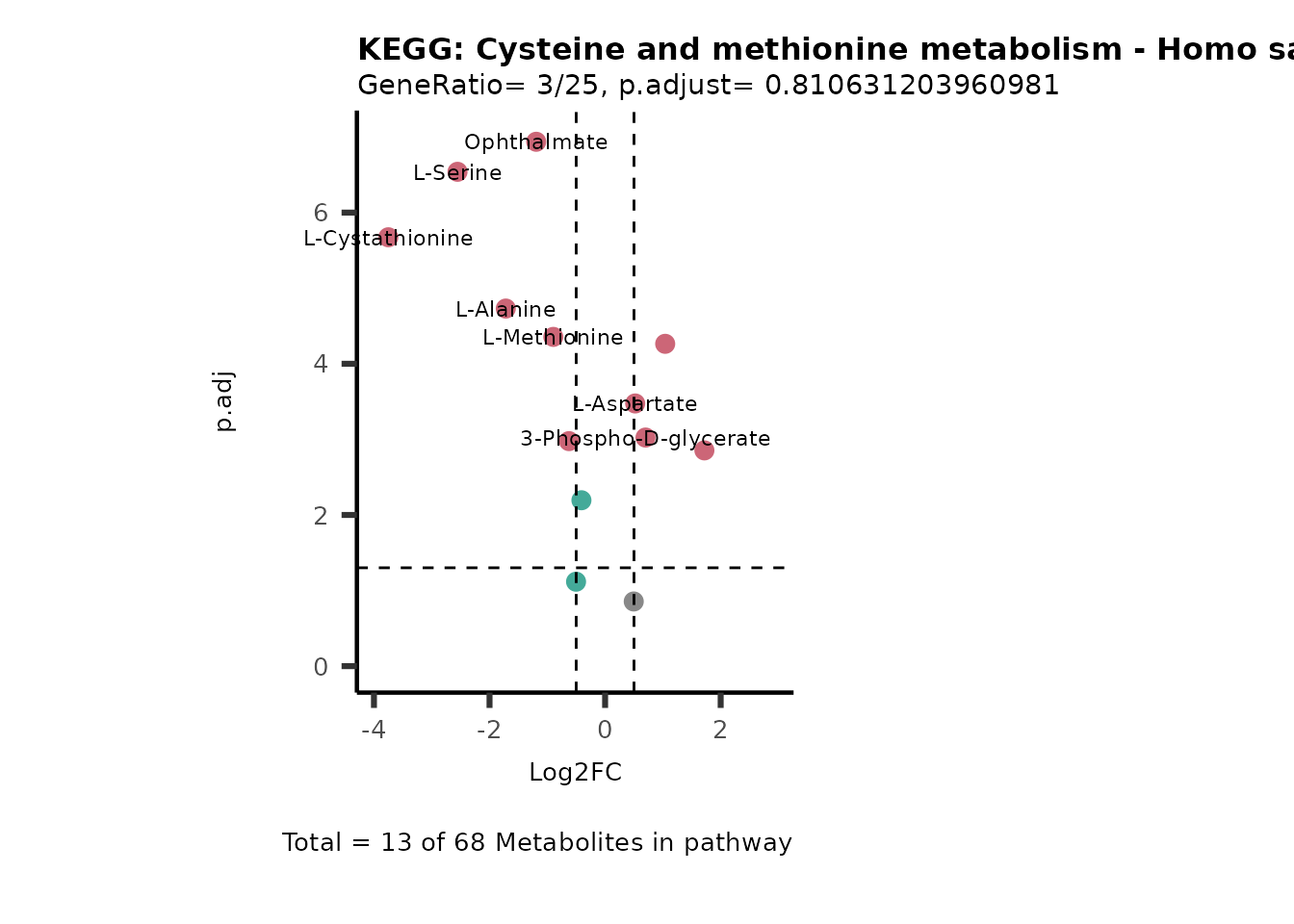
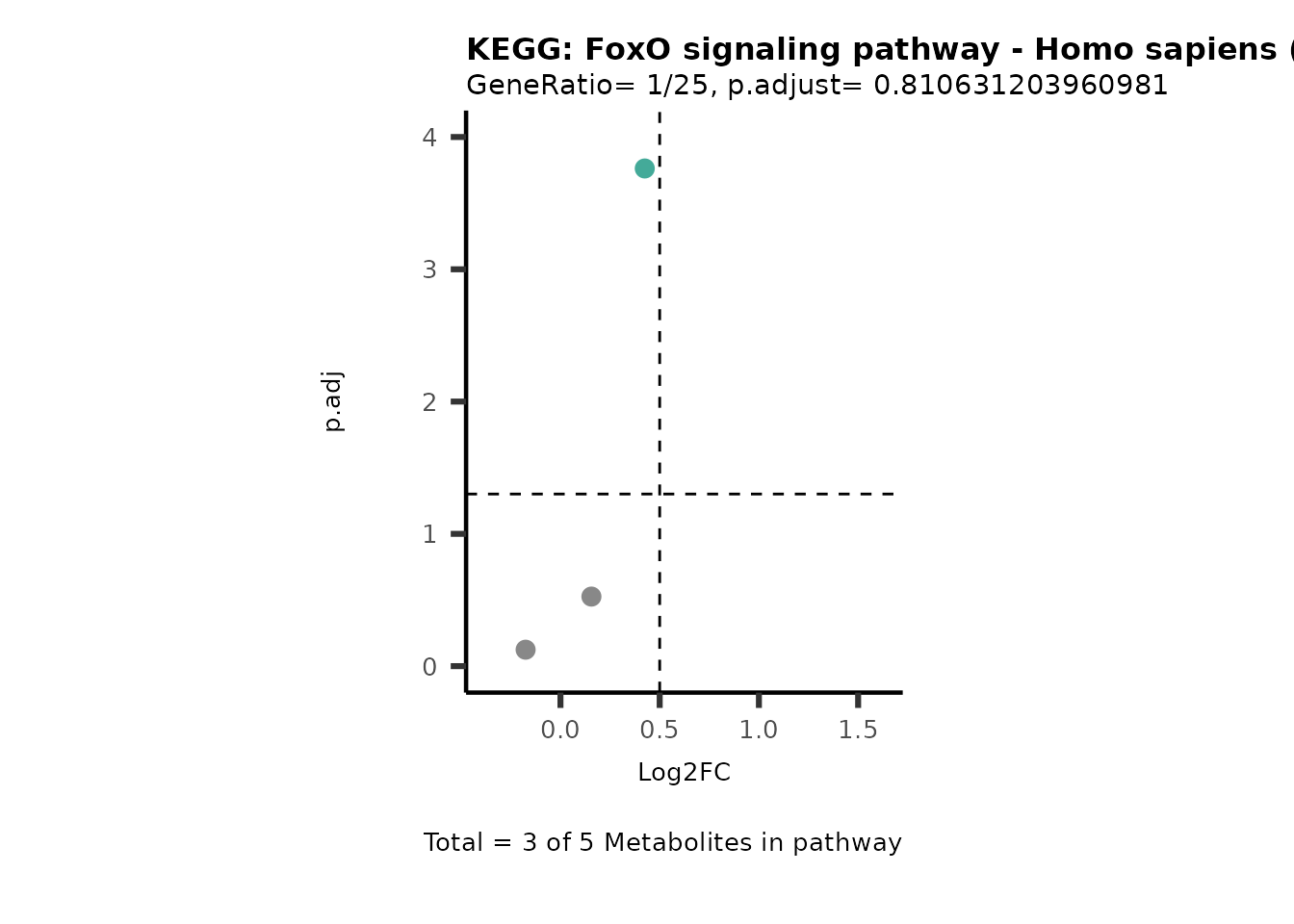
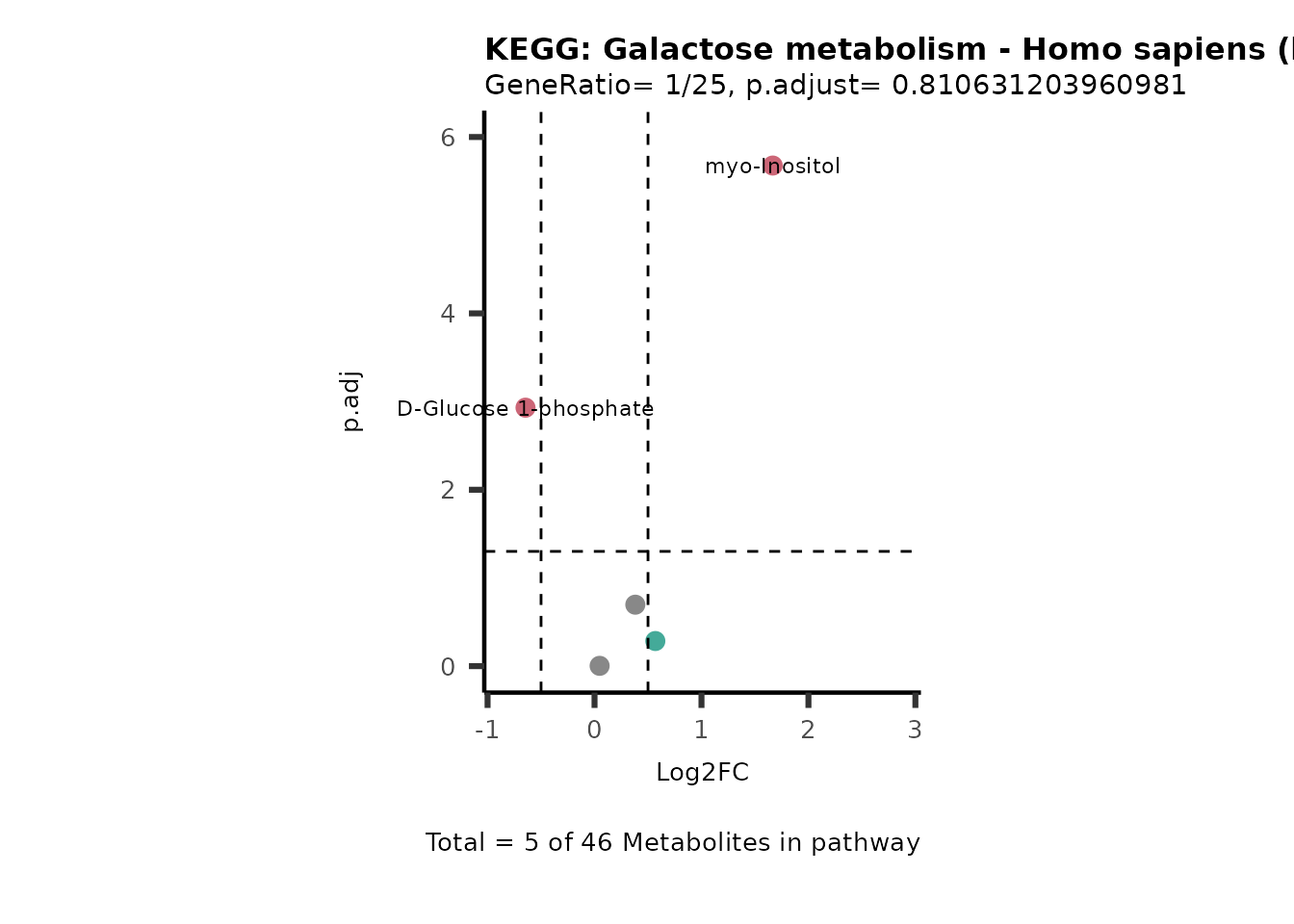
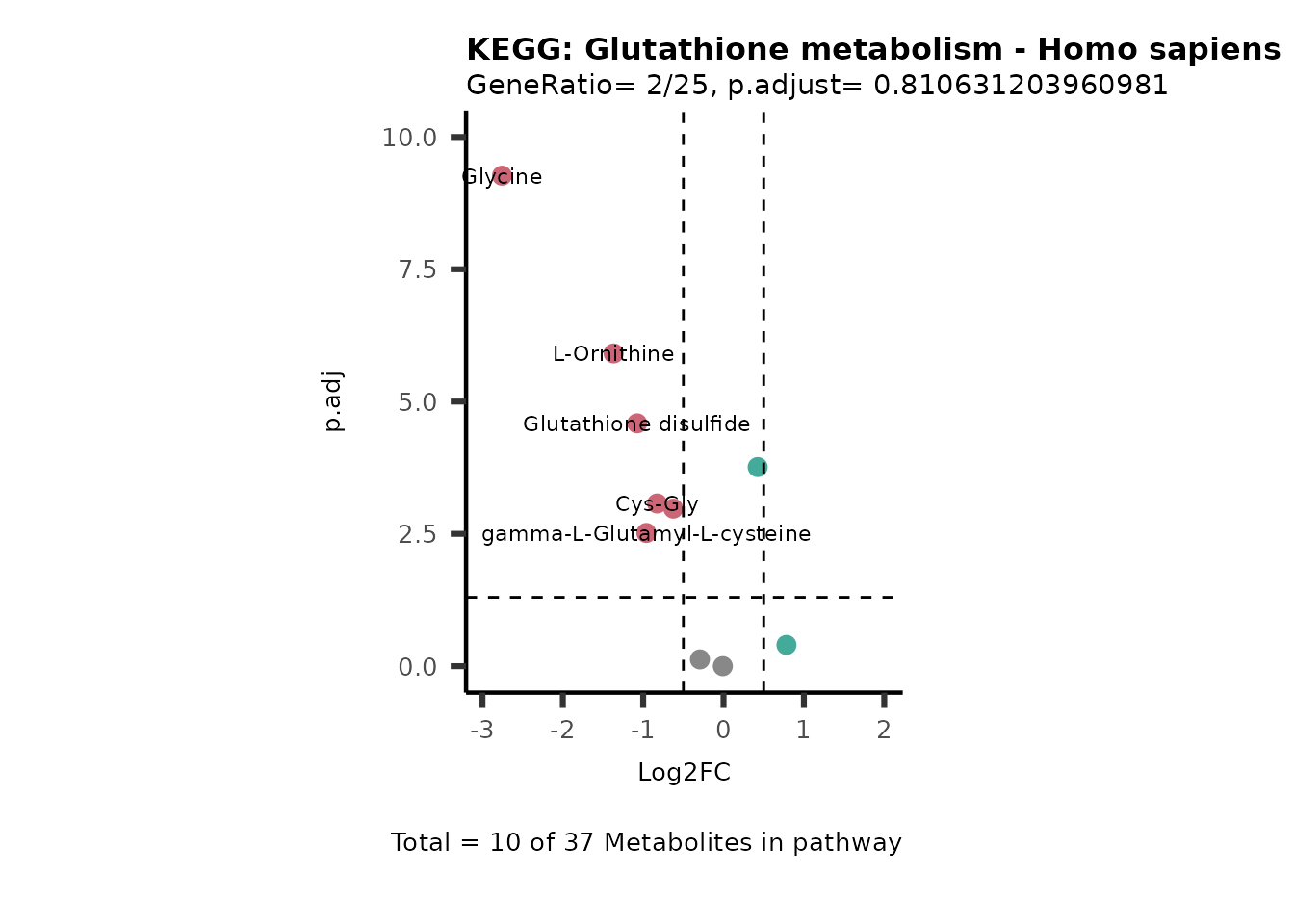
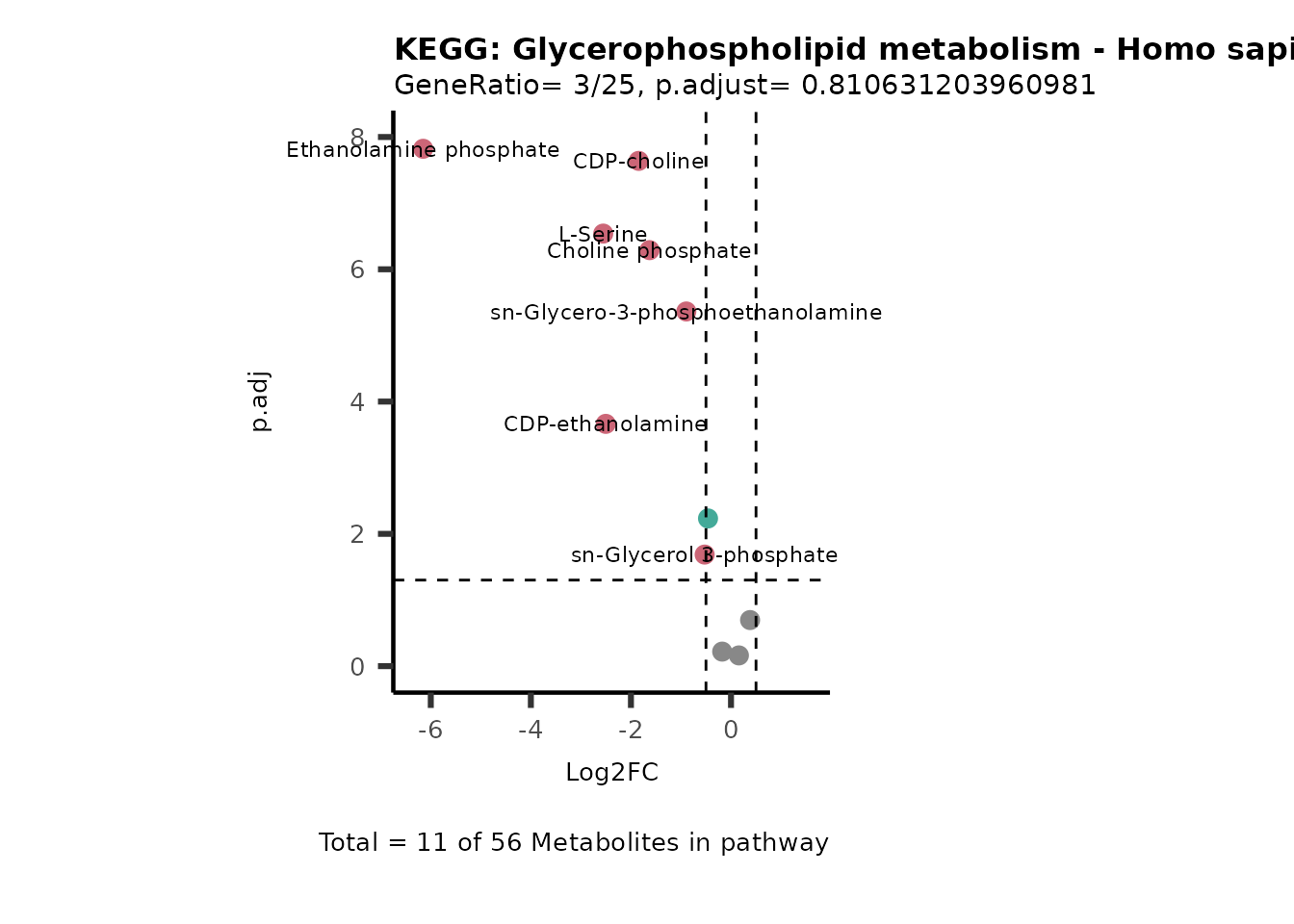
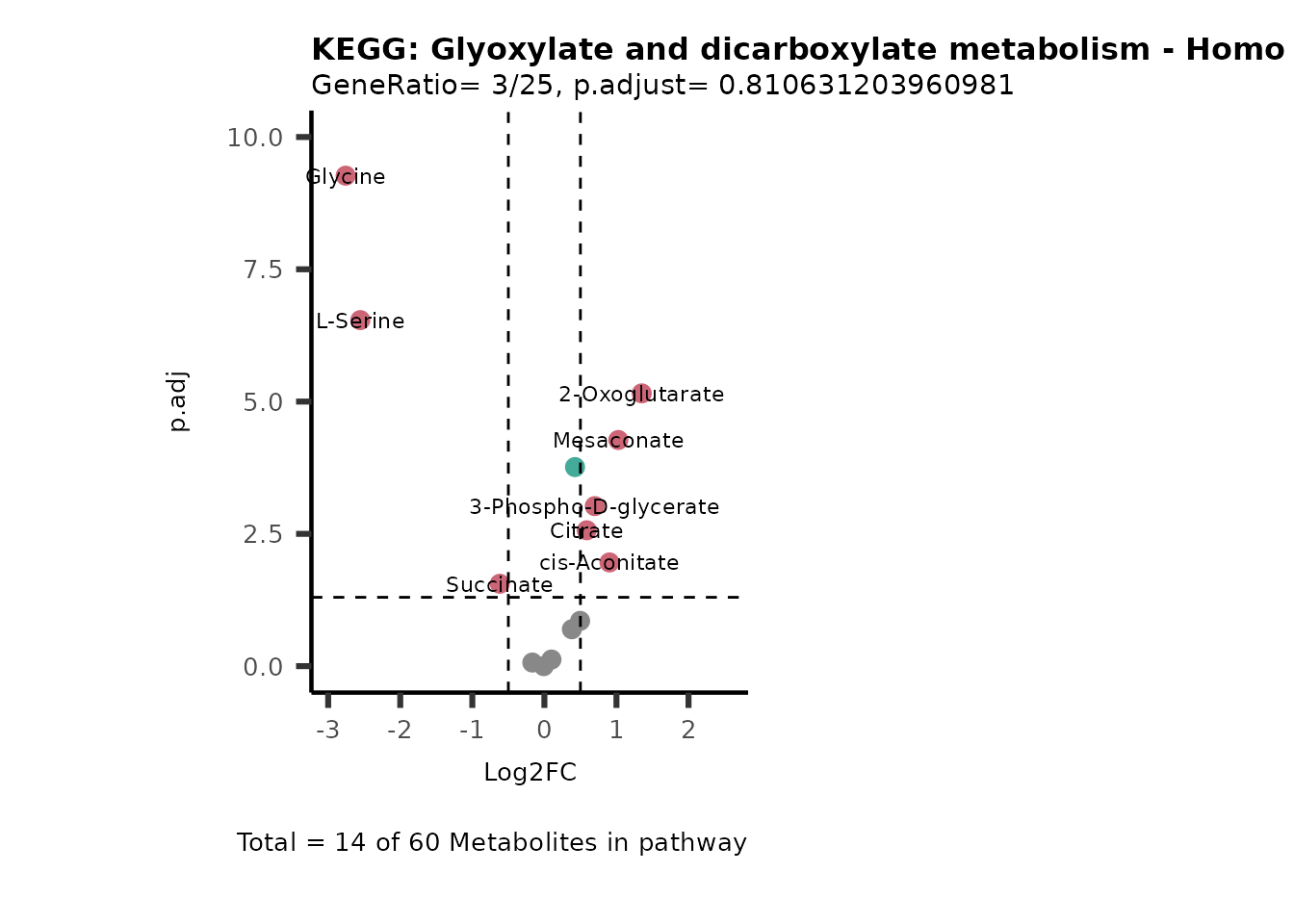
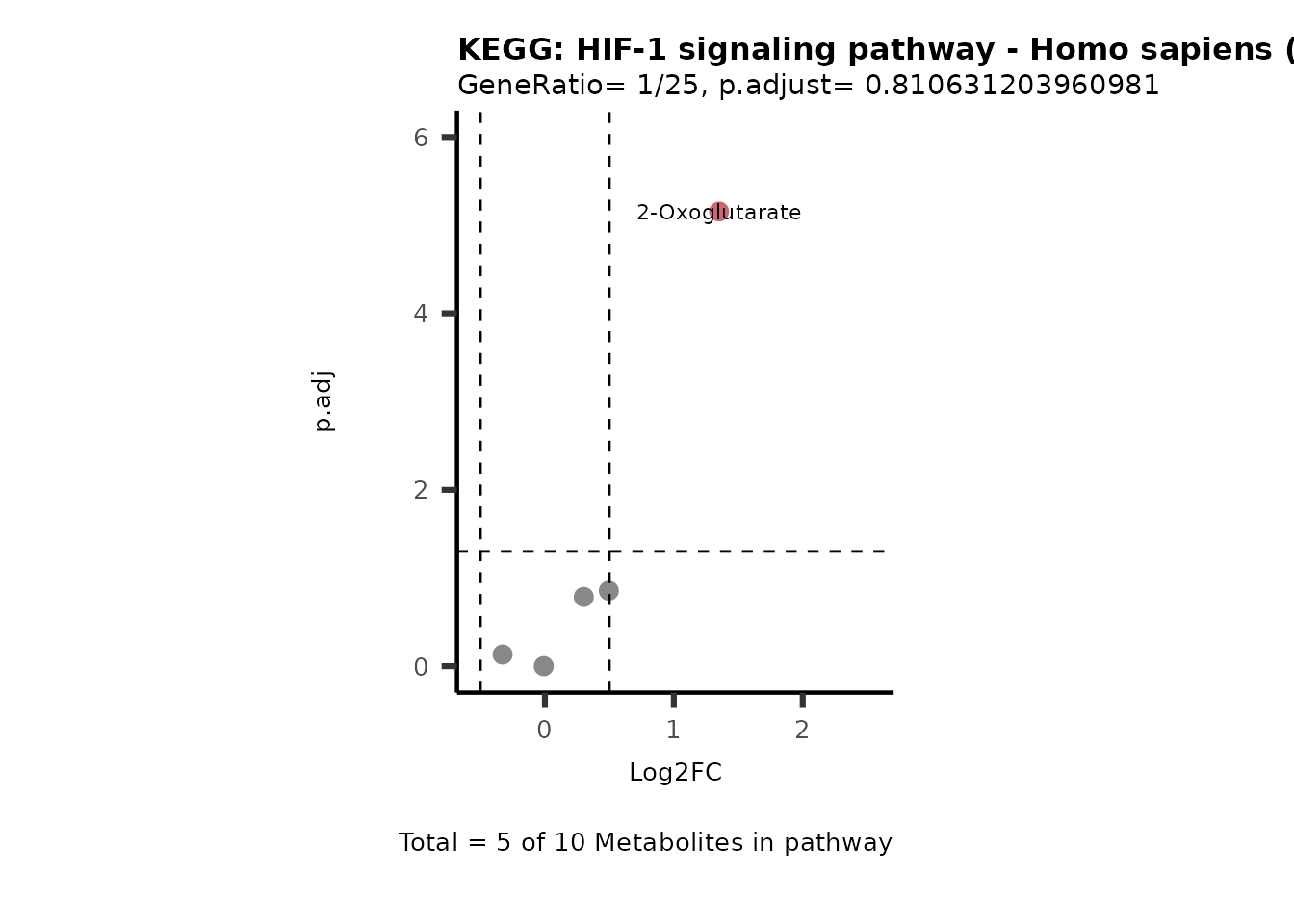
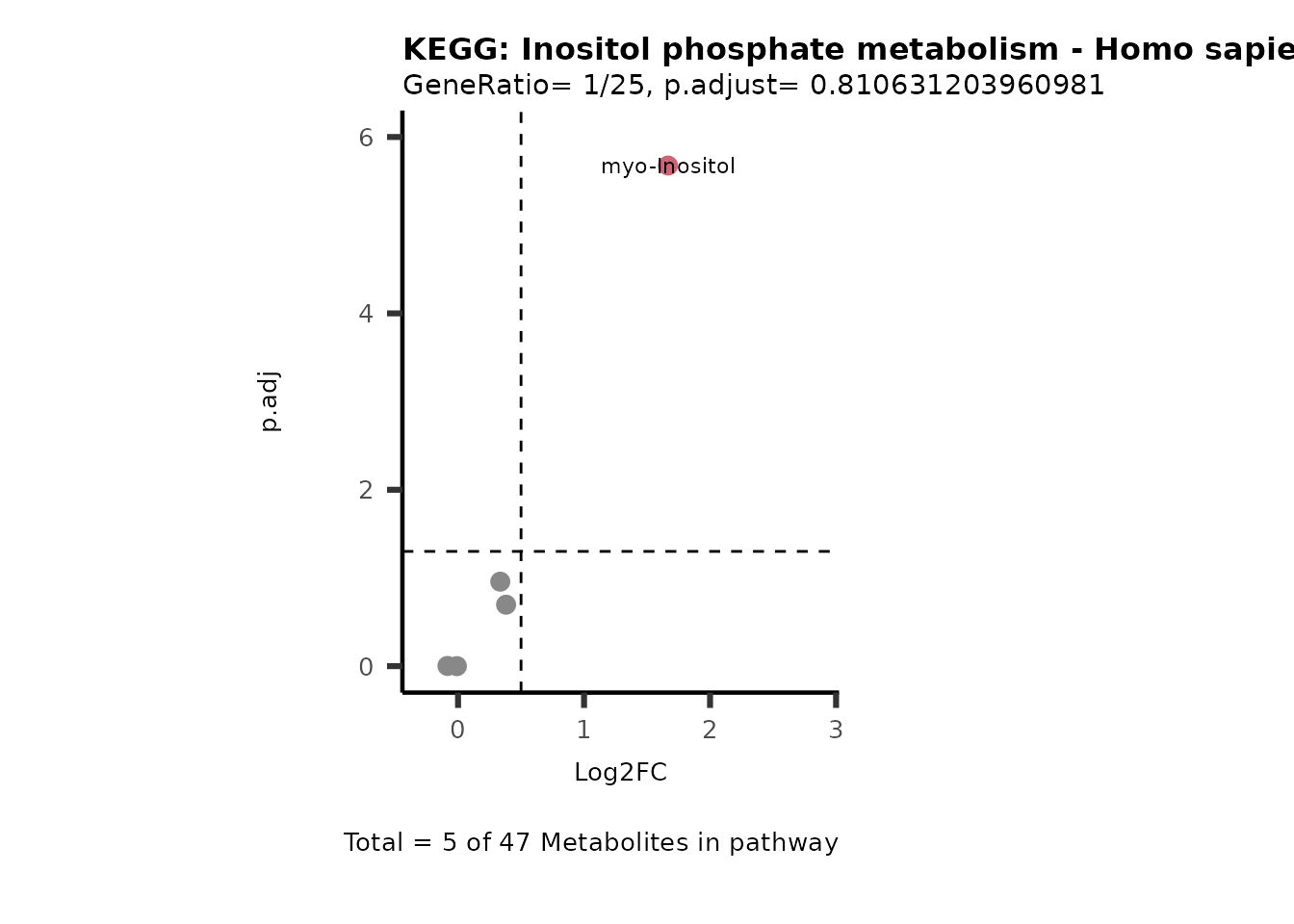
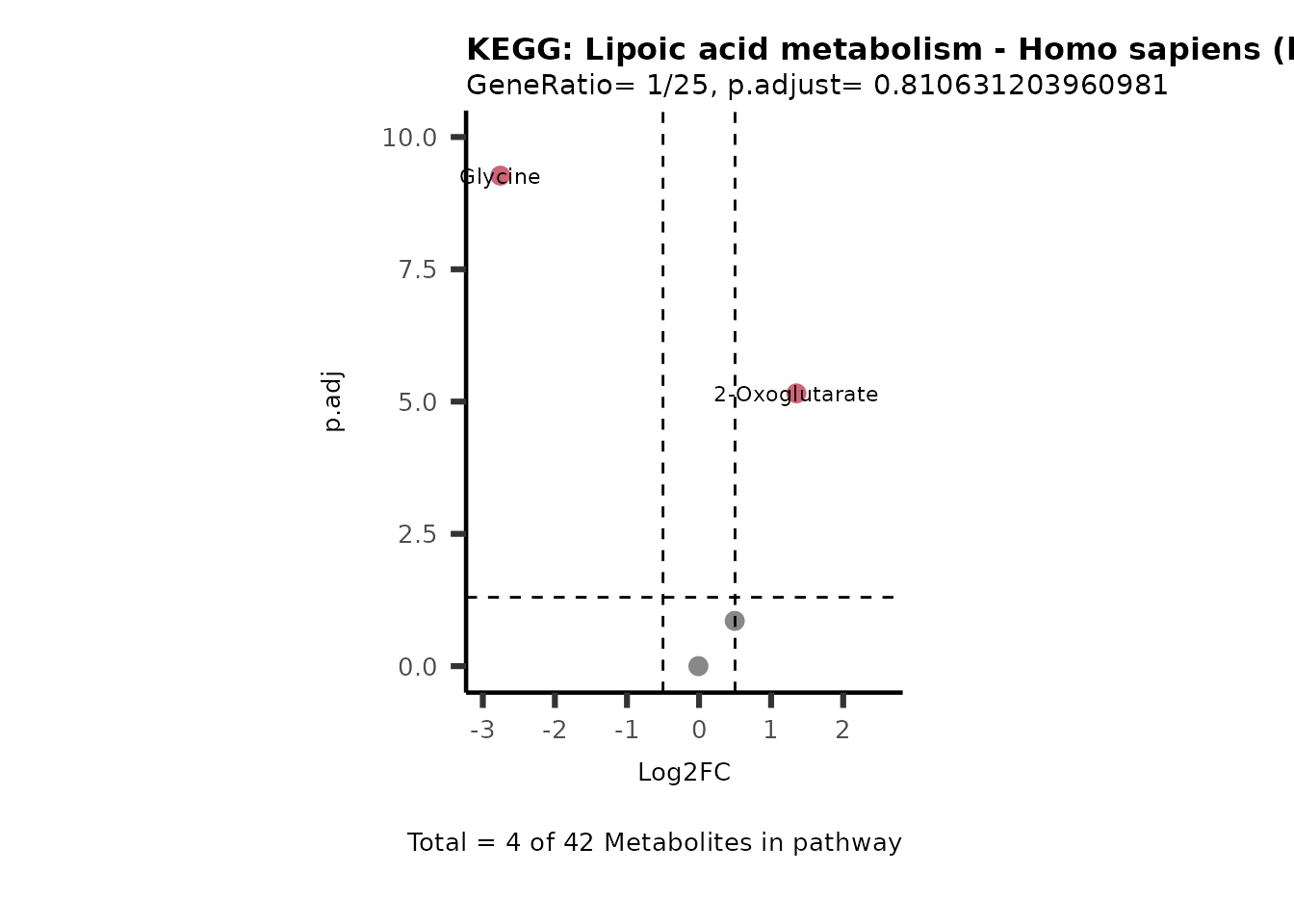
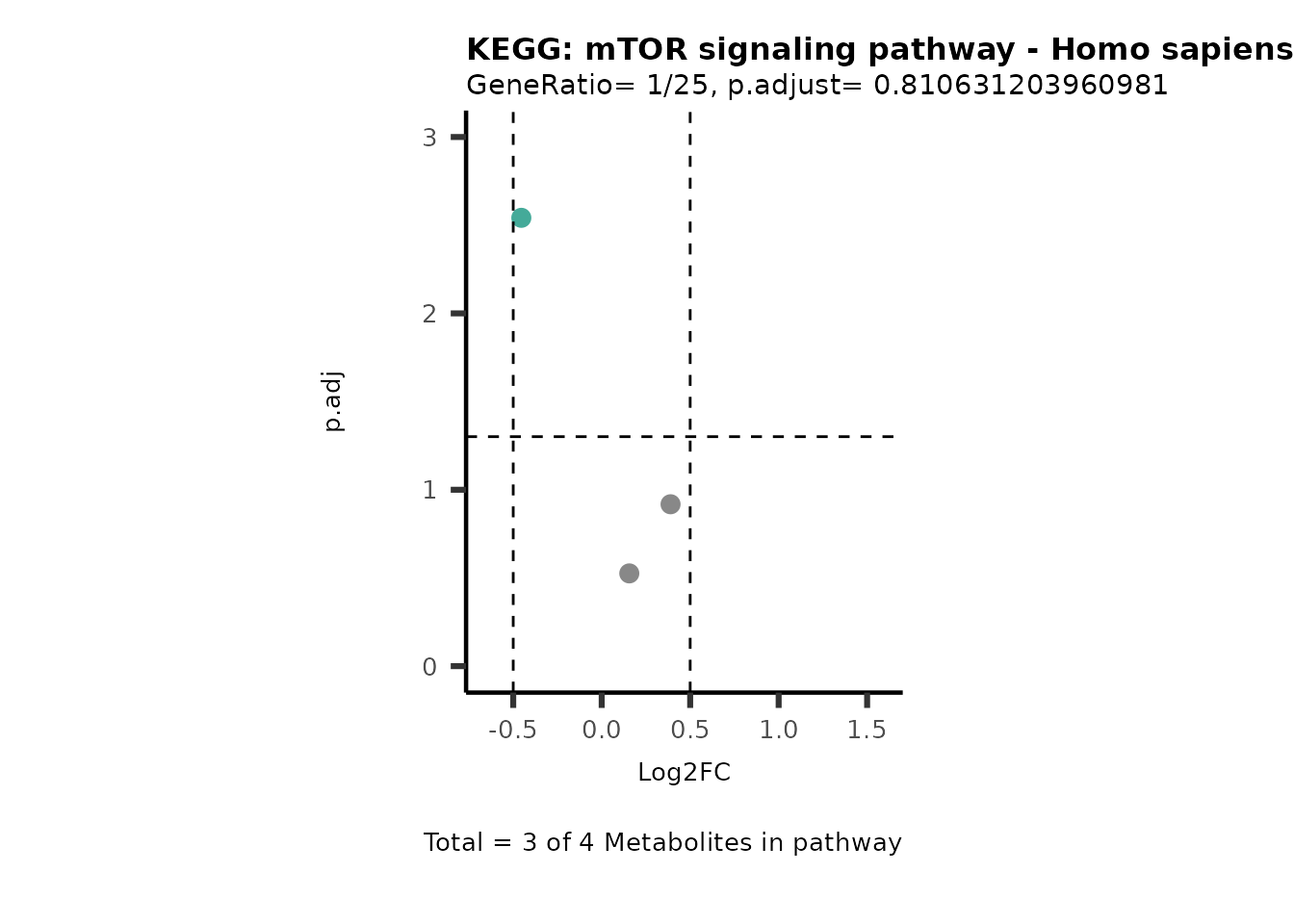
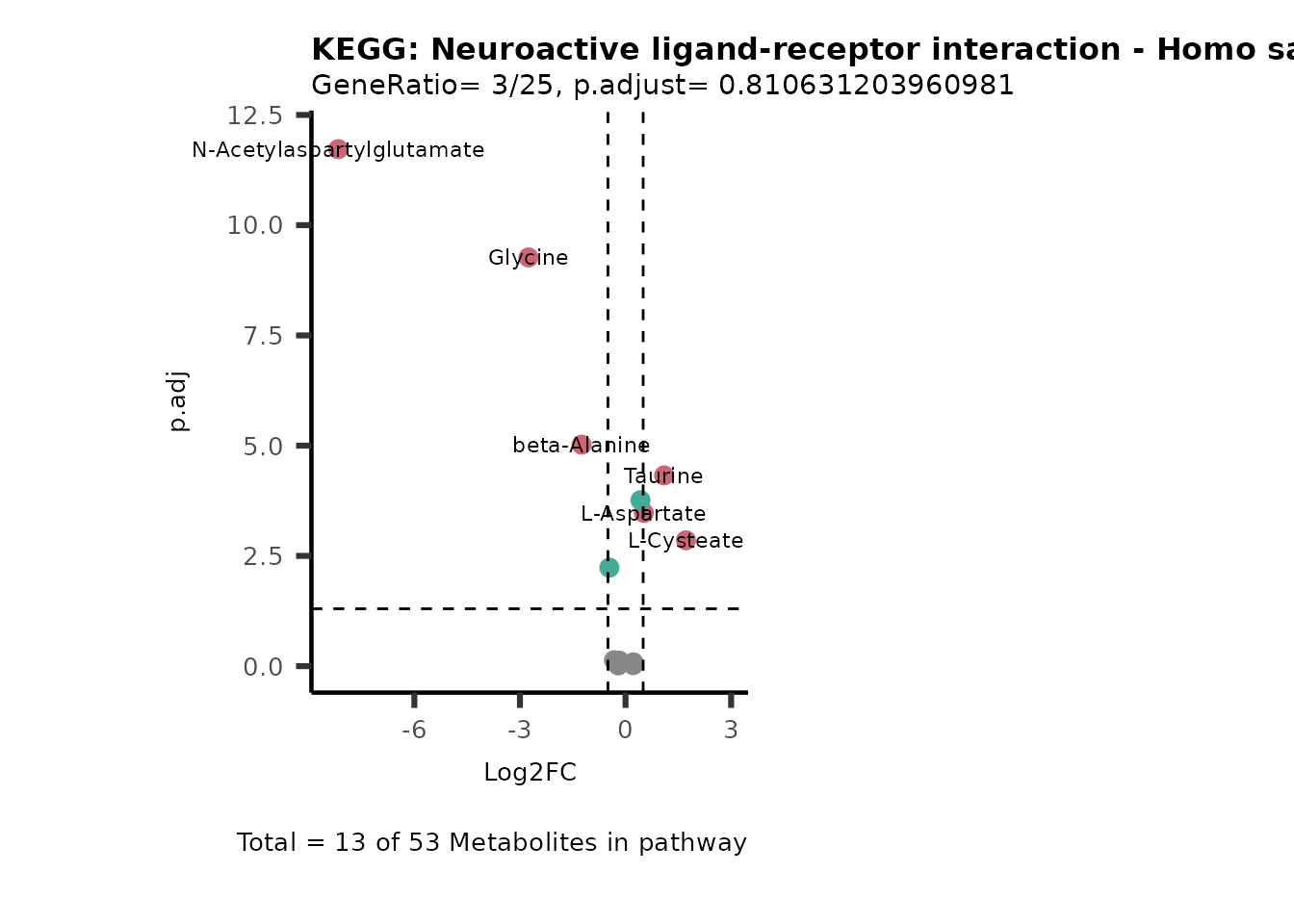
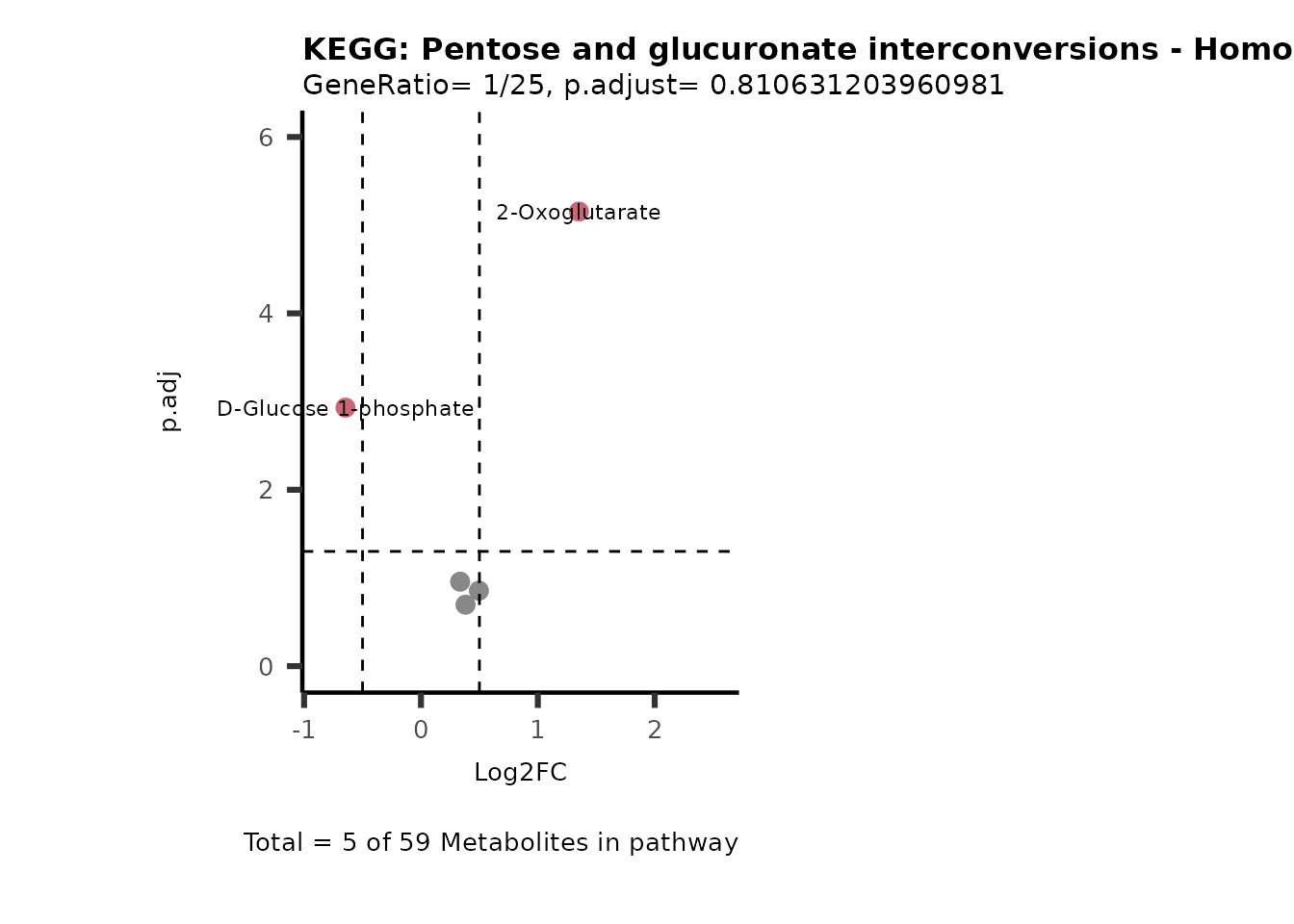

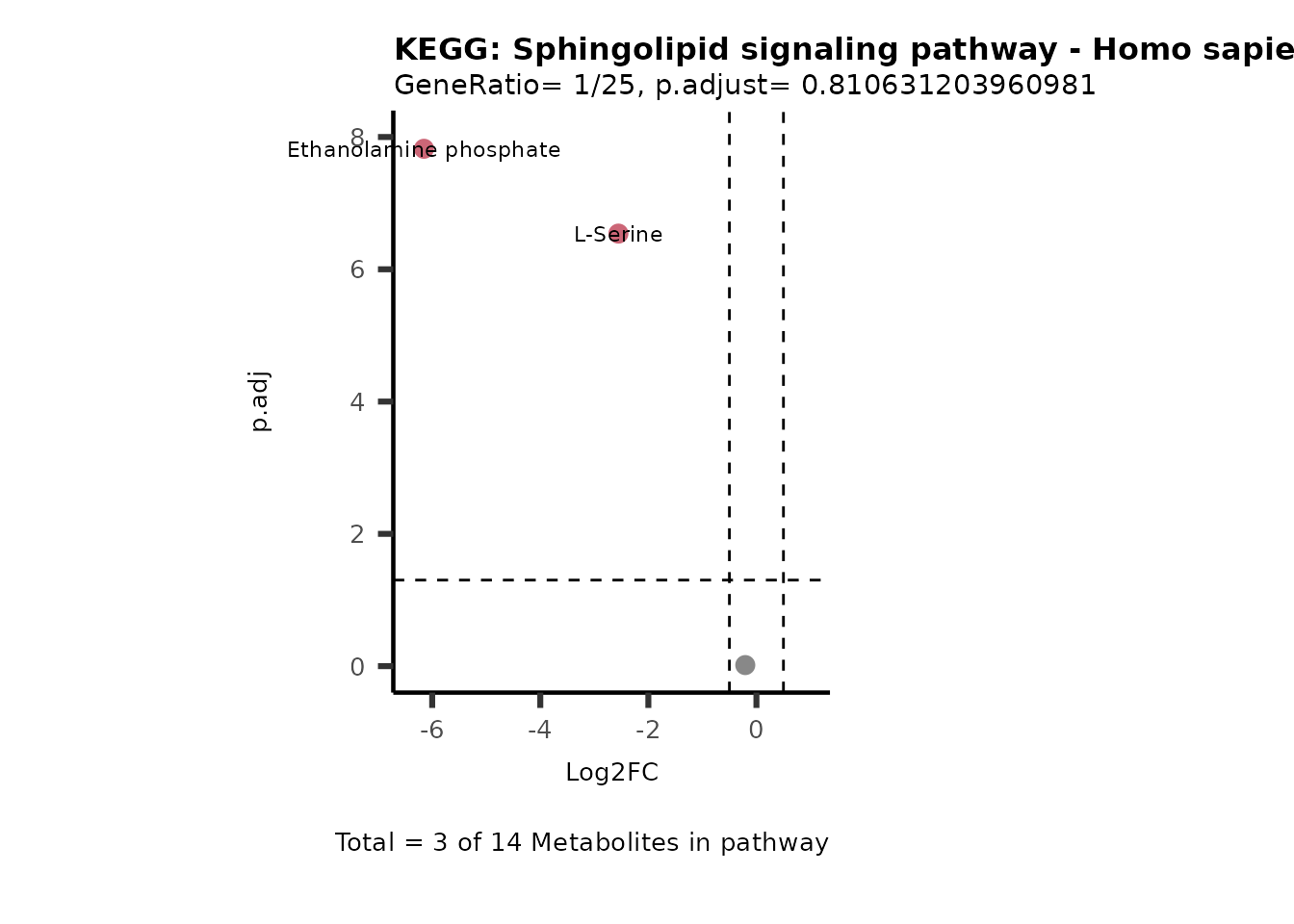
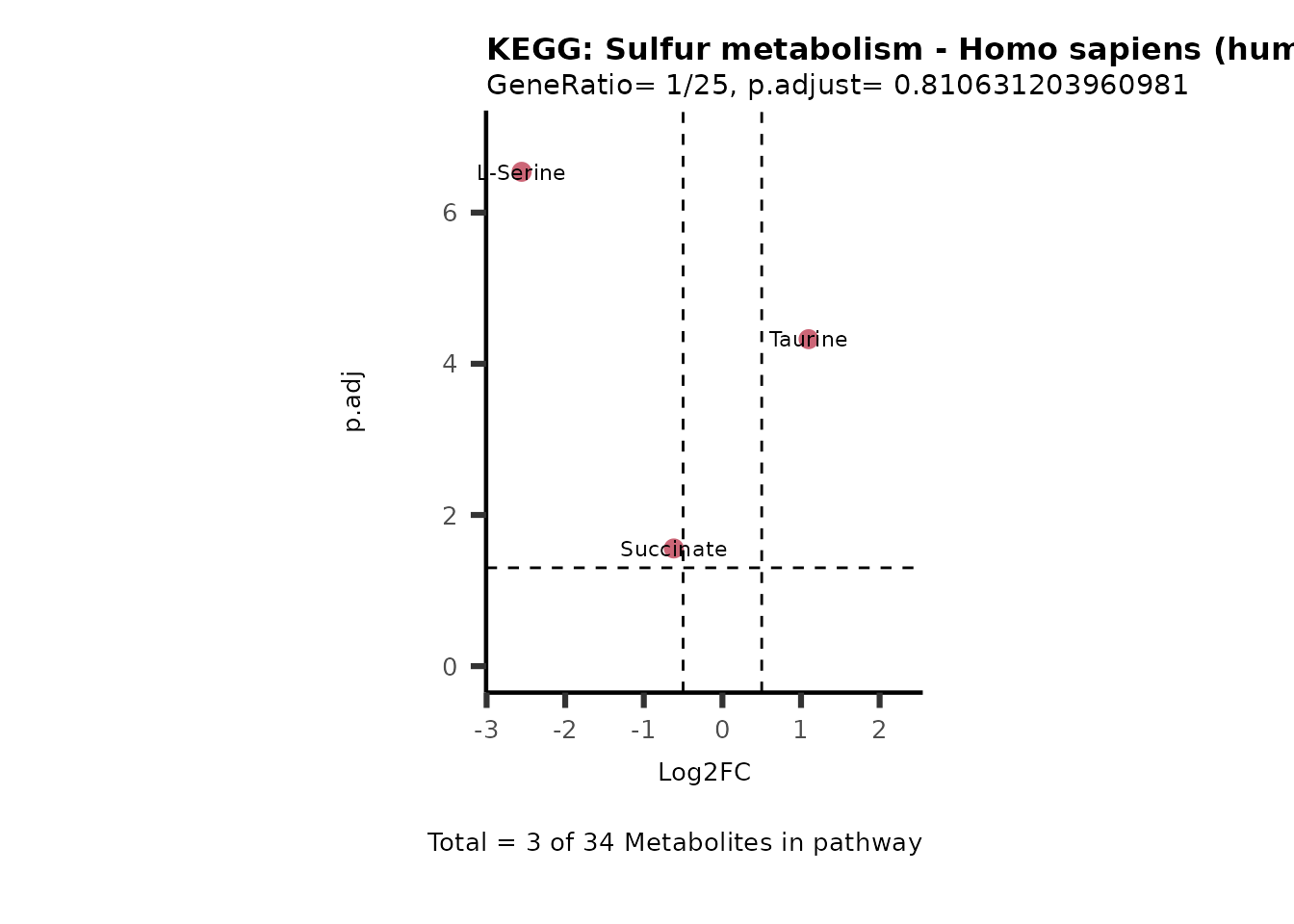
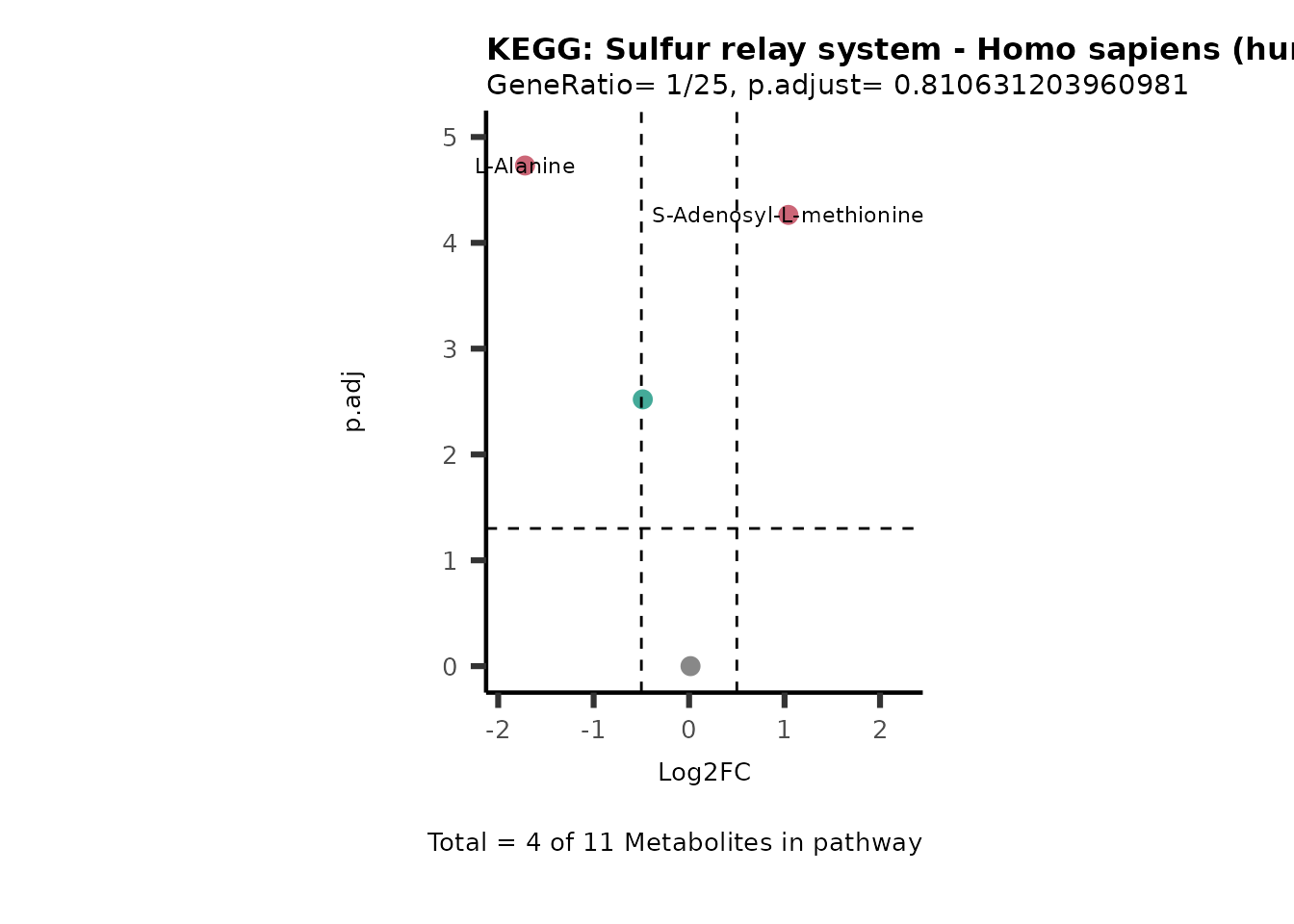
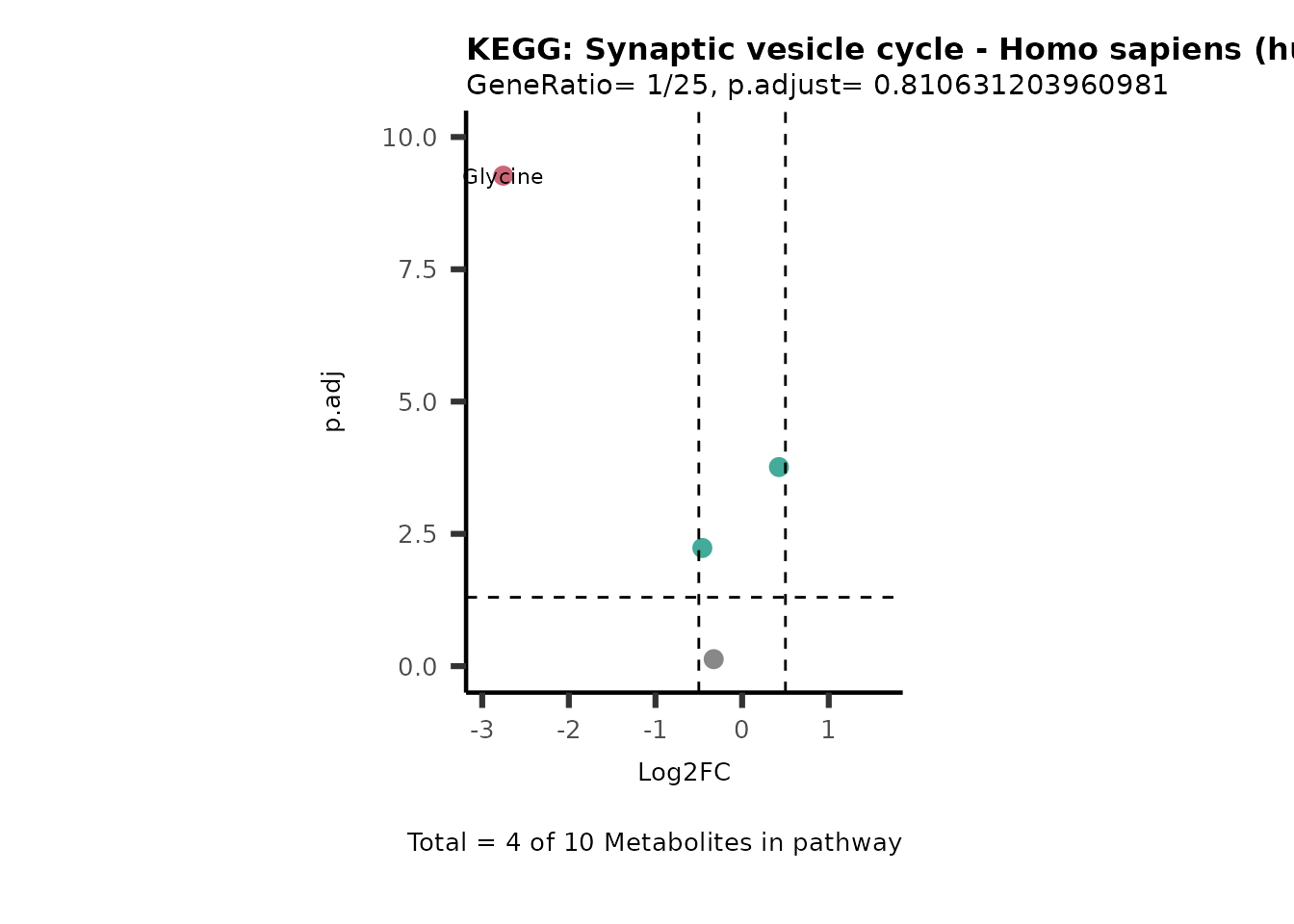
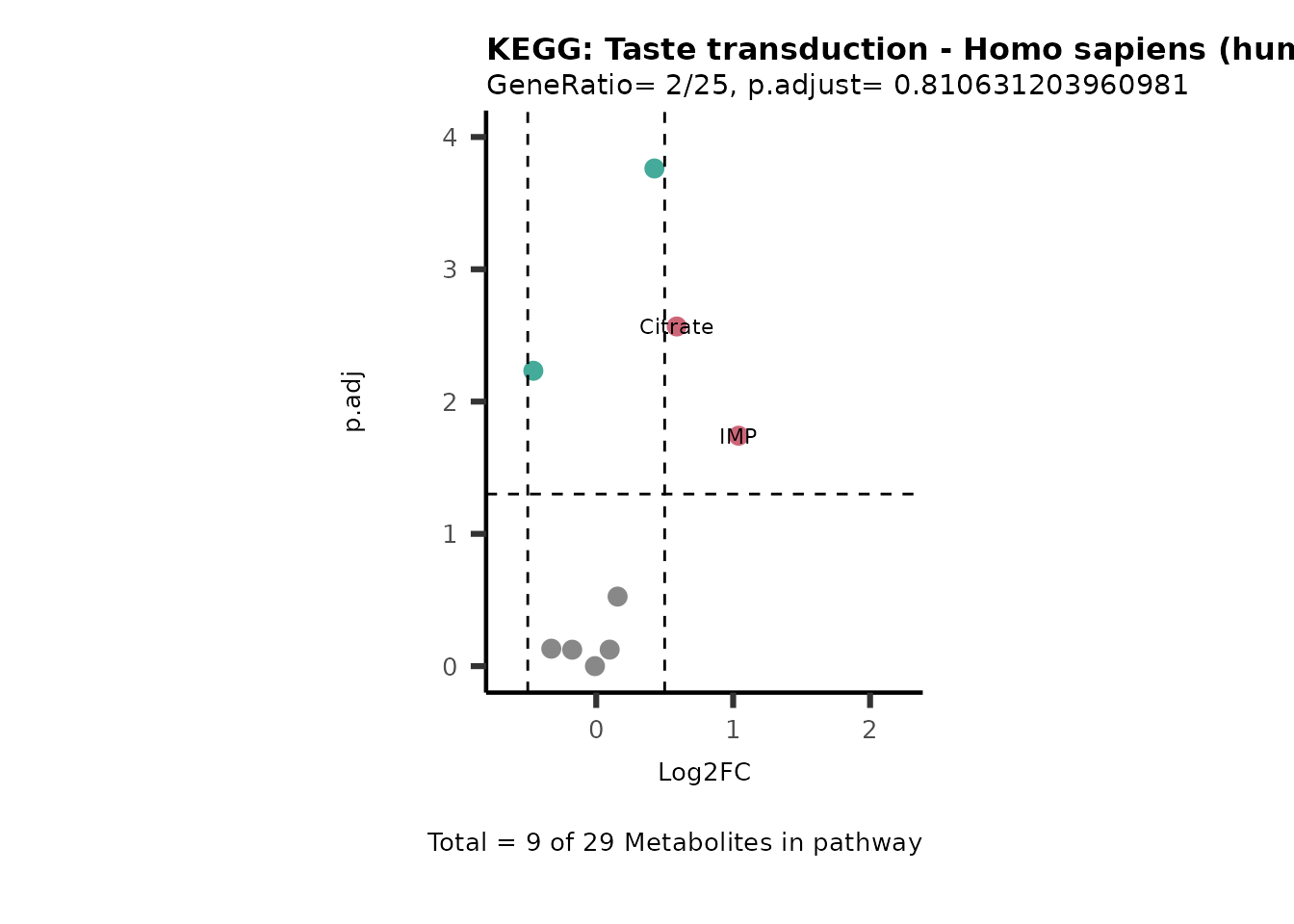
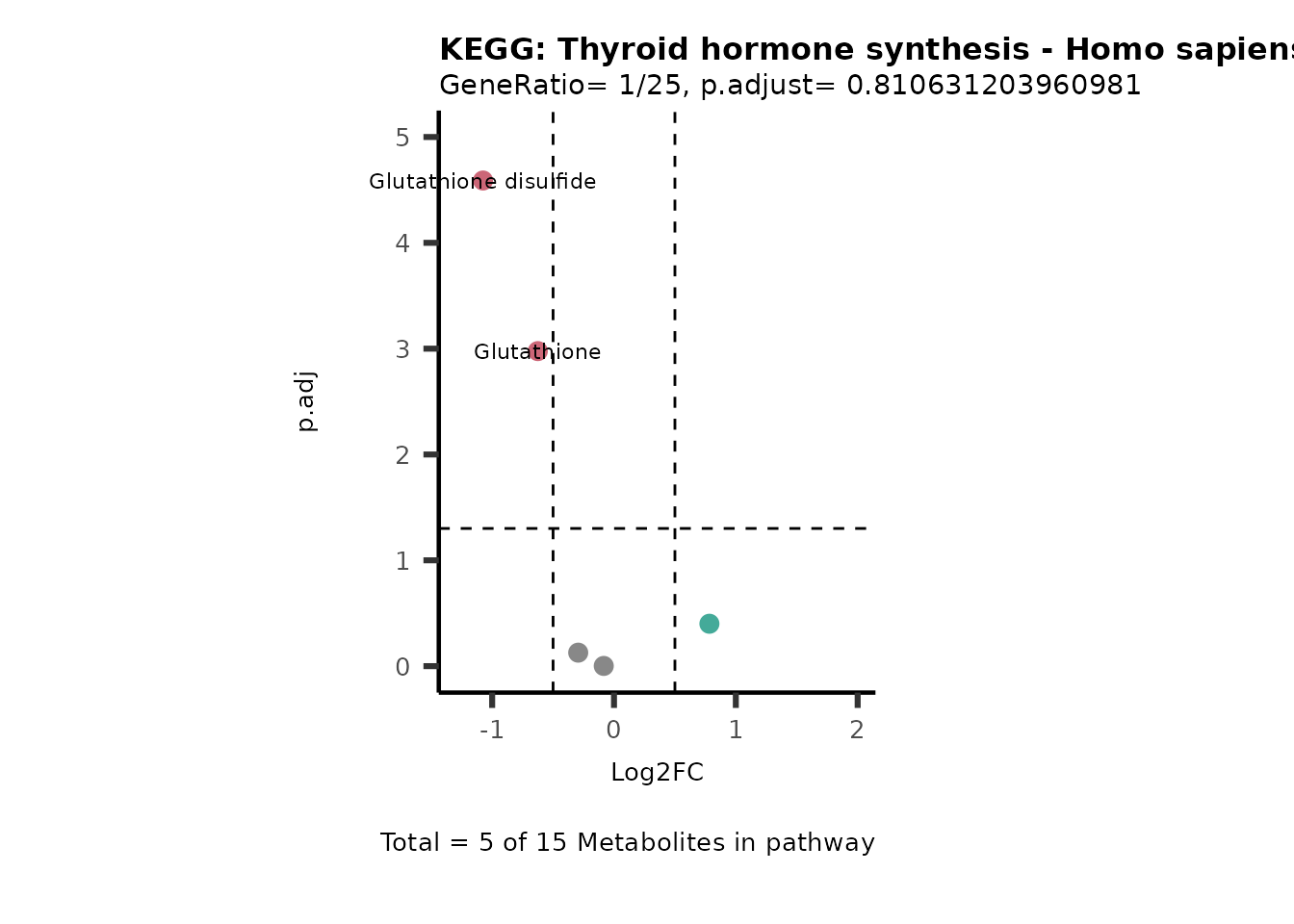
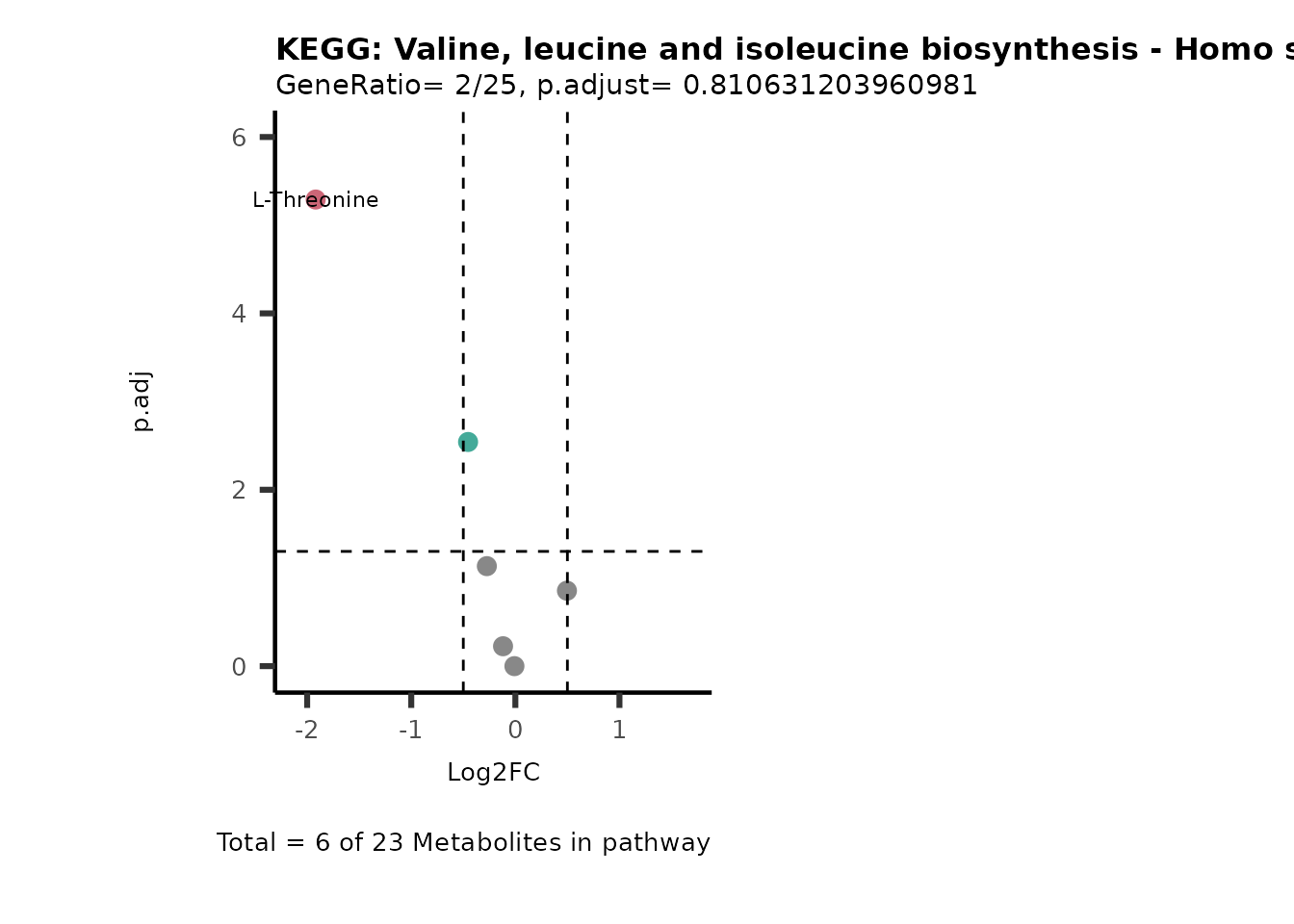
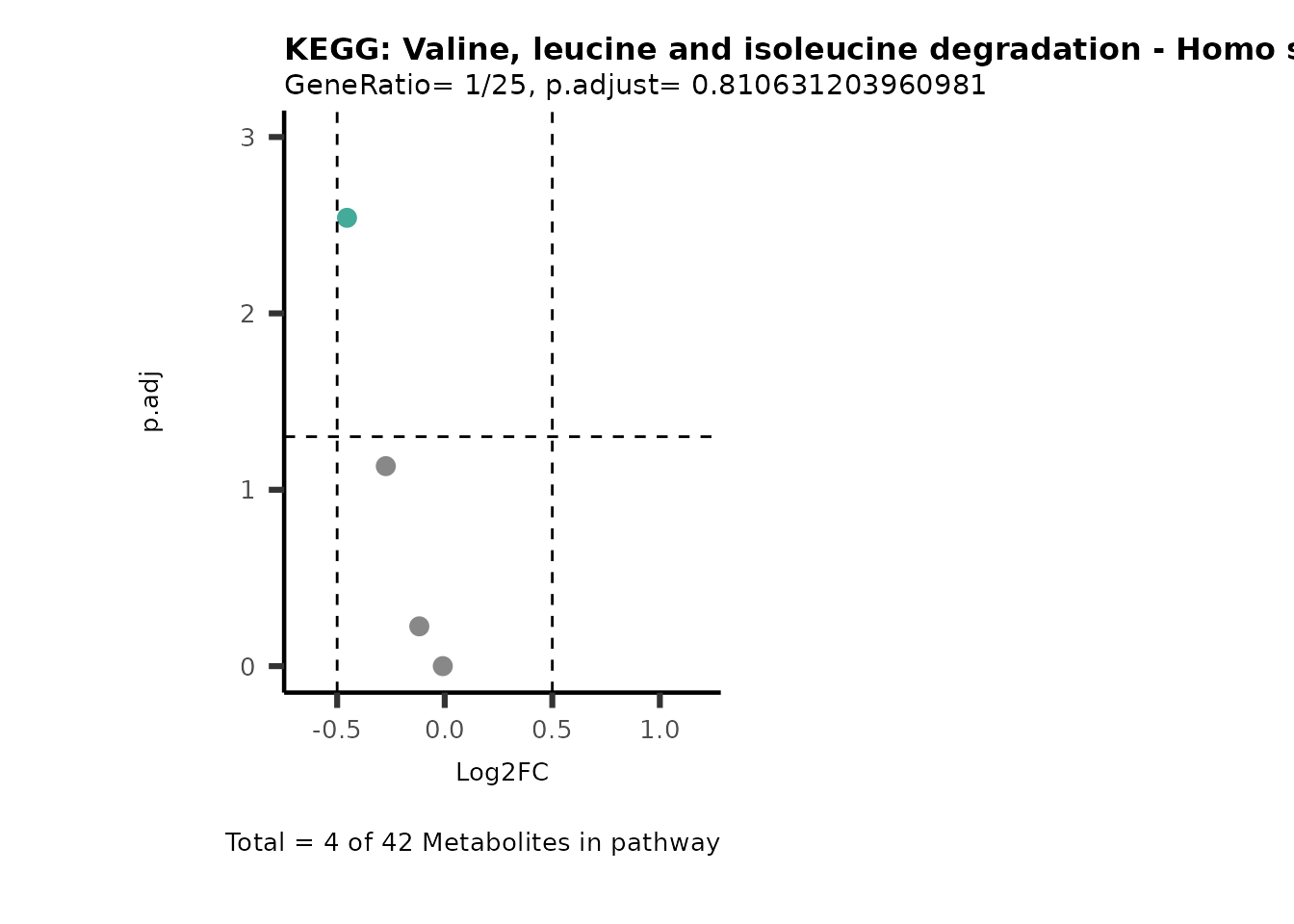
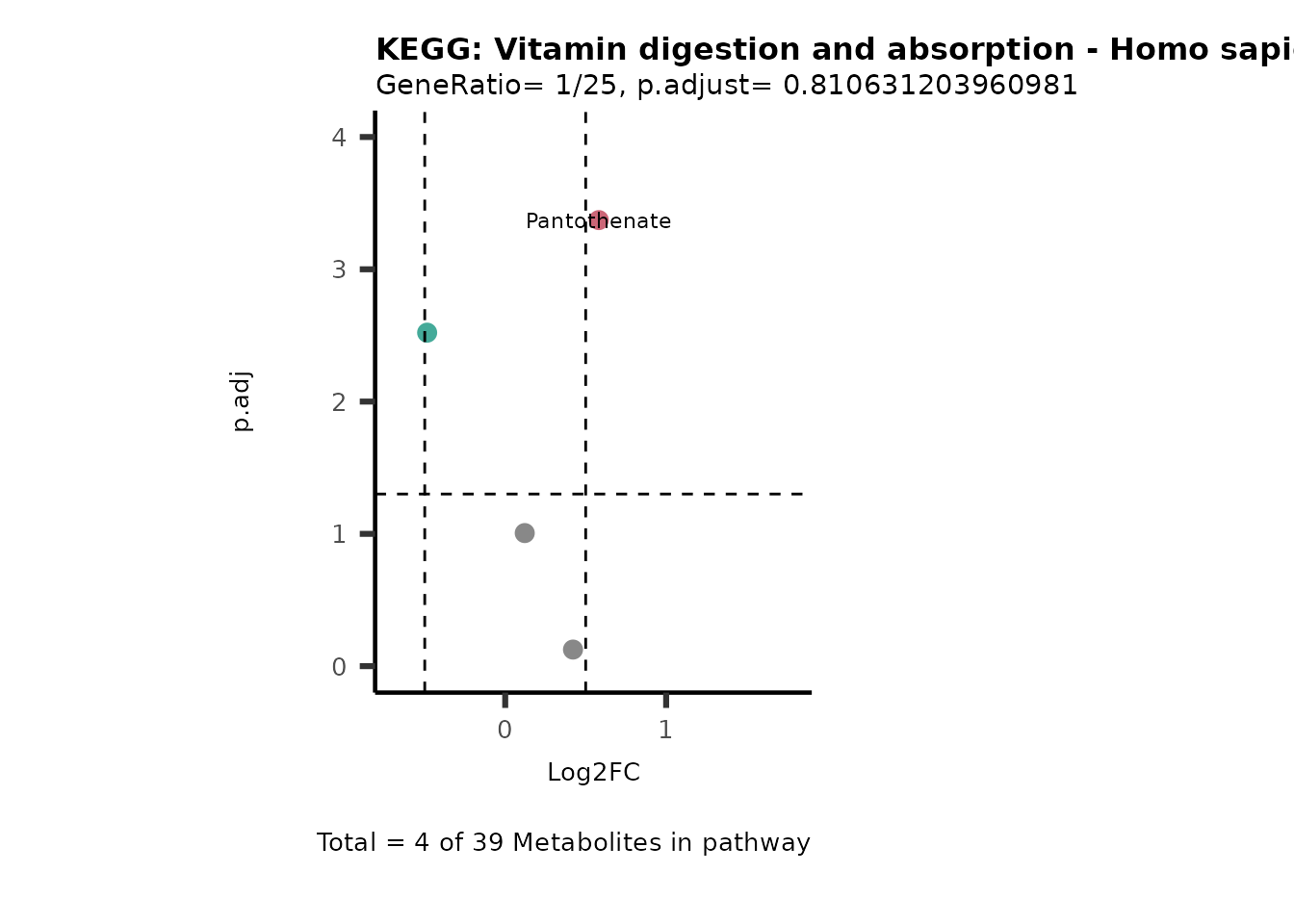
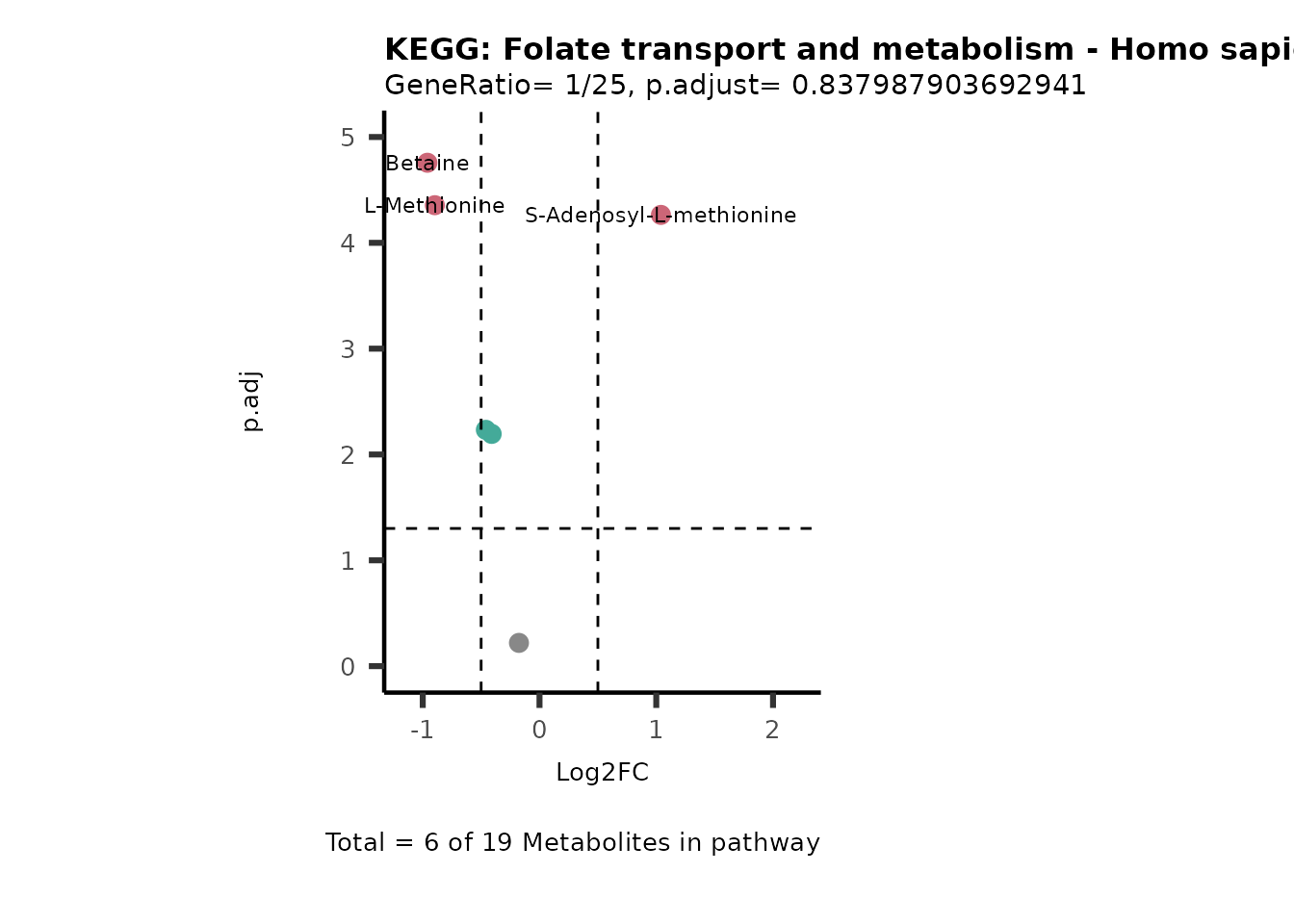
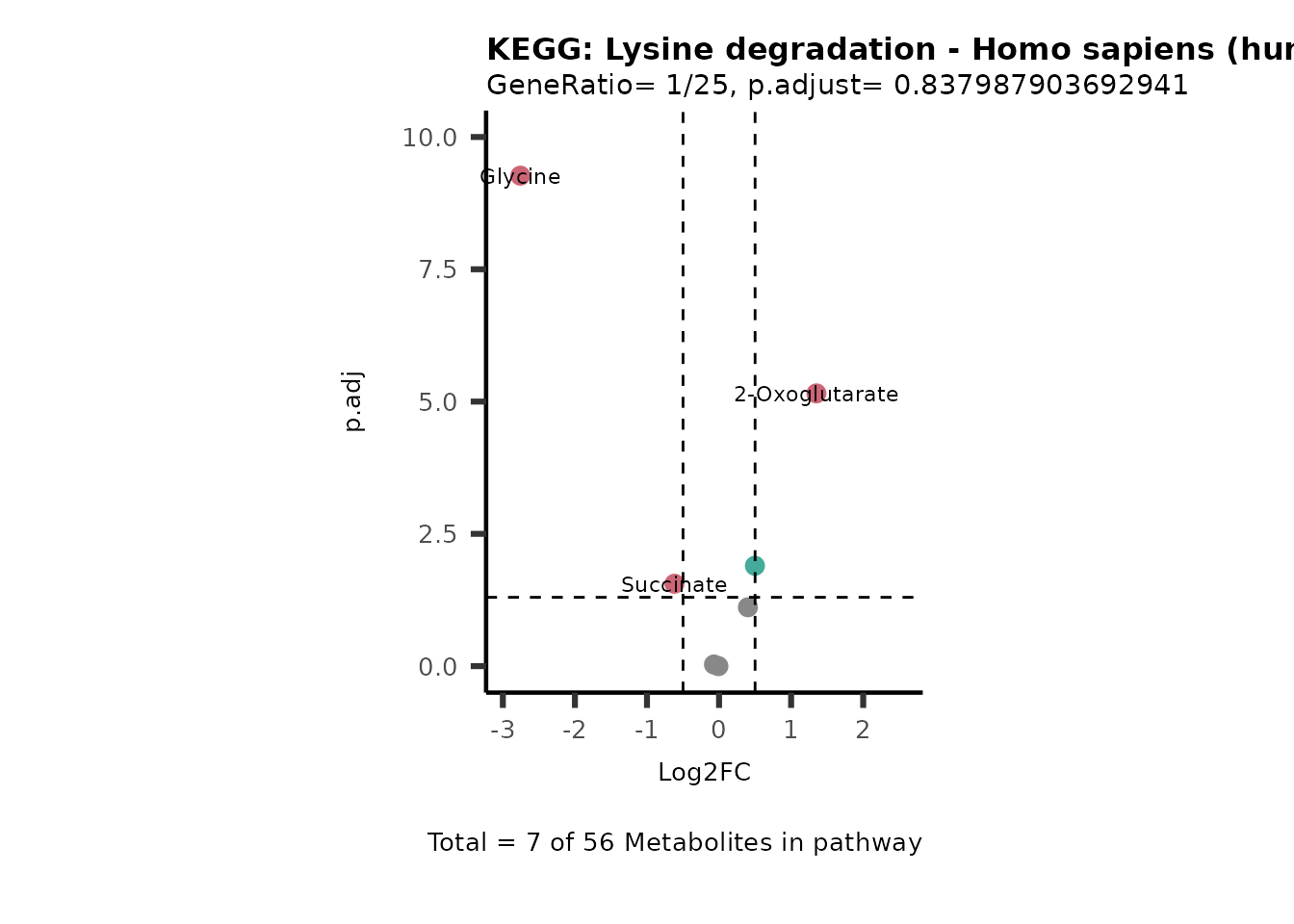
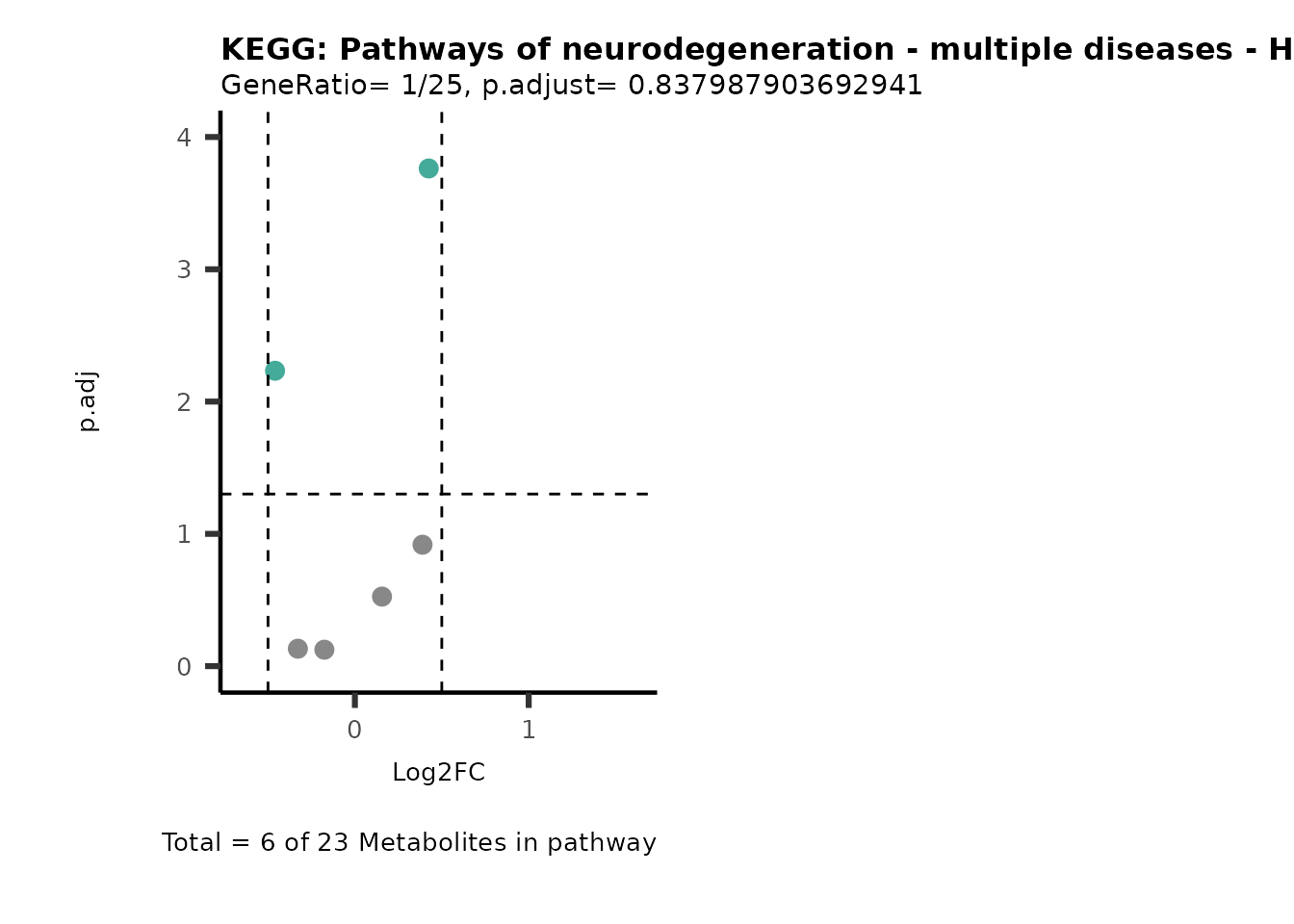
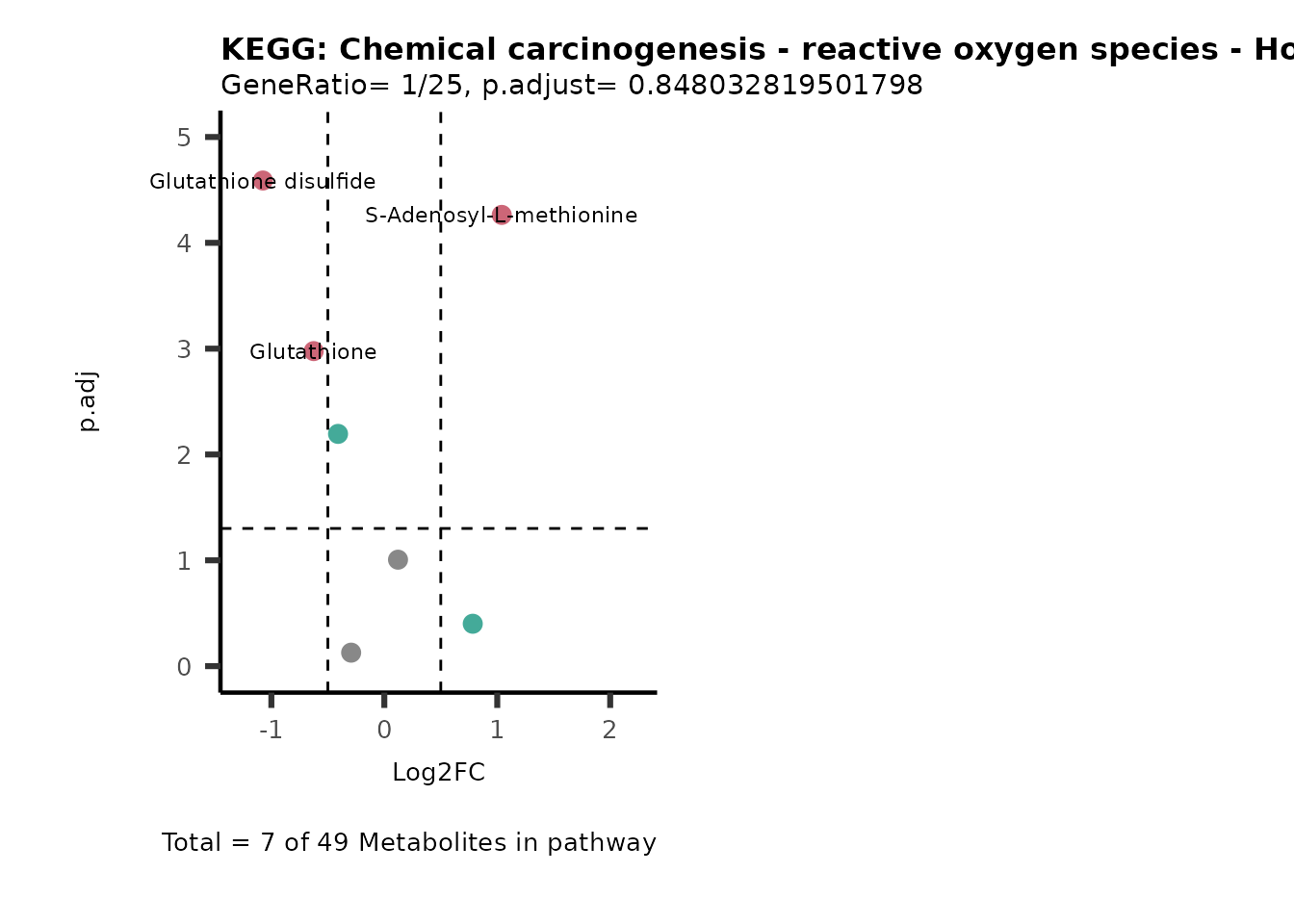
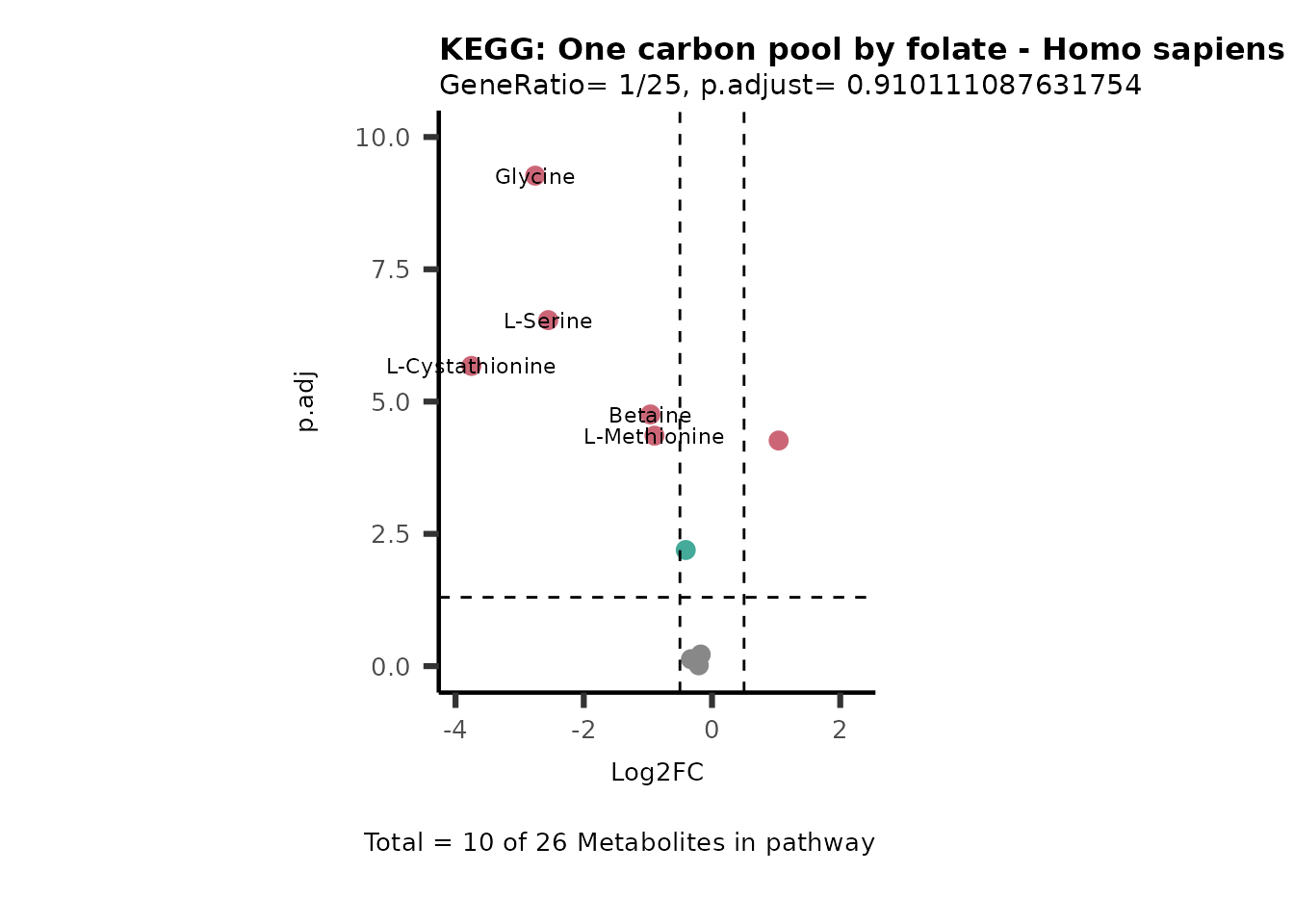
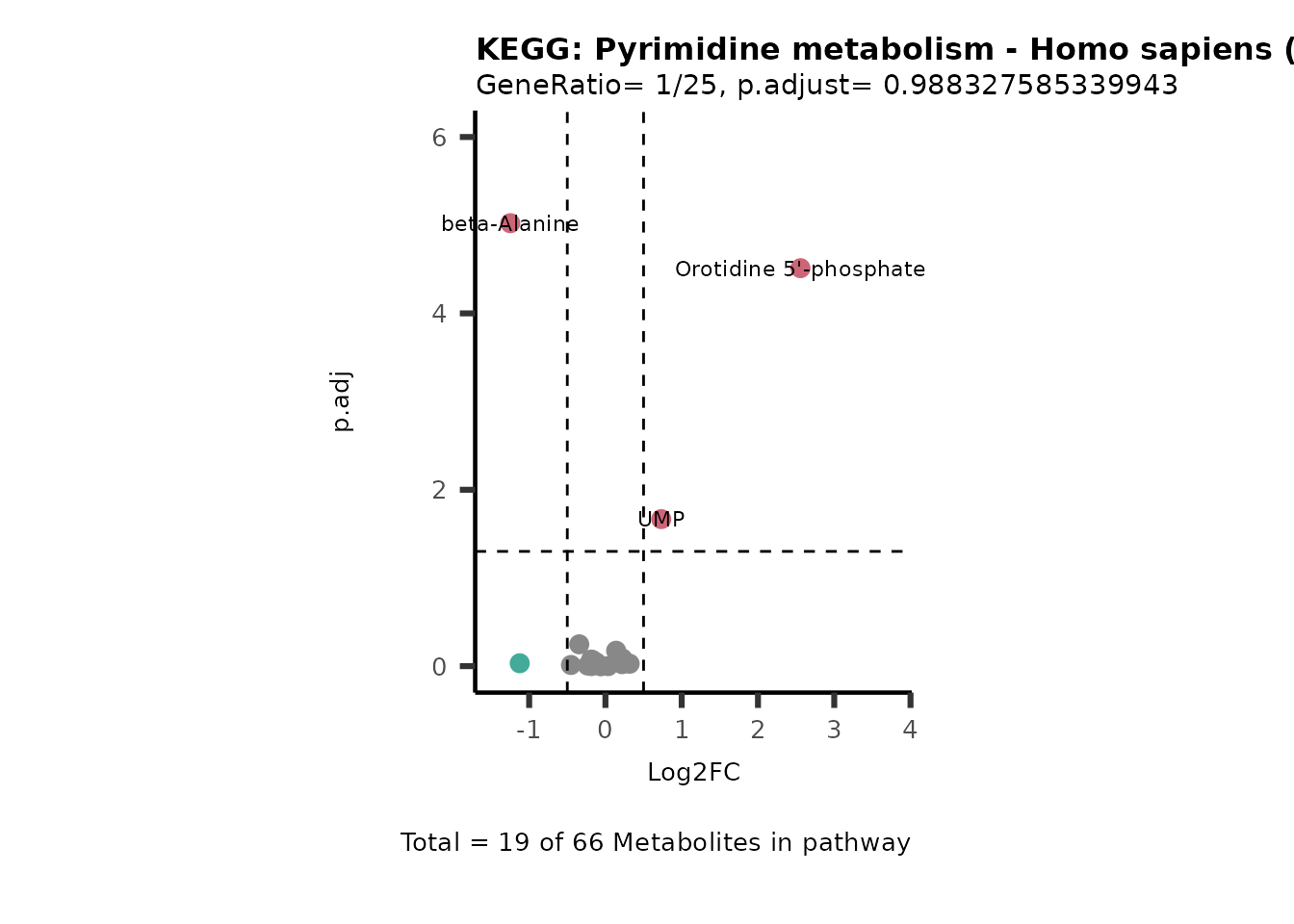
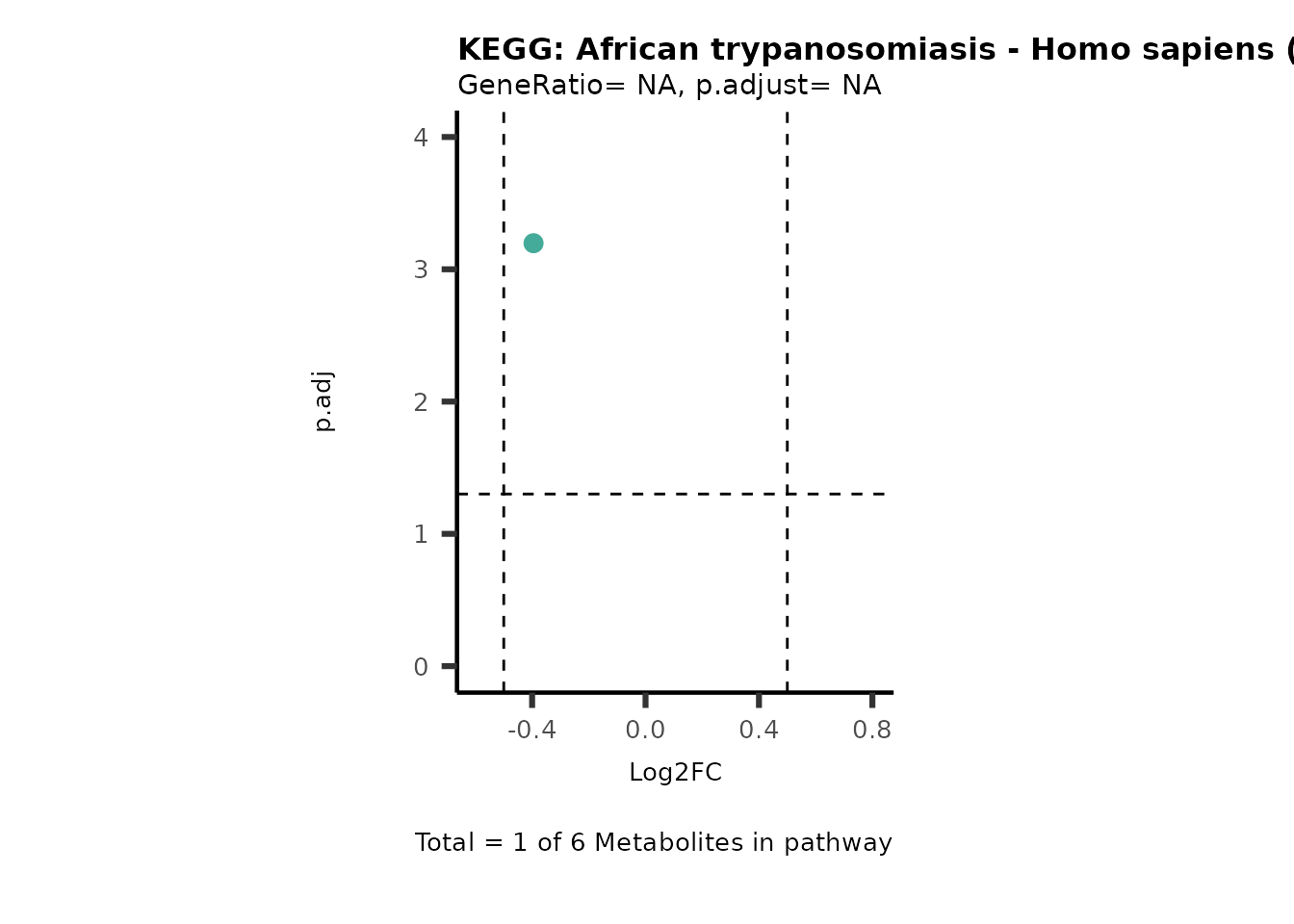
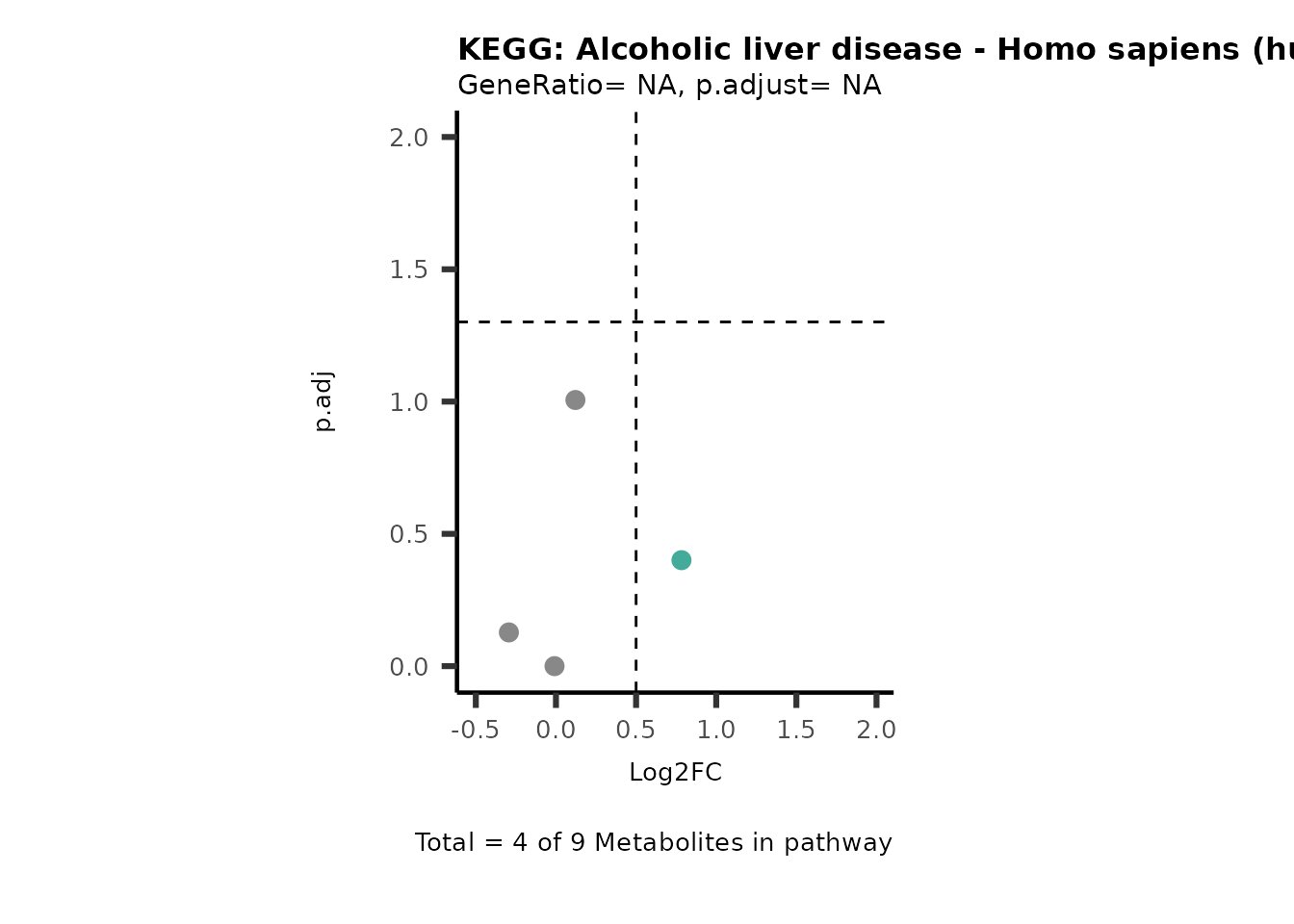


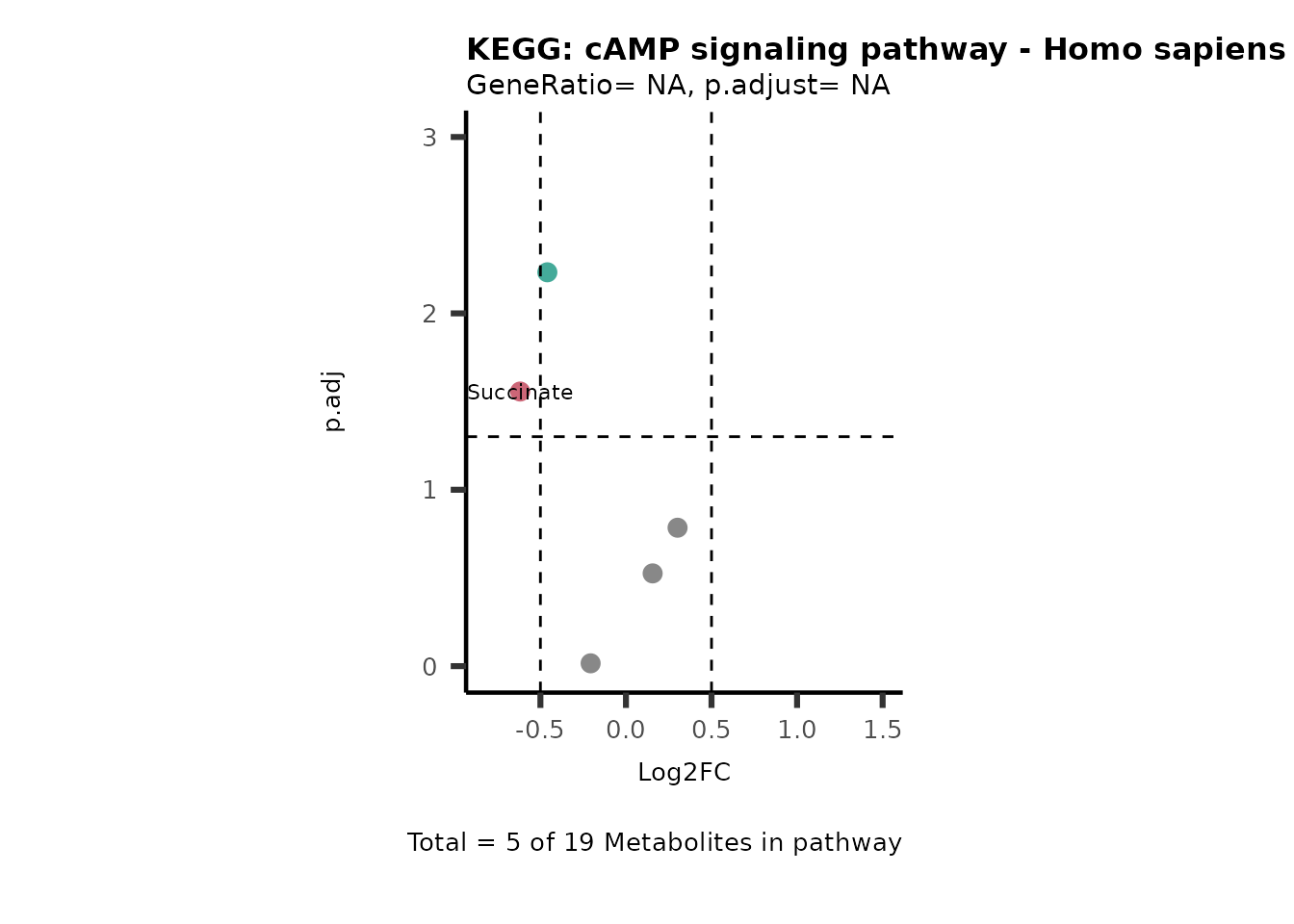



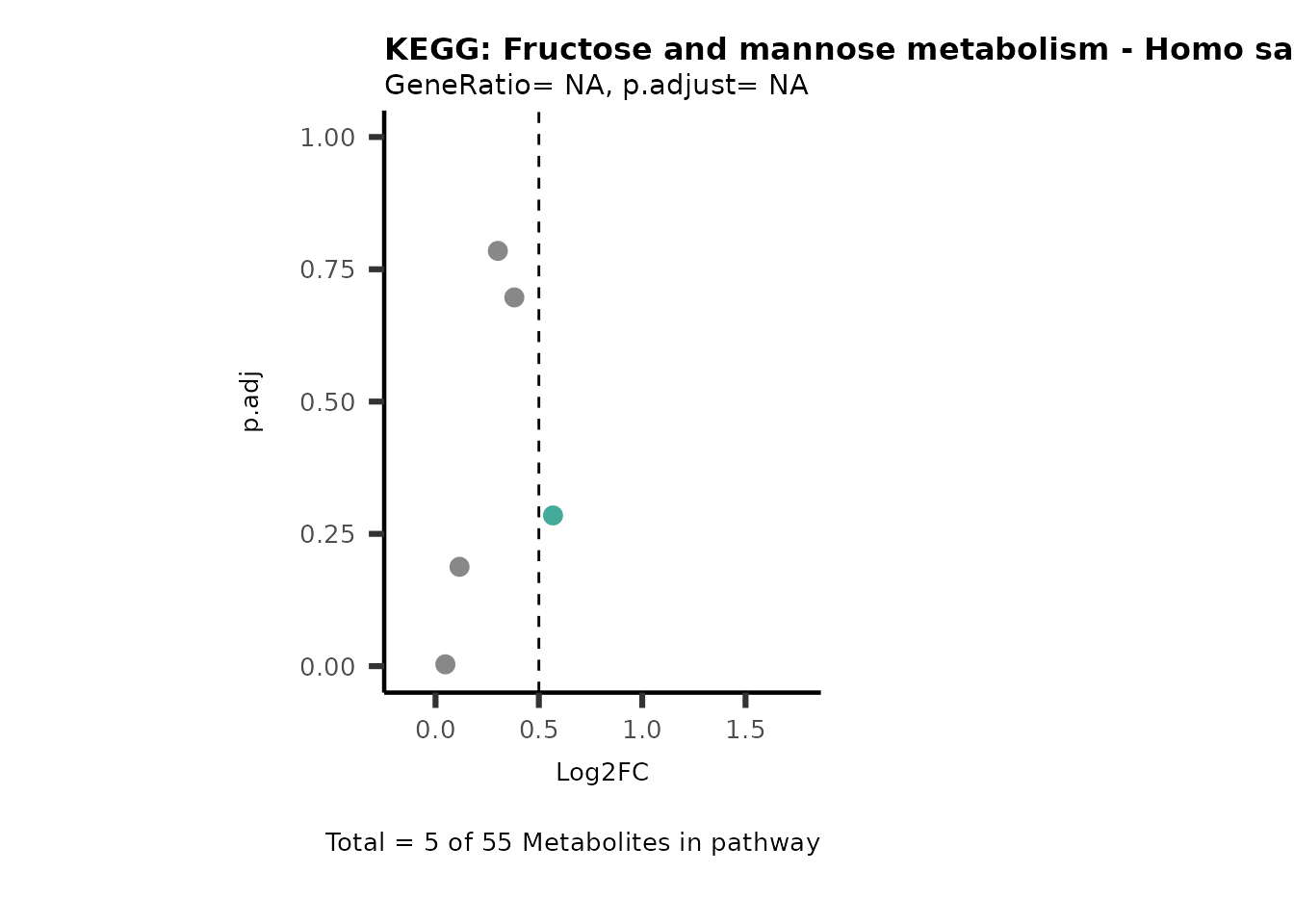






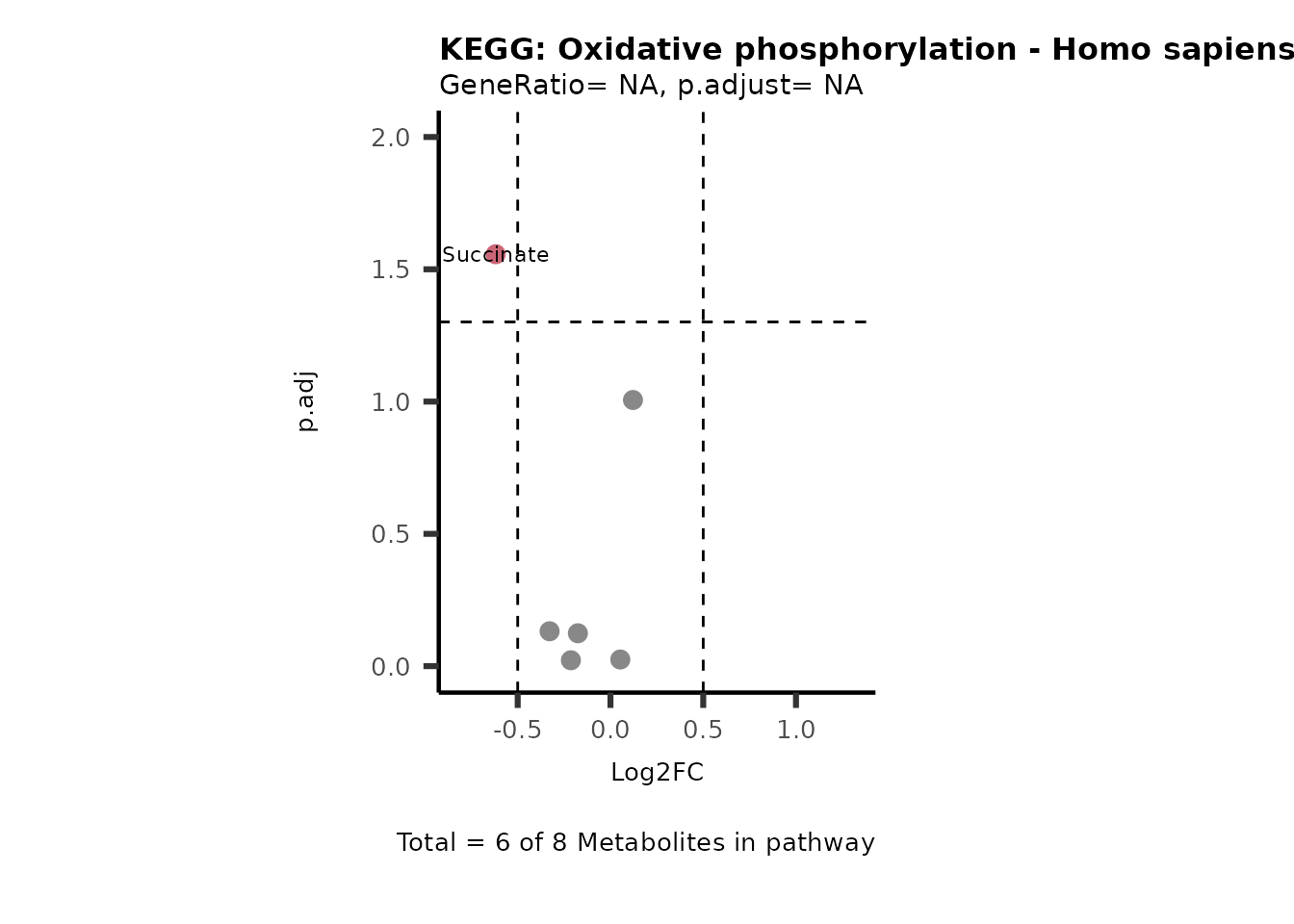


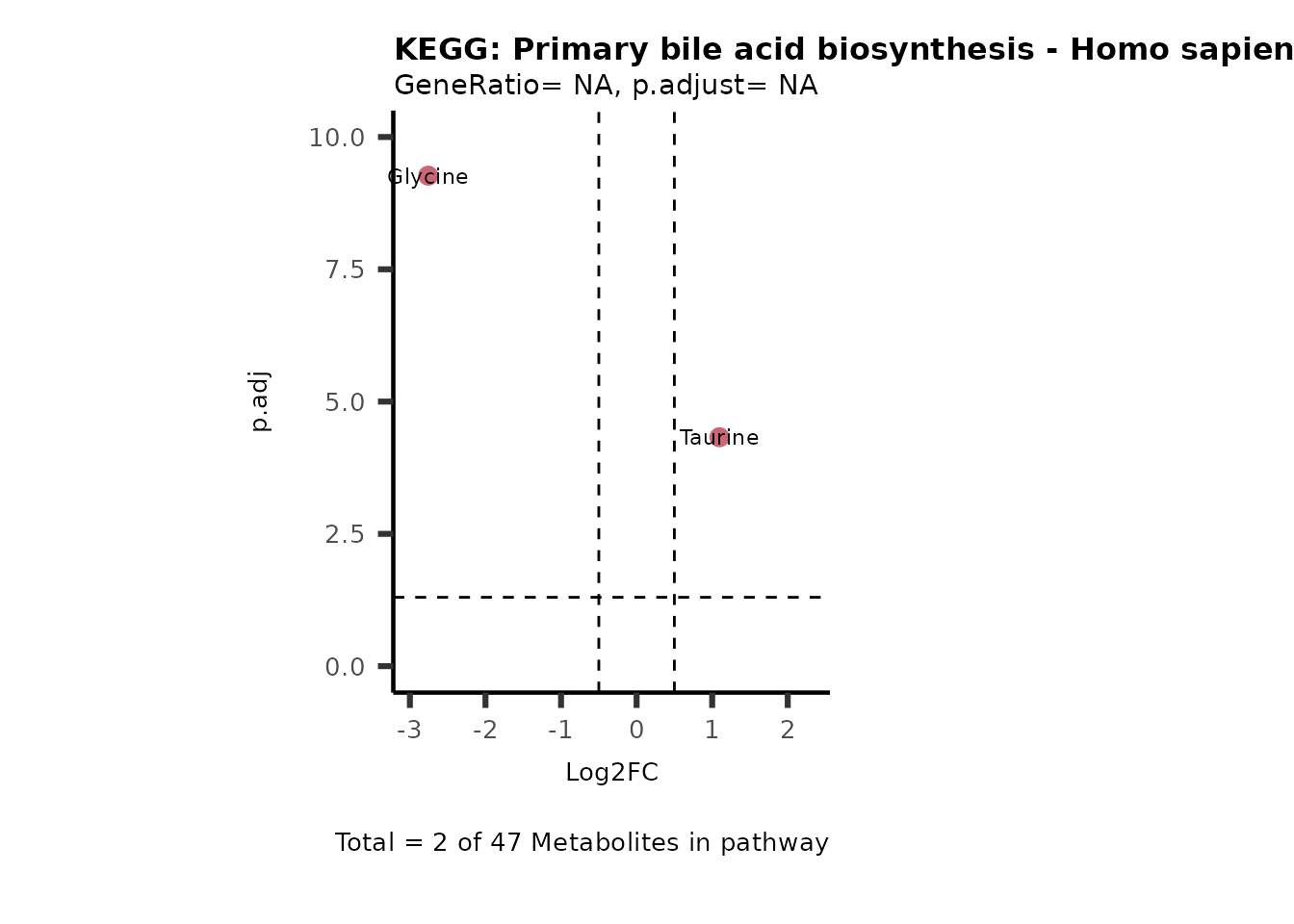
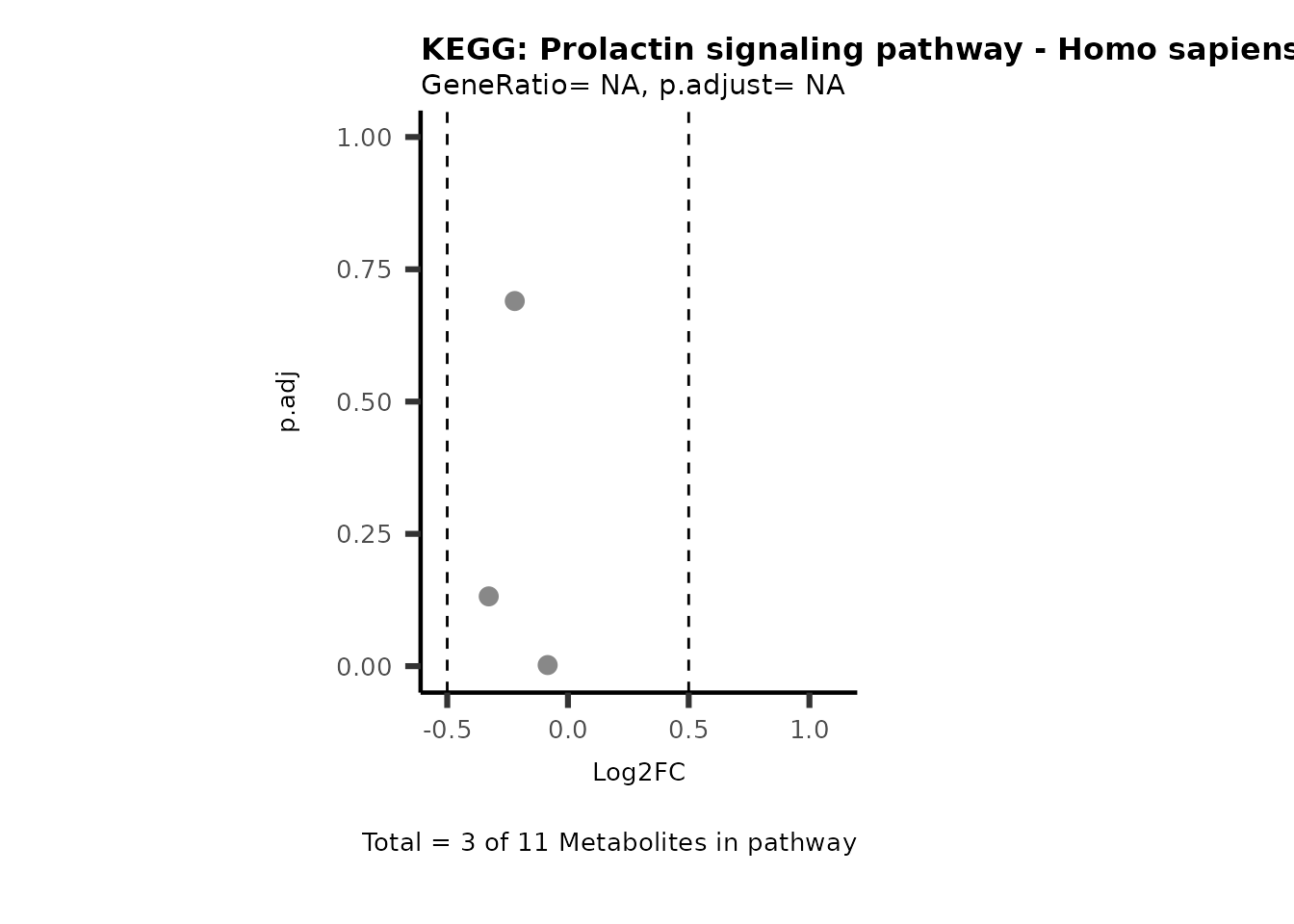


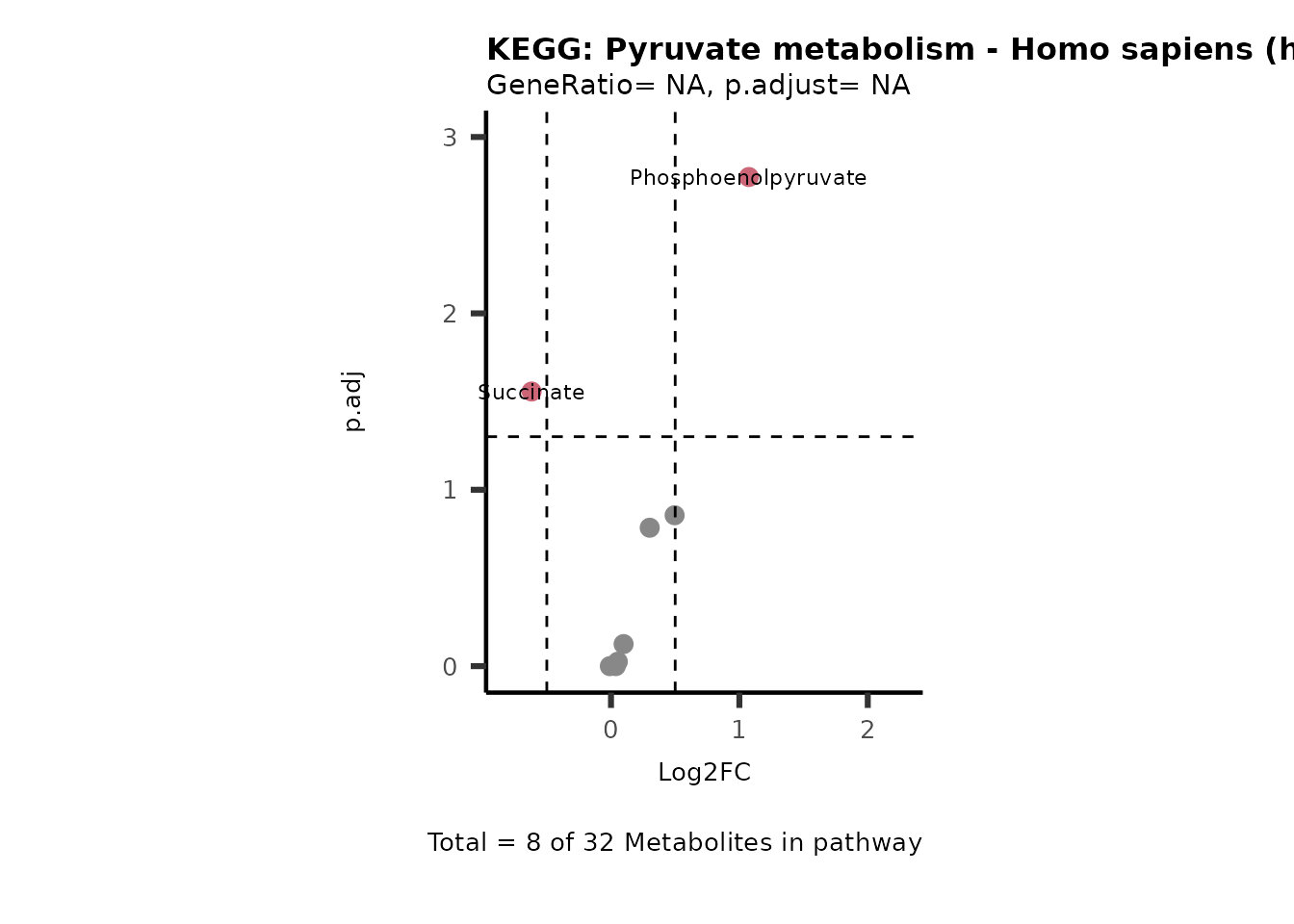

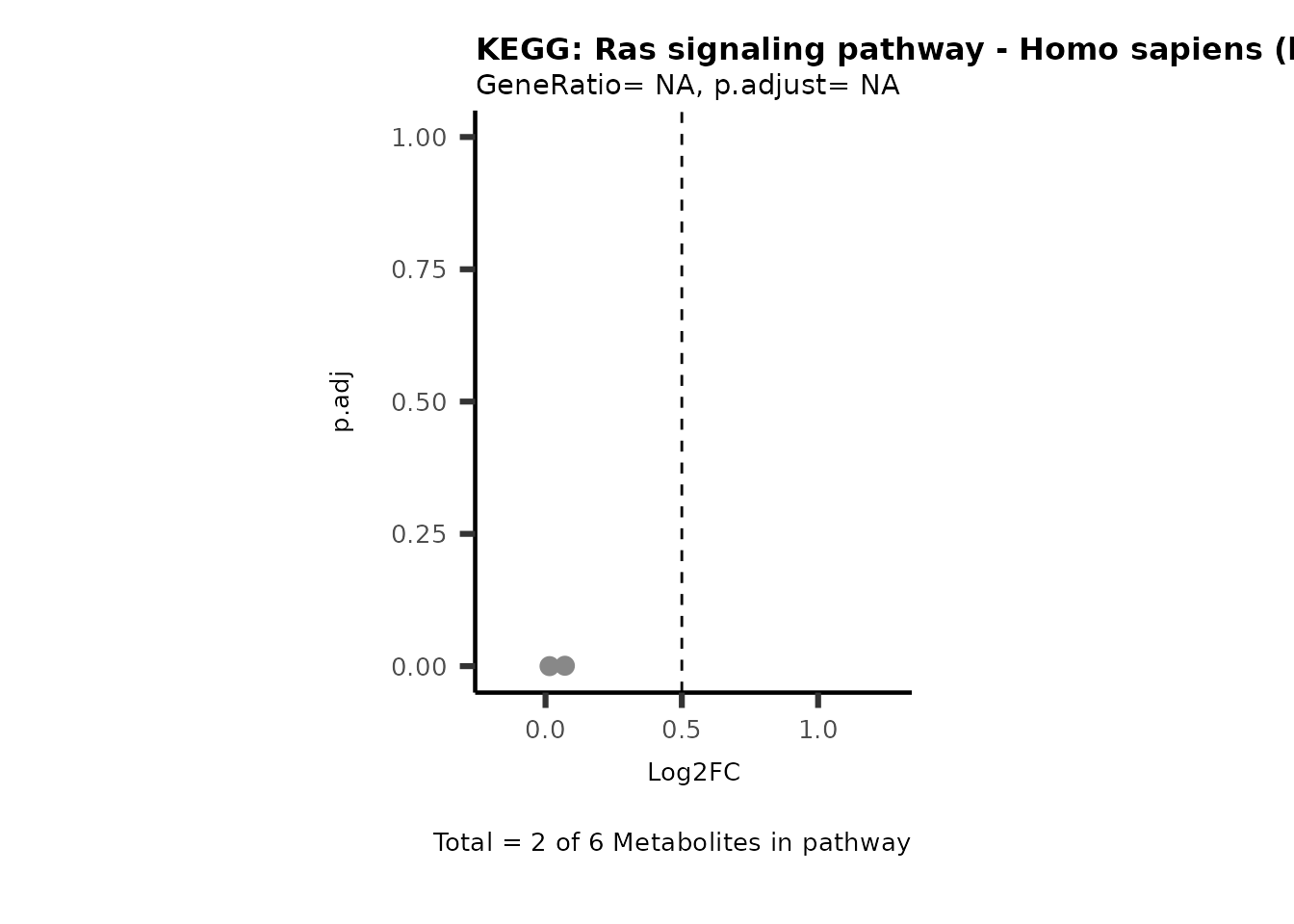
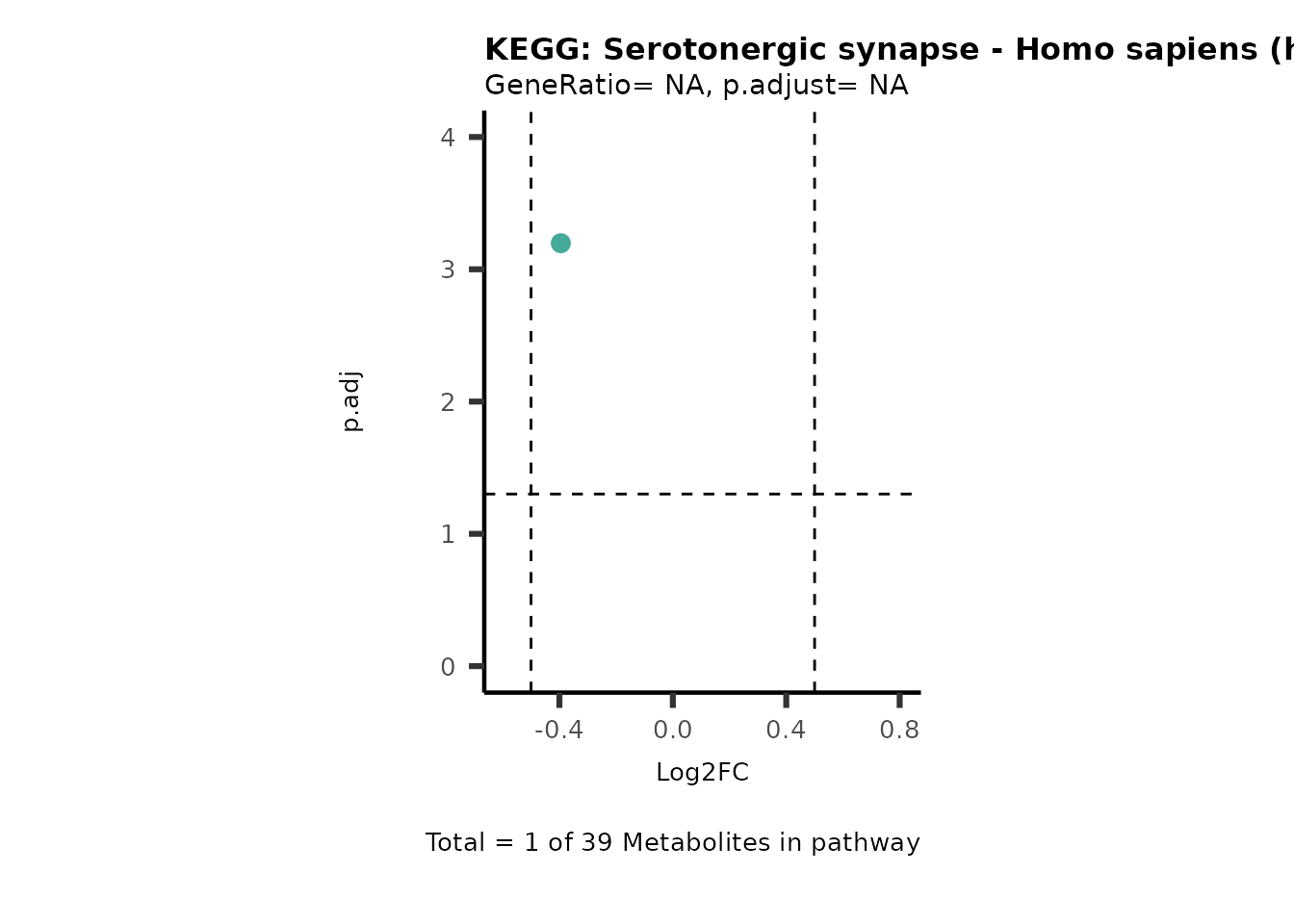
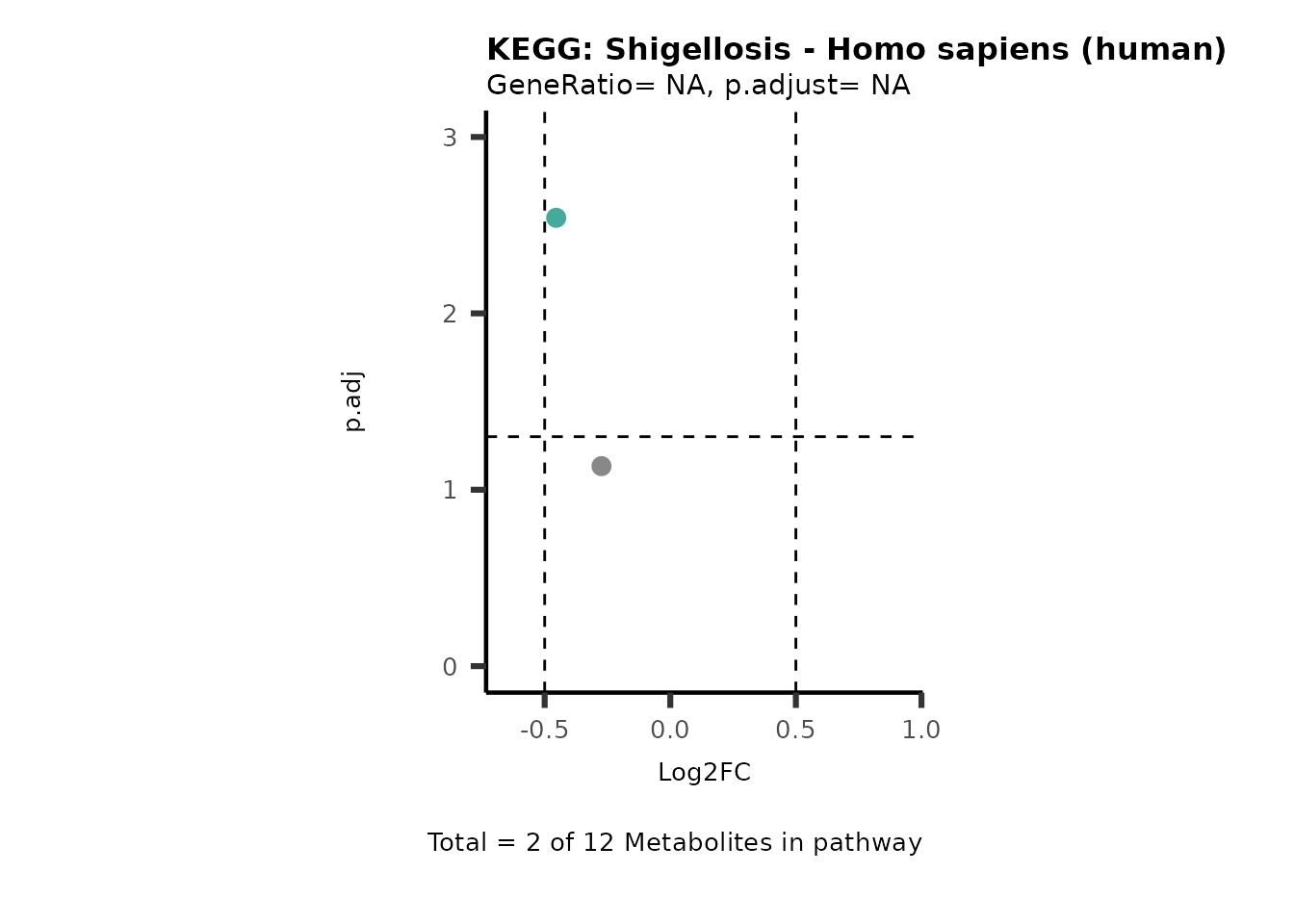
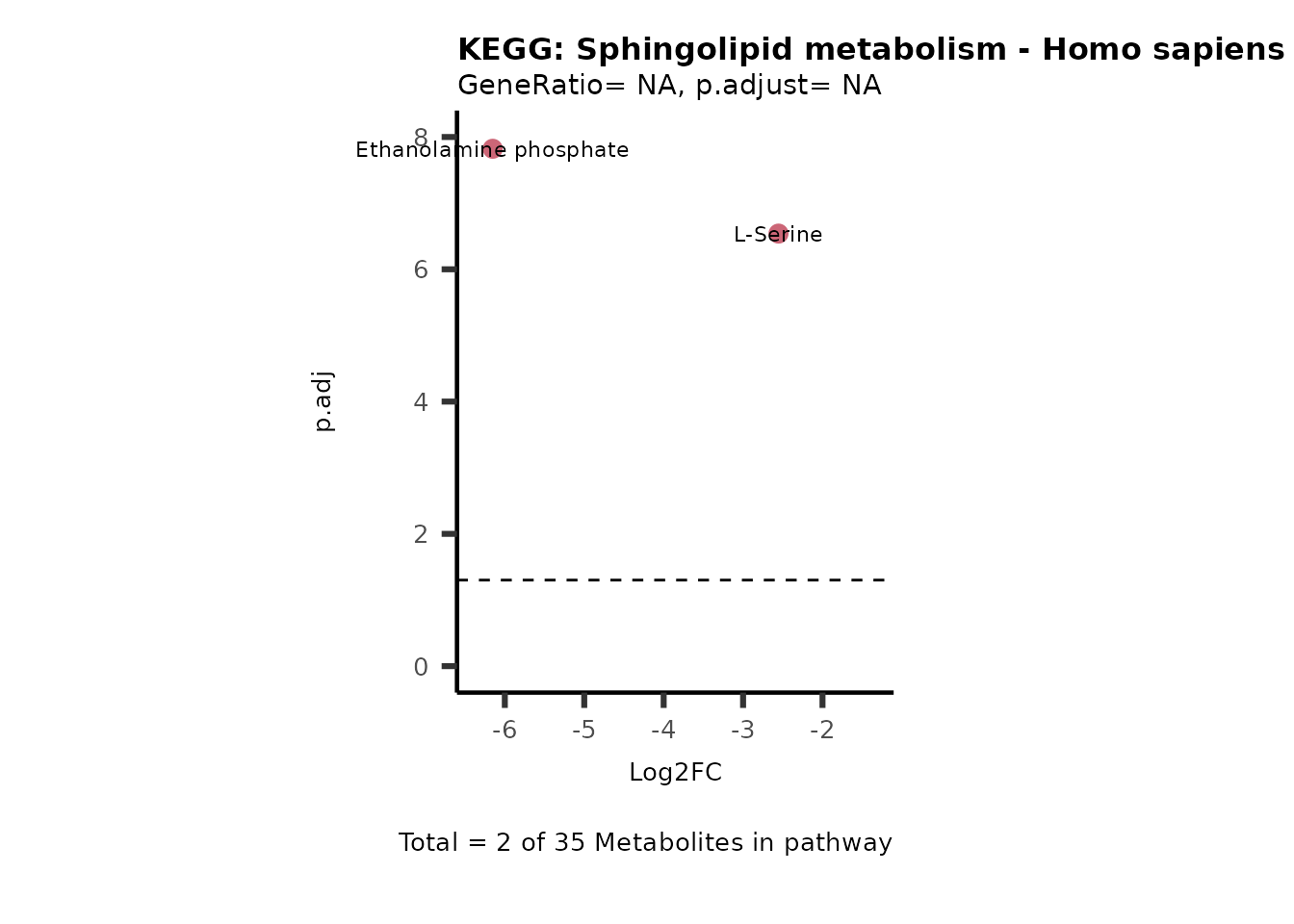
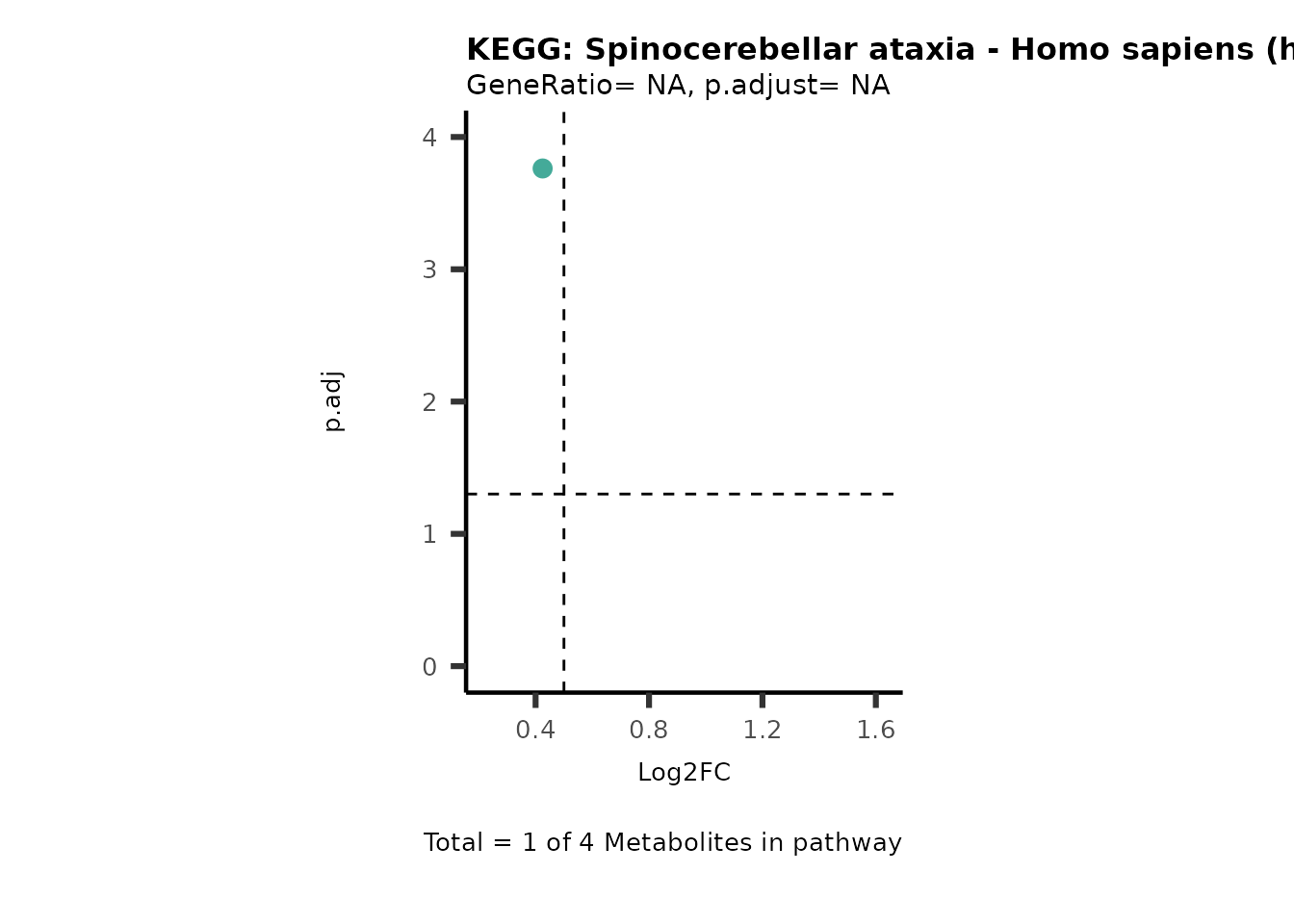
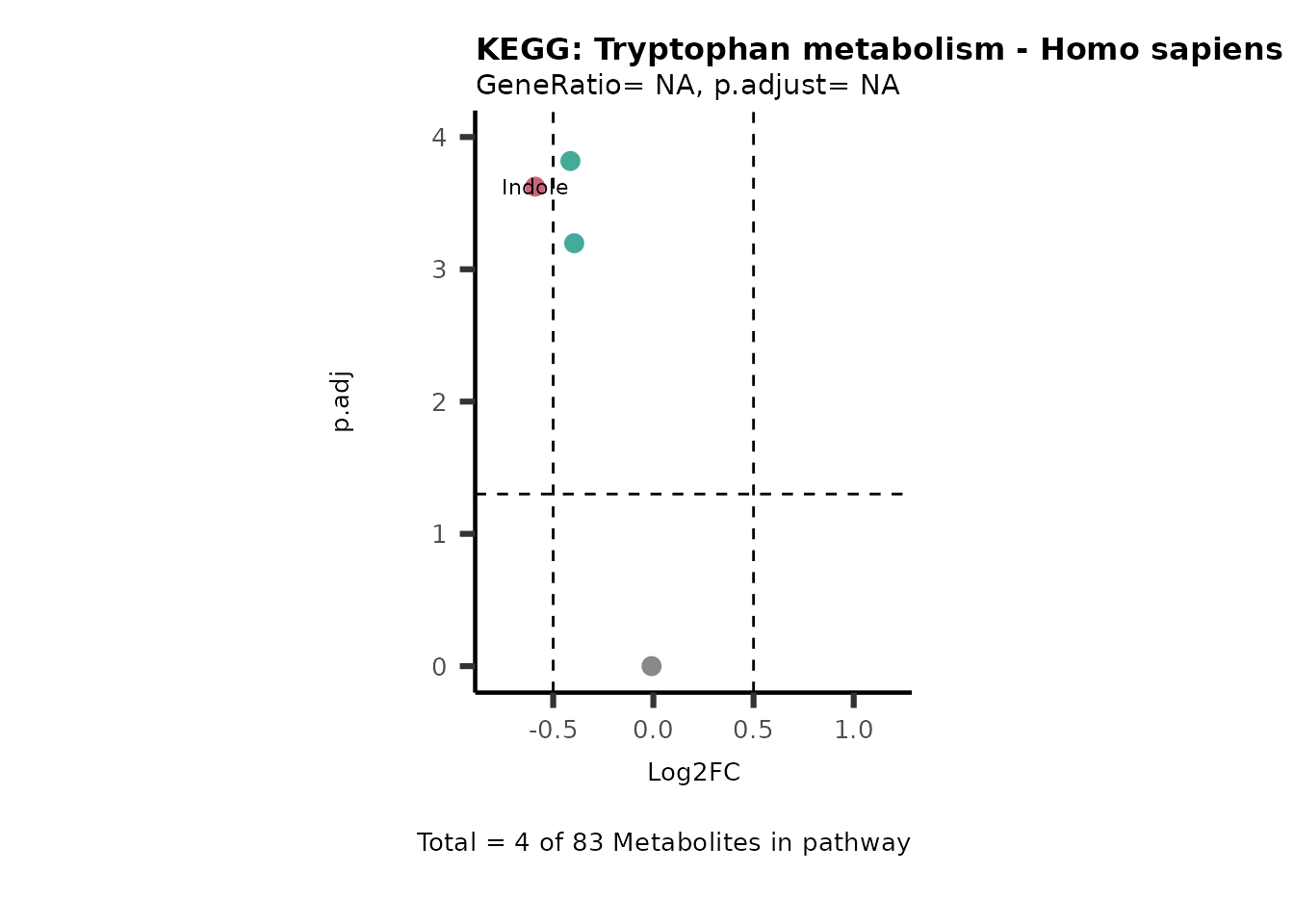

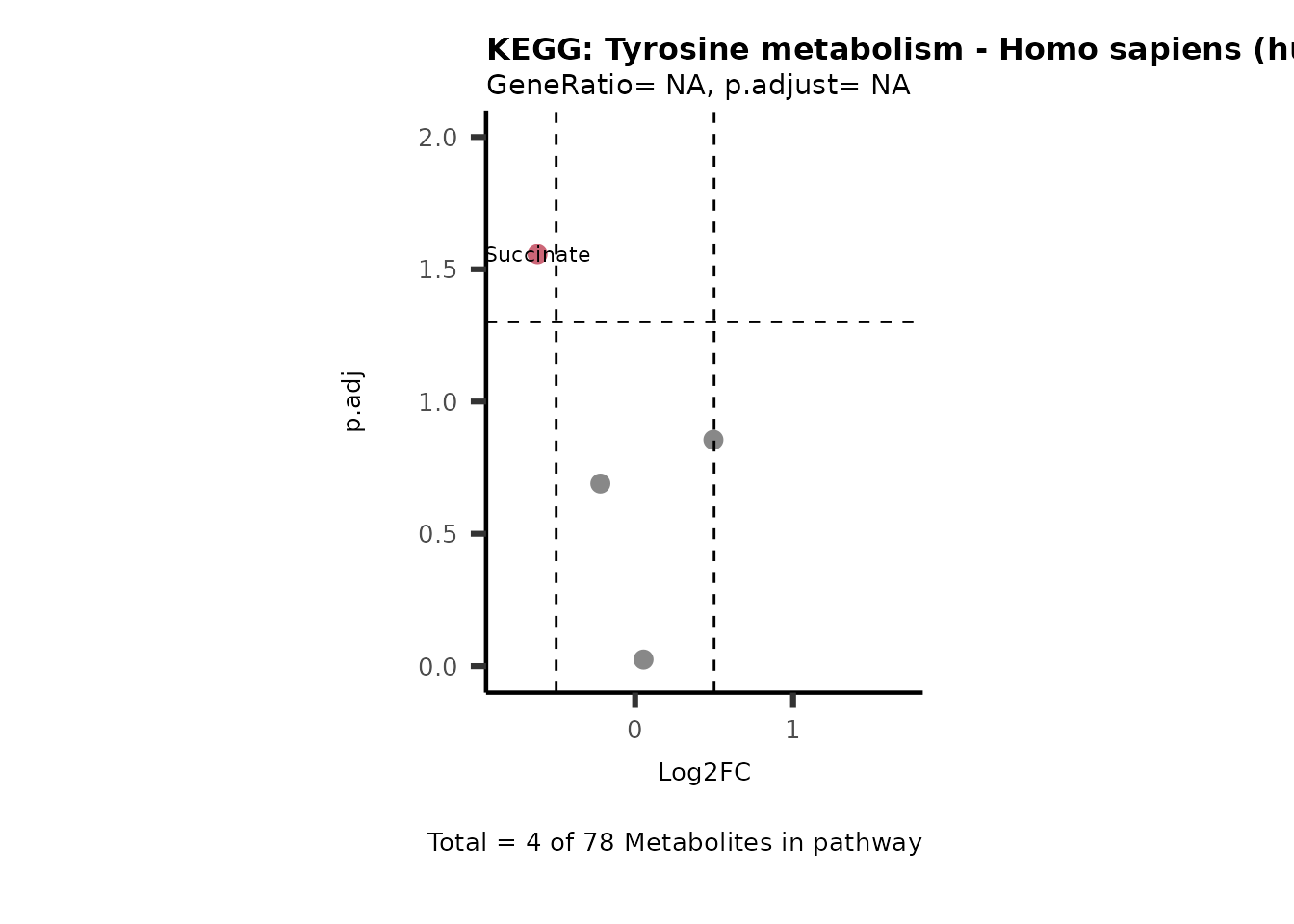
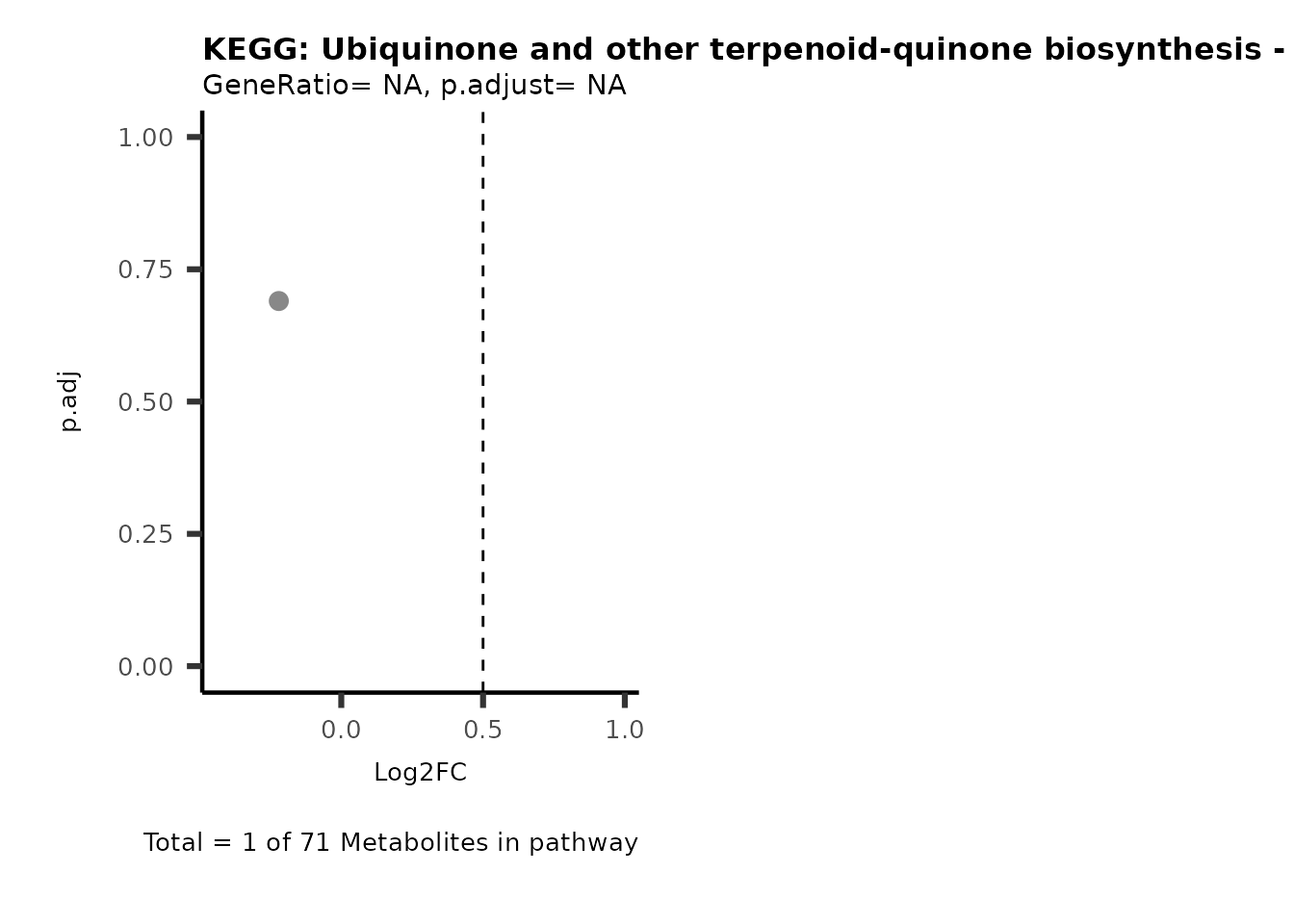
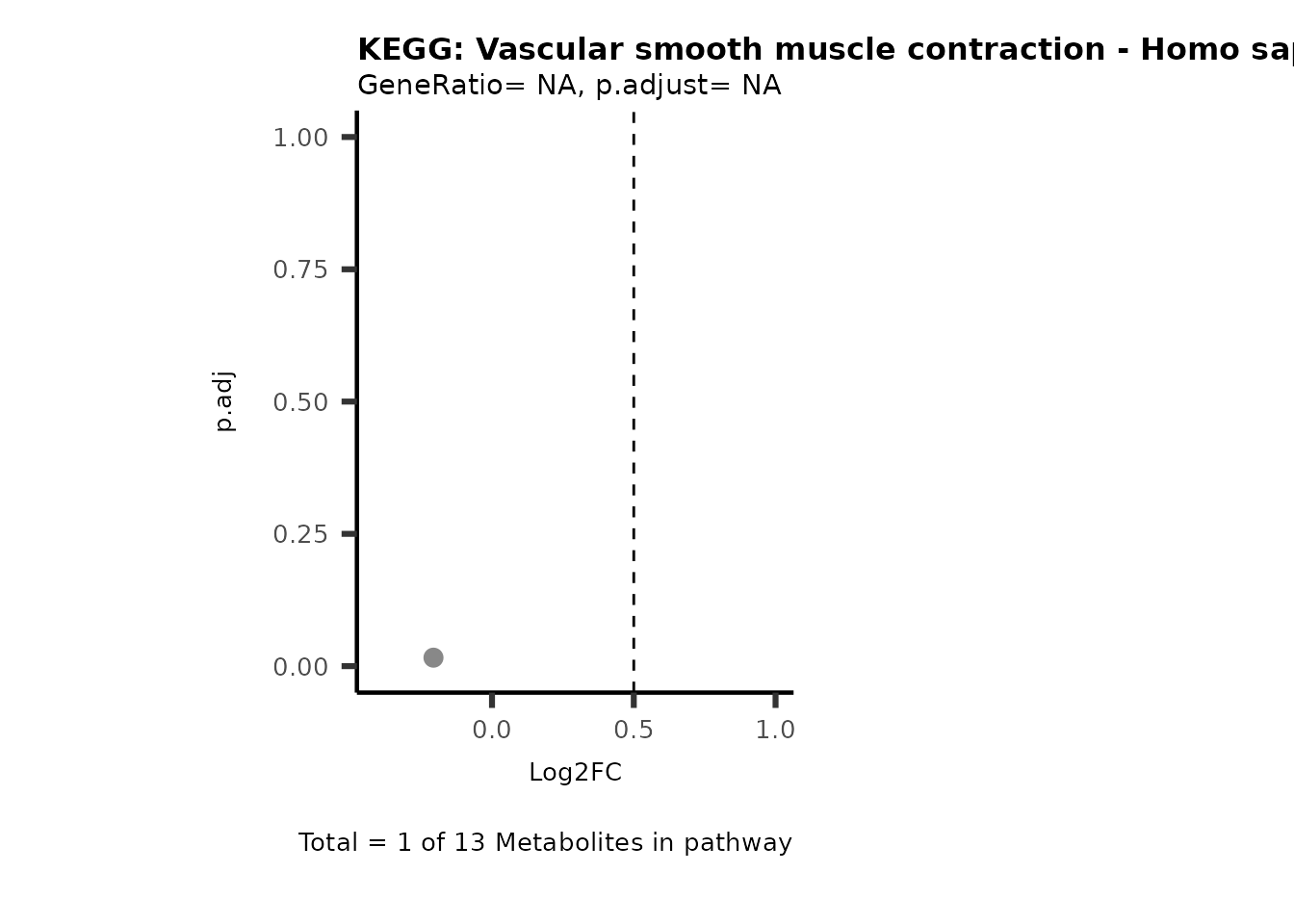
Session information
#> R version 4.4.2 (2024-10-31)
#> Platform: x86_64-pc-linux-gnu
#> Running under: Ubuntu 24.04.1 LTS
#>
#> Matrix products: default
#> BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
#> LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
#>
#> locale:
#> [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8 LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8
#> [6] LC_MESSAGES=C.UTF-8 LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C LC_TELEPHONE=C
#> [11] LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
#>
#> time zone: UTC
#> tzcode source: system (glibc)
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] tibble_3.2.1 ggfortify_0.4.17 rlang_1.1.4 dplyr_1.1.4 magrittr_2.0.3 MetaProViz_2.1.3
#> [7] ggplot2_3.5.1
#>
#> loaded via a namespace (and not attached):
#> [1] splines_4.4.2 later_1.4.1 ggplotify_0.1.2 bitops_1.0-9
#> [5] R.oo_1.27.0 cellranger_1.1.0 polyclip_1.10-7 XML_3.99-0.17
#> [9] factoextra_1.0.7 lifecycle_1.0.4 rstatix_0.7.2 lattice_0.22-6
#> [13] vroom_1.6.5 MASS_7.3-61 backports_1.5.0 limma_3.58.1
#> [17] sass_0.4.9 rmarkdown_2.29 jquerylib_0.1.4 yaml_2.3.10
#> [21] zip_2.3.1 EnhancedVolcano_1.20.0 qcc_2.7 RColorBrewer_1.1-3
#> [25] cowplot_1.1.3 DBI_1.2.3 lubridate_1.9.4 abind_1.4-8
#> [29] zlibbioc_1.48.2 rvest_1.0.4 purrr_1.0.2 R.utils_2.12.3
#> [33] ggraph_2.2.1 BiocGenerics_0.48.1 RCurl_1.98-1.16 hash_2.2.6.3
#> [37] yulab.utils_0.1.8 tweenr_2.0.3 rappdirs_0.3.3 GenomeInfoDbData_1.2.11
#> [41] IRanges_2.36.0 S4Vectors_0.40.2 enrichplot_1.22.0 ggrepel_0.9.6
#> [45] tidytree_0.4.6 pheatmap_1.0.12 pkgdown_2.1.1 svglite_2.1.3
#> [49] codetools_0.2-20 DOSE_3.28.2 xml2_1.3.6 ggforce_0.4.2
#> [53] tidyselect_1.2.1 aplot_0.2.4 farver_2.1.2 viridis_0.6.5
#> [57] stats4_4.4.2 jsonlite_1.8.9 tidygraph_1.3.1 Formula_1.2-5
#> [61] systemfonts_1.1.0 tools_4.4.2 progress_1.2.3 treeio_1.26.0
#> [65] ragg_1.3.3 Rcpp_1.0.13-1 glue_1.8.0 gridExtra_2.3
#> [69] xfun_0.49 qvalue_2.34.0 GenomeInfoDb_1.38.8 withr_3.0.2
#> [73] fastmap_1.2.0 digest_0.6.37 gridGraphics_0.5-1 timechange_0.3.0
#> [77] R6_2.5.1 textshaping_0.4.1 colorspace_2.1-1 GO.db_3.18.0
#> [81] gtools_3.9.5 RSQLite_2.3.9 R.methodsS3_1.8.2 tidyr_1.3.1
#> [85] generics_0.1.3 data.table_1.16.4 graphlayouts_1.2.1 prettyunits_1.2.0
#> [89] httr_1.4.7 htmlwidgets_1.6.4 scatterpie_0.2.4 inflection_1.3.6
#> [93] pkgconfig_2.0.3 gtable_0.3.6 blob_1.2.4 XVector_0.42.0
#> [97] shadowtext_0.1.4 clusterProfiler_4.10.1 OmnipathR_3.15.2 htmltools_0.5.8.1
#> [101] carData_3.0-5 fgsea_1.33.1 scales_1.3.0 kableExtra_1.4.0
#> [105] Biobase_2.62.0 png_0.1-8 ggfun_0.1.8 knitr_1.49
#> [109] rstudioapi_0.17.1 tzdb_0.4.0 reshape2_1.4.4 nlme_3.1-166
#> [113] checkmate_2.3.2 curl_6.0.1 cachem_1.1.0 stringr_1.5.1
#> [117] parallel_4.4.2 vipor_0.4.7 HDO.db_0.99.1 AnnotationDbi_1.64.1
#> [121] desc_1.4.3 pillar_1.10.0 grid_4.4.2 logger_0.4.0
#> [125] vctrs_0.6.5 ggpubr_0.6.0 car_3.1-3 beeswarm_0.4.0
#> [129] evaluate_1.0.1 readr_2.1.5 cli_3.6.3 compiler_4.4.2
#> [133] crayon_1.5.3 ggsignif_0.6.4 labeling_0.4.3 plyr_1.8.9
#> [137] fs_1.6.5 ggbeeswarm_0.7.2 stringi_1.8.4 viridisLite_0.4.2
#> [141] BiocParallel_1.36.0 munsell_0.5.1 Biostrings_2.70.3 lazyeval_0.2.2
#> [145] GOSemSim_2.28.1 Matrix_1.7-1 hms_1.1.3 patchwork_1.3.0
#> [149] bit64_4.5.2 KEGGREST_1.42.0 statmod_1.5.0 igraph_2.1.2
#> [153] broom_1.0.7 memoise_2.0.1 bslib_0.8.0 ggtree_3.10.1
#> [157] fastmatch_1.1-4 bit_4.5.0.1 readxl_1.4.3 gson_0.1.0
#> [161] ape_5.8-1